Матрица-Перематрица
- воскресенье, 16 мая 2021 г. в 00:34:55

Работа нейронной сети основана на манипуляциях с матрицами. Для обучения используются разнообразные методы, многие из которых выросли из метода градиентного спуска, где необходимо умение обращаться с матрицами, вычислять градиенты (производные по матрицам). Если заглянуть “под капот” нейронной сети, можно увидеть цепочки из матриц, выглядящие зачастую устрашающе. Проще говоря, “нас всех подстерегает матрица”. Пора познакомиться поближе.
Для этого сделаем следующие шаги:
рассмотрим манипуляции с матрицами : транспонирование, умножение, градиент;
построим игрушечную нейронную сеть;
познакомимся с методом обратного распространения ошибки с использованием метода градиентного спуска.
Все шаги сопровождаются примерами кода с использованием только NumPy . Вычисления, не выходящие, впрочем, за рамки элементарной математики, приведены подробно. За индексами придется внимательно следить, но не отчаивайтесь, просто представьте, что каждый индекс - винтик, который надо закрутить, следуя простым правилам, но не пропустить. Если вдруг не разберетесь, ничего страшного - одно из двух: либо сбой в матрице, либо одно из двух.
Основная структура данных в системах машинного обучения - тензор, который, по сути, является многомерным массивом. Тем не менее, тензор звучит солиднее, причем настолько, что он вошел в название библиотеки машинного обучения Google TensorFlow.
Итак, определим одномерный массив, он же тензор с единственной осью, он же тензор первого ранга, или просто вектор, который будем обозначать  , где индекс
, где индекс  ;
;  - размерность вектора.
- размерность вектора.
import numpy as np # импорт модуля numpy
a=np.array([1,2,5])
a.ndim # одномерный тензор, количество осей = 1
a.shape # длина массива по каждой оси (3,)
a.shape[0] # длина массива по нулевой оси = 3Скалярное произведение двух векторов  . Отметим, что по повторяющимся индексам производится суммирование, здесь пробегает значения от 0 до 2 включительно.
. Отметим, что по повторяющимся индексам производится суммирование, здесь пробегает значения от 0 до 2 включительно.
b=np.array([3,4,7])
np.dot(a,b) # скалярное произведение = 46
a*b # поэлементное произведение array([ 3, 8, 35])
np.sum(a*b) # = 46Теперь перейдем к двумерному тензору (тензору второго ранга) - матрице , элементы которой выводятся как
, элементы которой выводятся как . Например,
. Например,  - элемент матрицы на пересечении 0-й строки и 2-го столбца. Из определения ясно, что матрица имеет две оси.
- элемент матрицы на пересечении 0-й строки и 2-го столбца. Из определения ясно, что матрица имеет две оси.
A=np.array([[ 1, 2, 3],
[ 2, 4, 6]])
A # array([[1, 2, 3],
# [2, 4, 6]])
A[0, 2] # элемент на нулевой строке, во втором столбце = 3
A.shape # (2, 3) матрица имеет 2 строки, 3 столбцаПри умножении матриц и
и получаем матрицу
получаем матрицу  , элементы которой
, элементы которой  . Поскольку по повторяющимся индексам производится суммирования, количество столбцов матрицы
. Поскольку по повторяющимся индексам производится суммирования, количество столбцов матрицы должно совпадать с количеством строк
должно совпадать с количеством строк (первое измерение
(первое измерение  совпадает с нулевым измерением
совпадает с нулевым измерением )
)
B=np.array([[7, 8, 1, 3],
[5, 4, 2, 7],
[3, 6, 9, 4]])
A.shape[1] == B.shape[0] # true
A.shape[1], B.shape[0] # (3, 3)
A.shape, B.shape # ((2, 3), (3, 4))
C = np.dot(A, B)
C # array([[26, 34, 32, 29],
# [52, 68, 64, 58]]);
# например, C[0,1]=A[0,0]B[0,1]+ A[0,1]B[1,1]+A[0,2]B[2,1]=1*8+2*4+3*6=34
C.shape # (2, 4) Если попытаемся умножить  , то:
, то:
np.dot(B, A) # ValueError: shapes (3,4) and (2,3) not aligned: 4 (dim 1) != 2 (dim 0)Первая размерность матрицы  не совпадает с нулевой
не совпадает с нулевой  , о чем красноречиво и говорится.
, о чем красноречиво и говорится.
Посмотрим, как построить матрицу из двух векторов. Для этого из векторов сделаем матрицы с одним столбцом, элементы которой  и
и  . Затем имеем
. Затем имеем  . Повторяющийся индекс есть, но он стоит не внутри произведения, как прописано в правилах для произведения матриц, поэтому воспользуемся тождеством
. Повторяющийся индекс есть, но он стоит не внутри произведения, как прописано в правилах для произведения матриц, поэтому воспользуемся тождеством  , где
, где  - транспонированная матрица (используем обозначения NumPy). В результате имеем
- транспонированная матрица (используем обозначения NumPy). В результате имеем . Любопытно, что операция транспонирования приводит
. Любопытно, что операция транспонирования приводит  .
.
a = np.reshape(a, (3,1)) # изменяет форму тензора, от a.shape = (3,) к (3,1),
b = np.reshape(b, (3,1)) # три строки, один столбец
D = np.dot(a,b.T)
D # array([[ 3, 4, 7],
# [ 6, 8, 14],
# [15, 20, 35]])Вводим матрицу на входе, получаем результат на выходе. Поскольку мы тренируемся на подготовленном наборе данных, на выходе знаем нужный ответ.
Представим себе нейронную сеть как черный ящик с ручками, которыми можно манипулировать так, чтобы значения на выходе из нашего ящика как можно меньше отличались от тестового результата. Мера отклонения выводится с помощью функции потерь (cost function). Отметим, что в одну сторону ручки крутятся полегче. Туда осторожно и крутим. Когда все данные из тренировочного набора прошли один раз, и каждую ручку покрутили с выбранным шагом (learning rate), говорят, произошла одна эпоха (epoch). И так повторяем до тех пор, пока уменьшается функция потерь. Далее записываем показания ручек (веса), которые вместе с архитектурой и методом коррекции весов представляют собой исчерпывающий набор данных относительно обученной нейронной сети. Теперь мы можем засунуть в наш черный ящик любые разумные данные и получить наиболее вероятный ответ. Раньше этим занимались разумные животные, теперь ситуация изменилась, но как не было разумного подхода, так до сих пор и нет.

Разберем простую нейронную сеть, показанную на рисунке из статьи (рекомендую посмотреть, есть русский перевод ).
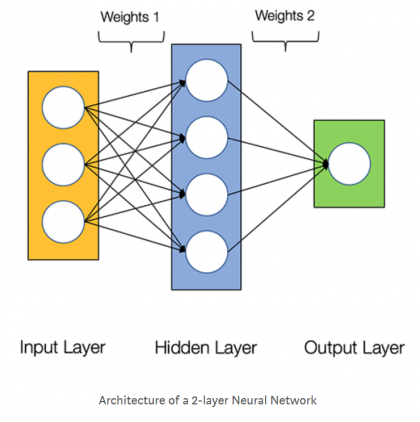
На входе имеем подготовленные данные - совокупность образцов (samples) . Каждый образец представлен вектором с тремя компонентами. Таким образом, все данные представлены тензором второго ранга (матрицей), первая ось которого (ось с нулевым индексом ) - ось образцов (samples), вторая - ось признаков (features).
Для обучения нейронной сети имеем подготовленный тренировочный набор, в котором каждый образец имеет определённый выход (целевые данные). Это может быть распределение по классам (мужчина, женщина и …) или, например, значение температуры кончика носа для заданных параметров. Нам необходимо построить такую модель, чтобы значения на выходе как можно меньше отличались от значений из тренировочного набора.
Давайте пройдемся по нашей нейронной сети от начала до конца, посмотрим, что где лежит. Мы не будем ничего запоминать, просто погуляем по “Дворцу памяти” . Там не так много места, поскольку это всего лишь произведения матриц, которые разворачиваются от начала до конца. Мы вольны делать с ними все что угодно, только надо контролировать, чтобы каждая последующая матрица правильно зацеплялась с предыдущей по правилу умножения матриц. Есть матрицы с данными, и есть матрицы с параметрами, которые впоследствии подстроим, когда пойдем в обратный путь.
Предположим, на входе имеем 10 экземпляров векторов с трем признаками. Таким образом, матрица на входе имеет форму (10, 3). Пока возьмем ее “с потолка”, заполним случайными числами. Существует несколько вариантов, как это можно сделать. Итак, можно заполнить матрицу:
целыми в диапазоне, например, от 0 до 50 ;
X=np.random.randint(0, 50, (10, 3))равномерно распределенными в диапазоне от 0 до 1;
X=np.random.rand(10, 3)распределёнными по нормальному закону со средним  и дисперсией
и дисперсией . Нормальное распределение, или распределение Гаусса, обычно обозначается как
. Нормальное распределение, или распределение Гаусса, обычно обозначается как ;
;
X=4*np.random.randn(10, 3) + 2Когда  и
и  , имеем дело со стандартным нормальным распределением.
, имеем дело со стандартным нормальным распределением.
Итак, на входе имеем матрицу  с формой
с формой  Теперь нам надо определить матрицу весов
Теперь нам надо определить матрицу весов  , чтобы подать значения на внутренний слой с четырьмя нейронами. Если значения в тренировочном наборе полностью определены при постановке задачи обучения, первоначальные значения весов задаются действительно произвольно, полагаясь впоследствии на методы их корректировки. Очевидно, что, вспоминая правила умножения матриц,
, чтобы подать значения на внутренний слой с четырьмя нейронами. Если значения в тренировочном наборе полностью определены при постановке задачи обучения, первоначальные значения весов задаются действительно произвольно, полагаясь впоследствии на методы их корректировки. Очевидно, что, вспоминая правила умножения матриц,  должна иметь форму
должна иметь форму  . Полезно себе представить, что
. Полезно себе представить, что  . В результате, на внутренний слой приходит матрица
. В результате, на внутренний слой приходит матрица  с формой
с формой  , на которую действует - причем весьма необычным способом - функция активации , выбранная должным образом для внутреннего слоя. Функция действует на каждый элемент матрицы независимо от другого элемента. Иными словами, если есть матрица
, на которую действует - причем весьма необычным способом - функция активации , выбранная должным образом для внутреннего слоя. Функция действует на каждый элемент матрицы независимо от другого элемента. Иными словами, если есть матрица  с формой
с формой  (
(  строк,
строк,  столбцов ) и с элементами
столбцов ) и с элементами  , то после действия функции
, то после действия функции  получим матрицу с той же формой, элементы которой равны
получим матрицу с той же формой, элементы которой равны  ; просто, например, имеем
; просто, например, имеем  , и так для каждого элемента. На выходе для каждого образца получим число, поэтому проблема выбора матрицы весов
, и так для каждого элемента. На выходе для каждого образца получим число, поэтому проблема выбора матрицы весов  становится тривиальной, поскольку она должна иметь форму
становится тривиальной, поскольку она должна иметь форму  . Таким образом,
. Таким образом,  . Итак, наше предсказание
. Итак, наше предсказание  представлено в виде матрицы с 10-ю строчками (samples) и одним столбцом. В матричном виде все выглядит тривиально:
представлено в виде матрицы с 10-ю строчками (samples) и одним столбцом. В матричном виде все выглядит тривиально:

Напоминаем, что нумерация начинается с нуля. Для наглядности мы пока не включили функции активации и смещения (bias).
Проверим на коде. Задача состоит в следующем: создать имитацию данных на входе, построить матрицы весов, получить значение на выходе, следить за формой.
X=np.random.randint(0, 50, (10, 3))
w1=2*np.random.rand(3,4)-1 # матрица случайных чисел в диапазоне от -1 до +1
w2=2*np.random.rand(4,1)-1
Y=np.dot(np.dot(x,w1),w2) # значения на выходе
Y.shape # (10, 1)
Y.T.shape # (1, 10)
(np.dot(Y.T,Y)).shape # (1, 1), смотрим, что получается при сверткеНа выходе получили числа внутри матрицы с формой . Мы специально выбирали веса в диапазоне от -1 до +1, исходя из собственных “мутных” соображений (пока это не принципиально).
Теперь включим функции активации. Первая функция  будет действовать на вход “скрытого слоя”, вторая - на выход . В результате имеем
будет действовать на вход “скрытого слоя”, вторая - на выход . В результате имеем


Подавая значения на вход нейронной сети из тренировочного набора, мы должны сравнить наши предсказания с этими значениями. С этой целью определим функцию потерь

где  - тренировочный набор, и мы ввели обозначение
- тренировочный набор, и мы ввели обозначение  . Напомним, что для транспонированной матрицы справедливо соотношение
. Напомним, что для транспонированной матрицы справедливо соотношение  .
.
Это все, что мы можем получить на выходе. Пора в обратный путь.
На самом деле никакого распространения нет. Выход нейронной сети - просто произведение матриц. Причем все должно быть построено таким образом, чтобы функция потерь оказалась минимальной. Для этого необходимо нужным образом подстроить параметры, входящие в матрицы весов.
Функция потерь - это функция многих переменных, в роли которых выступают веса. Экстремальная точка функции  находится из уравнения
находится из уравнения  , где “штрих ” - производная. Если вторая производная в этой точке больше нуля, это будет минимум, и наоборот. Понятно, что решить уравнение со многими переменными затруднительно, поэтому и проверить экстремум не представляется возможным. Можно поступить проще: стартовать из произвольной точки в пространстве весов - она у нас уже задана, поскольку мы определили матрицу весов случайным образом, - затем двигаться в направлении минимума. Выберем одну переменную веса (напомним, их у нас уже 16 штук), при этом зависимость от этой переменной одномерная, если зафиксированы остальные. Двигаемся от нуля в положительном направлении. Если спускаемся вниз,
, где “штрих ” - производная. Если вторая производная в этой точке больше нуля, это будет минимум, и наоборот. Понятно, что решить уравнение со многими переменными затруднительно, поэтому и проверить экстремум не представляется возможным. Можно поступить проще: стартовать из произвольной точки в пространстве весов - она у нас уже задана, поскольку мы определили матрицу весов случайным образом, - затем двигаться в направлении минимума. Выберем одну переменную веса (напомним, их у нас уже 16 штук), при этом зависимость от этой переменной одномерная, если зафиксированы остальные. Двигаемся от нуля в положительном направлении. Если спускаемся вниз, , мы должны продолжить движение, если поднимаемся по склону,
, мы должны продолжить движение, если поднимаемся по склону,  , лучше вернуться назад в направлении к минимуму. Таким образом, изменение переменной должно быть пропорционально производной с отрицательным знаком. Для функции потерь имеем
, лучше вернуться назад в направлении к минимуму. Таким образом, изменение переменной должно быть пропорционально производной с отрицательным знаком. Для функции потерь имеем

или для компонент

где  - коэффициент скорости обучения (learning rate). Как видно, в этой формуле стоят производные по матрицам. Производные в этих формулах еще называют градиентом . Для векторов - это нормально, а для тензоров, почему бы и нет. Тем более, название самого метода - градиентный спуск .
- коэффициент скорости обучения (learning rate). Как видно, в этой формуле стоят производные по матрицам. Производные в этих формулах еще называют градиентом . Для векторов - это нормально, а для тензоров, почему бы и нет. Тем более, название самого метода - градиентный спуск .
Для вычисления производных по матрицам необходимо руководствоваться правилом

где  - символ Кронекера, который отличен от нуля только тогда, когда
- символ Кронекера, который отличен от нуля только тогда, когда  . Например,
. Например,  , а уже
, а уже  . Но самое главное: внимательно отслеживать индексы и никуда не спешить.
. Но самое главное: внимательно отслеживать индексы и никуда не спешить.
Для производной от функции потерь по матрице имеем

где, напомним,  , по повторяющимся индексам производится суммирование.
, по повторяющимся индексам производится суммирование.
Градиент без активации. Пока проделаем вычисления без функций активации. Затем, когда освоимся в мире элементарного дифференцирования матриц, включим механизмы активации.
Итак, вспоминая  , получим
, получим

Напомним, для произвольной матрицы справедливо  . Таким образом, окончательно получим следующее выражение:
. Таким образом, окончательно получим следующее выражение:

или

Посмотрим, получится ли, используя наши доморощенные данные, правильная форма для . Поскольку
. Поскольку  имеет форму
имеет форму  , после транспонирования -
, после транспонирования -  . Форма
. Форма  совпадает с формой
совпадает с формой  -
-  . Таким образом, форма
. Таким образом, форма  равна
равна  , как и должно быть.
, как и должно быть.
deltaW2=2*np.dot(np.dot(X,w1).T,Y)
deltaW2.shape # (4,1)Теперь займемся  .
.


Индексы, которые “торчат наружу”, некоторыми называются “говорящие ” - в данном случае это  и
и  . Пока мы работаем с компонентами, сомножители можно произвольно переставлять, поскольку это всего лишь числа. Это мы и сделали: поставили члены с “говорящими” индексами впереди и сзади (если необходимо транспонировали), затем проследили, чтобы индексы правильно цеплялись друг за другом в соответствии с правилом умножения матриц.
. Пока мы работаем с компонентами, сомножители можно произвольно переставлять, поскольку это всего лишь числа. Это мы и сделали: поставили члены с “говорящими” индексами впереди и сзади (если необходимо транспонировали), затем проследили, чтобы индексы правильно цеплялись друг за другом в соответствии с правилом умножения матриц.
Для формы  имеем:
имеем:  .
.
Градиент с активацией. Надеюсь,те, кто следит за индексами, разобрались с результатами предыдущего раздела, когда не было никаких функций активации. Пришло время их включить. Дифференцировать по матрицам надо аккуратно, поскольку теперь матрицы весов скрыты под функциями. Мы рекомендуем сделать замены переменных, чтобы на каждом этапе дифференцирования имели дело только с одной матрицей. Надеюсь, правила дифференцирования сложной функции знакомы читателю, но на всякий случай напомним: если  , то производная от
, то производная от  по
по  равна
равна  .
.
Итак,

где используем очевидную цепочку замен:

Матрица весов  находится не так глубоко внутри функций, поэтому первоначально найдем градиент по этой матрице. Последовательно разворачивая цепочку дифференцирования, имеем
находится не так глубоко внутри функций, поэтому первоначально найдем градиент по этой матрице. Последовательно разворачивая цепочку дифференцирования, имеем

Действительно,

Напомним, здесь функция от матрицы - матрица с той же формой. Для перемещения индекса  в начало цепочки поступаем как обычно:
в начало цепочки поступаем как обычно:  , аналогично для функций
, аналогично для функций  . Таким образом, в результате получаем
. Таким образом, в результате получаем

Остановимся подробнее на операции поэлементного умножения “*” матриц . Если у нас есть две матрицы,  и
и  , с одинаковой формой, то в результате действия операции поэлементного умножения
, с одинаковой формой, то в результате действия операции поэлементного умножения  мы получим матрицу с той же формой, каждый элемент которой равен произведению элементов; например, третий элемент второй строки равен
мы получим матрицу с той же формой, каждый элемент которой равен произведению элементов; например, третий элемент второй строки равен  .
.
Проиллюстрируем на коде. Пусть  и
и  . Эти функции будут принимать матрицы, затем возводить в степень по правилу, что каждый элемент матрицы независимо возводится в степень. Для этого в NumPy есть соответствующие функции.
. Эти функции будут принимать матрицы, затем возводить в степень по правилу, что каждый элемент матрицы независимо возводится в степень. Для этого в NumPy есть соответствующие функции.
def f1(x): # первая функция
return np.power(x,2)
def graf1(x): # производная
return 2*x
def f2(x): # вторая функция
return np.power(x,3)
def gradf2(x): # производная
return 3*np.power(x,2)
A=np.dot(X,w1) # вход внутреннего слоя
B=f1(A) # выход скрытого слоя
C=np.dot(B,w2) # вход слоя на выходе
Y=f2(С) # значения на выходе
deltaW2=2*np.dot(B.T, Y*gradf2(C))
deltaW2.shape # (4,1)Вычисление градиента по  развернется в более длинную цепочку, но при этом здесь отсутствуют концептуальные сложности. Просто надо аккуратно двигаться вперед - шаг за шагом.
развернется в более длинную цепочку, но при этом здесь отсутствуют концептуальные сложности. Просто надо аккуратно двигаться вперед - шаг за шагом.

где  . Раздельно вычисляем производные:
. Раздельно вычисляем производные:


Собирая все вместе, получим

где мы использовали очевидные свертки индексов

Действительно,  , индексы
, индексы  и
и  мы не трогаем, поскольку они “говорящие”, так что остается побеспокоиться относительно
мы не трогаем, поскольку они “говорящие”, так что остается побеспокоиться относительно  .
.
Теперь располагаем “говорящие” индексы в нужных местах, что приводит к соотношению

![\delta W^{(1)}=2(X.T)\cdot [[(\widetilde{Y}*f_2^{'}(C))\cdot(W^{(2)}.T)]*f_1^{'}(A)].](https://habrastorage.org/getpro/habr/upload_files/cfb/a83/1aa/cfba831aa8bf857c4c5a7d0da07a17cc.svg)
Действительно, если ввести вспомогательную матрицу  , то при умножении получаем матрицу
, то при умножении получаем матрицу  , и дальше поэлементное умножение
, и дальше поэлементное умножение  .
.
Проверим в коде.
deltaW1=2*np.dot(X.T, np.dot(Y*gradf2(C),w2.T)*gradf1(A))
deltaW1.shape # (3,4)Основным результатом является получение выражения для градиентов. Но это лишь игра с камешками на берегу озера.
“То, что было - нынче сплыло. Прошлое прости-прощай!” А что дальше? Если некоторые термины для вас не знакомы, поройтесь, почитайте, но особо вникать не надо. Хотите научиться шить, для этого не следует годами изучать инструкцию для швейной машинки. Просто надо сесть и попытаться что-нибудь сделать, используя навыки, которыми вы обладаете. Садитесь и шейте! Думаю, если интересуетесь нейронными сетями, уже есть какой-то багаж навыков. Во всяком случае, здесь не место бахвалиться своими знаниями инструкций, как это принято у продвинутых знатоков библиотек.
Итак, что я рекомендую сделать сейчас же. У James Loy - автора статьи , которая и инспирировала настоящие заметки, есть отличная книга, в которую полезно, при желании, заглянуть. К этой книге прилагаются коды . Откройте коды к первой главе, в одном из них увидите воплощение того, чем мы занимались в этих заметках, но только на своих данных. Попробуйте обучить нейронную сеть на собственных данных с другой логикой “вход-выход”, используйте другие функции активации, постройте графики, научитесь выводить время выполнения. Когда надоест баловаться и захочется более лёгкой жизни, значит пришло время связать свою жизнь с TensorFlow и Keras. Для этого много чего есть, но лучше начать с первоисточника (есть перевод на русский).
Пишите коды, вникайте в формулы, читайте книги, задавайте себе вопросы.
Что касается инструментов, то это Jupyter Notebook (Anaconda рулит!), Colab...