https://habr.com/ru/company/yandex/blog/539580/- Блог компании Яндекс
- Ненормальное программирование
- Python
- C++
- Серверная оптимизация
Что связывает языки Python и C++? Как извлечь из этого выгоду лично для себя? На большой конференции Pytup Александр Букин показал способы, благодаря которым можно оптимизировать свой код, а также выбирать и эффективно использовать сторонние библиотеки.
— Всем привет, меня зовут Александр Букин, я разрабатываю Яндекс.Погоду. Вы еще можете знать меня как сооснователя Pytup. Также я состою в программных комитетах таких классных конференций, как PyCon.ru и YaTalks.
Сегодня мы с вами поговорим о любви Python и C++. А точнее — о том, что же их объединяет, эти два прекрасных языка и, на самом деле, еще C, и что мы можем почерпнуть из этих прекрасных отношений.
Дисклеймер: название доклада — это отсылка к прекрасному сериалу «Любовь. Смерть. Роботы» на Netflix. Всем очень советую.
Чтобы разобраться в хитром сплетении двух языков, нам придется вернуться в прошлое. Давным-давно в одной не очень для нас далекой галактике родился герой.

Этот герой был силен, он не по годам хорошо осваивал силу. У него было много мидихлориан. А еще все знали, что этот парень очень быстрый.

Он любил скорость. И, конечно, он рос, развивался, и с годами у него стало появляться больше возможностей, способностей. Он обрастал библиотеками. Его мощь росла. Но в какой-то момент, не очень далекий, он понял, что ему хочется большего, что он стоит на месте, что нужно двигаться. И для этого он решил познать другую сторону, познать мощь ООП и улучшенные стандарты библиотеки. Познав эту мощь, он переродился и стал сильнее, и все мы его узнали как C++.

Но незадолго до этого он успел дать жизнь новому прекрасному герою, нашему любимому Python.

Как мы знаем, их родство — C и Python — прямое. И Python какое-то время был разделен с отцом. Он развивался немного отдельно, хотя отец, конечно, оказывал на него большое влияние. И не все у них хорошо складывалось. Иногда ему даже было сложно принять, что C++ — его папа. Он не всегда с этим хорошо мирился. Шло время, и ему все-таки удалось найти общий язык с отцом. Объединив усилия, найдя эту любовь, Python и C++ вместе одолели зло во вселенной. Их общая мощь оказалась так велика, что никто не мог удержать их.

Я считаю, это прекрасно. Давайте поймем, почему для нас, для разработчиков, это может быть полезно, а не только интересно. Как я и упомянул, C++ всегда был очень быстр, а Python не всегда. Скорее он даже прославился тем, что его производительность в важных задачах иногда страдает. Это как раз то, чем C++ может помочь — ускорить ваш код, некоторые части, которые вы в своих сервисах вызываете действительно часто. Давайте выясним, как это сделать.
Во-первых, дисклеймер: никакой C++ не ускорит код твой лучше тебя. Прежде чем попробовать техники, которые мы обсудим дальше, всегда нужно помнить, что начинаем мы с кода, который написали. Скорее всего, его можно оптимизировать прямо сейчас, просто пройдясь по нему. И прежде чем пробовать сишные хаки, попробуйте просто сделать алгоритм лучше, причесать свой текущий питонячий код. Но если вы это уже сделали, или в вас просто силен дух авантюризма, то приглашаю вас в удивительный мир ускорения Python.
Так как Python написан на C, у него есть довольно большое количество способов интеграции с ним. Сегодня мы рассмотрим два из них — Cython и Native Extension на C/C++. Подробнее остановимся именно на нативных расширениях. Да, там есть еще подмножество. Но, во-первых, эти два — мои любимые. Во-вторых, целого доклада не хватит рассказывать про каждый из них.
Небольшое введение про Cython. Это довольно популярная технология: например, gevent написан с помощью него. Он легко интегрируется в сборку проекта, именно поэтому он мне нравится. У Cython достаточно хорошая документация. Еще для разработчика есть полезная вещь — cythonize. Это оборачивание вашей функции вызов этой функции, который в среднем на синтетических тестах даже дает ускорение в выполнении кода до двух раз.
 Ссылка со слайда
Ссылка со слайда
Понятно, что есть и минусы. Во-первых, хотя Cython, в отличие от других способов, предлагает вам писать на близком к CPython синтаксисе, все равно в мелочах они отличаются. И иногда это мешает. Во-вторых, когда вам всё-таки приходится переключаться на C, его необходимо знать. Но здесь, кстати, необязательно знать его всегда. Конечно же, присутствует наш любимый Segmentation Fault, который можно словить, если плохо поработать с памятью уже в сыром C. Из этого же растут ноги сложностей в дебаггинге. Но если вам не хочется очень глубоко погружаться в C, а хочется попробовать ускорить свою технологию прямо сейчас, Cython — хороший выбор.
Но мы, как говорится, верим в абсолют, поэтому абсолютная сила — это абсолютная скорость. И мы хотим сильно ускорить выполнение, поэтому полезем внутрь.
 Ссылка со слайда
Ссылка со слайда
Полезть внутрь — это как раз использовать нативный Extension. Несмотря на то, что это не самая простая технология, она родная. Ее документация есть прямо в доке Python. Она тоже легко интегрируется в сборку проекта и позволяет создавать свои типы данных. Здесь вам уже никак не обойти необходимость знания C и написания на нем кода. Здесь придется, если вы будете делать что-то сложное, поработать с памятью и поотлаживаться.

Маленький пример. Вот минимальный файл spammodule.c, в котором описывается, как ни странно, модуль спама. Как мы видим, мы подключаем заголовочный файл include Python.h, который понадобится нам для любого модуля. И описываем наш модуль. Говорим, какое у него будет имя, и описываем функцию его инициализации PyInit_spam. Дальше вызываем PyModule_Create, который либо возвращает null, либо возвращает модуль.

Чтобы все это заработало, необходимо всё-таки сбилдить наш модуль. Для этого можно воспользоваться setuptools. Мы пишем небольшой setup.py, в котором указываем, что нам нужен Extension. Говорим, как его называть и откуда брать исходники. Запускаем setup.py build, setup.py install. Можно импортить, можно использовать.
Это пример для C. Пример для С++ выглядит очень похоже.

Просто пишем исходник на плюсах, добавляем sources spammodule.cpp, и указываем, что язык у нас тоже С++. Поздравляю, вы прекрасны. Всего лишь нужно в разделе вашего файла .c или .cpp написать валидный, хорошо работающий, правильно интерпретирующий работу с памятью код на C и на плюсах. Возможно, вы к этому не очень готовы. Может быть, вам просто лень это делать, или вы думаете: я же разработчик, а разработчик не делает своих велосипедов. Наверное, раз это такой родной и давно используемый механизм, уже есть кто-то, кто это сделал. И да, уже есть.
Давайте посмотрим парочку примеров. Например, есть ujson.

Что мы делаем часто, как все разработчики? Перекладываем джейсончики.
Эта библиотека используется довольно легко. У нее есть стандартные функции dumps и loads. И внутри она реализована как раз с помощью Extension. Там парочка C-файлов и оберточка сверху.
Давайте не будем верить мне на слово, что простое добавление C-кода ускоряет файлики. Давайте это побенчмаркаем, посериализуем, десериализуем их. Все измерения, которые я дальше буду показывать, — в миллисекундах.
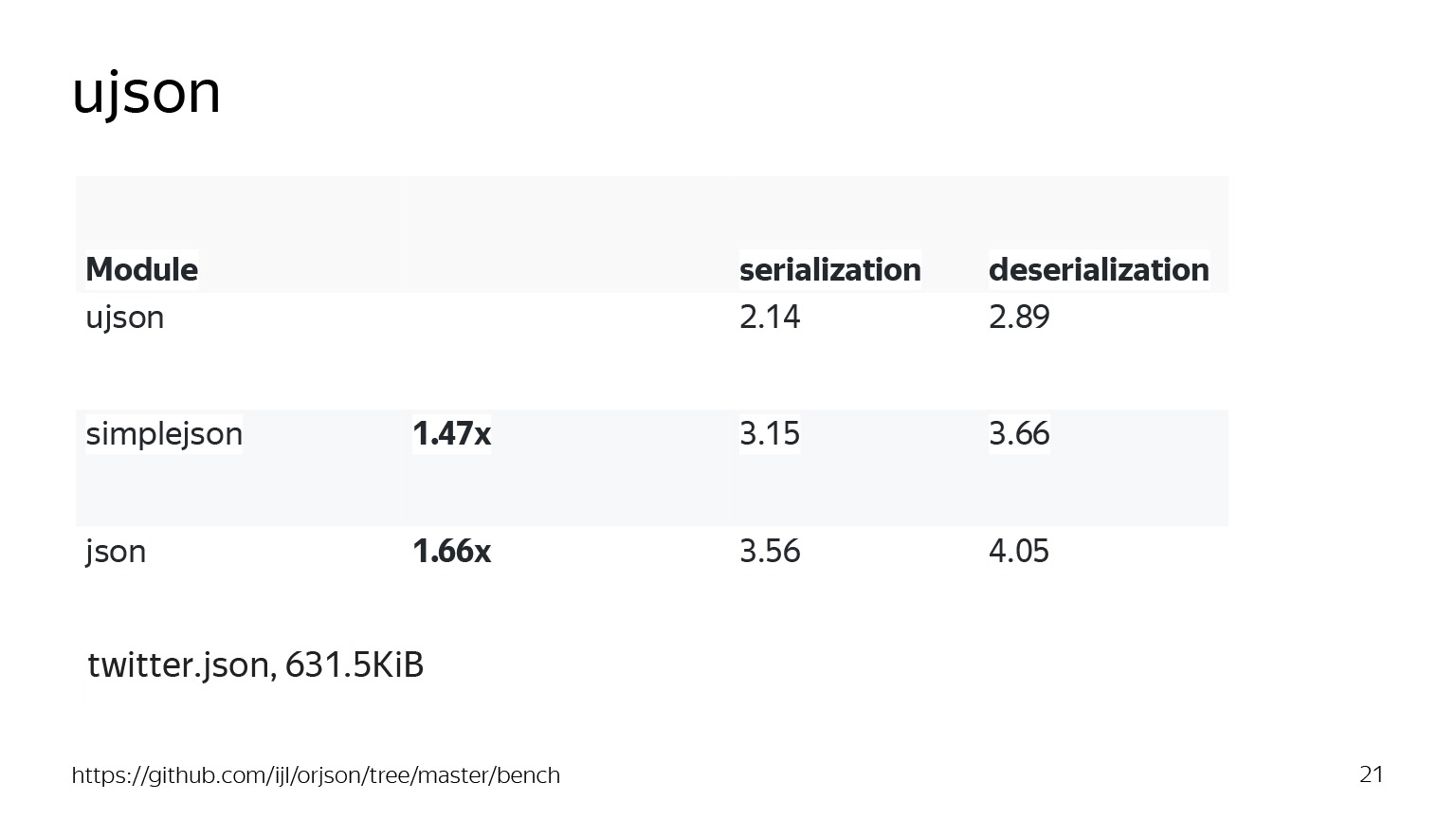
Для начала возьмем не очень большой файл, который возвращает API Twitter, JSON, размером 600 килобайт.
 Ссылка со слайда
Ссылка со слайда
Я взял за основу две очень популярные Python-библиотеки: json и simplejson. Мы получаем, что сериализация и десериализация в районе 3,5 миллисекунд у json и 3,15 у simplejson. Выглядит довольно быстро. Как вы думаете, за сколько это сделает ujson? Допустим, он сделает это за 3 секунды ровно. Может быть, за 2,9. Но на самом деле прирост будет больше. Я добавил ссылку на бенчмарк, и сериализация заняла практически 2 миллисекунды. Как мы видим, прирост в полтора раза, довольно неплохо. Но конечно, хотелось бы большего.
 Ссылка со слайда
Ссылка со слайда
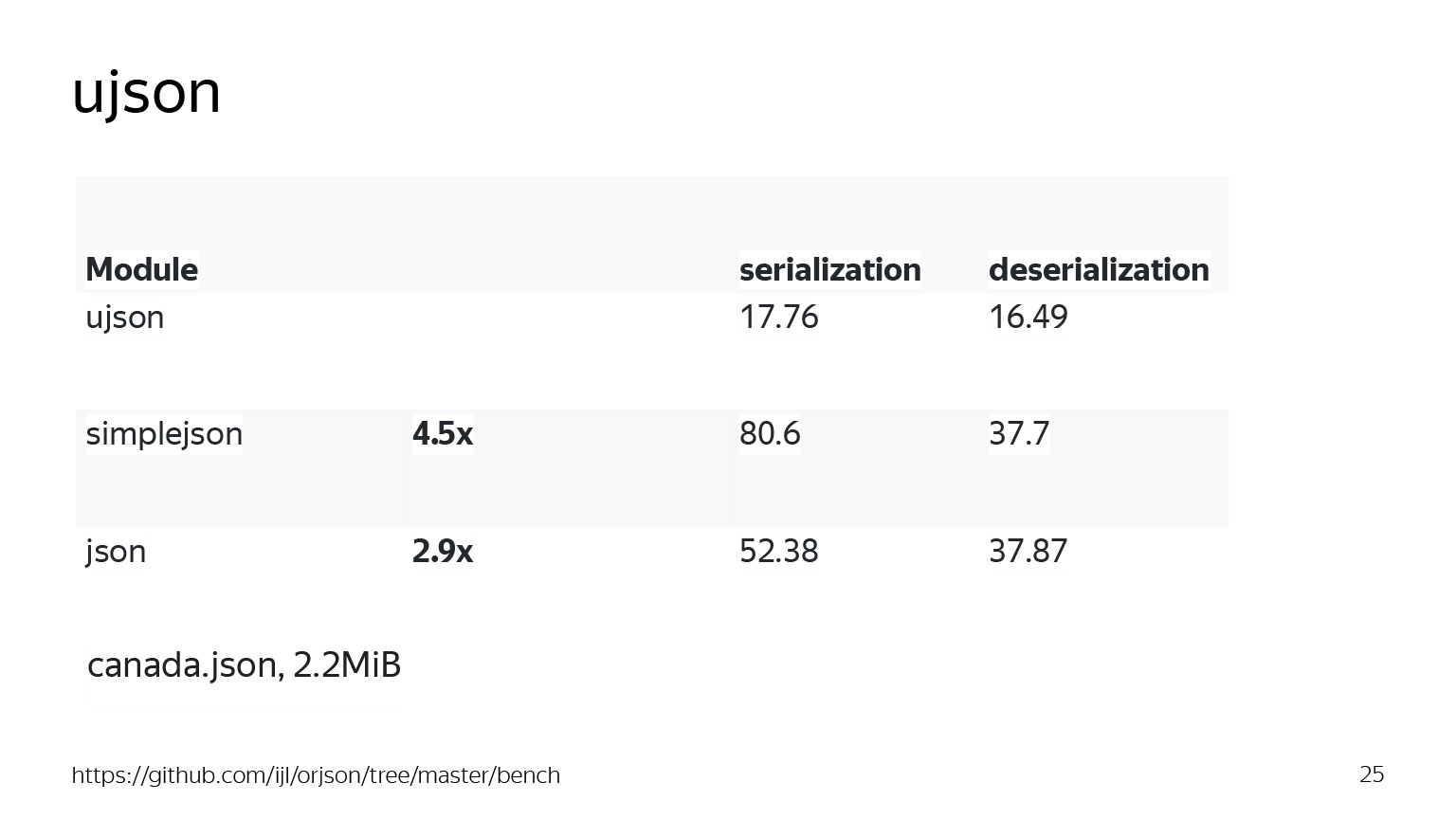
Возьмем файлик побольше — canada.json. Это файл с геоточками на 2 мегабайта. Видим, что тот же simplejson уже работает не так однозначно, ему потребовалось целых 80 миллисекунд на сериализацию. json немножко получше. Но ujson здесь вырывается вперед гораздо сильнее на большом количестве данных, и мы уже получаем прирост в четыре с половиной раза относительно simplejson с сериализацией и в три раза относительно json. Отличный результат.
Я дам вам насладиться этой скоростью. Но есть и ложка дегтя. Понятно, что библиотека ujson не во всем хороша с точки зрения совместимости. Она не поддерживает все типы данных, которые можно сериализовать. Если вы найдете на ее GitHub, то увидите, что там довольно много issues, иногда есть утечки памяти, иногда ошибки. Надо помнить, что ничто не идеально, и смотреть, подходит ли данная библиотека для вашего конкретного варианта.
Но если у вас где-то сериализуется json и ограничения этой библиотеки вам подходят, попробуйте. Возможно, вы будете приятно удивлены.

Посмотрим на задачу, которая часто встречается и которая в Python исторически не очень быстро работает, — парсинг дат. Есть такая библиотека — ciso8601. Она тоже написана с помощью C Extension. Вот так выглядит ее использование. Довольно просто. Есть функция parse_datetime, в которой вы передаете строчку в одном из поддерживаемых форматов. Это парсится в стандартный datetime object. Даже поддерживает тайм-зоны.
Давайте тоже побенчмаркаем. Парсить мы будем вот такую строчку: 2014-01-09T21:48:00. Все измерения, которые получим, будут в микросекундах.
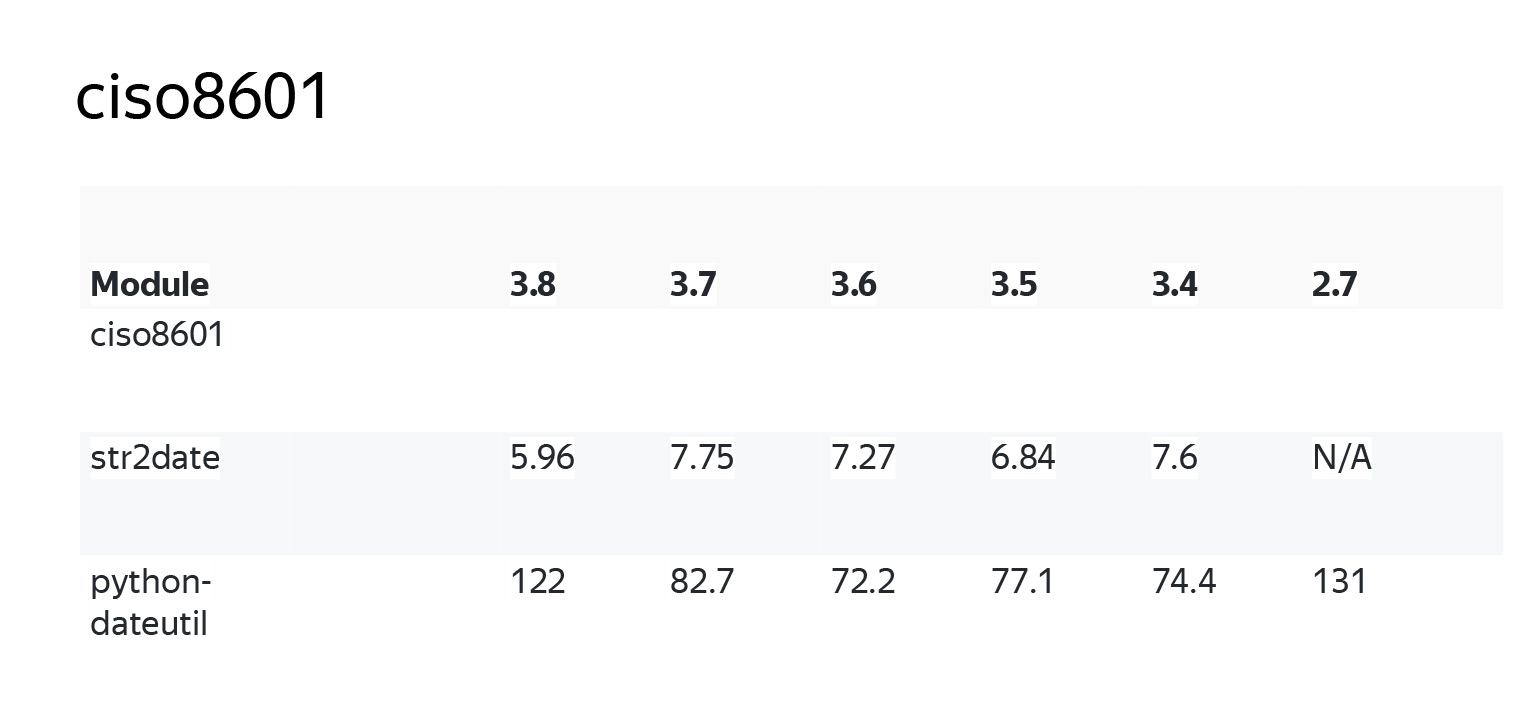
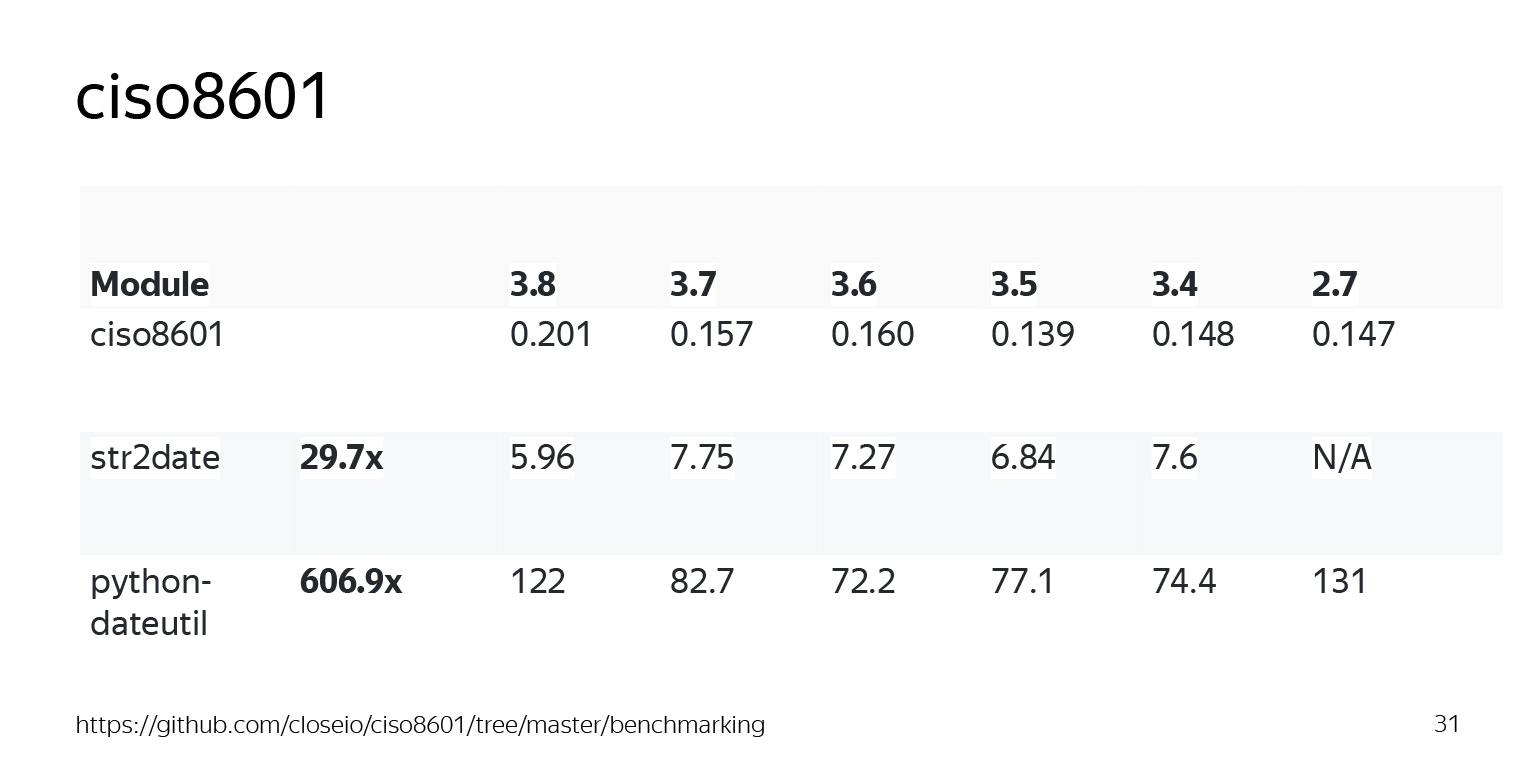
Здесь добавилась еще версия Python. Будет интересно посмотреть на разных версиях, как оно работает. Я взял за основу python-dateutil, который фактически является расширенной стандартной библиотекой datetime, и популярный, но написанный на Python str2date.
python-dateutil на версии Python 3.8 делает это за 122 микросекунды — видите, необычно, что он чуть замедлился относительно 3.7. Гораздо быстрее, на порядок, делает это str2date. Что же может нам предложить ciso? Наверное, будет одна микросекунда.
 Ссылка со слайда
Ссылка со слайда
На самом деле будет меньше одной микросекунды, очень быстро. И даже в одном из худших случаев с версией 3.8 это опережает оригинальный datetime парсер в 600 раз. Если мы возьмем версию 2.7, это будет практически в 1000 раз быстрее.
Это уже производит гораздо более сильное впечатление, чем наш предыдущий бенчмарк с json. И мы задаемся вопросом: наверное, что-то не так, что-то в datetime работает нехорошо. На самом деле нет. Просто у этой библиотеки тоже есть свои минусы с точки зрения поддержки форматов и дебаггинга, если что-то пошло не так.
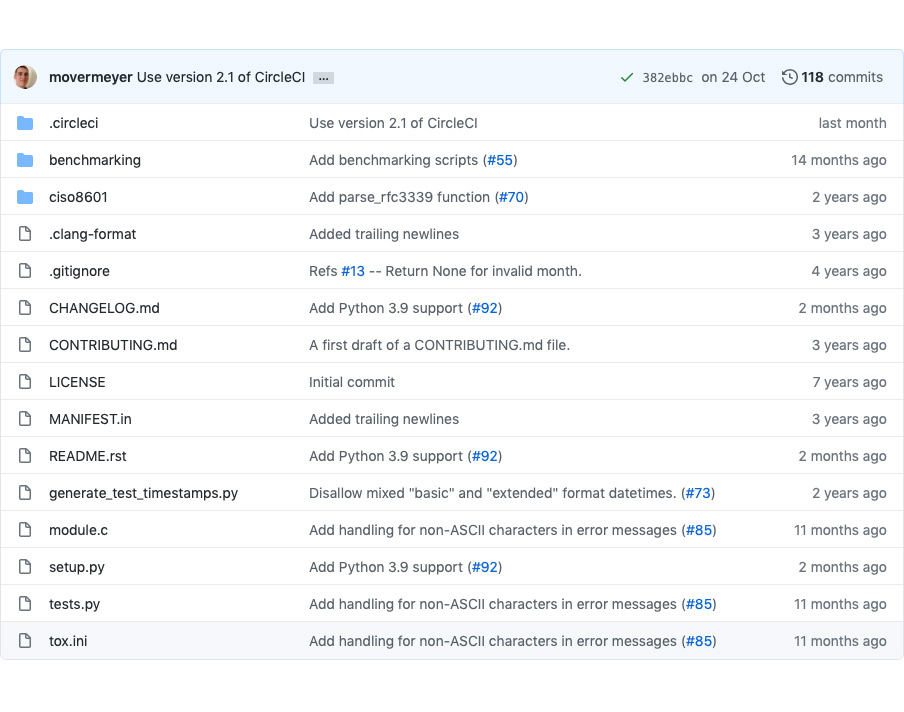
Но давайте взглянем на нее чуть подробнее как на хороший пример C Extension. Вот небольшой проектик. Тут много файликов, но самый важный — module.c. В этом файлике находится весь код этой библиотеки. Это всего один файлик, и он всего на 586 строчек. Второй важный файлик — setup.py. Помните, мы вначале рассматривали spammodule.c. Это точно такая же схема. Есть один C-файлик и один setup.py. Как мы видим, внутри он, конечно, поразвернутее, но вот эта строчка — «Дай мне, пожалуйста, Extension, обзови его вот так, возьми у него исходники» — присутствует и здесь.

Ребята большие молодцы, что не стали усложнять. Это помогает. Так мы затронули то, что, как говорится, можно сделать одной левой. Вы уже сейчас можете просто взять, поменять пару строчек в своем коде, там, где работаете с датами с json, и получить прирост. Я считаю, это замечательно.
Если же ваша задача не настолько простая, ваша функциональность, которая вызывается часто и дает большой прирост, не настолько большая — возможно, стоит попробовать написать самому. Но так как интеграция двух языков усложняет жизнь, я все-таки советую не забывать делать это максимально атомарными вещами и понемножку, чтобы это была маленькая функция.
Немножко о том, где еще можно узнать, что такое расширение для Python, почему они хороши и как его ускорить. В 2018 году у нас на Pytup
выступал Костя Гуков, который рассказывал про расширение на Rust. Там он показывал расширения, которые тоже парсят даты. Забегая вперед, скажу, что они медленнее, чем написанные на C, но тоже очень быстрые. Антон Патрушев на PyCon тоже рассказывал про расширение на Rust:
Как видите, это сейчас довольно популярно. И если вдруг C вам не по душе, а хочется написать расширение, можно посмотреть в эту сторону. Позже Кирилл еще расскажет, как ускорить не конкретно свой код или функцию, а весь Python. И будет ли он ускоряться в принципе в ближайшем будущем. Всем советую послушать.
Давайте подведем небольшие итоги:
- Не забывайте оптимизировать свой код на Python. Это первое, что нужно делать всегда, когда кажется, что что-то может происходить быстрее.
- Если вы провели оптимизацию, попробуйте сторонние библиотеки, которые содержат написанное с помощью C и C++ Extension или с помощью Rust. Возвращаясь немного назад, ujson — не самая быстрая библиотека, есть быстрее: orjson, njson. Попробуйте их.
- И если ваша задача довольно узкая или вам хочется сделать что-то свое, пишите свои расширения, изучайте новые языки для этих расширений. Развивайтесь.
May the Force be with you, друзья.
