Лучший regexp для Go. Benchmark c другими ЯП. Сравнение библиотек
- среда, 23 августа 2023 г. в 00:00:17
"Не используйте регулярки, иначе вместо 1 проблемы, у вас их станет 2!" - как то так говорят знатоки. А что остается делать непослушным, желающим эффективный поиск по большому количеству шаблонов?
Да, для такой довольно специфичной проблемы существуют крутые решения вроде Ragel или re2c. Тем не менее, для своего проекта мне показалось нецелосообразным пока осваивать эти прекрасные технологии.
В этой статье мы рассмотрим альтернативы стандартной библиотеке для регулярных выражений в Go, проведем их бенчмарк по скорости и потребляемой памяти. А также с практической точки зрения рассмотрим различия между ними.
На данный момент можно выделить следующие рабочие альтернативы стандартному regexp, которые можно использовать для нахождения паттернов в Go:
go-re2 - максимально легко заменяет стандартный regexp. Использует C++ re2 для повышения производительности при работе с большими входными данными или сложными выражениями;
regexp2 - многофункциональный движок Regexp для Go. Он не имеет гарантий по времени исполнения, как встроенный пакет regexp, но совместим с Perl5 и .NET;
go-pcre - обеспечивает поддержку Perl-совместимых регулярных выражений с помощью libpcre или libpcre++. Доступна JIT-компиляция, что делает этот форк намного быстрее аналогов. Из минусов - нужно ставить зависимость в виде libpcre3-dev;
rure-go - использует регекс-движкок Rust с помощью привязок CGo. Но есть зависимость от Rust библиотеки, которую необходимо скомплировать;
gohs - regex движок, разработанный с учетом высокой производительности и гибкости. Реализован в виде библиотеки, предоставляющей простой С-API. Тут так же необходимо компилировать и связывать сторонние зависимости;
go-yara - инструмент для помощи в идентификации и классификации образцов вредоносного ПО. Хоть YARA и имеет функционал для шаблонирования и регулярных выражений, но он сильно ограничен, поэтому не буду включать эту библиотеку в тестах далее.
Прежде чем начать сравнивать приведенные решения, стоит показать насколько плохо обстоят дела со стандартной regex библиотекой в Go. Я нашел проект, где автор сравнивает быстродействие стандартных regex движков многих ЯП. Суть этого бенчмарка заключается в многократной прогонке 3 регуляркок над предопределенным текстом. Go в этом бенчмарке оказалсяна 3 месте! С конца...
Language | Email(ms) | URI(ms) | IP(ms) | Total(ms) |
|---|---|---|---|---|
Nim Regex | 1.32 | 26.92 | 7.84 | 36.09 |
Nim | 22.70 | 21.49 | 6.75 | 50.94 |
Rust | 26.66 | 25.70 | 5.28 | 57.63 |
... | ... | ... | ... | ... |
Python PyPy3 | 258.78 | 221.89 | 257.35 | 738.03 |
Python 3 | 273.86 | 190.79 | 319.13 | 783.78 |
Go | 248.14 | 241.28 | 360.90 | 850.32 |
C++ STL | 433.09 | 344.74 | 245.66 | 1023.49 |
C# Mono | 2859.05 | 2431.87 | 145.82 | 5436.75 |
Насколько я понял, бенчмаркинг регекс движков не самая простая тема и нужно знать детали имплементаций и алгоритмов для корректного сравнения.
Из других бенчмарков можно выделить следующие:
Benchmarks Game - сравнение движков с оптимизированными версиями под каждый ЯП. Например здесь Go уже не в конце, но и далек от идеала... И конечно же не использует нативную библиотеку, а обертку над PCRE - go-pcre, которую указывал в аналогах.
Performance comparison of regular expression engines - сравнение различных regex движков (PCRE, PCRE-DFA, TRE, Oniguruma, RE2, PCRE-JIT).
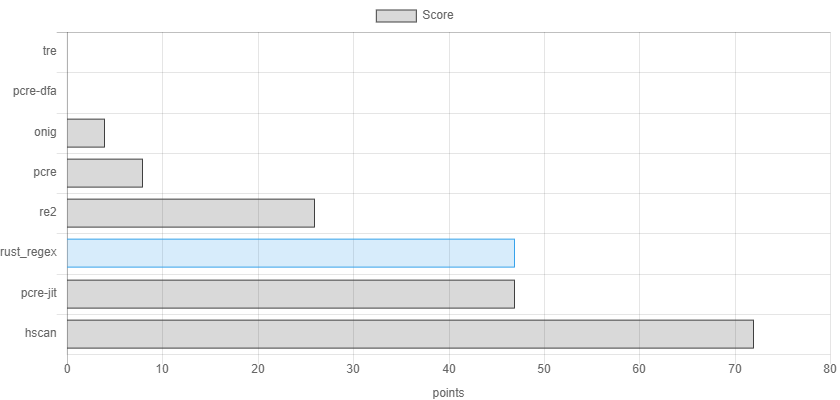
A comparison of regex engines - тут автор пытается сравнить движки используя различные регулярки, которые могут представлять сложности в зависимости от имплементации движка. В этом бенчмарке автор в тройку лучших движков выделяет: Hyperscan, PCRE c JIT компиляцией и Rust regex (rure использует его):
Давайте попробуем теперь сравнить приведенные в аналогах библиотеки с дефолтными regex движками других ЯП. А также посмотрим насколько они будут быстрее стандартного Go regex. Для этого я обновил вышеупомянутый проект, добавив код с новыми библиотеками. Вот что получилось после прогонки на моей машине:
Language | Email(ms) | URI(ms) | IP(ms) | Total(ms) |
|---|---|---|---|---|
Go Rure | 2.61 | 2.11 | 3.33 | 8.05 |
C++ SRELL | 1.74 | 3.03 | 10.67 | 15.45 |
Rust | 11.95 | 0.96 | 3.05 | 15.96 |
Nim | 13.98 | 14.35 | 3.13 | 31.46 |
PHP | 14.43 | 14.63 | 4.87 | 33.93 |
Go PCRE | 14.18 | 14.98 | 6.21 | 35.37 |
C# .Net Core | 10.83 | 5.10 | 26.71 | 42.64 |
Javascript | 42.78 | 30.17 | 0.92 | 73.87 |
Go Re2 | 35.81 | 37.86 | 33.79 | 107.46 |
Go Hyperscan | 90.17 | 31.64 | 8.68 | 130.49 |
Perl | 92.51 | 66.42 | 22.51 | 181.44 |
Dart | 73.48 | 63.60 | 80.52 | 217.59 |
C PCRE2 | 109.73 | 101.05 | 10.95 | 221.72 |
Kotlin | 120.31 | 163.53 | 293.69 | 577.53 |
Java | 205.14 | 201.55 | 295.68 | 702.36 |
Python 3 | 246.26 | 176.01 | 303.08 | 725.34 |
C++ STL | 328.87 | 273.43 | 230.35 | 832.64 |
Go | 270.19 | 275.73 | 504.79 | 1050.71 |
Go Regexp2 | 1703.51 | 1482.60 | 64.46 | 3250.57 |
C# Mono | 2543.82 | 2139.44 | 110.37 | 4793.64 |
Ps. Немного сократил таблицу, поэтому прошу на форк проекта, чтобы посмотреть все результаты.
Pss. В данном случае на результаты могла повлиять виртуализация (тесты проводились в среде Docker на Windows 11).
Тем не менее, видно насколько быстрее могут быть регулярки с некоторыми библиотеками! Мы даже обогнали Rust библиотекой на Go, которая использует библиотеку Rust 🥴🙆🏼♂️. Возможно это нам пытается объяснить автор данного решения в своем репозиторие.
В результате, почти все альтернативные решения дают нам прирост в скорости в 8-130 раз! За исключением Regexp2, который оказался медленней стандартной библиотеки.
Изучая уже существующие бенчмарки и результаты Бенчмарка#1, мне не хватило ответов на следующие вопросы:
Насколько быстро приведенные библиотеки будут обрабатывать большие файлы?
Насколько быстрее будет обработка при группировке регулярных выражений?
Как быстро будут прогоняться регулярки без совпадений в тексте?
Сколько памяти потребляют разные библиотеки?
Сколько регулярок я смогу скомпилировать при группировке?
Для ответов на эти вопросы я написал небольшую программу для бенчмаркинга, с помощью которой можно сравнить разные regex движки по их быстроте и используемой ими памяти. Если хотите потестить сами или оценить верность используемых методов, то вот код.
Стоит выделить следующие особенности этого бенчмарка:
В тестах ниже я использовал 5 различных регулярных выражений:
allRegexps["email"] = `(?P<name>[-\w\d\.]+?)(?:\s+at\s+|\s*@\s*|\s*(?:[\[\]@]){3}\s*)(?P<host>[-\w\d\.]*?)\s*(?:dot|\.|(?:[\[\]dot\.]){3,5})\s*(?P<domain>\w+)`
allRegexps["bitcoin"] = `\b([13][a-km-zA-HJ-NP-Z1-9]{25,34}|bc1[ac-hj-np-zAC-HJ-NP-Z02-9]{11,71})`
allRegexps["ssn"] = `\d{3}-\d{2}-\d{4}`
allRegexps["uri"] = `[\w]+://[^/\s?#]+[^\s?#]+(?:\?[^\s#]*)?(?:#[^\s]*)?`
allRegexps["tel"] = `\+\d{1,4}?[-.\s]?\(?\d{1,3}?\)?[-.\s]?\d{1,4}[-.\s]?\d{1,4}[-.\s]?\d{1,9}`
По хорошему, следовало бы использовать хитровынаписанные регулярки, как это делают авторы других бенчмарков - для того чтобы проверить "слабые" места алгоритмов. Но я не сильно разбираюсь в подкопотных деталях движков и взял простые регулярки из народа. Поэтому, думаю, должно получиться оценить различные параметры библиотек сразу с практической точки зрения.
Вместо статичного файла будет использоваться строка, содержащая наши матчи, которая будет многократно повторена в памяти для симуляции файлов разного размера:
var data = bytes.Repeat([]byte("123@mail.co nümbr=+71112223334 SSN:123-45-6789 http://1.1.1.1 3FZbgi29cpjq2GjdwV8eyHuJJnkLtktZc5 Й"), config.repeatScanTimes)
Дополнительно к последовательному прогону регулярок по данным, будет производится отдельный, с именованной группировкой регулярных выражений, где в итоге они примут следующую форму:
`(?P<имя_1>регулярка_1)|(?P<имя_2>регулярка_2)|...|(?P<имя_N>регулярка_N)`
К слову, в Hyperscan имеется специальный функционал, где мы можем собрать базу из регулярок и использовать их на данных. В тестах буду использовать этот способ.
В отличие от Бенчмарка#1, для каждой регулярки я буду замерять время нахождения результата без учёта времени их компиляции;
В итоге мы получим результаты для каждой библиотеки и каждой регулярки в следующем виде:
Generate data...
Test data size: 100.00MB
Run RURE:
[bitcoin] count=1000000, mem=16007.26KB, time=2.11075s
[ssn] count=1000000, mem=16007.26KB, time=62.074ms
[uri] count=1000000, mem=16007.26KB, time=69.186ms
[tel] count=1000000, mem=16007.26KB, time=83.101ms
[email] count=1000000, mem=16007.26KB, time=172.915ms
Total. Counted: 5000000, Memory: 80.04MB, Duration: 2.498027s
...
Под "большим файлом" я буду понимать сгенерированный из нашей предопределенной строки объем данных в памятий равный 100МБ. Конечно же, это трудно назвать большим файлом, но не хотелось бы ждать часами результатов в некоторых случаях 😅.
Так же, есть смысл попробовать сгруппировать все регулярные выражения в одно и посмотреть насколько это отразится на производительности. Гипотеза заключается в том, что последовательная прогонка регулярок по данным должна быть дольше, чем один прогон с помощью сгруппированной регулярки.
Чтож, давайте запустим бенчмаркер и посмотрим на то как быстро отдельные библиотеки будут обрабатывать данные. Сделать это с помощью тулзы можно написав:
# Бенч всех либ, повторяем строку 1000000 раз (100МБ)
regexcmp 1000000
# Бенч отдельной либы
regexcmp 1000000 rure
В итоге имеем следующие результаты:
Lib | Tel | URI | SSN | Bitcoin | Total | Total-group | |
|---|---|---|---|---|---|---|---|
Rure | 0.173s | 0.083s | 0.069s | 0.062s | 2.11s | 2.49s | 10.13s |
PCRE | 49.5s | 0.367s | 2.92s | 2.07s | 2.19s | 57.07s | 9.94s |
Re2 | 0.954s | 0.63s | 0.956s | 0.945s | 1.05s | 4.54s | 3.24s |
Hyperscan | 0.469s | 1.09s | 0.669s | 0.174s | 1.97s | 4.38s | 4.97s |
Regexp2 | 126.4s | 1.02s | 21.51s | 2.63s | 3.38s | 154.9s | 20.65s |
Go regexp | 11.22s | 1.52s | 3.62s | 2.66s | 3.32s | 22.36s | 26.49s |
На графике отобразил время обработки 100МБ данных всеми регулярками в последовательном режиме и с помощью группы:

Выводы:
Группировка действительно может значительно улучшить скорость исполнения, но в некоторых случаях и ухудшить :);
Самым быстрым в последовательной обработке оказался - Rure, с группировкой - Re2;
Определенные регулярки могут вызывать труднусти у некоторых библиотек (время нахождения email у Regexp2 и PCRE);
Сейчас уже не получится сказать, что некоторые решения быстрее стандартной библиотеки в 180 раз, максимальный прирост x8-9.
В предыдущем случае мы симулировали идеальную ситуацию, когда в данных всегда встречаются совпадения. Но а что, если в тексте не будет матчей для регулярки, насколько это отразится на производительности?
В этом тесте я дополнительно добавил 5 видоизменненных регулярок для SSN, которые не матчятся с тестируемыми данными. В данном случае под SSN мы будем иметь в виду \d{3}-\d{2}-\d{4} регулярку, а под Non-matching - \d{3}-\d{2}-\d{4}1. Не сильное отличие? Но давайте посмотрим как это скажится на времени нахождении всех совподений:
Lib | SSN | Non-matching | Total | Total-group |
|---|---|---|---|---|
Rure | 0.06s | 0.083s | 2.93s | 15.68s |
PCRE | 2.06s | 4.21s | 81.02s | 13.52s |
Re2 | 0.960s | 0.449s | 6.75s | 3.26s |
Hyperscan | 0.175s | 0.043s | 4.61s | 4.94s |
Regexp2 | 2.73s | 3.09s | 171.1s | 15.72s |
Go regexp | 2.66s | 2.57s | 35.13s | 37.66s |
На графике показал, затраченное время на обработку всех 10 регулярок, с сортировкой по времени обработки Non-matching:

Выводы:
В этот раз так же: самым быстрым в последовательной обработке оказался - Rure, с группированными выражениями - Re2;
PCRE снова отличается, с 2х временем на обработку non-matching регулярок в последовательном режиме;
Некоторые алгоритмы наоборот, значительно быстрее справляются в случае отсутствия совпадений (Re2, Hyperscan);
А теперь посмотрим сколько памяти затрачивают различные решения при обработке 100МБ файла. Ниже предоставил результаты для каждой отдельной регулярки и общий объем затраченной памяти:
Lib | Email, MB | Tel, MB | URI, MB | SSN, MB | Bitcoin, MB | Non-matching, KB | Total, GB | Total-group, GB |
|---|---|---|---|---|---|---|---|---|
Rure | 16 | 16 | 16 | 16 | 16 | 0.0001 | 0.08 | 0.08 |
PCRE | 186 | 186 | 186 | 186 | 186 | 0.38 | 0.93 | 0.9 |
Re2 | 254 | 254 | 254 | 255 | 254 | 100473 | 1.77 | 0.97 |
Hyperscan | 314 | 314 | 314 | 314 | 314 | 0.68 | 1.57 | 1.7 |
Regexp2 | 997 | 854 | 854 | 854 | 902 | 396006 | 6.44 | 5.23 |
Go regex | 191 | 144 | 144 | 160 | 208 | 3.62 | 0.78 | 1.8 |
На графике показал затрачиваемую библеотками память на обработку 10 регулярок (как и в прошлом тесте), с сортировкой по затратам на non-mathcing:

Выводы:
Rure удивляет практическим отсутствием потребляемой памяти;
Regexp2 напротив сильно прожорлив, потребляя значительно больше памяти среди конкуретнов;
Re2, несмотря на свою быстроту, оказался не самым экономичным в плане памяти решением;
Go regex показывается себя с хорошой стороны в данной случае, с относительно невыскоими затратами в последовательном режиме.
На основные вопросы ответы вроде бы получены. А давайте теперь посмотрим максимальный объем регулярки, которой мы можем скомпилировать с разными решениями. В данном случае мы возьмем отдельную регулярку и многократно повторим её в группах.
Для данной ситуации я буду использовать URI regexp:
`[\w]+://[^/\s?#]+[^\s?#]+(?:\?[^\s#]*)?(?:#[^\s]*)?
Далее я привел результаты компиляции регулярок, с затраченными на них памятью. Тут цифры в первой строке это количество URI выражений в группе:
Lib | 100 | 250 | 500 | 1000 | 5000 | 10000 |
|---|---|---|---|---|---|---|
Rure | 0.38MB | ❌ | ❌ | ❌ | ❌ | ❌ |
PCRE | 0.40MB | 2.37MB | ❌ | ❌ | ❌ | ❌ |
Re2 | 7.10MB | 15.51MB | 38.35MB | 92.79MB | 1181MB | ❌ |
Hyperscan | 0.03MB | 0.06MB | 0.12MB | 0.25MB | 1.21MB | 2.52MB |
Regexp2 | 1.06MB | 3.96MB | 12.56MB | 43.93MB | 926MB | 3604MB |
Go regex | 1.29MB | 4.52MB | 14.02MB | 47.18MB | 942MB | 3636MB |
Выводы
Как мы видим, некоторые решения имеют ограничения на объем компилируемых регулярных выражений;
Hyperscan не только позволяет использовать большое количество регулярок, но и затрачивает минимальное количество памяти на регулярки в скомпилированном состоянии;
Regexp2 и Go regex имеют сопоставимые затраты на память, и так же позволяют компилировать большое количество регулярок;
Re2 затрачивает наибольшее количество памяти при компиляции.
Надеюсь вам было полезно узнать про альтернативные решения для регулярок на Go и исходя из данных, которые я привел, каждый сможет сделать для себя определенные выводы, которые позволят выбрать наиболее подходящее для вашей ситуации Regex решение.
Можно долго и в деталях сравнивать эти библиотеки, алгоритмы которые они используют, их лучшие\худшие стороны. Своим "топорным" сравнением я лишь хотел показать разницу между ними в самых общих случаях.
Таким образом, для максимального ускорения регулярок я бы посоветовал обратить внимание на Rure-Go, но если вам нужна наиболее простая установка библиотеки без зависимойстей, то есть Go-Re2. А в случае с обработкой большого количества регулярок хорошим выбором будет Hyperscan. Также не стоит забывать про затраты на использование CGo в некоторых библиотеках.
Что касается меня, то несомненной использую полученные "открытия" в своем будущем проекте. Если кому-то была интересная тема, то предлагаю подписаться тут или на Гитхабе :).