https://habrahabr.ru/company/yandex/blog/341192/- Яндекс API
- Совершенный код
- Open source
- JavaScript
- Блог компании Яндекс
В процессе выхода на международный рынок с API Карт мы решили отказаться от комментирования кода на русском языке. При этом на основе комментариев формируются справочники сервиса, которые затем публикуются у нас на портале, и отказываться от поддержки справочников на русском языке мы не хотели. Из доклада Олеси Горбачевой и Максима Горкунова вы узнаете, как технические писатели Яндекса совместно с разработчиками API Карт поменяли язык комментариев и организовали синхронную поддержку справочников и примеров сразу на двух языках.
— Меня зовут Олеся, я занимаюсь документированием API Карт. Выступать я буду не одна, со мной будет мой коллега Максим — ответственный за инструменты локализации в Яндексе.
Сегодня мы расскажем о том, как мы поменяли язык в комментариях в коде JS API карт. Что мы сделали? Все комментарии, которые были на русском языке в коде, поменяли на английские комментарии. По ходу доклада мы расскажем, почему пришлось переводить комментарии в коде, в чем сложность этой задачи, и как это повлияло на нашу систему автогенерации документации из кода. Нам пришлось переводить не просто комментарии в коде, а документационные, на основе которых мы формируем и публикуем справочники API в Яндексе. Над этой задачей трудились не только служба документации и локализации, но и команда API Карт, эти веселые ребята являются заказчиками задачи, виновниками торжества.
Как возникла задача перевода комментариев в коде? Вернемся в прошлое, когда код еще документировался на русском языке. На прошлом Гипербатоне в прошлом году я уже рассказывала, что для документирования кода у нас используется инструмент JSDoc.

Разработчики размечали код на русском языке в соответствии с требованиями JSDoc. Я при необходимости эти требования вычитывала, вносила правки и коммитила в код.
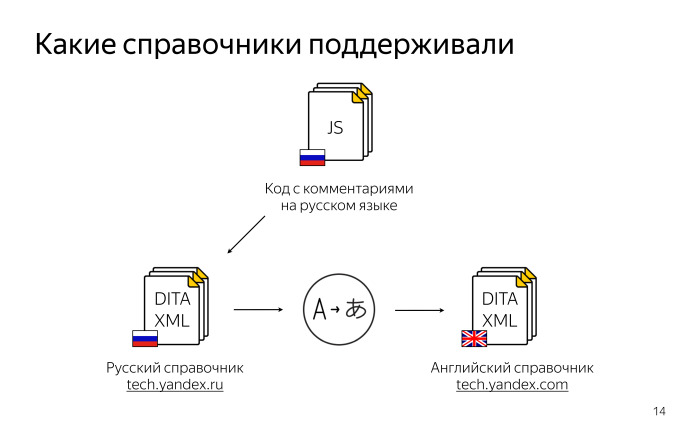
Какие справочники мы поддерживали? В первую очередь, код на русском языке. DITA XML — это формат представления нашей документации, подробнее об нем — в
докладе Леши Миронова. Вот пример собранного справочника, который можно посмотреть
здесь.
Мы поддерживали не только русский справочник, но и английский. Собранный русский справочник мы отдавали на перевод и получали справочник на английском. Его тоже опубликовали, но уже
на домене com.
С английским справочником была некая проблема. Правки в комментарии вносятся достаточно часто. В API достаточно короткий релизный цикл. И если русский справочник мы можем публиковать оперативно, хоть каждый день, то каждый день отдавать его на перевод мы себе позволить не могли.
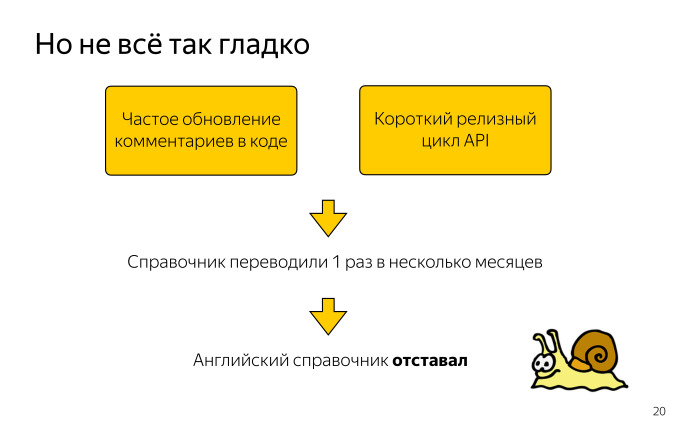
Поэтому мы накапливали пачку изменений и отдавали справочник на перевод раз в несколько месяцев. И английский справочник отставал от русского. На тот момент русская документация была более приоритетной, и для нас это было приемлемо.
Время шло, API Карт развивался, и рост аудитории в мире стал значительным.
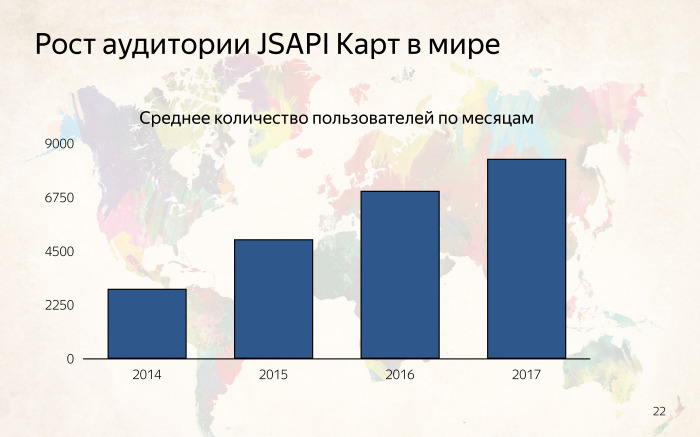
Нам чаще стали писать люди из разных уголков планеты с вопросом об использовании API Карт и вопросами к документации — почему у нас там устаревшая версия. В тот момент мы начали задумываться, полгода назад, что, во-первых, Яндекс — международная компания, а API карт — масштабный проект. И любой пользователь в мире может открыть код и увидеть русские комментарии. Это неправильно.
Кроме того, на тот момент разработчики стали выпускать для работы с API
внешние модули, которые лежат на GitHub, и документация к ним сразу пишется на английском. И давайте не забывать про отставание английского справочника. Взвесив все это, мы подумали, что надо переводить все комментарии на английский, и дальше писать уже сразу на английском.
В чем сложность задачи? Мы подсчитали, что на тот момент в коде API карт было ровно 4703 комментария. Некоторые из них достаточно большие. Это один фрагмент, один комментарий. Они не все такие длинные, но тем не менее.


Все это нужно было перевести. И перевести не с нуля. За многие годы перевода справочника мы накопили огромную память переводов, которую мы умели использовать только при переводе обычных XML-документов. Нам хотелось научиться применять эту память для перевода комментариев в коде.
Нам не хотелось переводить вручную. Мы не хотели руками копировать, переводить и обратно копировать в код 4700 комментариев. Мы хотели автоматически извлекать комментарии, и на их места вставлять перевод, сохраняя скелет JS-документа, все JSDoc-теги, их валидность, ну и не ломая сам код. О том, как мы это делали, расскажет Максим.
— Добрый день. Добавлю технических деталей, расскажу, как эта задача выглядела с точки зрения локализационного инженера.
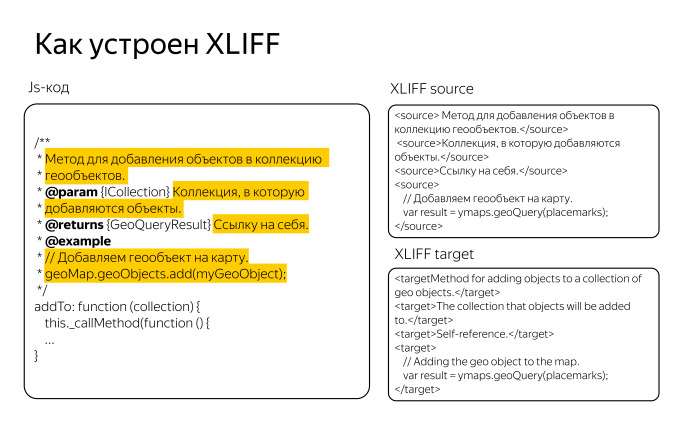
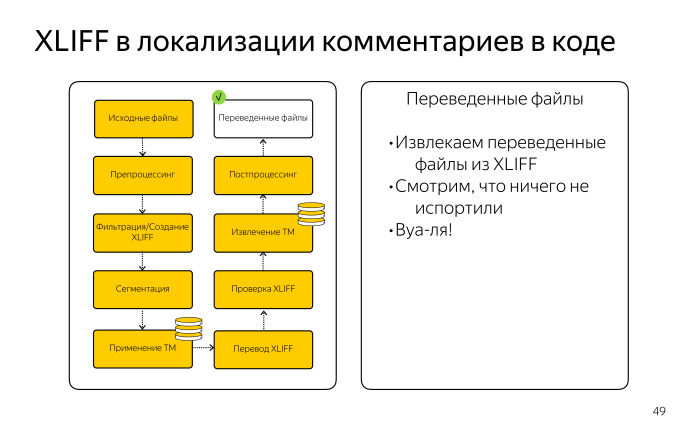
Нам надо было найти в JS-коде все описания классов, объектов и методов, потом текстовые описания ко всем параметрам и представить весь этот текст в виде XLIFF-файла. В Яндексе мы все стремимся переводить через XLIFF, у нас для этого отлажены процессы, существуют фермы переводов, сервер для хранения translation memory, ТМ. Фактически нужно было из всех JS-скриптов сделать XLIFF и перевести его в Cat tool. Для этой задачи мы использовали Okapi Framework, мощный опенсорсный инструмент, который мы применяем для автоматизации задач локализации.
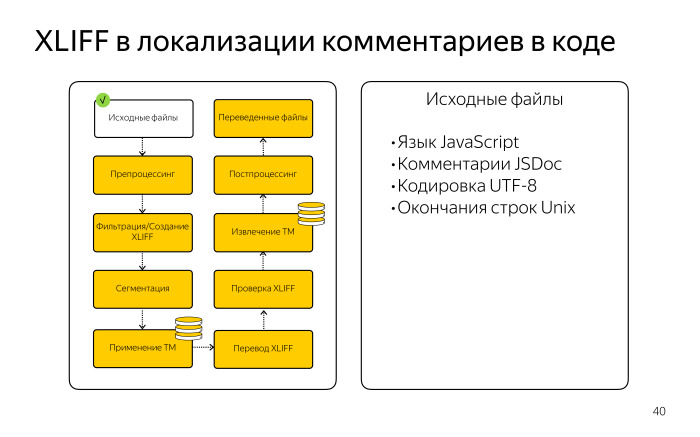
Мы брали исходный JS-файл из репозитория, убеждались, что он удовлетворяет требованиям, кодировке UTF-8, одинаковому окончанию строк — это важно для работы Cat tool.
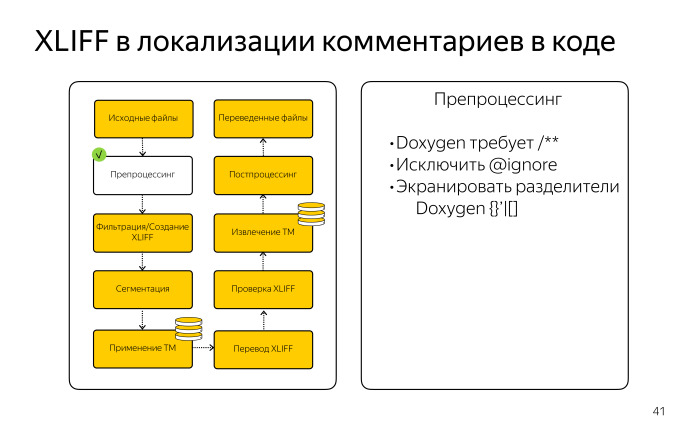
Дальше нужно было их подготовить, чтобы применить один из фильтров Okapi. Хотя JSDoc — самый мощный инструмент для документирования JS-файлов, готового фильтра для него не существует. Нам пришлось как-то выкручиваться. Мы использовали ближайший по смыслу фильтр из набора Okapi Framework, который извлекает комментарии Doxygen. Это другая система документирования кода, которая в основном используется для комментариев в С++, Java- и, возможно, в Python.
Формат этих комментариев очень схож. Фактически нам надо было подделать эти JS-файлы, привести их такому виду, который ожидал Doxygen-фильтр. Различия заключались в основном в звездочках, слэшах. Допустим, требовалось три слэша для отбивки комментария, а не два, звездочек тоже должно быть две, а не одна. Мы немного видоизменили этот код. С точки зрения программистов он тогда стал невалидным, но поскольку эти фильтры его не разбирают, это все равно что текстовый файл, то нам это было неважно.
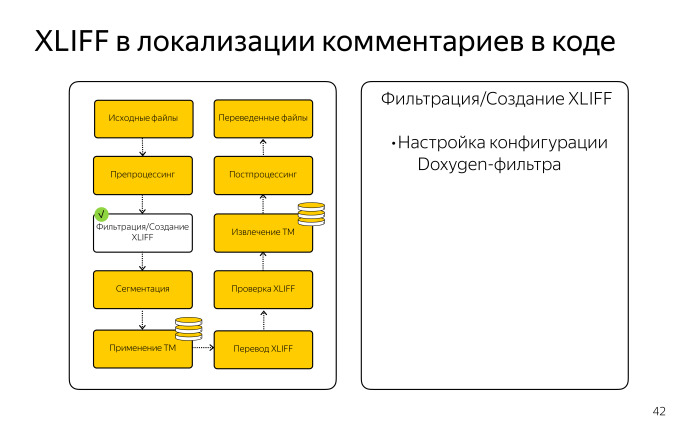
Мы настроили конфигурации, прописали все параметры JSDoc, чтобы выдирать из них только текст. Нас не интересовали служебные программистские вещи, нас интересовал только русский текст.
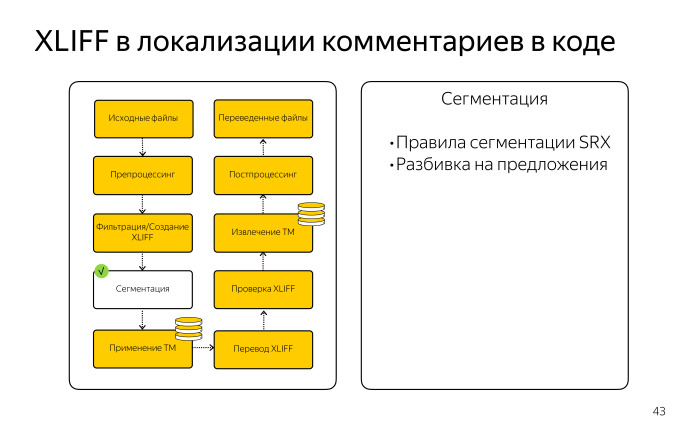
Дальше мы изготовили пайплайн. В терминологии Okapi Framework это последовательность шагов, которая приведет нас к созданию XLIFF. Далее был шаг сегментации. У нас существуют правила в виде файлов SRX для русского языка, которые позволяют разбить большие блоки текста на отдельные предложения. Это повышает процент совпадения из ТМ, поскольку фрагменты памяти становятся мельче.
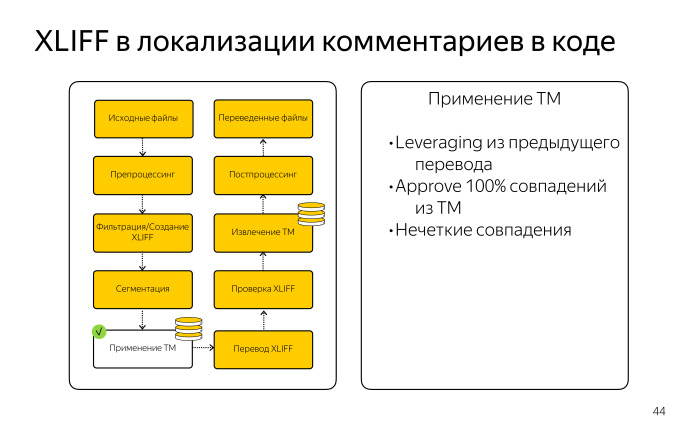
Дальше мы применили имеющийся ТМ, который у нас остался из справочника, получили нечеткие и четкие совпадения и дальше переводили полученный огромный XLIFF-файл в Cat tool.
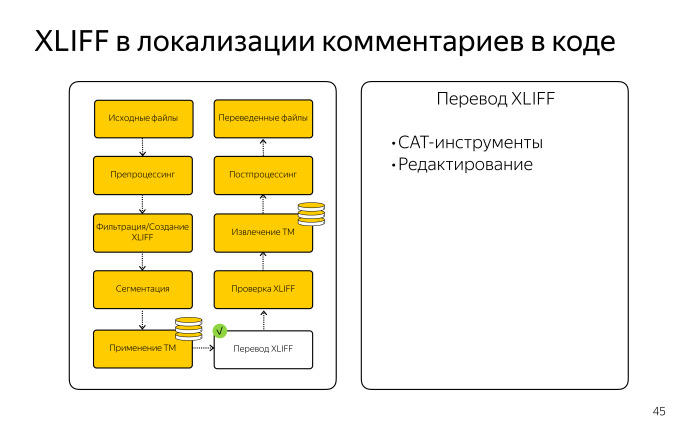
Здесь мы использовали XLIFF-файл, поскольку он хорошо дружит с Okapi, и эти XLIFF можно переводить в онлайн-инструменте.
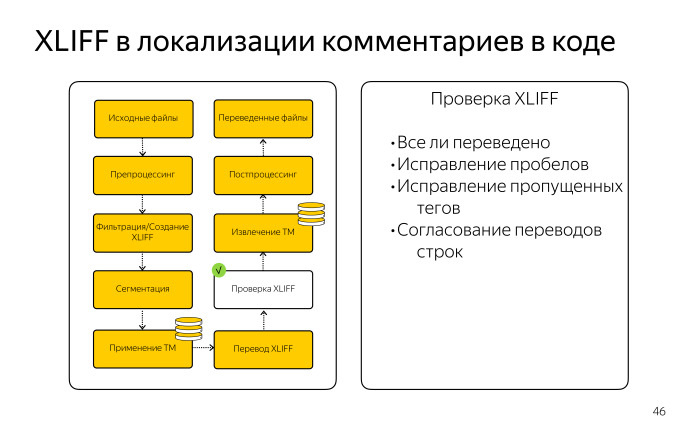
Дальше нужно было отредактировать полученный перевод и проверить, все ли получилось, на месте. Тут была довольно сложная задача из-за специфики комментариев и отбивки звездочками. Нужно было убедиться, что если в нашем варианте было пять строчек, то и в переводе должны быть те же пять строк, иначе разъедется огромная простыня, будет нарушено форматирование. Для этого мы написали специальную исправлялку пропущенных пробелов, переводов строк, а также хитро проверяли наличие инлайновых тегов. Если что-то было пропущено — подставляли их из source.

Затем мы извлекли полученную ТМ для дальнейшего использования.
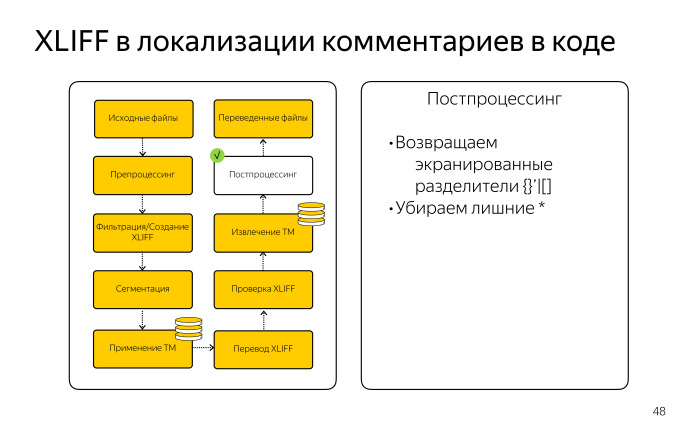
Нам нужно было сделать постпроцессинг, целиком зеркальный препроцессингу. Мы должны были получить обратно валидный JS-файл, убрав все то, что было нужно для работы фильтра Doxygen.
В итоге мы получили тот же самый набор JS-файлов, но все комментарии уже были на английском языке. Разработчики команды Карт написали тесты и убедились, что все наши изменения происходили только в тех областях, где находились комментарии, то есть никакой код мы не попортили. Вот такое было приключение.

— В качестве демонстрации — фрагмент из текущего исходника кода. Но на этом задача еще не была решена до конца. Нужно было продумать, кто будет редактировать английские комментарии в коде, и главное — как?
И нам нужно было адаптировать систему автогенерации, ведь язык комментариев теперь изменился. Как мы это решали? Редактором переводов мы выбрали нашего переводчика Эми. Эми переводит практически всю техническую документацию в Яндексе, в частности API Карт. Разработчики карт хотели упростить Эми жизнь по максимуму. Они не хотели, чтобы Эми отслеживала вручную все изменения в коде, в комментариях, и чтобы ей не пришлось самой работать в консоли с командами Git.
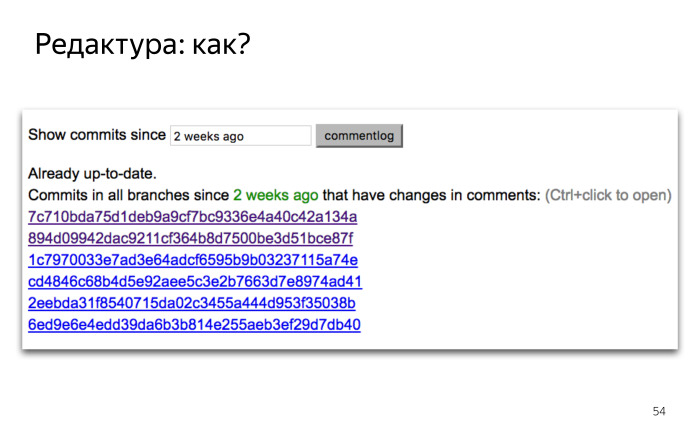
Поэтому ребята написали простенький скриптик на Node.js, где Эми вбивает дату, и ей выводится список всех коммитов в коде за это время, которые содержат именно правки в комментарии.
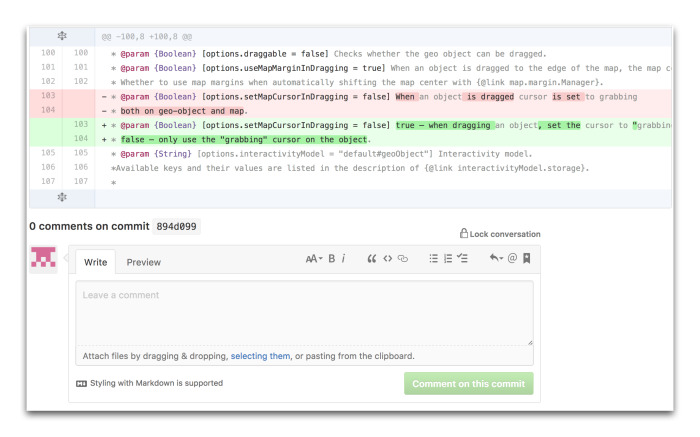
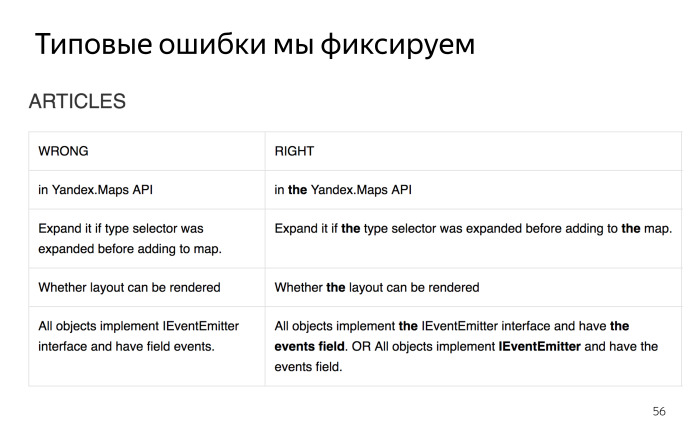
Например, Эми переходит по одному из них, попадает в интерфейс нашего внутреннего GitHub, и там зелененьким подсвечивается, какие правки были внесены в комментарий. Эми вычитывает, по необходимости правит, и коммитит в код прямо по кнопке. Все просто. Конечно, здесь нужно быть аккуратным, чтобы не закоммитить ничего лишнего. Также Эми фиксирует все типовые ошибки, которые мы совершаем, вычитывая код. Речь про ошибки, которые мы совершаем при написании текстов на техническом английском. Здесь пример с ошибками в артиклях, но таких табличек намного больше. Это хорошая практика для того, чтобы в будущем избежать подобных ошибок.
Как мы настраивали и адаптировали систему автогенерации. Давайте вернемся в прошлое и представим, что у нас комментарии в коде на русском языке. Как раньше формировались API?
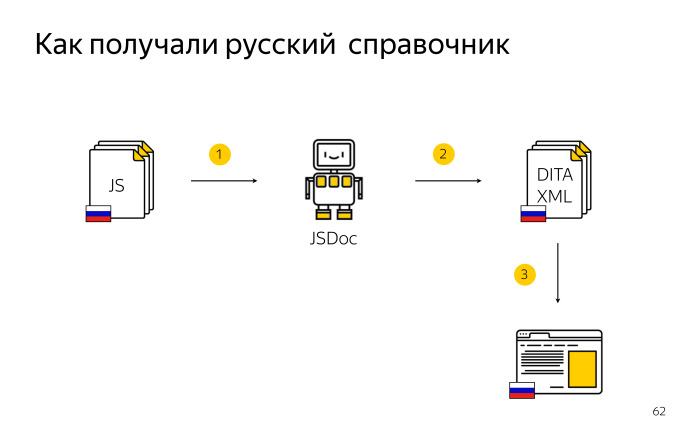
Для формирования русского справочника мы исходный код API с русскими комментариями прогоняли через JSDoc. Нужно было какое-то время подождать, и JSDoc отдавал нужную DITA XML, готовый справочник, который мы публиковали на нашем домене ru. Тут просто.
Как мы получали английский справочник из русских комментариев?
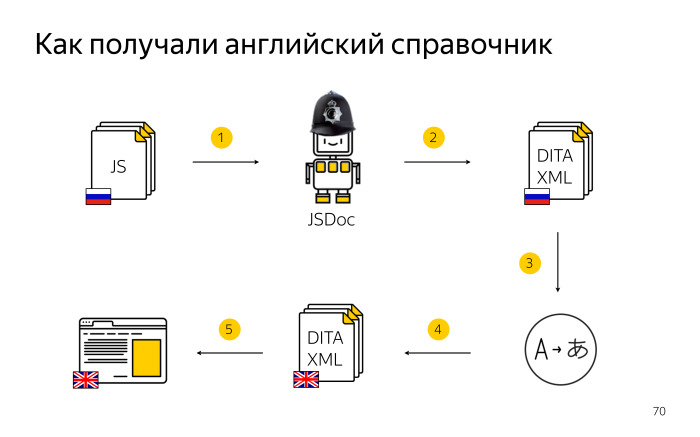
Мы брали русский код, снова прогоняли его через JSDoc отдельной итерацией, но мы настраивали специальный шаблон, локализованный под английский язык. Например, название таблиц было сразу на английском. Наличие такого шаблона я помечу английским шлемом. Нам английский JSDoc отдавал DITA XML, но по-прежнему с русским описанием, которое мы отдавали на перевод. Эми переводила и возвращала мне DITA XML на английском языке, готовый справочник, который можно публиковать на домене com.
Хорошо, но это было раньше. Теперь все поменялось, комментарии на английском языке. Как мы собираем английский справочник? Так же, как раньше собирали русский. Берем исходный код, прогоняем через программку-англичанина JSDoc, и получаем английские исходники, которые мы публикуем на домене com. Что же с русским справочником? Код с английскими комментариями, и у нас есть ТМ, память переводов, которую мы накапливали годами.
ТМ мы применяли при переводе с русского на английский. И тогда мы подумали, что если оно заработает и в обратную сторону, при переводе с английского на русский? Эми с Максом провели ряд экспериментов, и действительно это оказалось так. Мы можем применять накопленную годами ТМ и в обратную сторону.
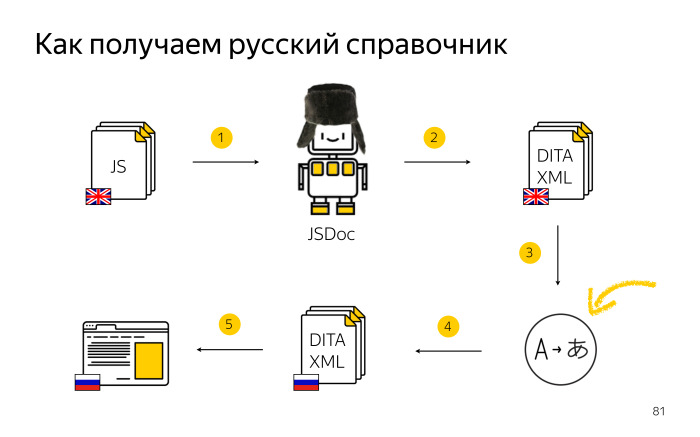
Это значит, что мы теперь русский справочник прогоняем по такой же схеме, как раньше собирали английский. Тут главное не запутаться: мы берем исходный код с английскими комментариями, прогоняем через JSDoc, но уже с шаблоном, локализованным под русский язык, с названиями таблиц на русском языке. Полученные справочники отдаем на перевод и публикуем их переведенными на русский.
В качестве переводчика здесь уже выступаю я. Каждый раз, когда мне нужно публиковать русский справочник, я вначале собираю английский, в инструменте Swordfish делаю перевод недостающих фрагментов текста, ранее непереведенных, и далее мы публикуем. Помните улитку, показывающую, что сначала справочник, который мы переводили, всегда отставал? Сейчас главное было, чтобы русский справочник не отставал. В первую очередь, время сократилось за счет того, что переводом занимаюсь я. Не нужно стоять в очереди на перевод: открыл, перевел пару строк и сам все собрал.
А синхронизировать справочники нам помогла программа TeamCity. Это инструмент от JetBrains, который позволяет автоматизировать многие процессы вашего проекта. Достаточно мощная штука.
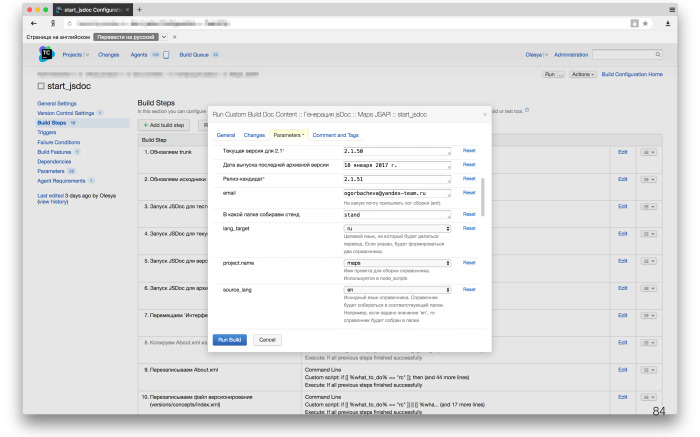
Это пример внутреннего настроенного интерфейса TeamCity. Это пример конфигурации для сборки справочников. Там задаются нужные параметры, язык справочника, номер версии и так далее, по кнопке запускаются, готовятся нужные источники. И наконец мы также формируем PDF для английской версии. Раньше мы этого не делали.
В чем же плюсы локализации комментариев в коде? Во-первых, теперь API Карт содержат английские комментарии, поэтому любой разработчик из любой точки мира может увидеть английский язык. Во-вторых, наконец-то мы настроили оперативную выкладку английских документов. В-третьих, мы сняли нагрузку с переводчика — теперь Эми не надо каждый раз переводить эти справочники. И наконец, если когда-нибудь нам придется переводить справочники на другие языки, то выполнять перевод с английского намного проще, чем с русского.

Это списки инструментов, которые мы используем в проекте. Спасибо!