https://habrahabr.ru/post/344560/- Машинное обучение
- Занимательные задачки
- Python
- Data Mining
Пролог
Порой у каждого из нас возникает вопрос, который не даёт нам покоя. И как правило ответ на такой вопрос можно получить лишь проанализировав опыт большого количества людей. У меня возник такой вопрос: «Какие факторы влияют на IQ и является ли он хоть чуточку преимуществом?». Конечно, читатель может воскликнуть, что всем давно уже все известно и можно прочитать статьи на эту тему. В какой-то степени вы окажитесь правы, но увы, статьи на тему IQ оказались крайне противоречивыми и навязали мне еще большее количество вопросов. Поэтому я и решил провести своё скромное исследование на эту тему.

Сambridge study in delinquent development
В 1962 году, в Англии началось масштабное и долгосрочное исследование(20 лет) на тему того, какие факторы влияют на асоциальное поведение. В качестве респондентов было выбрано около 500 мальчиков 10 лет, к каждому респонденту прилагается 890 параметров, которые описывают его юность, взросление, жизнь его семьи и его окружения. Cреди этих параметров был уровень IQ, который и навел меня на мысль исследования зависимостей между ним и другими переменными.

Импорт библиотек и загрузка данных:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore')
import random as rn
from sklearn.cross_validation import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestRegressor
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import svm
data = pd.read_stata('/Users/####/Downloads/ICPSR_08488/DS0001/08488-0001-Data.dta')
Обработка данных
В качестве целевой переменной был выбран коэффициент IQ, и она нуждалась в небольшой корректировке:
data['V288'].replace('IQ75',75,inplace=True )
data['V288'].replace('IQ129',129,inplace=True)
data['V288'].replace('IQ128',128,inplace=True)
Отбор необходимых признаков
#Создаем словарь, где мы будем хранить наши коэффициенты важности переменных
ranks = {}
# Создадим функцию для заполнения нашего словаря
def ranking(ranks, names, order=1):
minmax = MinMaxScaler()
ranks = minmax.fit_transform(order*np.array([ranks]).T).T[0]
ranks = map(lambda x: round(x,2), ranks)
return dict(zip(names, ranks))
#Зададим целевую переменную(Y)
Y = data['V288'].values
#Убираем Y из нашей обучающей выборки
IQ = data.drop(['V288'], axis=1)
X = data.as_matrix()
# Названия колонок
colnames = IQ.columns
%matplotlib inline
from sklearn.feature_selection import RFE, f_regression
from sklearn.linear_model import (LinearRegression, Ridge, Lasso, RandomizedLasso)
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestRegressor
# Теперь выявляем наиболее важные признаки
rlasso = RandomizedLasso(alpha=0.04)
Y = data['V288'].values
rlasso.fit(X, Y)
ranks["rlasso/Stability"] = ranking(np.abs(rlasso.scores_), colnames)
print('finished')
Чтобы не нагружать статью кодом я привел фрагмент лишь одного теста оценки признаков.Если будет интересно могу скинуть все исходники.
Отобразим все значения важности в нашем словаре
r = {}
for name in colnames:
r[name] = round(np.mean([ranks[method][name]
for method in ranks.keys()]), 2)
methods = sorted(ranks.keys())
ranks["Mean"] = r
methods.append("Mean")
print("\t%s" % "\t".join(methods))
for name in colnames:
print("%s\t%s" % (name, "\t".join(map(str,
[ranks[method][name] for method in methods]))))
Матрица результатов выглядит следующим образом, а последний столбец отображает среднее значение важности исходя из всех тестов:
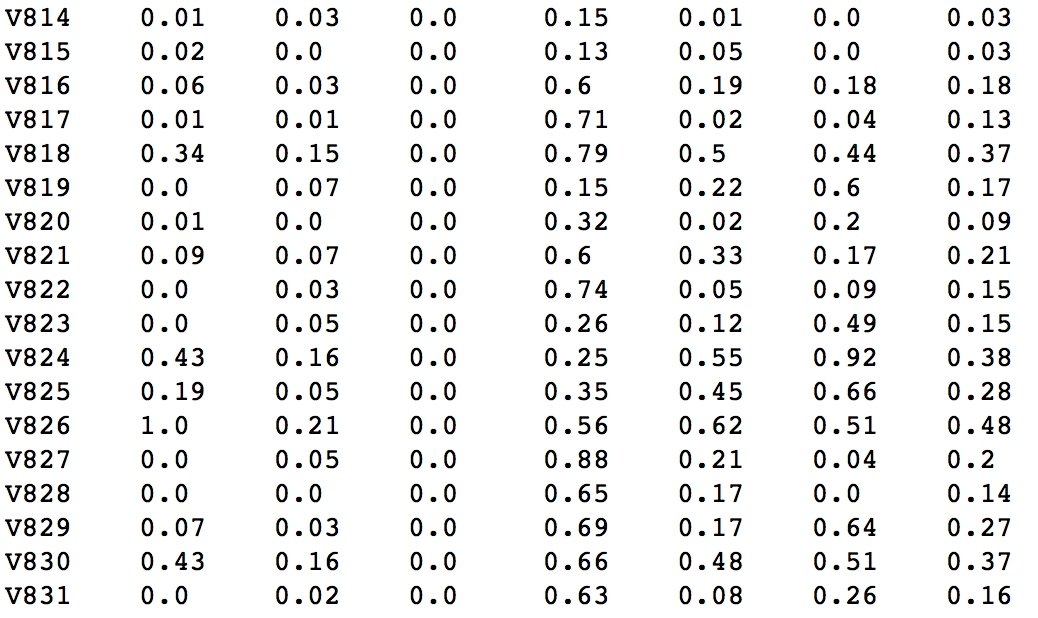
Давайте выберем топ 100 переменных по среднему значению:
sorted(r, key=r.get, reverse=True)[:100]
Описание наиболее значимых признаков признаков
Также на всякий случай я перепроверял эти переменный с помощью критерия Пирсона.
1. Средний IQ и состояние быта:
p_value 0.035
Нормальное: 98.171533
Ужасное: 103.934307
2.Средний IQ и поведение:
p_value 0.005
Дебошир: 102.395833
Адекватный: 98.286385
3.Средний IQ и вранье
p_value 0.004
Редко врет: 94.357895
Периодически врет: 99.627907
Часто врет: 101.702381
Всегда врет: 102.204545
4.Средний IQ и соц поддрежка:
Подразумеваются субсидии и пособия.
p_value 0.004
Не поддерживается государством: 98.310976
Поддерживается: 107.132530
5.Средний IQ и внешний вид:
p_value 0.011
Опрятный: 96.295597
Средний показатель: 102.608696
Неопрятный: 100.526316
6.Средний IQ и уровень концентрации внимания
p_value 0.007
Хорошая концентрация: 98.732218
Плохая концентрация: 105.186207
7.Средний IQ и проблемы развития в младенчестве
p_value 0.012
Нормальное: 99.294304
Задержка развития: 104.562500
В конце было интересно посмотреть зависимость того, какой IQ был у ребенка в школе и тем, сколько он зарабатывает уже в 30 лет(берется средний недельный доход)
IQ и зарплата:
111 и выше: 17.500000
101-110: 16.906250
91-100: 17.364486
90 и ниже: 17.558140
Вывод
Существуют факторы, которые действительно способны влиять на наш IQ, но с другой стороны IQ в случае нашей выборки не смог повлиять на уровень заработка.