https://habr.com/ru/post/470127/- Python
- Алгоритмы
- Машинное обучение
- Звук
Автоматическое сочинение музыки
Почти сразу после того, как я научился программированию, мне хотелось создать ПО, способное сочинять музыку.
Я в течение нескольких лет предпринимал примитивные попытки автоматического сочинения музыки для
Visions of Chaos. В основном при этом использовались простые математические формулы или генетические мутации случайных последовательностей нот. Добившись недавно скромного успеха в изучении и применении TensorFlow и нейронных сетей для
поиска клеточных автоматов, я решил попробовать использовать нейронные сети для создания музыки.
Как это работает
Композитор обучает нейросеть с
долгой кратковременной памятью (Long short-term memory, LSTM). LSTM-сети хорошо подходят для предсказания того, «что встретится дальше» в последовательностях данных. Подробнее о LSTM можно прочитать
здесь.
LSTM-сеть получает различные последовательности нот (в данном случае это одноканальные файлы midi). После достаточного обучения она получает возможность создавать музыку, схожую с обучающими материалами.
Схемы внутреннего устройства LSTM могут казаться пугающими, но использование
TensorFlow и/или
Keras сильно упрощают создание LSTM и эксперименты с ними.
Исходная музыка для обучения моделей
Для таких простых LSTM-сетей нам достаточно, чтобы исходные композиции представляли собой один канал midi. Отлично для этого подходят файлы midi с соло на пианино. Я нашёл файлы midi с пианинными соло на
Classical Piano Midi Page и
mfiles, и использовал их для обучения своих моделей.
Музыку разных композиторов я поместил в отдельные папки. Благодаря этому пользователь может выбрать Баха, нажать на кнопку Compose и получить композицию, которая (надеюсь) будет походить на Баха.
Модель LSTM
Моделью, на основании которого я писал код, был выбран
этот пример автора
Sigurður Skúli Sigurgeirsson, о котором он подробнее пишет
здесь.
Я запустил выполнение скрипта lstm.py и через 15 часов он завершил обучение. Когда я запустил predict.py для генерации файлов midi, то был разочарован, потому что они состояли из одной повторяющейся ноты. Дважды повторив обучение, я получил такие же результаты.
Исходная модель
model = Sequential()
model.add(CuDNNLSTM(512,input_shape=(network_input.shape[1], network_input.shape[2]),return_sequences=True))
model.add(Dropout(0.3))
model.add(CuDNNLSTM(512, return_sequences=True))
model.add(Dropout(0.3))
model.add(CuDNNLSTM(512))
model.add(Dense(256))
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop',metrics=["accuracy"])
Добавив в скрипт вывод графиков, я увидел, почему моя модель не работала. Точность не росла со временем, как должна была. См. ниже в посте хорошие графики, на которых видно, как должна выглядеть рабочая модель.
Я понятия не имел, почему так получилось. но отказался от этой модели и начал настраивать параметры.
model = Sequential()
model.add(CuDNNLSTM(512, input_shape=(network_input.shape[1], network_input.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(CuDNNLSTM(256))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=["accuracy"])
Она компактнее и в ней меньше слоёв LSTM. Также я добавил BatchNormalization, увидев его в
видео sentdex. Скорее всего, существуют более качественные модели, но эта вполне неплохо работала во всех моих сеансах обучения.
Заметьте, что в обеих моделях я заменил LSTM на CuDNNLSTM. Так я добился гораздо более быстрого LSTM-обучения благодаря использованию Cuda. Если у вас нет
GPU с поддержкой Cuda, то придётся пользоваться LSTM. Спасибо
sendtex за этот совет. Обучение новых моделей и сочинение файлов midi при использовании CuDNNLSTM выполняется примерно в пять раз быстрее.
Как долго следует обучать модель
От длительности обучения модели (количества эпох) зависит схожесть результатов с исходной музыкой. Если эпох слишком мало, то в получившемся результате будет слишком много повторяющихся нот. Если эпох слишком много, то модель будет переобучена и просто скопирует исходную музыку.
Но как узнать на каком количестве эпох остановиться?
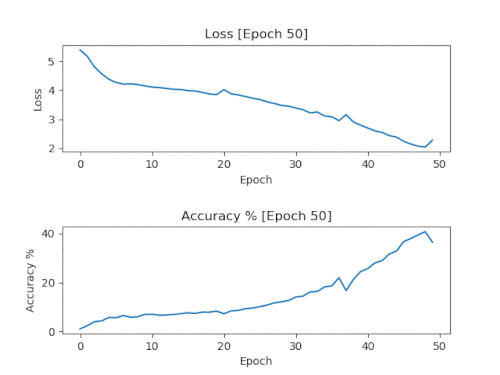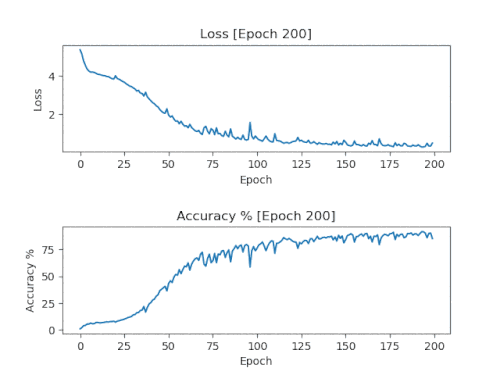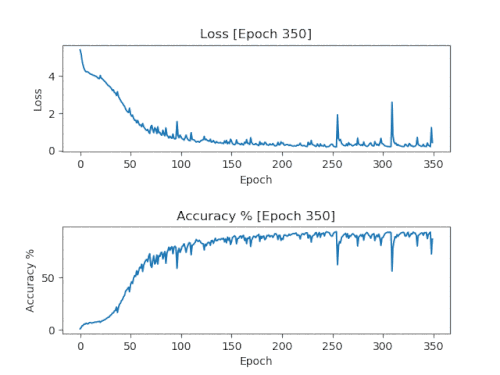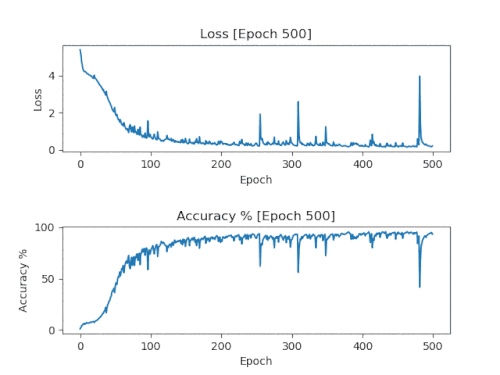
Простое решение заключается в добавлении обратного вызова, который сохраняет модель и график точности/потерь через каждые 50 эпох на прогоне обучения в 500 эпох. Благодаря этому после завершения обучения у вас получатся модели и графики с инкрементом в 50 эпох, показывающие, как именно проходит обучение.
Вот результаты графиков одного прогона с сохранением каждых 50 эпохах, объединённые в один анимированный GIF.
Именно такие графики мы и хотим увидеть. Потери должны падать и оставаться низкими. Точность должна повышаться и оставаться близкой к 100%.
Нужно использовать модель с количеством эпох, соответствующим моменту, когда графики впервые достигли своих пределов. Для показанного выше графика это будет 150 эпох. Если использовать более «старые» модели, то они будут переобучены и скорее всего приведут к простому копированию исходного материала.
Соответствующая этим графам модель обучалась на файлах midi категории «Гимны» (Anthems), взятых
отсюда.

Выходные midi-данные в модели с 150 эпохами.
Выходные midi-данные в модели с 100 эпохами.
Даже модель с 100 эпохами может слишком точно копировать исходник. Это может происходить из-за относительно малой выборки файлов midi для обучения. При большем количестве нот обучение проходит лучше.
Когда обучение проходит плохо
На изображении выше показан пример того, что иногда может происходить и происходит во время обучения. Потери уменьшаются, а точность повышается, как и обычно, но внезапно они начинают сходить с ума. На этом этапе возможно тоже стоит остановиться. Модель больше не будет (по крайней мере, на моём опыте) снова обучаться правильно. В этом случае сохранённая модель с 100 эпохами ещё слишком случайна, а с 150 эпохами уже прошла момент сбоя модели. Теперь я сохраняюсь через каждые 25 эпох, чтобы точно найти идеальный момент модели с наилучшим обучением, ещё до того, как она переобучится и придёт к сбою.
Ещё один пример ошибки обучения. Эта модель обучалась на файлах midi, взятых
отсюда. В этом случае она хорошо держалась чуть дольше, чем 200 эпох. При использовании модели с 200 эпохами получается следующий результат в Midi.
Без создания графиков мы бы никогда не узнали, есть ли у модели проблемы и когда они возникли, а также не смогли бы получить хорошую модель, не начиная всё с нуля.
Другие примеры
Модель с 75 эпохами, созданная на основании композиций
Шопена.
Модель с 50 эпохами, основанная на
Midi-файлах рождественских композиций.
Модель с 100 эпохами, основанная на
Midi-файлах рождественских композиций. Но очень ли они «рождественские»?
Модель с 300 эпохами, основанная на Midi-файлах Баха, взятых
отсюда и
отсюда.
Модель с 200 эпохами, основанная на единственном Midi-файле Балакирева, взятого
здесь.
Модель с 200 эпохами, основанная на композициях
Дебюсси.
Модель с 175 эпохами, основанная на композициях Моцарта.
Модель с 100 эпохами, основанная на композициях
Шуберта.
Модель с 200 эпохами, основанная на композициях
Шумана.
Модель с 200 эпохами, основанная на композициях
Чайковского.
Модель с 175 эпохами, основанная на народных песнях.
Модель с 100 эпохами, основанная на колыбельных.
Модель с 100 эпохами, основанная на музыке для свадеб.
Модель с 200 эпохами, основанная на моих собственных файлах midi, взятых из моих саундтреков к
видео на YouTube. Возможно, она немного переобучена, потому что в основном генерирует копии моих коротких одно- и двухтактных файлов midi.
Партитуры
Получив файлы midi, можно воспользоваться онлайн-инструментами наподобие
SolMiRe, чтобы преобразовать их в партитуры. Ниже показана партитура представленного выше файла midi Softology с 200 эпохами.
Где можно протестировать композитора
LSTM Composer теперь включён в
Visions of Chaos.
Выберите стиль из раскрывающегося списка и нажмите Compose. Если у вас установлены минимально необходимые Python и TensorFlow (инструкции см.
здесь), то за несколько секунд (если у вас быстрый GPU) вы получите новый сочинённый машиной файл midi, который можно слушать и использовать для любой другой цели. Никаких авторских прав, никаких лицензионных отчислений. Если вам не понравятся результаты, то можете снова нажать на Compose и через несколько секунд будет готова новая композиция.
Результаты пока нельзя считать полноценными композициями, но в них есть интересные небольшие последовательности нот, которые я буду использовать для создания музыки в будущем. В этом отношении LSTM-композитор может быть хорошим источником вдохновения для написания новых композиций.
Исходники на Python
Ниже приведён использованный мной код скриптов на Python для обучения LSTM и прогнозирования. Чтобы эти скрипты работали, необязательно устанавливать Visions of Chaos, а обучение и генерирование midi будут работать из командной строки.
Вот скрипт обучения
lstm_music_train.py
lstm_music_train.py# based on code from https://github.com/Skuldur/Classical-Piano-Composer
# to use this script pass in;
# 1. the directory with midi files
# 2. the directory you want your models to be saved to
# 3. the model filename prefix
# 4. how many total epochs you want to train for
# eg python -W ignore "C:\\LSTM Composer\\lstm_music_train.py" "C:\\LSTM Composer\\Bach\\" "C:\\LSTM Composer\\" "Bach" 500
import os
import tensorflow as tf
# ignore all info and warning messages
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
import glob
import pickle
import numpy
import sys
import keras
import matplotlib.pyplot as plt
from music21 import converter, instrument, note, chord
from datetime import datetime
from keras.models import Sequential
from keras.layers.normalization import BatchNormalization
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import CuDNNLSTM
from keras.layers import Activation
from keras.utils import np_utils
from keras.callbacks import TensorBoard
from shutil import copyfile
# name of midi file directory, model directory, model file prefix, and epochs
mididirectory = str(sys.argv[1])
modeldirectory = str(sys.argv[2])
modelfileprefix = str(sys.argv[3])
modelepochs = int(sys.argv[4])
notesfile = modeldirectory + modelfileprefix + '.notes'
# callback to save model and plot stats every 25 epochs
class CustomSaver(keras.callbacks.Callback):
def __init__(self):
self.epoch = 0
# This function is called when the training begins
def on_train_begin(self, logs={}):
# Initialize the lists for holding the logs, losses and accuracies
self.losses = []
self.acc = []
self.logs = []
def on_epoch_end(self, epoch, logs={}):
# Append the logs, losses and accuracies to the lists
self.logs.append(logs)
self.losses.append(logs.get('loss'))
self.acc.append(logs.get('acc')*100)
# save model and plt every 50 epochs
if (epoch+1) % 25 == 0:
sys.stdout.write("\nAuto-saving model and plot after {} epochs to ".format(epoch+1)+"\n"+modeldirectory + modelfileprefix + "_" + str(epoch+1).zfill(3) + ".model\n"+modeldirectory + modelfileprefix + "_" + str(epoch+1).zfill(3) + ".png\n\n")
sys.stdout.flush()
self.model.save(modeldirectory + modelfileprefix + '_' + str(epoch+1).zfill(3) + '.model')
copyfile(notesfile,modeldirectory + modelfileprefix + '_' + str(epoch+1).zfill(3) + '.notes');
N = numpy.arange(0, len(self.losses))
# Plot train loss, train acc, val loss and val acc against epochs passed
plt.figure()
plt.subplots_adjust(hspace=0.7)
plt.subplot(2, 1, 1)
# plot loss values
plt.plot(N, self.losses, label = "train_loss")
plt.title("Loss [Epoch {}]".format(epoch+1))
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.subplot(2, 1, 2)
# plot accuracy values
plt.plot(N, self.acc, label = "train_acc")
plt.title("Accuracy % [Epoch {}]".format(epoch+1))
plt.xlabel("Epoch")
plt.ylabel("Accuracy %")
plt.savefig(modeldirectory + modelfileprefix + '_' + str(epoch+1).zfill(3) + '.png')
plt.close()
# train the neural network
def train_network():
sys.stdout.write("Reading midi files...\n\n")
sys.stdout.flush()
notes = get_notes()
# get amount of pitch names
n_vocab = len(set(notes))
sys.stdout.write("\nPreparing note sequences...\n")
sys.stdout.flush()
network_input, network_output = prepare_sequences(notes, n_vocab)
sys.stdout.write("\nCreating CuDNNLSTM neural network model...\n")
sys.stdout.flush()
model = create_network(network_input, n_vocab)
sys.stdout.write("\nTraining CuDNNLSTM neural network model...\n\n")
sys.stdout.flush()
train(model, network_input, network_output)
# get all the notes and chords from the midi files
def get_notes():
# remove existing data file if it exists
if os.path.isfile(notesfile):
os.remove(notesfile)
notes = []
for file in glob.glob("{}/*.mid".format(mididirectory)):
midi = converter.parse(file)
sys.stdout.write("Parsing %s ...\n" % file)
sys.stdout.flush()
notes_to_parse = None
try: # file has instrument parts
s2 = instrument.partitionByInstrument(midi)
notes_to_parse = s2.parts[0].recurse()
except: # file has notes in a flat structure
notes_to_parse = midi.flat.notes
for element in notes_to_parse:
if isinstance(element, note.Note):
notes.append(str(element.pitch))
elif isinstance(element, chord.Chord):
notes.append('.'.join(str(n) for n in element.normalOrder))
with open(notesfile,'wb') as filepath:
pickle.dump(notes, filepath)
return notes
# prepare the sequences used by the neural network
def prepare_sequences(notes, n_vocab):
sequence_length = 100
# get all pitch names
pitchnames = sorted(set(item for item in notes))
# create a dictionary to map pitches to integers
note_to_int = dict((note, number) for number, note in enumerate(pitchnames))
network_input = []
network_output = []
# create input sequences and the corresponding outputs
for i in range(0, len(notes) - sequence_length, 1):
sequence_in = notes[i:i + sequence_length] # needs to take into account if notes in midi file are less than required 100 ( mod ? )
sequence_out = notes[i + sequence_length] # needs to take into account if notes in midi file are less than required 100 ( mod ? )
network_input.append([note_to_int[char] for char in sequence_in])
network_output.append(note_to_int[sequence_out])
n_patterns = len(network_input)
# reshape the input into a format compatible with CuDNNLSTM layers
network_input = numpy.reshape(network_input, (n_patterns, sequence_length, 1))
# normalize input
network_input = network_input / float(n_vocab)
network_output = np_utils.to_categorical(network_output)
return (network_input, network_output)
# create the structure of the neural network
def create_network(network_input, n_vocab):
'''
""" create the structure of the neural network """
model = Sequential()
model.add(CuDNNLSTM(512, input_shape=(network_input.shape[1], network_input.shape[2]), return_sequences=True))
model.add(Dropout(0.3))
model.add(CuDNNLSTM(512, return_sequences=True))
model.add(Dropout(0.3))
model.add(CuDNNLSTM(512))
model.add(Dense(256))
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop',metrics=["accuracy"])
'''
model = Sequential()
model.add(CuDNNLSTM(512, input_shape=(network_input.shape[1], network_input.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(CuDNNLSTM(256))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=["accuracy"])
return model
# train the neural network
def train(model, network_input, network_output):
# saver = CustomSaver()
# history = model.fit(network_input, network_output, epochs=modelepochs, batch_size=50, callbacks=[tensorboard])
history = model.fit(network_input, network_output, epochs=modelepochs, batch_size=50, callbacks=[CustomSaver()])
# evaluate the model
print("\nModel evaluation at the end of training")
train_acc = model.evaluate(network_input, network_output, verbose=0)
print(model.metrics_names)
print(train_acc)
# save trained model
model.save(modeldirectory + modelfileprefix + '_' + str(modelepochs) + '.model')
# delete temp notes file
os.remove(notesfile)
if __name__ == '__main__':
train_network()
А вот скрипт генерации midi
lstm_music_predict.py:
lstm_music_predict.py# based on code from https://github.com/Skuldur/Classical-Piano-Composer
# to use this script pass in;
# 1. path to notes file
# 2. path to model
# 3. path to midi output
# eg python -W ignore "C:\\LSTM Composer\\lstm_music_predict.py" "C:\\LSTM Composer\\Bach.notes" "C:\\LSTM Composer\\Bach.model" "C:\\LSTM Composer\\Bach.mid"
# ignore all info and warning messages
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
import pickle
import numpy
import sys
import keras.models
from music21 import instrument, note, stream, chord
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Activation
# name of weights filename
notesfile = str(sys.argv[1])
modelfile = str(sys.argv[2])
midifile = str(sys.argv[3])
# generates a piano midi file
def generate():
sys.stdout.write("Loading notes data file...\n\n")
sys.stdout.flush()
#load the notes used to train the model
with open(notesfile, 'rb') as filepath:
notes = pickle.load(filepath)
sys.stdout.write("Getting pitch names...\n\n")
sys.stdout.flush()
# Get all pitch names
pitchnames = sorted(set(item for item in notes))
# Get all pitch names
n_vocab = len(set(notes))
sys.stdout.write("Preparing sequences...\n\n")
sys.stdout.flush()
network_input, normalized_input = prepare_sequences(notes, pitchnames, n_vocab)
sys.stdout.write("Loading LSTM neural network model...\n\n")
sys.stdout.flush()
model = create_network(normalized_input, n_vocab)
sys.stdout.write("Generating note sequence...\n\n")
sys.stdout.flush()
prediction_output = generate_notes(model, network_input, pitchnames, n_vocab)
sys.stdout.write("\nCreating MIDI file...\n\n")
sys.stdout.flush()
create_midi(prediction_output)
# prepare the sequences used by the neural network
def prepare_sequences(notes, pitchnames, n_vocab):
# map between notes and integers and back
note_to_int = dict((note, number) for number, note in enumerate(pitchnames))
sequence_length = 100
network_input = []
output = []
for i in range(0, len(notes) - sequence_length, 1):
sequence_in = notes[i:i + sequence_length]
sequence_out = notes[i + sequence_length]
network_input.append([note_to_int[char] for char in sequence_in])
output.append(note_to_int[sequence_out])
n_patterns = len(network_input)
# reshape the input into a format compatible with LSTM layers
normalized_input = numpy.reshape(network_input, (n_patterns, sequence_length, 1))
# normalize input
normalized_input = normalized_input / float(n_vocab)
return (network_input, normalized_input)
# create the structure of the neural network
def create_network(network_input, n_vocab):
model = keras.models.load_model(modelfile)
return model
# generate notes from the neural network based on a sequence of notes
def generate_notes(model, network_input, pitchnames, n_vocab):
# pick a random sequence from the input as a starting point for the prediction
start = numpy.random.randint(0, len(network_input)-1)
int_to_note = dict((number, note) for number, note in enumerate(pitchnames))
pattern = network_input[start]
prediction_output = []
# generate 500 notes
for note_index in range(500):
prediction_input = numpy.reshape(pattern, (1, len(pattern), 1))
prediction_input = prediction_input / float(n_vocab)
prediction = model.predict(prediction_input, verbose=0)
index = numpy.argmax(prediction)
result = int_to_note[index]
prediction_output.append(result)
pattern.append(index)
pattern = pattern[1:len(pattern)]
if (note_index + 1) % 50 == 0:
sys.stdout.write("{} out of 500 notes generated\n".format(note_index+1))
sys.stdout.flush()
return prediction_output
# convert the output from the prediction to notes and create a midi file from the notes
def create_midi(prediction_output):
offset = 0
output_notes = []
# create note and chord objects based on the values generated by the model
for pattern in prediction_output:
# pattern is a chord
if ('.' in pattern) or pattern.isdigit():
notes_in_chord = pattern.split('.')
notes = []
for current_note in notes_in_chord:
new_note = note.Note(int(current_note))
new_note.storedInstrument = instrument.Piano()
notes.append(new_note)
new_chord = chord.Chord(notes)
new_chord.offset = offset
output_notes.append(new_chord)
# pattern is a note
else:
new_note = note.Note(pattern)
new_note.offset = offset
new_note.storedInstrument = instrument.Piano()
output_notes.append(new_note)
# increase offset each iteration so that notes do not stack
offset += 0.5
midi_stream = stream.Stream(output_notes)
midi_stream.write('midi', fp=midifile)
if __name__ == '__main__':
generate()
Размеры файлов моделей
Недостаток включения нейросетей в Visions of Chaos заключается в размере файлов. Если бы генерация модели была быстрее, то я бы просто добавил кнопку, чтобы конечный пользователь мог сам обучать модели. Но поскольку некоторые из сеансов обучения множества моделей могут занимать по несколько дней, это не особо практично. Мне показалось, что лучше выполнить всё обучение и тестирование самому, и добавить только самые лучшие работающие модели. Это также означает, что конечному пользователю достаточно просто нажать на кнопку, и обученные модели создадут музыкальные композиции.
Каждая из моделей имеет размер 22 мегабайта. В условиях современного Интернета это не так уж много, но за годы разработки Visions of Chaos наращивал свой размер постепенно, и только недавно он внезапно увеличился с 70 до 91 МБ (из-за модели поиска клеточных автоматов). Поэтому я пока добавил в основной установщик Visions of Chaos только одну модель. Для пользователей, которым хочется большего, я выложил ссылку на ещё 1 ГБ моделей. Также они могут воспользоваться приведённым выше скриптом, чтобы создавать собственные модели, основанные на выбранных ими файлах midi.
Что дальше?
На данном этапе LSTM-композитор является простейшим примером использования нейронных сетей для сочинения музыки.
Я уже нашёл другие композиторы музыки на нейронных сетях, с которыми поэкспериментирую в будущем, поэтому можно ожидать, что в Visions of Chaos будут появляться новые возможности автоматического сочинения музыки.