https://habrahabr.ru/post/329250/- Открытые данные
- Визуализация данных
- JavaScript
- Data Mining
Недавно смотрел
серию видео популяризатора математики. Там он пытается рассказывать про математический анализ и линейную алгебру немного с позиции человека, который «как бы» изобрел бы ее с нуля. То есть пытается делать доступными простые и понятые визуализации относительно сложных концепций, как бы объясняя их с позиции человека, который как будто бы придумал это впервые. Относительно недавно читал
статью на Хабре про unsupervised learning и увидел там раздел про
Affinity Propagation. Как оказалось, мы использовали именно этот метод кластерного анализа чисто интуитивно, сами того не ведая.
TLDR для данной статьи. Если хотите интерактивную визуализацию, проследуйте
сюда.
В данной визуализации в виде графа показаны связи между музыкальными жанрами ~25,000 самых популярных артистов мира, причем размер кругляшка показывает популярность данного жанра, а размер ребра графа — силу связи.
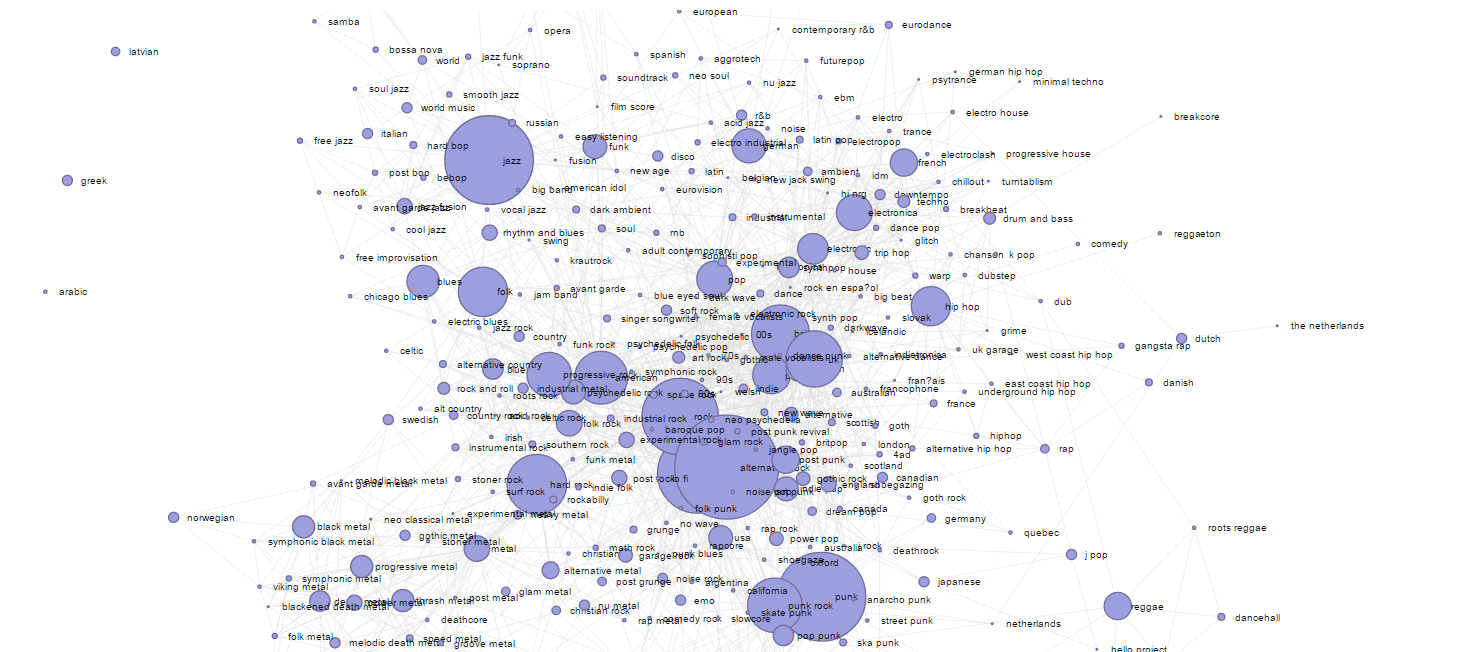 Эврика раз
Эврика раз
Эта визуализация представляет из себя визуализацию, сделанную на библиотеке D3.js (мы где-то нашли шаблон), на данных похожести групп. Исходные данные и свою рекурсию можно начать
тут. Алгоритм обработки данных был примерно такой (это все было давно, помню в общих чертах, jpn тогда не использовал):
- Взять базу Musicbrainz;
- Распаковать ее (если нужно — обращайтесь, есть распакованная копия в PostgreSQL где-то годичной давности);
- Взять данные всех артистов, всех альбомов с жанрами;
- Построить распределения количества альбомов, жанров, треков на одного артиста. Построить распределение популярности жанров;
- Взять логарифмы от этих данных и почистить их от явного мусора, редких или очень частых «мусорных» значений;
- Далее следовал ряд шагов связанный с базой компании, где я работал, которые менее важны (по сути мы также связывали жанры, чистили нашу внутреннюю базу от мусора, проставляли значения итд итп);
- Взяв за меру схожести количество одинаковых жанров у артистов построить метрику расстояния между i) артистами ii) между жанрами;
- По сути, насколько я помню, на практике мы это делали перемножением матриц размерности ~25,000 строк;
- В итоге мы получили меры похожести артистов и музыкальных жанров;
- Похожесть артистов получилась так себе, поскольку в среднем у артиста было несколько тегов, а вот похожесть жанров вышла отличная;
- Ручной простановкой и кластерным анализом мы объеденили жанры в группы жанров;
Тогда, когда мы это делали, про питон и науку о данных мы не знали (лолшто?) и все делалось сочетанием SQL запросов, манипуляций с CSV-файлами и перемножением получившихся матриц. Когда мы почистили базу компании и послали всем заветный email, в котором было все описано все проделанное и была продемонстрирована указанная диаграмма… в ответ мы получили ничего. Никто не задал ни одного вопроса. Всем было просто безразлично. Данные нашей кропотливой ушли на прод, продлив срок жизни системы тегов на пару лет (там был лютый мусор, т.к. не было никакой курации и контроля за заполнением данных), а в ответ мы получили безмолвное молчание и упреки формата «зачем мы потратили так много времени на какое-то говно?». Тот факт, что такая информация безумно полезна для построения рекомендаций, рейтингов похожести, кросс-продаж и увеличения перелинковки на сайте тоже прошел незаметно.
После этого помню эпизод, когда один из менеджеров компании пытался ввести отзывы о мероприятиях в виде одной звездочки. Это не дошло до имплементации также по причине, описанной выше. Какой там коллаборативные фильтеринг уж =)
Было и смешно и грустно, что по факту мы «нащупали» работающий алгоритм и сделали так, чтобы он работал на проде, но всем как говорится безразлично.
Эврика два
Второй момент аналогичной эврики — примитивный алгоритм коллаборативной фильтрации (лучше всего на коленке он
пояснен тут в форме xlsx файла). По идее «правильный» алгоритм работает так:
- Есть выборка условно из отзывов на фильмы;
- Из априорных соображений выбирается количество латентных (ненаблюдаемых факторов) — допустим люди оценивают фильмы по 5 критериям;
- Случайно генерируются веса, которые опосредуют связь пользователь-латентный фактор и фильм-латентный фактор;
- Также в модель включаются константы (bias values);
- Методом градиентного спуска или его аналогом делается оптимизация весов (посмотрите xls файл по ссылке выше);
На практике, не зная про это и про питон, я делал так. Рассчитывал какой-то показатель, который имел распределение Пуассона и пытался нормировать его и привести к нормальному. Выглядит примерно так:

С набором показателей выглядит примерно так:

Потом линейными и логистическими регрессиями я подбирал веса. По сути получается очень грубый аналог такого метода, но где вместо латентных факторов выступают некие эвристики, придуманные мной и имеющие достаточно хорошие статистические свойства.
В общем, если вы еще не поняли, то моя мысль состоит в следующем:- Делайте то, что вам нравится;
- Не слушайте «советчиков» и всех тех, кто «знает как лучше», но ничего не делает;
- Не отчаивайтесь, если на вашем пути будут встречаться темные личности, темные моменты и темные ситуации;
- Пытайтесь улучшать свою работу, себя и мир хотя бы по крупице каждый день;