Как я сделал самый быстрый ресайз изображений. Часть 2, SIMD
- четверг, 20 апреля 2017 г. в 03:14:19
Это продолжение цикла статей о том, как я занимался оптимизацией и получил самый быстрый ресайз на современных x86 процессорах. В каждой статье я рассказываю часть истории, и надеюсь подтолкнуть еще кого-то заняться оптимизацией своего или чужого кода. В предыдущих сериях:
→ Часть 0
→ Часть 1, общие оптимизации
В прошлый раз мы получили ускорение в среднем в 2,5 раза без изменения подхода. В этот раз я покажу, как применять SIMD-подход и получить ускорение еще в 3,5 раза. Конечно, применение SIMD для обработки графики не является ноу-хау, можно даже сказать, что SIMD был придуман для этого. Но на практике очень мало разработчиков используют его даже в задачах обработки изображений. Например, довольно известные и распространенные библиотеки ImageMagick и LibGD написаны без использования SIMD. Отчасти так происходит потому, что SIMD-подход объективно сложнее и не кроссплатформенный, а отчасти потому, что по нему мало информации. Довольно просто найти азы, но мало детальных материалов и разбора реальных задач. От этого на Stack Overflow очень много вопросов буквально о каждой мелочи: как загрузить данные, как распаковать, запаковать. Видно, что всем приходится набивать шишки самостоятельно.
Смело пропускайте этот раздел, если уже знакомы с основами. SIMD означает singe instruction, multiple data (одна команда, множество данных). Такой подход позволяет объединить несколько одинаковых операций в одну. Набор данных, над которым выполняется операция, называется вектор.
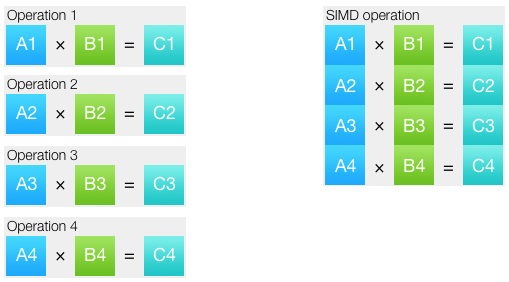
В большинстве случаев на современных процессорах SIMD-инструкции выполняются за столько же тактов, за сколько их скалярные аналоги. Т.е. теоретически при переходе на SIMD можно рассчитывать на ускорение в 2, 4, 8, 16 и даже 32 раза, в зависимости от используемых типов данных и наборов команд. На практике выходит по-разному. Во-первых, даже в векторизованном коде часть кода остается скалярным. Во-вторых, часто для векторных операций данные нужно подготовить: распаковать и запаковать. Как правило, запаковка и распаковка данных — это самое сложное при написании SIMD-кода. В-третьих, SIMD-инструкции не являются точной копией обычных: для каких-то операций есть специфичные инструкции, хорошо решающие стоящую задачу, а для других задач нужных инструкций не оказывается. Например для нахождения минимального и максимального значений есть отдельные SIMD-инструкции, работающие без условных переходов. А вот целочисленного векторного деления в процессорах x86 просто нет.
В векторные регистры помещается больше значений. Как много — зависит от типа данных и размера регистра. SSE-регистры 128-битные. Если, например, мы работаем с 32-битными целыми, то в один SSE-регистр поместится четыре значения. В основном доступны следующие тип данных:
Все векторные регистры одинаковые и не знают, какого типа данные в них находятся. Интерпретация зависит только от инструкции, которая работает с регистром. Соответственно, большинство инструкций имеют разновидности для работы с данными разных типов. Инструкции могут принимать данные одного типа, а выдавать другого. Если вы знакомы с ассемблером, это чем-то напоминает то, как работают обычные регистры: вы можете записать что-то в 32-битный регистр eax, а потом работать с его 16-битной частью ax.
Первые SIMD-инструкции появились в процессоре Intel Pentium MMX. Собственно MMX — это и есть название расширения команд. Этот набор был настолько важным, что Intel вынесла его в название процессора. С помощью MMX я когда-то давно писал простенькие алгоритмы вроде смешивания двух изображений или суперсемплинга. Писал на Дельфи, но чтобы использовать MMX, приходилось спускаться на уровень ниже и делать вставки на ассемблере.
С тех пор я не слишком следил за развитием процессорных команд и связанных с ними средств разработки. Поэтому, когда я недавно снова взялся за SIMD, был приятно удивлен. Нет, компилятор все еще не способен автоматически применять SIMD-инструкции в более-менее сложных случаях. А если и способен, то обычно у него получается хуже, чем самостоятельно написанный SIMD-код. Но зато для применения SIMD уже давно не нужно писать на ассемблере, все делается специальными функциями — интринсиками.
Чаще всего каждому интринсику соответствует одна конкретная инструкция процессора. Т.е. написанный код получается очень эффективный и близкий к железу. Но при этом для написания кода вы пользуетесь знакомым и относительно безопасным синтаксисом Си. Вы как обычно подключаете заголовочный файл, в котором определены функции-интринсики, как обычно объявляете переменные, используя специальные типы данных, и как обычно вызываете функции. Словом, пишите обычный код. Небольшое неудобство только в том, что с SIMD-типами данных нельзя использовать математические операции, для всех вычислений нужно использовать интринсики. Грубо говоря, нельзя написать ss0 + ss1, можно только add_float(ss0, ss1) (название функции выдумано).
SIMD-расширений много. В основном наличие в процессоре более нового расширения означает наличие всех предшественников. По хронологии появления расширения располагаются в следующем порядке:
MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, AVX-512
Как видите, список внушительный. Не на каждой машине есть каждое расширение. Найти живой x86 процессор без MMX можно разве что в музее. SSE2 — обязательное расширение для 64-битных процессоров, т.е. в наши дни тоже есть практически везде. Поддержку SSE4.2 можно найти в любом процессоре, начиная с архитектуры Nehalem, т.е. с 2008 года. А вот AVX2 есть только у не бюджетных процессоров Intel, начиная с ядра Haswell, т.е. с 2013 года, а у AMD они появились в процессорах Ryzen, выпущенных в 2017 году. AVX-512 пока доступны только в серверных процессорах Intel Xeon и Xeon Phi.
От выбора набора инструкций, зависит производительность и сложность написания кода, а также поддержка процессоров. Иногда разработчики делают несколько реализаций своего кода под разные наборы инструкций. Я выбрал два: SSE4.2 и AVX2. Я рассуждал так: SSE4.2 — базовый набор, который должен быть у всех, кого хоть сколько волнует производительность и не стоит мучаться, реализовывая все, например, на SSE2. А AVX2 для тех, кто не ленится менять железо хотя бы раз в 3 года. Что бы вы не выбрали для своей реализации, со временем ваш выбор будет становиться только более верным, потому что количество процессоров на рынке с выбранным набором инструкций будет только увеличиваться.
Давайте наконец вернемся к коду. Для того, чтобы использовать SSE4.2 в Си, нужно подключить целых три заголовочных файла:
#include <emmintrin.h>
#include <mmintrin.h>
#include <smmintrin.h>Кроме того, нужно указать флаг компилятора -msse4. Если речь идет о сборке питоновского модуля (как у нас), то можно добавить этот флаг прямо из командной строки, чтобы не усложнять сейчас сборку:
$ CC="ccache cc -msse4" python ./setup.py developНаиболее полный справочник по интринсикам можно найти по ссылке Intel Intrinsics Guide. Там есть хороший поиск и фильтрация, в описании интринсиков указаны соответствующие им инструкции, псевдокод инструкций и даже время выполнения в тактах на процессорах Intel последних поколений. Как справочник, это уникальная вещь. Но формат справочника не позволяет составить общую картину, как что должно происходить.
Векторизации поддаются только одинаковые операции над разными данными. В нашем случае одинаковые действия производятся над разными каналами изображения:
for (xx = 0; xx < imOut->xsize; xx++) {
ss0 = 0.5;
ss1 = 0.5;
ss2 = 0.5;
for (y = ymin; y < ymax; y++) {
ss0 = ss0 + (UINT8) imIn->image[y][xx*4+0] * k[y-ymin];
ss1 = ss1 + (UINT8) imIn->image[y][xx*4+1] * k[y-ymin];
ss2 = ss2 + (UINT8) imIn->image[y][xx*4+2] * k[y-ymin];
}
imOut->image[yy][xx*4+0] = clip8(ss0);
imOut->image[yy][xx*4+1] = clip8(ss1);
imOut->image[yy][xx*4+2] = clip8(ss2);
}Подобный код есть для вертикального и горизонтального прохода. Для удобства вынесем и тот, и другой в отдельные функции и будем использовать SIMD только в рамках двух функций со следующими сигнатурами:
void
ImagingResampleHorizontalConvolution8u(
UINT32 *lineOut, UINT32 *lineIn,
int xsize, int *xbounds, float *kk, int kmax
);
void
ImagingResampleVerticalConvolution8u(
UINT32 *lineOut, Imaging imIn,
int ymin, int ymax, float *k
);Если вы помните, в предыдущей части я сделал три частных случая для двух, трех и четырех каналов в изображении. Это было нужно, чтобы избавиться от внутреннего цикла по каналам и в то же время не выполнять лишних вычислений для каналов, которых в изображении нет. В SIMD-версии мы не будем делить реализации по каналам: все вычисления всегда будут производиться над четырьмя каналами. Каждый пиксель будет представлен четырьмя 32-битными числами с плавающей точкой и будет занимать ровно один SSE-регистр. Да, для трехканальных изображений четверить операций будет выполняться вхолостую, а для двухканального — половина. Но проще закрыть на это глаза, чем пытаться максимально забить SSE-регистры полезными данными.
Взгляните еще раз на код выше. В самом начале идет присвоение аккумуляторам константного значения 0,5, которое нужно для округления результата. Для загрузки одного float-значения в весь регистр используются функции _mm_set1_*.
__m128 sss = _mm_set1_ps(0.5);Обычно последняя часть названия функции означает тип данных, с которым она работает. В нашем случае это _ps, что означает packed single.
Дальше, если мы хотим работать с пикселем как с вектором чисел с плавающей точкой, нужно как-то сконвертировать пиксель в это представление. В SSE нет инструкций, преобразовывающих 8-битные значения сразу в числа одинарной точности. Есть _mm_cvtepi32_ps, которая преобразует 32-битные целые в числа с одинарной точностью, но перед тем как её использовать, нужно распаковать 8-битные числа в 32-битные. Для этого пригодится функция _mm_cvtepu8_epi32. Ей нужно передать адрес на 128-битное значений в памяти.
__m128i pix_epi32 = _mm_cvtepu8_epi32(*(__m128i *) &imIn->image32[y][xx]);
__m128 pix_ps = _mm_cvtepi32_ps(pix_epi32);Заметьте, как много в SIMD-коде приходится делать явно при загрузке значений. В скалярном коде ничего этого нет, компилятор сам понимает, что раз мы умножаем 8-битное целое на float, то первое тоже нужно конвертировать в float.
Коэффициент для всех каналов одного пикселя одинаков, так что нам снова пригодится _mm_set1_ps.
__m128 mmk = _mm_set1_ps(k[y - ymin]);Осталось умножить коэффициенты на каналы и сложить с аккумулятором:
__m128 mul = _mm_mul_ps(pix_ps, mmk);
sss = _mm_add_ps(sss, mul);Теперь в аккумуляторе sss находится значение каналов пикселя, которые правда могут выходить за диапазон [0, 255], а значит нужно как-то эти значения ограничить. Помните функцию clip8 из предыдущей статьи? В ней было два условных перехода. В случае с SIMD у нас нет возможности использовать условные переходы в зависимости от данных, потому что процессор должен выполнять одну и ту же команду для всех данных. Но на самом деле так даже лучше, потому что есть функции _mm_min_epi32 и _mm_max_epi32. Поэтому мы переводим значения в целые 32-битные числа со знаком, а потом обрезаем их в пределах [0, 255].
__m128i mmmax = _mm_set1_epi32(255);
__m128i mmmin = _mm_set1_epi32(0);
__m128i ssi = _mm_cvtps_epi32(sss);
ssi = _mm_max_epi32(mmmin, _mm_min_epi32(mmmax, ssi));К сожалению, инструкции, обратной _mm_cvtepu8_epi32, нет, поэтому я не придумал ничего лучше, чем сдвинуть нужные байты в самое начало и потом конвертировать SSE-регистр в регистр общего назначения с помощью _mm_cvtsi128_si32.
__m128i shiftmask = _mm_set_epi8(-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,12,8,4,0);
lineOut[xx] = _mm_cvtsi128_si32(_mm_shuffle_epi8(ssi, shiftmask));Обратите внимание, в маске shiftmask младшие байты идут справа. Для горизонтального прохода все точно так же, меняется только порядок загрузки пикселей: загружаются соседние пиксели из строки, а не из соседних строк.
Все готово, пришло время запустить тест и узнать результат.
Scale 2560×1600 RGB image
to 320x200 bil 0,01151 s 355.87 Mpx/s 161.4 %
to 320x200 bic 0,02005 s 204.27 Mpx/s 158.7 %
to 320x200 lzs 0,03421 s 119.73 Mpx/s 137.2 %
to 2048x1280 bil 0,04450 s 92.05 Mpx/s 215.0 %
to 2048x1280 bic 0,05951 s 68.83 Mpx/s 198.3 %
to 2048x1280 lzs 0,07804 s 52.49 Mpx/s 189.6 %
to 5478x3424 bil 0,18615 s 22.00 Mpx/s 215.5 %
to 5478x3424 bic 0,24039 s 17.04 Mpx/s 210.5 %
to 5478x3424 lzs 0,30674 s 13.35 Mpx/s 196.2 %Результат для коммита 8d0412b.
Прирост от двух с половиной до трех раз! Напомню, что тестирую я на трехканальном RGB-изображении, поэтому ускорение в 3 раза в данном случае можно считать эталонным.
Предыдущий вариант был почти 1 в 1 скопирован со скалярного кода. Причем для запаковки и распаковки использовались функции, появившиеся в последних версиях SSE: _mm_cvtepu8_epi32, _mm_max/min_epi32, _mm_shuffle_epi8. Очевидно, что люди как-то справлялись с этими задачами и с более ранними версиями SSE. И действительно, есть целый набор функций по запаковке/распаковке данных, _mm_pack* и _mm_unpack*. И если распаковка тут не сильно помогает (_mm_cvtepu8_epi32 лучше подходит для наших целей), то запаковку можно сильно упростить. Упростить так, что не понадобятся никакие константы для сдвига и обрезания значений (речь об mmmax, mmmin и shiftmask).
Дело в том, что функции запаковки _mm_packs* выполняются с насыщением (saturation), о чем говорит буква s в названии, например _mm_packs_epi32. Насыщение значит, что если при конвертации значение переменной выходит за пределы нового типа, то оно остается экстремальным для данного типа. Например если мы делаем преобразование из 16-битного целого со знаком в 8-битное без знака, то значение 257 преобразуется в 255, а -3 в 0. Получается, что функции упаковки одновременно и сдвигают значения и не дают выйти за границы диапазона.
__m128i ssi = _mm_cvtps_epi32(sss);
ssi = _mm_packs_epi32(ssi, ssi);
ssi = _mm_packus_epi16(ssi, ssi);
lineOut[xx] = _mm_cvtsi128_si32(ssi);У меня эта оптимизация не дает ускорения, но зато выглядит красиво и не требует дополнительных констант. Смотреть коммит b17cdc9.
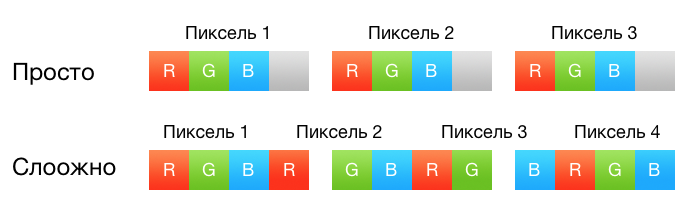
Если бы собака носила штаны, делала бы она это так или так?
А если бы регистры содержали в два раза больше данных? Когда я узнал, как работает AVX, то сразу вспомнил об этой картинке. При первом рассмотрении AVX инструкции кажутся странными и нелогичными. Это не просто «как SSE, только в 2 раза больше», в них есть какая-то непонятная логика. Взгляните сами на ту же инструкцию перемешивания, которой мы уже пользовались. Вот псевдокод SSE-версии:
FOR j := 0 to 15
i := j*8
IF b[i+7] == 1
dst[i+7:i] := 0
ELSE
index[3:0] := b[i+3:i]
dst[i+7:i] := a[index*8+7:index*8]
FI
ENDFORЛогично было бы предположить, что для AVX просто должен увеличиться счетчик с 15 до 31. Но нет, псевдокод AVX-версии намного мудренее:
FOR j := 0 to 15
i := j*8
IF b[i+7] == 1
dst[i+7:i] := 0
ELSE
index[3:0] := b[i+3:i]
dst[i+7:i] := a[index*8+7:index*8]
FI
IF b[128+i+7] == 1
dst[128+i+7:128+i] := 0
ELSE
index[3:0] := b[128+i+3:128+i]
dst[128+i+7:128+i] := a[128+index*8+7:128+index*8]
FI
ENDFORAVX — это не в два раза большее SSE, это два SSE! То есть на AVX-регистры стоит смотреть как на пару векторов. И эти вектора в большинстве команд друг с другом не взаимодействуют. Посмотрите на псевдокод AVX-команды еще раз, там четко видно, что первый блок работает только с младшими 128 битами, а второй только со старшими 128 битами. И нельзя перемешать так, чтобы в старших были младшие байты или наоборот. Причем, для этой инструкции разделение еще не слишком строгое: регистр, который говорит как сдвигать, может по-разному сдвигать верхнюю и нижнюю части. А зачастую бывает, что аргументы операций в обеих частях оказываются одинаковыми. Вот для примера псевдокод _mm256_blend_epi16:
FOR j := 0 to 15
i := j*16
IF imm8[j%8]
dst[i+15:i] := b[i+15:i]
ELSE
dst[i+15:i] := a[i+15:i]
FI
ENDFOR
dst[MAX:256] := 0Обратите внимание, что j итерируется до 15, а маска берется из байта по модулю восьми: imm8[j%8]. Т.е. у верхней и нижней части регистра всегда будет одинаковая маска. Еще много хлопот доставляет распаковка и запаковка, она тоже происходит независимо по верхним и нижним частям.
PACK_SATURATED(src[127:0]) {
dst[15:0] := Saturate_Int32_To_UnsignedInt16 (src[31:0])
dst[31:16] := Saturate_Int32_To_UnsignedInt16 (src[63:32])
dst[47:32] := Saturate_Int32_To_UnsignedInt16 (src[95:64])
dst[63:48] := Saturate_Int32_To_UnsignedInt16 (src[127:96])
RETURN dst[63:0]
}
dst[63:0] := PACK_SATURATED(a[127:0])
dst[127:64] := PACK_SATURATED(b[127:0])
dst[191:128] := PACK_SATURATED(a[255:128])
dst[255:192] := PACK_SATURATED(b[255:128])
dst[MAX:256] := 0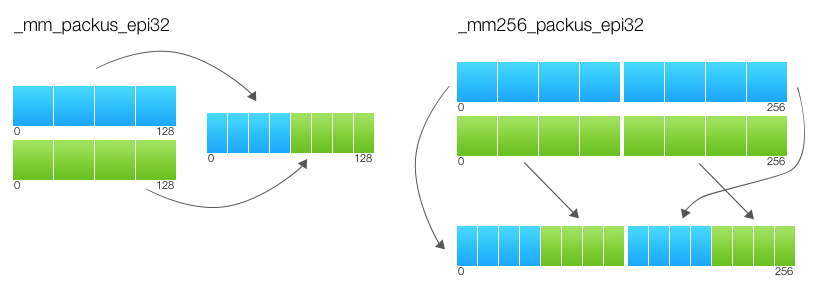
Нижние биты результата вычисляются только на основе нижних битов входных параметров. А верхние только на основе верхних. Я еще не встречал ни в одном источнике упоминания этого правила в явном виде, но его понимание сильно упрощает портирование SSE-кода на AVX.
Есть кое-что, что отличает и сами команды AVX от SSE. Помните проблему с зависимостью данных, рассмотренную в конце первой части? Она была учтена в AVX. Конечно, исправить поведение скалярных инструкций уже нельзя, но зато можно не допустить такой же ошибки при переходе от SSE к AVX. В псевдокоде каждой AVX-инструкции в конце есть строка:
dst[MAX:256] := 0Это значит, что AVX определяет поведение существующих команд с регистрами будущих поколений (512-битными и более). Но это еще не все. Для кодирования AVX-команд применяется система опкодов VEX. AVX включает в себя возможность кодировать в VEX даже SSE-инструкции. Закодированные таким образом SSE-инструкции также получают гарантии обнуления старших битов. Возможно, вы слышали о том, что существует пенальти около сотни тактов за использование AVX-команд после SSE или наоборот. Хорошая новость в том, что это пенальти не распространяется на SSE-команды, закодированные в VEX. И если пользоваться интринсиками, с флагом -mavx компилятор будет генерировать инструкции в новом формате. Плохая новость в том, что если код собран с -mavx и содержит SSE-команды, но не содержит ни одной AVX-команды, он все равно будет закодирован в VEX и не будет работать на процессорах без AVX. Т.е. не получится в рамках одного модуля сборки использовать SSE-инструкции в старом формате и AVX-инструкции:
if (is_avx_available()) {
resample_avx();
} else {
resample_sse();
}Потому что с флагом -mavx код из функции resample_sse() не запустится на процессоре без AVX, а без этого флага код из функции resample_avx() даже не скомпилируется.
До сих пор перевод на SIMD был достаточно простым, потому что в один SSE4-регистр влезает ровно один пиксель, представленный в виде четырех чисел с плавающей точкой. Но с AVX2 мы должны обрабатывать сразу 8 значений с плавающей точкой, то есть два пикселя. Но какие именно пиксели брать в один регистр? Тут мне снова хочется вставить картинку с собакой, которая носит штаны. Напомню, как выглядит каркас, например, горизонтальной свертки:
for (xx = 0; xx < xsize; xx++) {
xmin = xbounds[xx * 2 + 0];
xmax = xbounds[xx * 2 + 1];
for (x = xmin; x < xmax; x++) {
__m128i pix = lineIn[x];
__m128 mmk = k[x - xmin];
// Работа с пикселем
}
}Можно, например, взять соседние пиксели в строке: lineIn[x] и lineIn[x + 1], это самый очевидный вариант. Но тогда для этих пикселей придется готовить разные коэффициенты (k[x - xmin] и k[x - xmin + 1]). Да и расстояние от xmax до xmin может оказаться нечетным, и чтобы посчитать последний пиксель, нужно будет комбинировать SSE и AVX-код.
Можно взять пиксели в соседних строках: lineIn1[x] и lineIn2[x]. Но тогда загружать и выгружать пиксели придется как-то раздельно, что не очень удобно.
На самом деле любой способ будет иметь какие-то преимущества и недостатки. Скажу прямо, переводить горизонтальный проход на AVX2 не очень-то удобно. Другое дело вертикальный! Посмотрите на него:
for (xx = 0; xx < imIn->xsize; xx++) {
for (y = ymin; y < ymax; y++) {
__m128i pix = image32[y][xx];
__m128 mmk = k[y - ymin];
// Работа с пикселем
}
}Мы можем взять соседние пиксели в строке image32[y][xx] и image32[y][xx + 1] и у них будет одинаковый коэффициент. После выполнения внутреннего цикла в аккумуляторе будет результат для двух соседних пикселей, запаковать его тоже не составит труда. Короче, код можно переписать, просто поменяв все префиксы __m128 на __m256, а _mm_ на _mm256_. Единственное, что действительно отличается — использование функций _mm256_castsi256_si128 и _mm_storel_epi64 в конце. Первая — noop, просто приведение типов. А вторая сохраняет 64-битное значение из регистра в память.
Scale 2560×1600 RGB image
to 320x200 bil 0.01162 s 352.37 Mpx/s -0,9 %
to 320x200 bic 0.02085 s 196.41 Mpx/s -3,8 %
to 320x200 lzs 0.03247 s 126.16 Mpx/s 5,4 %
to 2048x1280 bil 0.03992 s 102.61 Mpx/s 11,5 %
to 2048x1280 bic 0.05086 s 80.53 Mpx/s 17,0 %
to 2048x1280 lzs 0.06563 s 62.41 Mpx/s 18,9 %
to 5478x3424 bil 0.15232 s 26.89 Mpx/s 22,2 %
to 5478x3424 bic 0.19810 s 20.68 Mpx/s 21,3 %
to 5478x3424 lzs 0.23601 s 17.36 Mpx/s 30,0 %Результат для коммита 86fe8a2.
Мы впервые получили небольшой проигрыш по производительности. Это не погрешность измерений, т.к. результат достаточно стабилен. Позже я объясню, почему так получилось. А пока видно, что выигрыш есть в основном при увеличении и не сильном уменьшении изображения. Как не трудно догадаться, так происходит потому, что вертикальный проход делается после горизонтального и поэтому оказывает большее влияние при большем размере конечного изображения. В целом же картина достаточно позитивная.
Для горизонтального прохода все же оказывается удобнее взять два соседних пикселя в строке. Тогда для них нужно будет подготовить разные коэффициенты:
__m256 mmk = _mm256_set1_ps(k[x - xmin]);
mmk = _mm256_insertf128_ps(mmk, _mm_set1_ps(k[x - xmin + 1]), 1);Ну а в конце результат в верхней части 256-битного регистра нужно будет сложить с результатом в нижней:
__m128 sss = _mm_add_ps(
_mm256_castps256_ps128(sss256),
_mm256_extractf128_ps(sss256, 1));Scale 2560×1600 RGB image
to 320x200 bil 0,00918 s 446.18 Mpx/s 26,6 %
to 320x200 bic 0,01490 s 274.90 Mpx/s 39,9 %
to 320x200 lzs 0,02287 s 179.08 Mpx/s 42,0 %
to 2048x1280 bil 0,04186 s 97.85 Mpx/s -4,6 %
to 2048x1280 bic 0,05029 s 81.44 Mpx/s 1,1 %
to 2048x1280 lzs 0,06178 s 66.30 Mpx/s 6,2 %
to 5478x3424 bil 0,16219 s 25.25 Mpx/s -6,1 %
to 5478x3424 bic 0,19996 s 20.48 Mpx/s -0,9 %
to 5478x3424 lzs 0,23377 s 17.52 Mpx/s 1,0 %Результат для коммита fd82859.
Тут мы снова видим для некоторых размеров небольшой проигрыш относительно предыдущего варианта. Но от обоих оптимизаций в сумме мы получили прирост от 6 до 50 процентов. В среднем AVX2-версия быстрее, чем SSE4-версия на 25%.
Много это или мало? Хотелось бы конечно получить от нового набора инструкций намного большего. Понятно, что на прирост в 100% рассчитывать не приходится, хотя бы 50% в среднем было бы тоже неплохо. Но имеем то, что имеем, и смысла отказываться от даже такого ускорения конечно же нет.
Осталось разобраться, почему же мы получали замедление для каждого шага в отдельности в некоторых случаях. Для этого нужно напомнить, на каком компьютере я запускаю тесты. Это обычный ноутбук с потребительским процессором Intel Core i5-4258U. Процессор имеет жесткие рамки по выделяемой мощности, поэтому для него приоритетна не максимальная производительность, а максимальная производительность на выделяемую мощность.
Как вы возможно знаете, последние лет восемь Интел маркирует свои процессоры двумя тактовыми частотами: номинальной и максимальной. Для i5-4258U это 2.4 ГГц и 2.9 ГГц. Со второй понятно — это максимальная частота, которую в принципе может осилить процессор. А первая — это минимальная частота, до которой может опуститься процессор под нагрузкой. Именно под нагрузкой, потому что без нагрузки в целях экономии энергии частота может опускаться гораздо ниже. Есть утилита, которая в реальном времени показывает частоту, температуру и потребление энергии процессором, а еще строит красивые графики. Она называется Intel Power Gadget. Утилита показывает, что во время работы SSE4-версии частота процессора стабильно держится на отметке 2.9 ГГц. При замене вертикального прохода на AVX2-версию, частота начинает скакать возле отметки 2.75 ГГц. А при полном AVX2-ускорении, частота практически не отклоняется от 2.6 ГГц. Т.е. процессор, выполняя AVX2-код, пасует и сбавляет обороты. А так как выигрыш от отдельных AVX2-проходов есть не для любых размеров изображения, мы можем наблюдать падение производительности из-за падения частоты. Однако при полном использовании AVX2 ускорение от более быстрого набора инструкций перекрывает незначительное падение частоты и мы все равно получаем выигрыш. Что тут можно сказать? Не останавливайтесь на полпути, переводите на AVX2 весь код.
Примечательно, что на сервере с процессором Xeon E5-2680 v2 (та же архитектура Haswell, что и в ноутбуке) подобного эффекта не наблюдается — там включение AVX2-проходов не дает падения частоты и, как следствие, не дает проседания производительности.