http://habrahabr.ru/post/240169/
На днях, у меня наконец-то дошли руки до обновления Zabbix.
С момента прочтения статьи
Вышел Zabbix 2.2 в соответствующем блоге, я не мог дождаться, когда же в Gentoo размаскируют версию 2.2. Практически не было такого нововведения в этой версии, которое бы мне не было интересно и полезно в «быту». Это и мониторинг VMware, и ускорение системы, и улучшения в LLDP, короче практически каждый пункт.
Шли месяцы, а версии 2.2 не было даже в замаскированных.
Иногда я откладываю текучку в сторону и занимаюсь чем-нибудь «параллельным» относительно срочных и важных задач и работ. В этот раз я вспомнил о желании обновить Zabbix до версии 2.2.
Проверил в маскированных*, ну наконец-то, есть 2.2.5
Ну все, переходим, прошел уже год с момента выпуска, версия stable'е не бывает, так что что бы ни случилось, решим.
Размаскировываем, собираем везде где нужно (основное это конечно сервер и прокси), перезапускаем. Переустанавливаем web интерфейс ииии…
И ничего, идет обновление БД.
Штука это не быстрая, база у меня не маленькая, а потом процесс вообще завис.
Ну думаю, началось, как говорится не успели начать, а уже все плохо.
В логах mysql было Error number 28 means 'No space left on device', места везде было более чем достаточно. Как говорится «при наличии гугла, я богоподобен» (с), не сразу, но удалось найти/догадаться что этот device это ibdata1 и ibdata2, размер которых регулируется параметром innodb_data_file_path. После того как я поменял max с 256M на 512М обновление базы завершилось успешно и сервер стартанул.
На прокси тоже были проблемы, и тоже из-за базы данных. Просто sqlite не обновляется, поэтому останавливаем прокси, удаляем старую базу и запускаем прокси. Как говорится внимательнее читайте Upgrade notes
Конечно за время обновления накопилось много просроченных данных, поэтому проверяем то что можем проверить, что в интерфейсе все показывается, и ждем, пока все устаканится и актуализируется.
Через пару часов, смотрим график:

День начинал становиться томным.
У нас очередь. Откуда?.. Основные просроченные данные с одного из прокси. А что за данные. А данные получаемые по SNMPv3.
Отлично. Были и раньше у меня к этому функционалу вопросы, но все руки не доходили, да была надежда что обновление эти вопросы решит. А тут система становится практически не работоспособной. В свое время, читая о том как люди с помощью одного сервера или прокси мониторят сотни сетевых девайсов я не мог понять в чем же дело? У меня несколько десятков устройств, и все работает на пределе. Уж и БД оптимизирована донельзя, и сервер положен на быстрый датастор, и памяти ему дано немало.
Откатываться назад не хотелось, поэтому было решено во что бы то ни стало попробовать разобраться с проблемой.
Я выбрал один из прокси, за которым больше всего SNMP устройств, и начал разбираться.
Вот что у нас в логах на прокси**:
4447:20141218:124053.605 SNMP agent item "ifAdminStatus.["10130"]" on host "co-xx02" failed: first network error, wait for 15 seconds
4468:20141218:124108.270 resuming SNMP agent checks on host "co-xx02": connection restored
И так беспорядочно по всем SNMP хостам, с разными итемами.
Сетевых проблем у меня точно нет, но для верности я конечно же по быстрому проверил связность, скорость и логи коммутаторов. Проверяем сам SNMP с помощью snmpwalk причем дергаем вообще все дерево. Никаких проблем.
Гуглим. У кого-то забиты поллеры, у кого-то некорректные таймауты, какой-то баг связанный с этим исправлен в версии 2.2.3. У кого-то хитрая проблема с сетью и теряется UDP. Но это все не наш случай.
Что тогда?..
Интересный факт, если перезагрузить прокси
/etc/init.d/zabbix-proxy restart
То видно как начинает сокращаться очередь, но потом бах, опять что-то происходит и она моментально вырастает***.
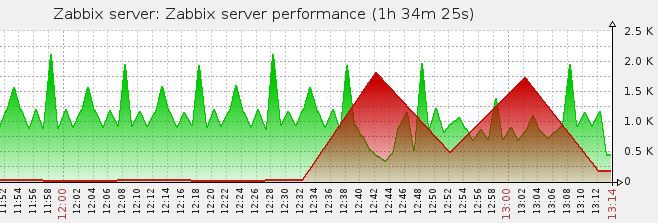
Что же происходит?..
Включаем расширенное логирование на zabbix-proxy
DebugLevel=4
Перезапускаем zabbix-proxy и ждем появления ошибок
Теперь вместо Network Error видим более полную информацию
Выглядит это примерно так5414:20141218:125955.481 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5414:20141218:125955.481 End of zbx_snmp_get_values():NETWORK_ERROR
5414:20141218:125955.481 End of zbx_snmp_process_standard():NETWORK_ERROR
5414:20141218:125955.481 In zbx_snmp_close_session()
5414:20141218:125955.481 End of zbx_snmp_close_session()
5414:20141218:125955.481 getting SNMP values failed: Cannot connect to "192.168.x.x:161": Too long.
5414:20141218:125955.481 End of get_values_snmp()
5414:20141218:125955.481 In deactivate_host() hostid:10207 itemid:43739 type:6
5414:20141218:125955.481 query [txnlev:1] [begin;]
5414:20141218:125955.481 query [txnlev:1] [update hosts set snmp_errors_from=1418896795,snmp_disable_until=1418896810,snmp_error='Cannot connect to "192.168.x.x:161": Too long.' where hostid=10207]
5414:20141218:125955.481 query [txnlev:1] [commit;]
5414:20141218:125955.481 SNMP agent item "ifOperStatus.["10143"]" on host "co-xx04" failed: first network error, wait for 15 seconds
5414:20141218:125955.481 deactivate_host() errors_from:1418896795 available:1
5414:20141218:125955.482 End of deactivate_host()
Статус 1, статус ошибки -1, число элементов 94
Здесь же вывод что это NETWORK_ERROR
И чуть ниже расшифровка Too long и деактивация хоста. Понятно что если хост деактивирован, данные с него получить нельзя, данные ставятся в очередь, вот и объяснение очереди.
Сразу же заинтересовал параметр errstat
Делаем cat /var/log/zabbix/zabbix_proxy.log | grep errstat
5412:20141218:130351.410 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:11
5433:20141218:130351.470 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5430:20141218:130351.476 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5417:20141218:130353.442 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:5
5420:20141218:130353.534 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
Ага, копаем глубжеЗдесь должна быть картинка We need to go deeper, но не будет. Мне кажется она всех достала.
Делаем cat /var/log/zabbix/zabbxi_proxy.log | grep errstat:-1
5416:20141218:130353.540 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5412:20141218:130355.571 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5417:20141218:130355.591 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
...
5420:20141218:130453.187 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5412:20141218:130455.206 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
5413:20141218:130455.207 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
Пришло время отключить мониторинг всех устройств за прокси кроме одного, т.к. иначе в логе слишком сложно разбираться. Все равно система в таком виде как сейчас для мониторинга не пригодна.
Отключаем, делаем
cat /var/log/zabbix/zabbxi_proxy.log | grep mapping_num
и перезагрузим прокси
Никаких ошибок первое время, да и mapping_num потихоньку растет от 1 все больше и больше (вырезаны отдельные строчки чтобы показать принцип)
Можно вечно смотреть за тем как растет mapping_num7876:20141218:131251.660 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:4
7872:20141218:131251.681 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:6
7872:20141218:131251.919 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:8
7876:20141218:131251.919 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:9
7868:20141218:131351.965 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:13
10502:20141218:135237.884 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31
10507:20141218:135238.244 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:62
12429:20141218:141637.942 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31
12429:20141218:141637.966 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31
12433:20141218:141651.142 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
А потом оппа 94, и -1 и too long. Т.е. сразу после запуска прокси тестирует устройства, посылает им SNMP запросы, увеличивая количество итемов в одном запросе. Очередь начинает быстро сокращаться. Потом он (то бишь прокси) доходит до волшебного числа 94, происходит сбой и устройства начинают отключаться заббиксом на 15 секунд, что в свою очередь начинает резко увеличивать очередь.
Как видим, здесь уже совсем не Network error, здесь уже Too long.
Ладно пробуем что-то найти по zabbix snmp too long, ничего.
Опять таймауты, перегрузка поллера… В одном интересном посте была информация, что такая ошибка возникала когда был неверно сформирован OID для итема, так что я дважды проверил все свои OID'ы в том числе через snmpget
Т.е. в итоге гугл мне помочь не смог.
Будем разбираться сами, это полезно.
Итак, что у нас есть?
Как только число итемов становится 94 (т.е. достаточно большим) что-то происходит и система сбивается.
Здесь опять картинка, которой не будет ;)
Пора лезть в код. В gentoo ничего качать не надо, уже все есть, так что я просто распаковал все в рабочую директорию.
Найдем сначала где выводится ошибка. Ищем по errstat
На удивление всего два таких места в файле с говорящим названием checks_snmp.c
вот эти два места:
со строки 745
/* communicate with agent */
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld max_vars:%d",
__function_name, status, NULL == response ? (long)-1 : response->errstat, max_vars);
и со строки 938
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d",
__function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num);
Пока нас интересует второй кусок (исходя из того что mapping_num есть только в нем)
Даже не программист видит, что у нас response NULL, а почему?..
Вспомним, что при errstat:-1, который теперь понятно откуда берется, у нас status:1. Т.е. функция snmp_synch_response возвращает 1, а что это значит?..
А это значит STAT_ERROR (1) (а еще она умеет STAT_TIMEOUT (2) и STAT_SUCCESS (0))
Как говорится непонятно, но здорово…
Зайдем с другой стороны, где-то здесь же в этом файле должен быть возврат NETWORK_ERROR попробуем разобраться где и почему.
Первое же вхождение в функции zbx_get_snmp_response_error (что как бы намекает)
Посмотреть код zbx_get_snmp_response_errorstatic int zbx_get_snmp_response_error(const struct snmp_session *ss, const DC_INTERFACE *interface, int status,
const struct snmp_pdu *response, char *error, int max_error_len)
{
int ret;
if (STAT_SUCCESS == status)
{
zbx_snprintf(error, max_error_len, "SNMP error: %s", snmp_errstring(response->errstat));
ret = NOTSUPPORTED;
}
else if (STAT_ERROR == status)
{
zbx_snprintf(error, max_error_len, "Cannot connect to \"%s:%hu\": %s.",
interface->addr, interface->port, snmp_api_errstring(ss->s_snmp_errno));
switch (ss->s_snmp_errno)
{
case SNMPERR_UNKNOWN_USER_NAME:
case SNMPERR_UNSUPPORTED_SEC_LEVEL:
case SNMPERR_AUTHENTICATION_FAILURE:
ret = NOTSUPPORTED;
break;
default:
ret = NETWORK_ERROR;
}
}
else if (STAT_TIMEOUT == status)
{
zbx_snprintf(error, max_error_len, "Timeout while connecting to \"%s:%hu\".",
interface->addr, interface->port);
ret = NETWORK_ERROR;
}
else
{
zbx_snprintf(error, max_error_len, "SNMP error: [%d]", status);
ret = NOTSUPPORTED;
}
return ret;
}
Ага. Т.е. мы со своим STAT_ERROR входим в switch где не попадаем ни под одно из приведенных условий, и таким образом получаем NETWORK_ERROR по дефолту.
Мы уже поняли что этот дефолт дезориентирует нас, нужно выяснить что же это за ошибка на самом деле. Код ошибки хранится в ss->s_snmp_errno, добавим вывод переменной в лог.
Программист из меня так себе, так что быстренько с помощью лома и чьей-то матери (с) сляпал патчик, вот такой:
diff -urN zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c
--- zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c 2014-07-17 17:49:45.000000000 +0400
+++ zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c 2014-10-10 16:38:31.000000000 +0400
@@ -938,7 +938,7 @@
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d",
- __function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num);
+ __function_name, status, NULL == response ? (STAT_ERROR == status ? (long) ss->s_snmp_errno : (long)-1) : response->errstat, mapping_num);
if (STAT_SUCCESS == status && SNMP_ERR_NOERROR == response->errstat)
{
Если статус STAT_ERROR выводить ss->s_snmp_errno
Закинул исходник заббикса в локальный репозиторий, быстро подправил ебилд и вперед.
Компилим, перезапускаем, ждем.
И вот она наша реальная ошибка.
11211:20141218:155253.362 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:18
11210:20141218:155253.393 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-5 mapping_num:94
Ошибка -5
Смотрим Net-SNMP snmp_api.h
#define SNMPERR_TOO_LONG (-5)
Что-то похожее было видно в логах, но по словосочетанию Too Long мы найти ничего не смогли, посмотрим что же это за ошибка и когда возникает.
в snmp_api.c можно это увидеть
еще немного кода/*
* Make sure we don't send something that is bigger than the msgMaxSize
* specified in the received PDU.
*/
if (pdu->version == SNMP_VERSION_3 && session->sndMsgMaxSize != 0 && length > session->sndMsgMaxSize) {
DEBUGMSGTL(("sess_async_send",
"length of packet (%lu) exceeds session maximum (%lu)\n",
(unsigned long)length, (unsigned long)session->sndMsgMaxSize));
session->s_snmp_errno = SNMPERR_TOO_LONG;
SNMP_FREE(pktbuf);
return 0;
}
/*
* Check that the underlying transport is capable of sending a packet as
* large as length.
*/
if (transport->msgMaxSize != 0 && length > transport->msgMaxSize) {
DEBUGMSGTL(("sess_async_send",
"length of packet (%lu) exceeds transport maximum (%lu)\n",
(unsigned long)length, (unsigned long)transport->msgMaxSize));
session->s_snmp_errno = SNMPERR_TOO_LONG;
SNMP_FREE(pktbuf);
return 0;
}
Есть всего два варианта:
1. Длина данных которые мы хотим послать больше чем параметр msgMaxSize определенный в полученном PDU
2. Нижележащий транспорт не способен послать пакет такой длины
Возникает вопрос как же пофиксить эту ошибку. Из вышесказанного следует, что нужно искать получаем ли мы msgMaxSize, правильно ли мы это обрабатываем и т.д. и т.п. Но я исходники zabbix вижу в первый раз, а C во второй (ну ладно в третий).
Короче не вызывает энтузиазма… Да и поломать наверное что-нибудь можно будет.
Лирическое отступление:
Надо сказать, что во время разбирательств с этой проблемой, я в том числе наткнулся на информацию о массовой обработке SNMP. Т.е. zabbix одним запросом может запросить множество SNMP элементов данных.
Подробности SNMP bulk processing
Суть в том, что zabbix умеет запрашивать до 128 значений одним запросом, но не все устройства способны обработать эти 128 значений за один раз. И в zabbiх используется стратегия поиска максимального значения для каждого конкретного устройства. Мы кстати видели это в логах. Постепенное повышение mapping_num. Как только zabbix получает ошибку от устройства SNMPERR_TOO_BIG он по определенному алгоритму ищет максимальное значение возвращающее результаты без ошибок.
К чему это я.
Механизм обработки ошибки переполнения (назовем его так) в заббиксе есть, надо его всего лишь расширить на еще один случай.
Сам алгоритм расписан под выводом нашей ошибки.
Опять этот кодelse if (1 < mapping_num &&
((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status))
{
/* Since we are trying to obtain multiple values from the SNMP agent, the response that it has to */
/* generate might be too big. It seems to be required by the SNMP standard that in such cases the */
/* error status should be set to "tooBig(1)". However, some devices simply do not respond to such */
/* queries and we get a timeout. Moreover, some devices exhibit both behaviors - they either send */
/* "tooBig(1)" or do not respond at all. So what we do is halve the number of variables to query - */
/* it should work in the vast majority of cases, because, since we are now querying "num" values, */
/* we know that querying "num/2" values succeeded previously. The case where it can still fail due */
/* to exceeded maximum response size is if we are now querying values that are unusually large. So */
/* if querying with half the number of the last values does not work either, we resort to querying */
/* values one by one, and the next time configuration cache gives us items to query, it will give */
/* us less. */
if (*min_fail > mapping_num)
*min_fail = mapping_num;
if (0 == level)
{
/* halve the number of items */
int base;
ret = zbx_snmp_get_values(ss, items, oids, results, errcodes, query_and_ignore_type, num / 2,
level + 1, error, max_error_len, max_succeed, min_fail);
if (SUCCEED != ret)
goto exit;
base = num / 2;
ret = zbx_snmp_get_values(ss, items + base, oids + base, results + base, errcodes + base,
NULL == query_and_ignore_type ? NULL : query_and_ignore_type + base, num - base,
level + 1, error, max_error_len, max_succeed, min_fail);
}
else if (1 == level)
{
/* resort to querying items one by one */
for (i = 0; i < num; i++)
{
if (SUCCEED != errcodes[i])
continue;
ret = zbx_snmp_get_values(ss, items + i, oids + i, results + i, errcodes + i,
NULL == query_and_ignore_type ? NULL : query_and_ignore_type + i, 1,
level + 1, error, max_error_len, max_succeed, min_fail);
if (SUCCEED != ret)
goto exit;
}
}
}
То есть все просто, нам надо добавить свое условие, не нарушив работу имеющихся. Для этого у нас есть все данные:
- status должен быть STAT_ERROR
- ss->s_snmp_errno должен быть SNMPERR_TOO_LONG
Учитываем еще что у нас два таких места (равно как и два вывода в лог-файл) и результирующий патч будет таким:
Наконец-тоdiff -urN zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c
--- zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c 2014-07-17 17:49:45.000000000 +0400
+++ zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c 2014-10-10 16:38:31.000000000 +0400
@@ -746,10 +746,10 @@
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld max_vars:%d",
- __function_name, status, NULL == response ? (long)-1 : response->errstat, max_vars);
+ __function_name, status, NULL == response ? (STAT_ERROR == status ? (long)ss->s_snmp_errno : (long)-1) : response->errstat, max_vars);
if (1 < max_vars &&
- ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status))
+ ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status || (STAT_ERROR == status && SNMPERR_TOO_LONG == ss->s_snmp_errno)))
{
/* The logic of iteratively reducing request size here is the same as in function */
/* zbx_snmp_get_values(). Please refer to the description there for explanation. */
@@ -938,7 +938,7 @@
status = snmp_synch_response(ss, pdu, &response);
zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d",
- __function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num);
+ __function_name, status, NULL == response ? (STAT_ERROR == status ? (long) ss->s_snmp_errno : (long)-1) : response->errstat, mapping_num);
if (STAT_SUCCESS == status && SNMP_ERR_NOERROR == response->errstat)
{
@@ -1001,7 +1001,7 @@
}
}
else if (1 < mapping_num &&
- ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status))
+ ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status || (STAT_ERROR == status && SNMPERR_TOO_LONG == ss->s_snmp_errno)))
{
/* Since we are trying to obtain multiple values from the SNMP agent, the response that it has to */
/* generate might be too big. It seems to be required by the SNMP standard that in such cases the */
Компилируем, перезапускаем…
И вот результат:
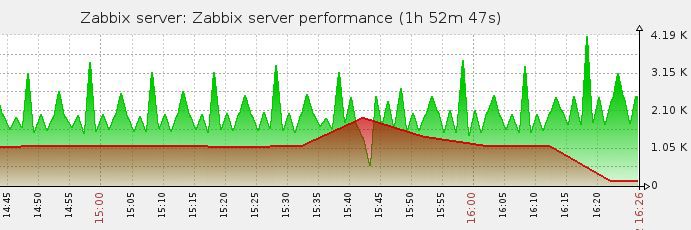
Ошибка Network Error пропала из логов.
Ура!..
Послесловие
Конечно, в действительности, поиск ошибки и решения занял больше времени. Пришлось больше ковырять исходники и zabbix и net-snmp, чтобы в итоге остановиться на двух местах в коде.
Но ощущение победы над «косной материей» бесценно.
* желание накатило 7 октября, а тогда 2.2.5 еще была замаскирована. По случайному совпадению ее размаскировали 10 октября;
** на время не смотрите, для написания статьи сымитировал ситуацию позже. Во время разборок, выдергивать из логов данные совершенно не было времени, поток, куда деваться;
*** да, да, картинку я тоже смоделировал. Представьте что там где зеленое в начале, там все красное ;) А потом пила во время рестартов.