Как я парсил Хабр, часть 1: тренды
- среда, 10 января 2018 г. в 03:14:00
Когда был доеден новогодний оливье, мне стало нечего делать, и я решил скачать себе на компьютер все статьи с Хабрахабра (и смежных платформ) и поисследовать.
Получилось несколько интересных сюжетов. Первый из них — это развитие формата и тематики статей за 12 лет существования сайта. Например, достаточно показательна динамика некоторых тем. Продолжение — под катом.

Чтобы понять, как развивался Хабр, нужно было обойти по все его статьи и выделить из них метаинформацию (например, даты). Обход дался легко, потому что ссылки на все статьи имеют вид "habrahabr.ru/post/337722/", причём номера задаются строго по порядку. Зная, что последний пост имеет номер чуть меньше 350 тысяч, я просто прошёлся по всем возможным id документов циклом (код на Python):
import numpy as np
from multiprocessing import Pool
with Pool(100) as p:
docs = p.map(download_document, np.arange(350000))Функция download_document пытается загружает страницу с соответствующим id и пытается вытащить из структуры html содержательную информацию.
import requests
from bs4 import BeautifulSoup
def get_doc_by_id(pid):
""" Download and process a Habr document and its comments """
# выгрузка документа
r = requests.get('https://habrahabr.ru/post/' +str(pid) + '/')
# парсинг документа
soup = BeautifulSoup(r.text, 'html5lib') # instead of html.parser
doc = {}
doc['id'] = pid
if not soup.find("span", {"class": "post__title-text"}):
# такое бывает, если статья не существовала или удалена
doc['status'] = 'title_not_found'
else:
doc['status'] = 'ok'
doc['title'] = soup.find("span", {"class": "post__title-text"}).text
doc['text'] = soup.find("div", {"class": "post__text"}).text
doc['time'] = soup.find("span", {"class": "post__time"}).text
# create other fields: hubs, tags, views, comments, votes, etc.
# ...
# сохранение результата в отдельный файл
fname = r'files/' + str(pid) + '.pkl'
with open(fname, 'wb') as f:
pickle.dump(doc, f)В процессе парсинга открыл для себя несколько новых моментов.
Во-первых, говорят, что создавать больше процессов, чем ядер в процессоре, бесполезно. Но в моём случае оказалось, что лимитирующий ресурс — не процессор, а сеть, и 100 процессов отрабатывают быстрее, чем 4 или, скажем, 20.
Во-вторых, в некоторых постах встречались сочетания спецсимволов — например, эвфемизмы типа "%&#@". Оказалось, что html.parser, который я использовал сначала, реагирует на комбинацию &# болезненно, считая её началом html-сущности. Я уж было собирался творить чёрную магию, но на форуме подсказали, что можно просто поменять парсер.
В-третьих, мне удалось выгрузить все публикации, кроме трёх. Документы под номерами 65927, 162075, и 275987 моментально удалил мой антивирус. Это статьи соответственно про цепочку джаваскриптов, загружающую зловредный pdf, SMS-вымогатель в виде набора плагинов для браузеров, и сайт CrashSafari.com, который отправляет айфоны в перезагрузку. Ещё одну статью антивирь обнаружил позднее, во время скана системы: пост 338586 про скрипты на сайте зоомагазина, использующие процессор пользователя для майнинга криптовалюты. Так что можно считать работу антивируса вполне адекватной.
"Живых" статей оказалась только половина от потенциального максимума — 166307 штук. Про остальные Хабр даёт варианты "страница устарела, была удалена или не существовала вовсе". Что ж, всякое бывает.
За выгрузкой статей последовала техническая работа: например, даты публикации нужно было перевести из формата "'21 декабря 2006 в 10:47" в стандартный datetime, а "12,8k" просмотров — в 12800. На этом этапе вылезло ещё несколько казусов. Самый весёлый связан с подсчётом голосов и типами данных: в некоторых старых постах произошло переполнение инта, и они получили по 65535 голосов.

В результате тексты статей (без картинок) заняли у меня 1.5 гигабайта, комментарии с метаинформацией — ещё 3, и около сотни мегабайт — метаинформация о статьях. Такое можно полностью держать в оперативной памяти, что было для меня приятной неожиданностью.
Начал анализ статей я не с самих текстов, а с метаинформации: дат, тегов, хабов, просмотров и "лайков". Оказалось, что и она может многое поведать.
Статьи на сайте публикуются с 2006 года; наиболее интенсивно — в 2008-2016 годах.
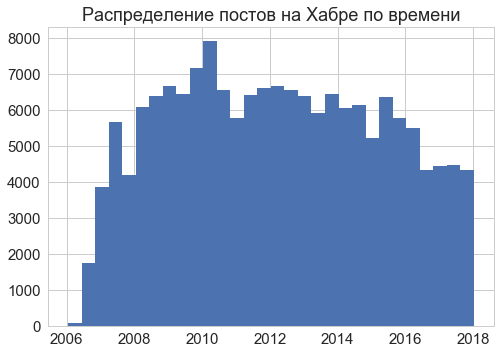
Насколько активно эти статьи читали в разное время, оценить не так просто. Тексты 2012 года и младше более активно комментировали и рейтинговали, но у более новых текстов больше просмотров и добавлений в закладки. Одинаково вели себя (вдвое упали) эти метрики только однажды, в 2015 году. Возможно, в ситуации экономического и политического кризиса внимание читателей перешло с айтишных блогов к более болезненным вопросам.
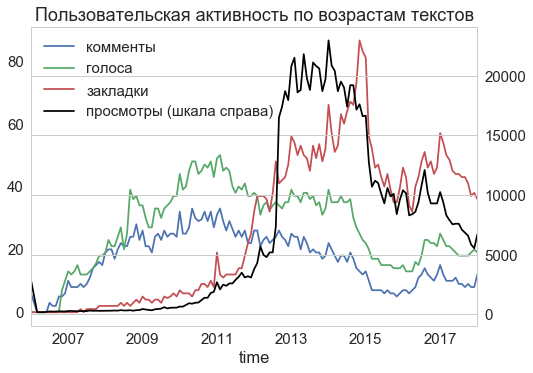
Кроме самих статей, я выкачал ещё комментарии к ним. Комментариев получилось 6 миллионов, правда, 240 тысяч из них оказались забаненными ("нло прилетело и опубликовало эту надпись здесь"). Полезное свойство комментариев в том, что для них указано время. Изучая время комментариев, можно примерно понять и то, когда вообще статьи читают.
Оказалось, что большую часть статей и пишут, и комментируют где-то с 10 до 20 часов, т.е. в типичный московский рабочий день. Это может значить и что Хабр читают в профессиональных целях, и что это хороший способ прокрастинации на работе. Кстати, это распределение времени суток стабильно с самого основания Хабра до сегодняшнего дня.

Однако основная польза от метки времени комментария — не время суток, а срок "активной жизни" статьи. Я подсчитал, как распределено время от публикации статьи до её комментария. Оказалось, что сейчас медианный комментарий (зелёная линия) приходит примерно через 20 часов, т.е. в первые сутки после публикации оставляют в среднем чуть больше половины всех комментариев к статье. А за двое суток оставляют 75% всех комментариев. При этом раньше статьи читали ещё быстрее — так, в 2010 году половина комментариев приходила уже в первые 6 часов.

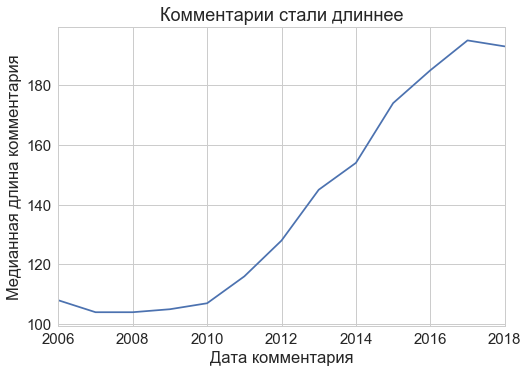
Для меня стало сюрпризом, что комментарии удлинились: среднее количество символов в комментарии за время существования Хабра выросло почти вдвое!
Более простая обратная связь, чем комментарии — это голоса. В отличие от многих других ресурсов, на Хабре можно ставить не только плюсы, но и минусы. Впрочем, последней возможностью читатели пользуются не так часто: текущая доля дизлайков составляет около 15% от всех отданных голосов. Раньше было больше, но со временем читатели подобрели.

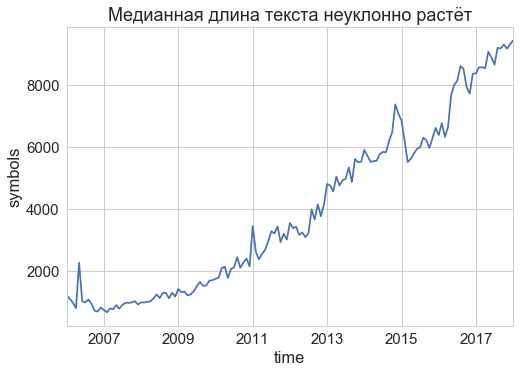
Менялись со временем и сами тексты. Например, типичная длина текста не прекращает устойчиво расти с самого запуска сайта, несмотря на кризисы. За десятилетие тексты стали почти в десять раз длиннее!
Стилистика текстов (в первом приближении) тоже менялась. За первые годы существования Хабра, например, выросла доля кода и чисел в текстах:

Разобравшись с общей динамикой сайта, я решил измерить, как менялась популярность различных тем. Темы можно выделять из текстов автоматически, но для начала можно не изобретать велосипед, а воспользоваться готовыми тегами, проставленными авторами каждой статьи. Четыре типичных тренда я вывел на графике. Тема "Google" изначально доминировала (возможно, в основном в связи с SEO-оптимизацией), но с каждым годом теряла вес. Javascript был популярной темой и продолжает постепенно, а вот машинное обучение начало стремительно набирать популярность лишь в последние годы. Linux же остаётся одинаково актуальным на протяжении всего десятилетия.

Конечно же, мне стало интересно, какие темы привлекают больше читательской активности. Я подсчитал медианное число просмотров, голосов и комментов в каждой теме. Вот что получилось:
Кстати, раз уж я сравниваю темы, можно сделать их рейтинг по частоте (и сравнить результаты с аналогичной статьёй от 2013 года).
При сравнении этих рейтингов можно обратить внимание, например, на победоносное шествие Питона и вымирание php, или на "закат" стартаперской тематики и взлёт машинного обучения.
Не все теги на Хабре имеют столь очевидную тематическую окраску. Вот, например, десяток тегов, которые встречались всего лишь один раз, но просто показались мне забавными. Итак: "идея движитель прогресса", "загрузка с образа дискеты", "штат айова", "драматургия", "супералеша", "паровой двигатель", "чем заняться в субботу", "у меня лисица в мясорубке", "а получилось как всегда", "смешных тэгов придумать не удалось". Чтобы определить тематику таких статей, тегов недостаточно — придётся осуществлять тематическое моделирование над текстами статей.
Более подробный анализ содержания статей будет в следующем посте. Во-первых, я собираюсь построить модель, прогнозирующую количество просмотров статьи в зависимости от её содержания. Во-вторых, хочется научить нейросеть генерировать тексты в той же стилистике, что и у авторов Хабра. Так что подписывайтесь :)