https://habrahabr.ru/post/343116/- Регулярные выражения
- Высокая производительность
- Алгоритмы
- Python
От переводчика
Не так давно столкнулся с проблемой поиска набора слов в большом тексте. Разумеется главной проблемой стала производительность. Поиск готовых решений порождал больше вопросов, чем давал ответов. Часто я натыкался на примеры использования каких-то сторонних коробок или онлайн-сервисов. А мне в первую очередь нужно было простое и легкое решение, которое в дальнейшем дало бы мысли для реализации собственной утилиты.
Несколько недель назад вышла замечательная англоязычная статься об open-source python-библиотеки
FlashText. Эта библиотека предоставляла быстрое работающее решение задачи поиска и замены ключевых слов в тексте.
Т.к. на русском материалов подобной тематики не так много, то я решил перевести эту статью на русский. Под катом вас ждет описание проблемы, разбор принципа работы библиотеки а так же примеры тестов производительности.
Начало
Основной задачей при работе с текстом является его очистка. Обычно этот процесс очень прост. К примеру нам нужно заменить словосочетание «Javascript» на «JavaScript». Но чаще нам нужно просто найти все упоминания словосочетания «Javascript» в тексте.
Задача очистки данных — это типичная задача для большинства проектов, работающих в области
даталогии (науки о данных).
Даталогия начинается с очистки данных
Недавно я решал именно такую задачу. Я работаю исследователем в
Belong.co и
обработка естественного языка занимает половину моего времени.
Когда я начал использовать
Word2Vec для анализа нашего
текстового корпуса, то понял, что синонимы анализировались, как одно значение. К примеру термин «Javascripting» использовался вместо «Jacascript» и.т.д.
Чтобы решить эту проблему мне понадобилось очистить текст. Для этого я написал приложение, использующее регулярное выражение, которое заменяло все возможные синонимы словосочетания «Javascript» на его исходную форму. Однако это породило лишь новые проблемы.
Some people, when confronted with a problem, think
“I know, I’ll use regular expressions.” Now they have two problems.
Данную цитату первый раз я встретил
тут и именно она характеризовала мой случай. Оказывается регулярное выражение выполняется относительно быстро, только в том случае, если число ключевых слов, которые необходимо найти и заменить в исходном тексте, не превышает лишь нескольких сотен. Но наш текстовый корпус состоял из более чем 3 миллионов документов и 20 тысяч ключевых слов.
Когда я оценил время, которое потребуется на замену всех ключевых слов, при помощи регулярных выражений, то оказалось что нам потребуется
5 дней для одного прогона нашего текстового корпуса.
Первое решение подобной проблему напрашивалось само собой: параллельный запуск нескольких процессов поиска и замены. Однако этот подход перестал быть эффективным, после того как увеличился объем данных. Теперь текстовый корпус состоял из десятков миллионов документов и сотен тысяч ключевых слов.
Но я был уверен, что должно быть лучшее решение этой проблемы! И я начал искать его…
Я поспрашивал коллег в моем офисе, задал несколько вопросов на
Stack Overflow. В результате у меня была пара неплохих предложений.
Vinay Pandey, Suresh Lakshmanan
в
обсуждение посоветовали попробовать
алгоритм Ахо-Корасик и
префиксное дерево.
Мои попытки найти готовое решение не увенчались успехом. Я не нашёл ни одной стоящей библиотеки. В результате я решил реализовать предложенные алгоритмы в контексте моей задачи. Таким образом и появился на свет
FlashText.
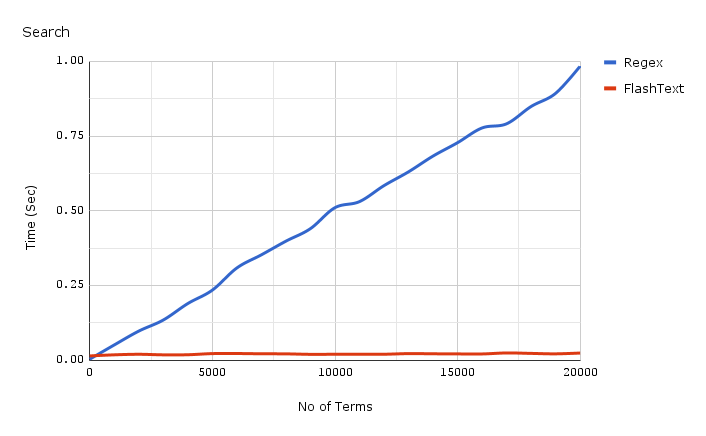
Прежде чем мы окунемся в детали реализации FlashText, давайте посмотрим как возросла скорость
поиска.
График показывает зависимость времени работы от числа ключевых слов, при выполнение операции поиска ключевых слов в одном документе. Как мы видим, время затраченное приложением использующим регулярное выражение линейно зависит от числа ключевых слов. Для FlashText такой зависимости не наблюдается.
FlashText уменьшил время одного прогона нашего текстового корпуса с 5 дней до 15 минут.
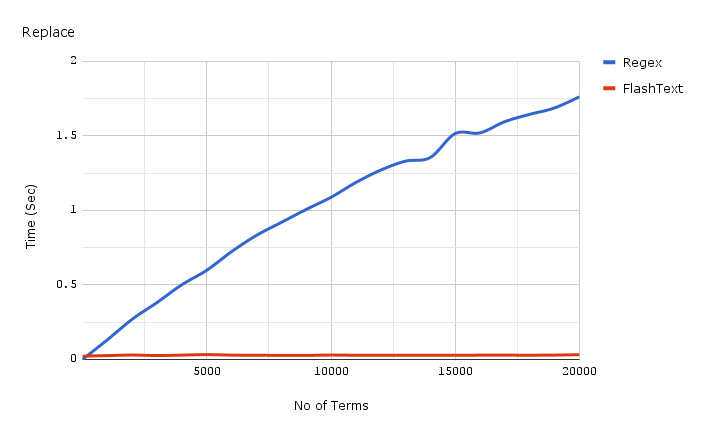
Ниже приведен график зависимости затраченного времени от числа ключевых слов при выполнении операции
замены в одном документе.
Код для получения бенчмарков, используемых для графиков, представленных выше можно найти
здесь, а сами бенчмарки
здесь.
Так что же такое FlashText ?
FlashText это небольшая open-source Python-библиотека, которая выложена на
GitHub. Она одинаково успешно справляется как с задачей поиска, так и задачей замены ключевых слов в текстовом документе.
Первым шагом при использовании FlashText является составление корпуса ключевых слов, который будет использоваться библиотекой для построения префиксного дерева. После чего на вход библиотеки подается текст для которого будет выполнятся процедура поиска или замены.
При
замене FlashText создаст новую строку с замененными ключевыми словами. При
поиске библиотека вернёт список ключевых слов, найденных во входной строке. В обоих случаях результат будет получен за один проход входной строки.
В twitter уже появились первые положительные отзывы от счастливых пользователей:
Почему FlashText настолько быстрее ?
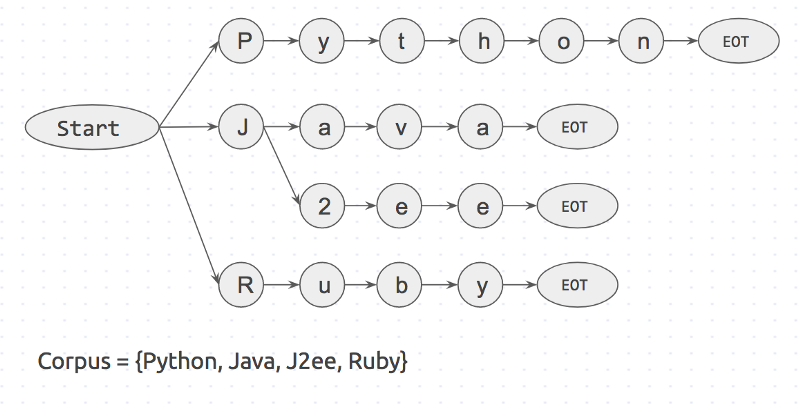
Давайте рассмотрим пример работы. Пусть у нас есть текст состоящий из трех слов:
I like Python и корпус ключевых слов, состоящий из 4 слов:
{ Python, Java, J2ee, Ruby }.
Если мы будем проверять наличие каждого ключевого слова из корпуса в исходном тексте, то у нас будет 4 итерации поиска:
is 'Python' in sentence?
is 'Java' in sentence?
...
Из псевдокода мы видим, что если список ключевых слов будет состоять из
n элементов, то нам понадобиться
n итераций.
Но мы можем поступить наоборот: проверять существование каждого слова из исходного текста в корпусе ключевых слов.
is 'I' in corpus?
is 'like' in corpus?
is 'python' in corpus?
Если предложение состоит из
m слов, то у нас будет
m итераций. Общее время выполнения операций будет прямо пропорционально зависеть от числа слов в тексте. Стоит отметить, что поиск слова в корпусе ключевых слов будет выполняться быстрее, чем поиск ключевого слова в тексте, т.к. корпус ключевых слов представляет из себя словарь.
В основе FlashText лежит второй подход. В его реализации так же использованы
алгоритм Ахо-Корасик и
префиксное дерево.
Алгоритм работы следующий:
Вначале создается префиксное дерево для корпуса ключевых слов. Оно будет выглядеть так:
«Start» и «EOT» представляют из себя границы слов: пробел, новая строка и т.д. Ключевое слово будет совпадать с входным значением, только в том случае если слово имеет пограничные символы с обоих сторон. Такой подход исключит ошибочные совпадения, такие как «apple» и «pineapple».
Далее рассмотрим пример. Возьмем строку
I like Python и начнем поэлементный поиск в ней ключевых слов.
Step 1: is <start>I<EOT> in dictionary? No
Step 2: is <start>like<EOT> in dictionary? No
Step 3: is <start>Python<EOT> in dictionary? Yes
Ниже представлено префиксное дерево для шага 3.
is <start>Python<EOT> in dictionary? Yes
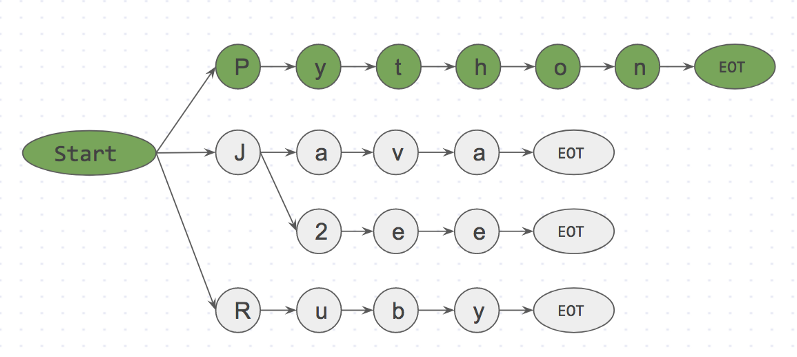
Благодаря такому подходу мы можем уже на первом символе отбросить like<EOT/>, потому что символ
i не расположен рядом с
start. Таким образом мы практически мгновенно можем откинуть слова, которые не входят в корпус и не тратить на них время.
Алгоритм FlashText будет анализировать символы входной строки
I like Python, в то время как корпус ключевых слов может иметь любые размеры. Размер корпуса корпус ключевых слов никак не скажется на быстродействие алгоритма. Это и есть основной секрет алгоритма FlashText.
Когда вам нужно использовать FlashText ?
Всё очень просто: как только размер корпуса ключевых слов становится больше 500, то появляется этот график.
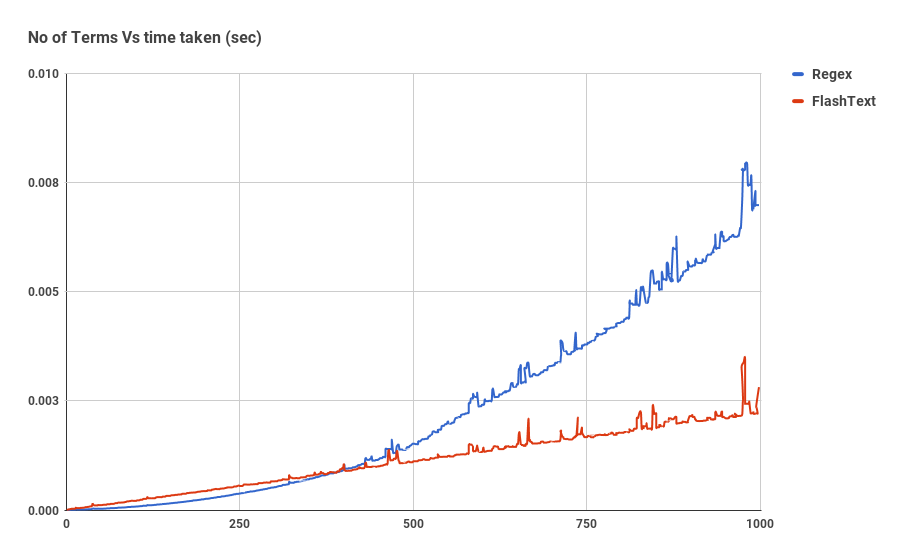
Однако стоит отметить, что Regex, в отличие от FlashText, может искать в исходной строке специальные символы такие как
^,$,*,\d,, которые не поддерживаются алгоритмом FlashText. То есть включать в корпус ключевых слов элемент
word\dvec не стоит, а вот с элементом
word2vec всё отработает отлично.
Как запустить FlashText для поиска ключевых слов
# pip install flashtext
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
# ['New York', 'Bay Area']
Тоже самое на GitHubКак запустить FlashText для замены ключевых слов
В общем то это была основная задача ради которой разрабатывался FlashText. У нас это используется для очистки данных перед обработкой.
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
# 'I love New York and NCR region.'
Тоже самое на GitHub
Если у вас есть коллеги которые работают с анализом тестовых данных,
распознаванием упоминаний сущностей,
обработкой естественного языка или
Word2vec, то прошу поделиться этой статьей с ними.
Эта библиотека оказалась очень полезной для нас и я уверен, что она сможет пригодиться кому-нибудь ещё.
Получилось длинно. Спасибо, что дочитали.