Как я чинил интерактивный логин, или Что там в кишках у //chrome/test/ChromeDriver?
- вторник, 23 января 2018 г. в 03:13:48
Эта статья возникла из-за одной моей ошибки и двух багов — по одному в Chromium Headless и ChromeDriver. В результате пришлось собрать всё это из исходников (в статье есть подробнейшая инструкция), отладить цепочку взаимодействия Selenium<->ChromeDriver<->Chromium в отладчике IntelliJ IDEA и Microsoft Visual Studio, покопаться в Java, C++ и JS.
Статья будет интересна тем, кто хочет понять, чем им грозит переход на Selenium + Headless Chrome и как с этим жить. А также всем, кто просто хочет немного поглумиться над несчастным быдлокодером.
Под катом есть пачка скриншотов (трафик!).

Кстати, всё это можно было бы сделать скринкастом — но нельзя, потому что время компиляции C++ необычайно долгое. Вместо этого тут будут скриншоты для привлечения внимания.
Вначале напомню названия участвующих продуктов. Их три штуки:
Всё вместе даёт нам в руки браузер, управляемый с помощью API на Java, JavaScript и так далее.
Вспомнили? Поехали дальше.
Завязка в том, что в одном из моих пет-проектов я парсю Хабр. Этот эксперимент называется Textorio, но там ещё нечего смотреть, я ещё даже не выкладывал код. Кстати, отправляется самый минимум запросов, и это не оказывает на Хабр вообще никакой нагрузки.
Для интерактивного логина на Хабр используется сочетание headed и headless Chromium. Вначале код пробует залогиниться на Хабру в автоматическом режиме с помощью headless-браузера и заранее сохранённых куков. Когда не получается (например, из-за гуглокапчи) — переходит в headed-режим и показывает пользователю окно логина.

Это обычная схема, которая используется и в другом софте — например, в Wirecast, которым я имею несчастье иногда пользоваться на стримах: таким образом там делается логин в Facebook, YouTube и Twitch. (По крайней мере это те направления, которые я сам использовал в стриминге. Может быть, их больше.) Но Wirecast использует свой велосипед, а я взял решение, достойное 2018 года (точнее, весны 2017) — полноценный Headless Chrome.

(на скриншоте у меня facepalm из-за того, что они не смогли посчитать высоту окна и показывают скроллбар справа)
На выбор повлияло ещё и то, что на Heisenbug и HolyJS удалось поговорить с кучей людей, которые его используют. И даже взять интервью у Виталия Слободина — бывшего разработчика PhantomJS, который сейчас активно топит за использование Headless Chromium. И даже пообщаться с Саймоном Стюартом — создателем WebDriver. Столько умных людей просто не могут ошибаться.
И действительно, сначала погружение в Headless Chrome оказалось мягким и приятным. Отладка проходила в полностью headed-режиме — так проще видеть, что браузер делает «под капотом». Но как дошло до продакшна, оказалось, что во время не-интерактивного логина куки, полученные в интерактивном режиме, полностью теряются!
Я чуть не вырвал себе все волосы на заднице. А потом наткнулся на эпичный тред в багтрекере Puppeteer. Puppeteer — это наш ближайший конкурент из мира JS, делают его такие же смузихлёбы, как мы, поэтому собирают они примерно такие же баги. Из этого трекера в дальнейшем было вытащено еще много удивительной инфы.
Вкратце, да — изначально Headless Chrome не мог вообще шарить никаких данных с headed-режимом. Но это не потому, что они такие умные и заботятся о безопасности (как предположила куча людей, из которых можно вспомнить Олега Царёва, например). А тупо потому, что раскладка файлов в user-data-dir в headless-режиме была другая. Со временем эту проблему начали решать, и в самых свежих канарейках (Chromium Canary — ночная сборка Хромиума) шаринг наконец заработал.
Впрочем, заработал только в одну сторону — сохраненное в headed можно использовать в headless, но не наоборот. Это связано с тем, что при выходе из headless Хромдрайвер прибивает его быстрее, чем Хромиум успевает сбросить данные на диск. Конкретную ссылку на баг я где-то потерял, если напишете в комментах — будет хорошо.
Но в моих целях интерактивного логина нужно только одно направление — из headed в headless, и так получилось, что оно уже работает в Канарейках.
Ну что ж, ясно, что надо переходить на Канарейку. Дело недолгое — подменить путь до chrome.exe.
Перезапустил тесты, и они тут же рассыпались в пыль.
Проблема возникала при выполнении вот такого тривиального кода:
public void setAttribute(WebElement element, String attName, String attValue) {
driver.executeScript("arguments[0].setAttribute(arguments[1], arguments[2]);", element, attName, attValue);
}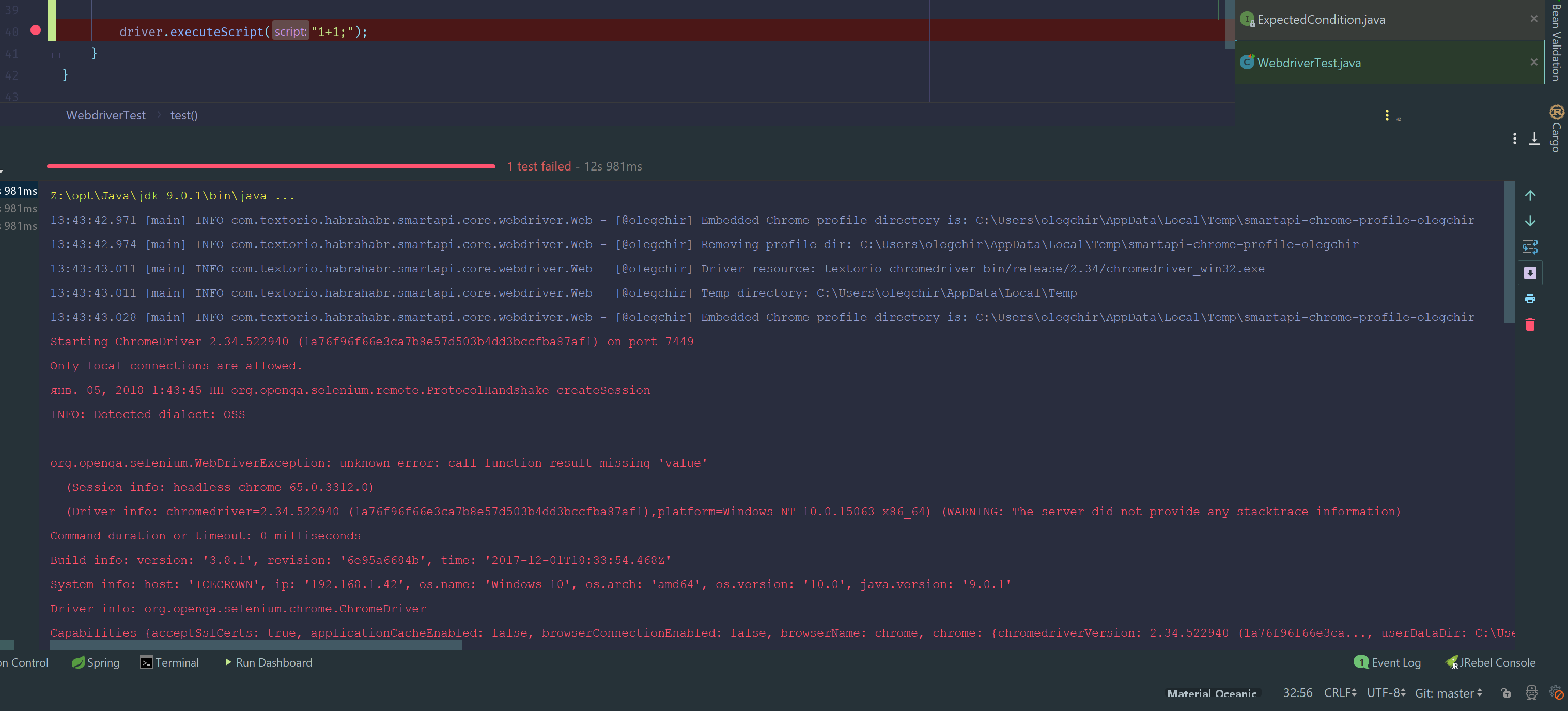
На скриншоте видно плохо, поэтому повторю по буквам:org.openqa.selenium.WebDriverException: unknown error: call function result missing 'value'.
Отчаянию моему не было предела. Если раньше было предельно ясно, как править такие ошибки, то сейчас происходила какая-то жесть. Никакие очевидные выкрутасы с Java-кодом не помогали.
Приведенный выше код на JavaScript объяснять особо нечего: он просто сетит выбранный атрибут на странице. При запуске скрипта на ChromeDriver, массив arguments заполняется тем, что передано в параметрах. Как именно параметры туда подсовываются — это отдельный вопрос, ведь первым аргументом идёт не id, а некий WebElement, который конкретно я получаю через XPath. Как это хранится, мы увидим ниже. Почему такого метода нет нативно в ChromeDriver и его надо писать самостоятельно — понятия не имею, спишем на молодость проекта Selenium :-). Возвращаемся к теме.
Интуитивно понятно, что эта версия ChromeDriver просто не совместима с используемой версией браузера, и нужно попытаться найти достаточно свежую версию ChromeDriver.
В принципе, эти достаточно свежие версии ChromeDriver есть в гуглооблаке. И вот тут начинается мой факап, благодаря которому появилась эта статья.
Я скопировал себе свежайшую версию Хромдрайвера (от второго января или что-то такое), запустился на ней… и получил всё ту же ошибку. Иначе говоря, новый Хромдрайвер несовместим с Канарейкой тоже? Как же так?!
На самом деле, свежий Хромдрайвер работает отлично. Проблема в том, что из-за каких-то мистических проблем с Windows, новый файл просто не скопировался. Если бы файл скопировался успешно, ошибки бы мы уже не увидели. Замнем для ясности, каким надо быть дебилом, чтобы не посмотреть на версию драйвера в логе, и перейдем к дальнейшему повествованию.
Затем были некоторые попытки размышлений.
Во-первых, нужно было читнуть спецификацию W3C Webdriver. Это очень важная спецификация, как мы поймём дальше.
После этого я выкачал Selenium Chrome Driver прямо в проект и начал люто его дебажить.
Сразу после чтения спеки W3C бросилось в глаза, что запрос делается не http://127.0.0.1:9999/session/sessionId/execute/sync, как написано в спеке, а на тот же URL, но только без Sync. Оказалось, в этом и есть разница между W3CHttpCommandCodec и JsonHttpCommandCodec, которые устанавливаются драйверу при инициализации.
А что если его подменить — мелькнула безумная мысль? Ищем метод-сеттер… и не находим.
Это поле — закрытое, и выставляется оно единственный раз при обработке команды NEW_SESSION. Собственно, диалект мы придумываем не сами внутри Selenium, а его сообщает нам Хромдрайвер, и на это решение никак не повлиять.
Но у нас же есть Reflection! Поле с URL-ом — final, поэтому будем менять целиком диалект.
Попробуем поменять диалект прямо перед отправкой executeScript в тесте:
public static CommandCodec commandDialectFromJsonToW3C(ChromeDriver driver) {
CommandCodec oldCommandCodec = null;
CommandExecutor commandExecutor = driver.getCommandExecutor();
try {
Field commandCodecField = commandExecutor.getClass().getSuperclass().getSuperclass().getDeclaredField("commandCodec");
commandCodecField.setAccessible(true);
oldCommandCodec = (CommandCodec) commandCodecField.get(commandExecutor);
W3CHttpCommandCodec newCodec = new W3CHttpCommandCodec();
commandCodecField.set(commandExecutor, newCodec);
} catch (Exception e) {
staticlogger.error("Can't change dialect", e);
}
return oldCommandCodec;
}(От вида этого кода глаза начинают кровоточить, но в своё оправдание — я писал его в сильно изменённом состоянии сознания, а здесь привожу для исторической достоверности.)
Круто? Нет. Хромдрайвер отлично обработал обращение на execute/sync и ответил в точности той же самой ошибкой, что в начале поста. Гипотеза с диалектом не выстрелила.
Простым решением было бы убиться об стену.
Но мы не ищем лёгких путей. Настоящий индеец идёт путём Gentoo, пружинистым шагом ступая по граблям, костылям и подпоркам ночных релизов!
Было принято решение собрать из исходников идеально подходящие друг другу версии Chrome и Chromedriver. В перспективе это позволит нам не зависеть от Большого Дяди и успешности его работы по сборке канареек. А еще, пердолиться с ручной сборкой из исходников — это приятно.
В принципе, это несложно, учитывая наличие подробных инструкций, хотя есть нюансы.
Во-первых, желательно выделить какой-нибудь быстрый диск (у меня это был SSD на NVMe), который исключить из сканирования антивирусом. Дело в том, что будет скачано около 20 гигабайт мелких файлов (и около 10, если качать без истории в git). Даже просто удаление этих файлов с SSD занимает минут пять. Если их начинает проверять антивирус, всё это может затянуться на часы.
Если у компа есть еще свободные ресурсы — они будут нелишними. Ни 20 ядер, ни 64GB RAM, ни самый наибыстрейший SSD на твёрдом топливе — ничего этого лишним не будет, как мы увидим дальше.
Во-вторых, оказалось совершенно необходимым настроить git:
$ git config --global user.name "Oleg Chirukhin"
$ git config --global user.email "oleg@textor.io"
$ git config --global core.autocrlf false
$ git config --global core.filemode false
$ git config --global branch.autosetuprebase alwaysЭто может оказаться неочевидным, но без трех нижних настроек ничего не работает.
Если этого не сделать, то будут валиться какие-то ошибки в питоне.
В-третьих, я использую Windows как основную платформу для большинства пользователей Хабра. Нужно установить Visual Studio не ниже update 3.2 с патчем 15063 (Creators Update). Подойдет и бесплатная версия. В онлайн-установщике нужно выбрать «Desktop development with C++» и в нём «MFC and ATL support».
Если вы, как и я, не доверяете гую, то дальше нужно скачать онлайн-установщик и из командной строки вызвать его со следующими параметрами:vs_community.exe --add Microsoft.VisualStudio.Component.VC.ATLMFC --includeRecommended
Дальше нужно пойти в «установку и удаление программ» и найти там Windows Software Development Kit.
Если вы пользуетесь Visual Studio, то там Windows Software Development Kit представлен в виде множества разных версий. Нужно найти самую свежую в списке.
Дальше будет кнопка Modify (или Change), потом список выбора, в котором надо выбрать радиобаттон с названием Change, и дальше — таблица дополнительных компонентов. Нужно выбрать Debugging Tools For Windows и нажать еще одну кнопку Change.
Если этого не сделать, всё будет валиться с Очень Странными Ошибками.
Если сильно повезет, там будет что-то человекочитаемое типа:
Exception: dbghelp.dll not found in "C:\Program Files (x86)\Windows Kits\10\Debuggers\x64\dbghelp.dll"
You must install the "Debugging Tools for Windows" feature from the Windows 10 SDK.Если не повезет, там будет какая-то бесполезная хренотень.
Дальше нужно закачать скрипты Depot Tools для управления репозиторием. Гугл не ищет лёгких путей и хранит весь код Хромиума в адской монорепе в гите, которая еще и юзает ссылки на SVN. Чтобы управлять этим безобразием, им пришлось понаписать скриптов управления, которые состоят из батников, баша, питона и всего такого, под каждую платформу — разное.
В руководстве говорят, что на Windows не стоит закачивать зависимости из чего-то кроме cmd.exe.
Проверил: рекомендация того стоит! Я пробовал собирать из моего любимого msys2 и из git bash: в них были ошибки, которых нет в cmd.exe вообще.
Поэтому запускаем cmd.exe и начинаем заливать скрипты:
mkdir z:/git
cd /d z:/git
git clone https://chromium.googlesource.com/chromium/tools/depot_tools.gitДальше добавляем путь до depot tools в PATH (у меня это было Z:/git/depot_tools)()
Еще нужно добавить глобальную переменную окружения DEPOT_TOOLS_WIN_TOOLCHAIN, значение — 0. Иначе сборщик начнет использовать не тот тулчейн.
Если часто пердолитесь с переменными окружения в Windows, то лучше всего использовать Rapid Environment Editor. Это не проплаченная реклама, эта программа реально сэкономила мне многие часы жизни.
cmd.exe
cd /d Z:/git/depot_tools
gclientЗатем идём заливать код Хромиума, так как Хромдрайвер является его частью.
Нужно создать пустую директорию и выполнить следующие команды:
mkdir chromium
cd chromium
fetch chromium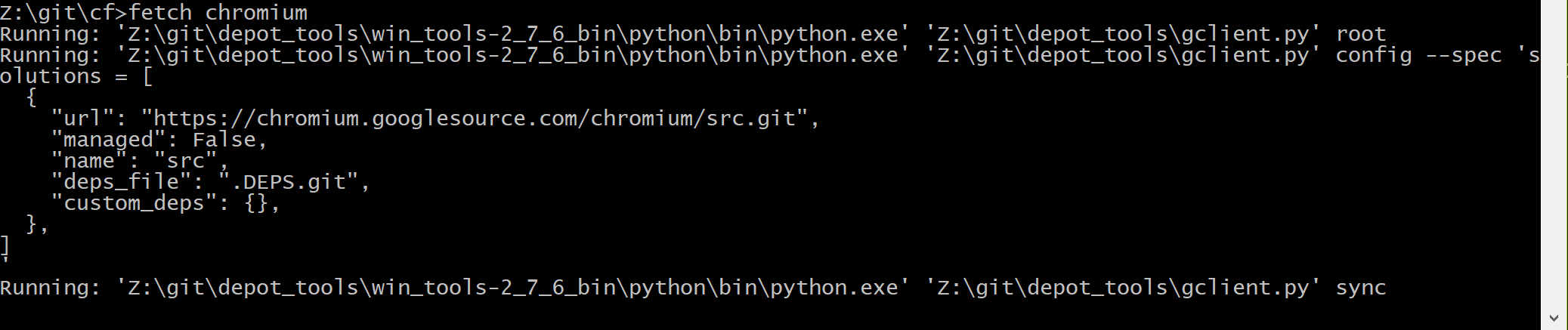
Вот в этом месте придётся долго ждать, там качается репозиторий на 20 гигов.
Самопальные depot tools, конечно, никому не известны. Но есть небольшой хелп тут и тут. Если хелпа не хватает — нужно читать самостоятельно и мучиться.
Кстати, гит жрёт значительные ресурсы. Так что, если вы, как и я, играете в Overwatch параллельно с такими операциями, можно выловить некислых лагов.

Так как я не доверял своей ночной сборке, то решил хакать ту версию, которая соответствует официальному стабильному драйверу.
Для этого нужно переключиться на тот кусок истории, который к нему максимально близко.
Кстати, выше можно было использовать fetch --no-history chromium, это экономит десяток гигабайт на жестком диске.
Но это годится, очевидно, только для получения самой свежей версии, а нам нужно вначале облапать историю и получить номер коммита.
Смотрим версию «стабильного» браузера: 63.0.3239.84.

Гуглим, что вышла она 6 декабря.
Как нормально посмотреть информацию о времени сборки, я так и не понял (если кто знает — расскажите?). Но гугление помогает.
Дальше смотрим все коммиты за эту дату:git log --after="2017-12-05" --until="2017-12-06"
Хэш последнего коммита за эту дату: 5eaac482ef2f7f68eab47d1874a3d2a69efeff33
git new-branch hacking
git reset --hard 5eaac482ef2f7f68eab47d1874a3d2a69efeff33Переключение может занять значительное время. Адская монорепа даёт о себе знать. В частности, пока я переключался на ветку hacking, в мастер прилетело несколько коммитов.
Кстати, для чтения коммитов очень рекомендую использовать графический git-клиент вместо командной строки.
Дело в том, что цифры там выходят совершенно безумные. Между интересующим нас коммитом (который был всего месяц назад) — пять тысяч штук других коммитов. Руками читать это в консоли — очень больно.
Для пробы, я сгенерил только проект для ChromeDriver. Нужно было понять, работает ли вообще сборка.gn gen --ide=vs2017 --filters="//chrome/test/chromedriver" out\Release
Я бы использовал в качестве IDE любимый CLion, но его нет в списке поддерживаемых в Ninja.
Из оставшегося, очевидно, Вижуалка — самое разумное под Windows.
Использующаяся дальше команда gn — это Ninja, система сборки C++. О том, как пользоваться Ninja конкретно в Хромиуме, рассказано в отдельном документе:
Чтобы посмотреть все возможные аргументы, запускаемgn args --list
Теперь используем вычитанные там опции:gn args out\Release
Открывается текстовый редактор, куда мы вписываем релизные опции:
is_official_build = true
is_component_build = false
is_debug = falseСохранить и закрыть. Ninja тут же начнет перегенерацию файлов проекта. Если он при этом повиснет — отменяем и еще по разу делаем gn args.
После чего запускаем сборку.ninja -C out\Release chromedriver
Эта сборка происходит быстро.
Не замерял, но минут за десять сделаться должна — там всего 4207 файлов.
Теперь можно пойти в директорию out\Default и спокойно скопировать оттуда chromedriver.exe. Он запустится без зависимостей и других файлов в этой директории. Мысленно поздравляем себя: теперь мы не зависим от умных дядей, собирающих нам ночные сборки на оффсайте.
Отлично, первая проба сделана, теперь нужно было собрать настоящий Хромиум.
ninja -C out\Default chrome
gn gen --ide=vs2017 --filters="//chrome" out\ChromeRelease
gn args out\ChromeRelease
is_official_build = true
is_component_build = false
is_debug = false
ninja -C out\ChromeRelease chromeПолучается около 34465 файлов.
На i7 6700k, 32GB RAM, NVMe SSD Samsung 960 EVO — полная сборка Хромиума заняла около 5 часов.
При 100% загрузке CPU и 60% загрузке RAM. (Предполагаю, что для полной загрузки RAM не хватило ядер.)
Репозиторий после сборки весит около 40 гигабайт.
Нужно отметить, что время от времени компиляция «затыкалась» на пару минут: загрузка проца и памяти падала на ноль, и даже вентиляторы переходили на обычный режим. Сколько раз так было «на пару минут» — не знаю, ибо ушёл спать. Мне не хватает знаний об устройстве компьютера, чтобы интерпретировать такое поведение — может, кто подскажет?
Всё это время на компьютере ничего делать не стоит.
За эти 5 часов я отлично выспался! Наступило хмурое утро 5-го января.
Ах, эта романтика родной Gentoo, долгие бессонные красноглазые ночи, проведённые за сборкой ночных билдов из мастера! Когда видишь собранный chrome.exe в консоли, это ощущается, как будто проделал долгую, приятную физическую работу.
С радостным возбуждением и раскалывающейся от боли головой (5 часов — это совсем немного) запускаю тесты на свеженьком браузере.
Ничего не работает.

Стало понятно, что нужно погружаться глубже.
В этот момент я впервые за праздники вспомнил о подаренной бутылке текилы и с трудом подавил непреодолимое желание нажраться в слюни.
...
На этот раз понадобилась дебажная сборка.
gn gen --ide=vs2017 --filters="//chrome/test/chromedriver" out\Hacking
gn args out\Hacking
is_official_build = false
is_component_build = true
is_debug = true
ninja -C out\Hacking chromedriverК сожалению, прямо этот коммит мгновенно валится с ошибкой:
Z:\git\cf\src>ninja -C out\Hacking chromedriver
ninja: Entering directory `out\Hacking'
[75/4177] CXX obj/base/base/precompile.cc.obj
FAILED: obj/base/base/precompile.cc.obj
../../third_party/llvm-build/Release+Asserts/bin/clang-cl.exe /nologo /showIncludes @obj/base/base/precompile.cc.obj.rsp /c ../../build/precompile.cc /Foobj/base/base/precompile.cc.obj /Fd"obj/base/base_cc.pdb"
Assertion failed: ID < FilenamesByID.size() && "Invalid FilenameID", file C:\b\rr\tmpcwzqyv\w\src\third_party\llvm\tools\clang\include\clang/Basic/SourceManagerInternals.h, line 105
Wrote crash dump file "C:\Users\olegchir\AppData\Local\Temp\clang-cl.exe-247121.dmp"
LLVMSymbolizer: error reading file: PDB Error: Unable to load PDB. Make sure the file exists and is readable. Calling loadDataForExeOMG, C:\b\rr\tmpcwzqyv\w\src\third_party? Захардкоженный диск C, вы это серьезно?
Но это не важно, ибо, просматривая интернет, обнаруживаем, что бага не в кривом пути, а в Clang. И на тот момент (до которого мы откатились в гите) её еще не пофиксили. Сейчас уже всё ОК. На тот момент баг обходился отключением precompiled headers.
Кстати, я каждый раз из Windows Explorer удаляю out\Hacking, чтобы быть уверенным в результате. С Windows ни в чём нельзя быть уверенным просто так.
gn gen --ide=vs2017 --filters="//chrome/test/chromedriver" out\Hacking
gn args out\Hacking
is_official_build = false
is_component_build = true
is_debug = true
enable_precompiled_headers = false
ninja -C out\Hacking chromedriverОстаётся открыть проект в Visual Studio:devenv out\Hacking\all.sln
При открытии Вижуалка подвисает — это нормально.
Но если она подвисает дольше нескольких минут — надо закрывать и открывать заново.
Особенно если у вас ReSharper C++ или что-то такое.
Изучение исходника по кейворду execute дает единственный сколько-нибудь интересный файл: chromedriver\chrome\web_view_impl.cc
В нем нас интересует, в первую очередь, CallFunction — очевидно, она обрабатывает входящий запрос.
Status WebViewImpl::CallFunction(const std::string& frame,
const std::string& function,
const base::ListValue& args,
std::unique_ptr<base::Value>* result) {
std::string json;
base::JSONWriter::Write(args, &json);
std::string w3c = w3c_compliant_ ? "true" : "false";
// TODO(zachconrad): Second null should be array of shadow host ids.
std::string expression = base::StringPrintf(
"(%s).apply(null, [null, %s, %s, %s])",
kCallFunctionScript,
function.c_str(),
json.c_str(),
w3c.c_str());
std::unique_ptr<base::Value> temp_result;
Status status = EvaluateScript(frame, expression, &temp_result);
if (status.IsError())
return status;
return internal::ParseCallFunctionResult(*temp_result, result);
}После того, как ответ получен, перед отдачей клиенту оно парсит результат:
Status ParseCallFunctionResult(const base::Value& temp_result,
std::unique_ptr<base::Value>* result) {
const base::DictionaryValue* dict;
if (!temp_result.GetAsDictionary(&dict))
return Status(kUnknownError, "call function result must be a dictionary");
int status_code;
if (!dict->GetInteger("status", &status_code)) {
return Status(kUnknownError,
"call function result missing int 'status'");
}
if (status_code != kOk) {
std::string message;
dict->GetString("value", &message);
return Status(static_cast<StatusCode>(status_code), message);
}
const base::Value* unscoped_value;
if (!dict->Get("value", &unscoped_value)) {
return Status(kUnknownError,
"call function result missing 'value'");
}
result->reset(unscoped_value->DeepCopy());
return Status(kOk);
}Внимательно присматриваемся к коду и… видим нашу ошибку — call function result missing 'value'!
Конечно, такое предположение еще надо подтвердить. «Code is cheap, show me debugger».
Для этого идём в IntelliJ IDEA и в Java-коде ставим брейкпоинт непосредственно перед отправкой executeScript:

После этого переходим в Вижуалку и выбираем там отладочное подключение к процессу:
И из списка выбираем chromedriver.exe:
Ставим брейкпоинт в начало функции WebViewImpl::CallFunction и смотрим, что произойдёт.
Дальше отпускаем код в Идее и натыкаемся на только что установленный брейкпоинт в Вижуалке.
В отладчике можно найти много интересных подробностей о соединении. Например, мы видим, что переданные в JS-функцию WebElement передаются по неким внутренним ссылкам, а не по XPath (по которому их искали изначально). Это очень круто, быстро и удобно. Функция передаётся тупо строкой — и все остальные параметры тоже завёрнуты в разумные типы современного C++.
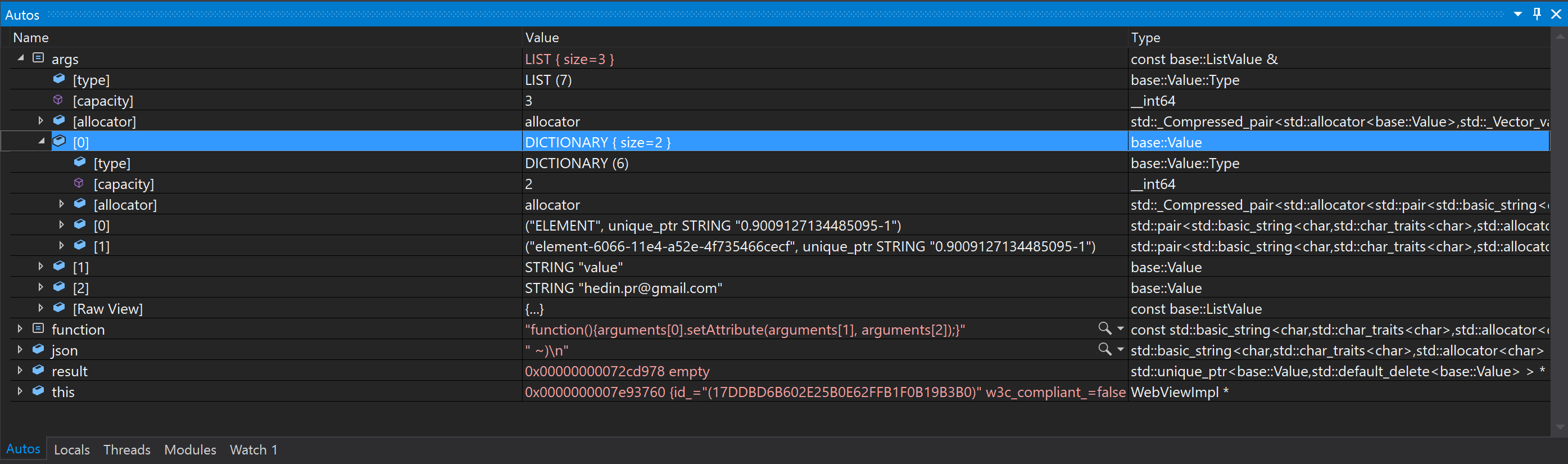
В частности, драйвер понимает, что диалект, который я пытался хачить из Джавы — не соответствует спеке W3C. Зря беспокоился!
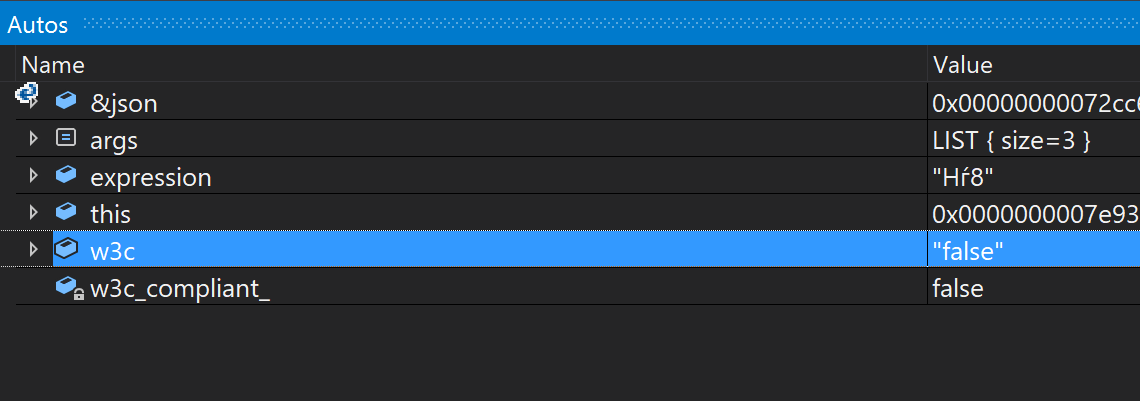
Параметры команды в JSON-форме (получающиеся в результате выполнения base::JSONWriter::Write(args, &json);) можно красиво посмотреть в отладчике:

Сомнительный параметр kCallFunctionScript оказался дичайшей простыней из JavaScript, засунутого в const char[]. Во имя сохранения психики хабровчан, выкладываю только небольшой фрагмент:

Самая интересная часть отладки происходит, когда мы подбираемся к функции ParseCallFunctionResult:
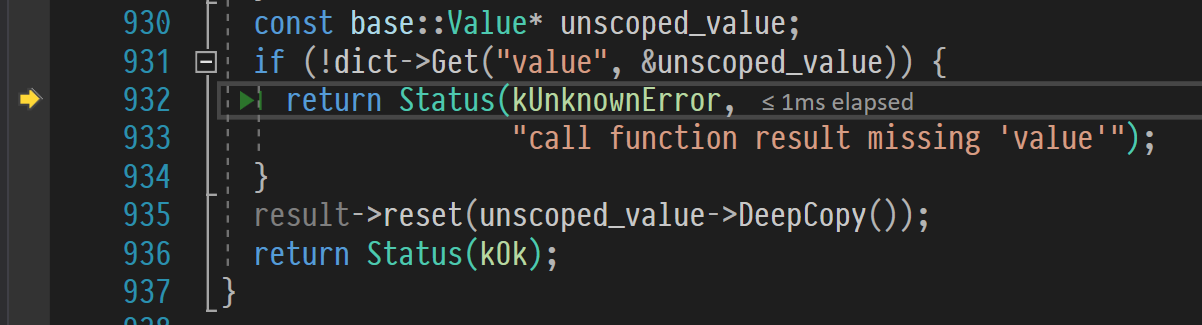
Как мы и ожидали, предположение сработало.
В этом куске говнокода написано, что если мы не смогли прочитать value, т.е. результат функции, то нужно сдаваться и отдавать клиенту ошибку.
Я рванулся в Java+JS код и переписал исходную функцию, добавив в конце JS-кода retur true;:
public void setAttribute(WebElement element, String attName, String attValue) {
driver.executeScript("arguments[0].setAttribute(arguments[1], arguments[2]); return true;", element, attName, attValue);
}Все тесты мгновенно позеленели.
Это, очевидно, ересь, и я уже начал готовиться файлить баг на трекер.
Но тут в голове что-то начало проясняться, и в минуту прозрения вспомнились слова из спеки W3C:
The Execute Script command executes a JavaScript function in the context of the current browsing context and returns the return value of the function.
Понимаете, returns. Они не следуют «Key words for use in RFCs to Indicate Requirement Levels». Они не используют слова must, must not, should и should not для индикации уровня значимости. Соответственно, с какой-то точки зрения, returns можно читать как must return. Или нет — это вопрос интерпретации.
С другой стороны, по спецификации и не требуется, чтобы мы передавали завершённую функцию. В конце концов, Хромдрайвер и так дописывает нам заголовок функции — так почему бы ему не приписать в конец и return?
Или с третьей стороны, функции в JS не могут вернуть ничего. Они всегда возвращают, как минимум, undefined.
Взглянем на таблицу соответствия:
null === undefined // false
null == undefined // true
null === null // trueОчевидно, что undefined отлично мапится на null, имеющийся в большинстве языков программирования (или имеющий эквиваленты). Нет никакой проблемы, чтобы транслировать undefined во что-то другое пустое.
С четвертой стороны, понятно, что проблема в стандарте. Конкретно в этом случае спецификация неполна. Оно оговаривает, что ExecuteScript обязательно вернёт то, что вернёт функция. Но не оговаривает, как он себя поведёт, если функция ничего не возвращает: текст спецификации можно интерпретировать и как «раз функция возвращает ничего, ExecuteScript это ничего и вернёт». Другая реализация ExecuteScript может стать несовместимой с новой версией спеки, так как сейчас возможны расклады:
ExecuteScript возвращает AExecuteScript возвращает B != AExecuteScript оно было изначально!)Фиксировать любое поведение не получится. Если только разрешать возможность сразу всех трёх вариантов одновременно.
На основании всего этого, пришёл к выводу, что файлить баг бессмысленно. Раз у меня вызов executeScript всё равно проходит сквозь транслятор, то можно просто детектить там return, и если его нет — приписывать в конец. Или проще — сделать два варианта вызова — для «функции» (есть результат), и для «процедуры» (нет результата), и «процедуре» всегда в конец дописывать return true; Или еще проще — каждый раз отслеживать наличие return вручную.
Но один вопрос не переставал глодать — а на кой чёрт поломали работающее поведение, какой коммит это притащил?
Тут я забрался в историю гита и нашёл неожиданное: коммит, в котором эту проблему уже исправили.
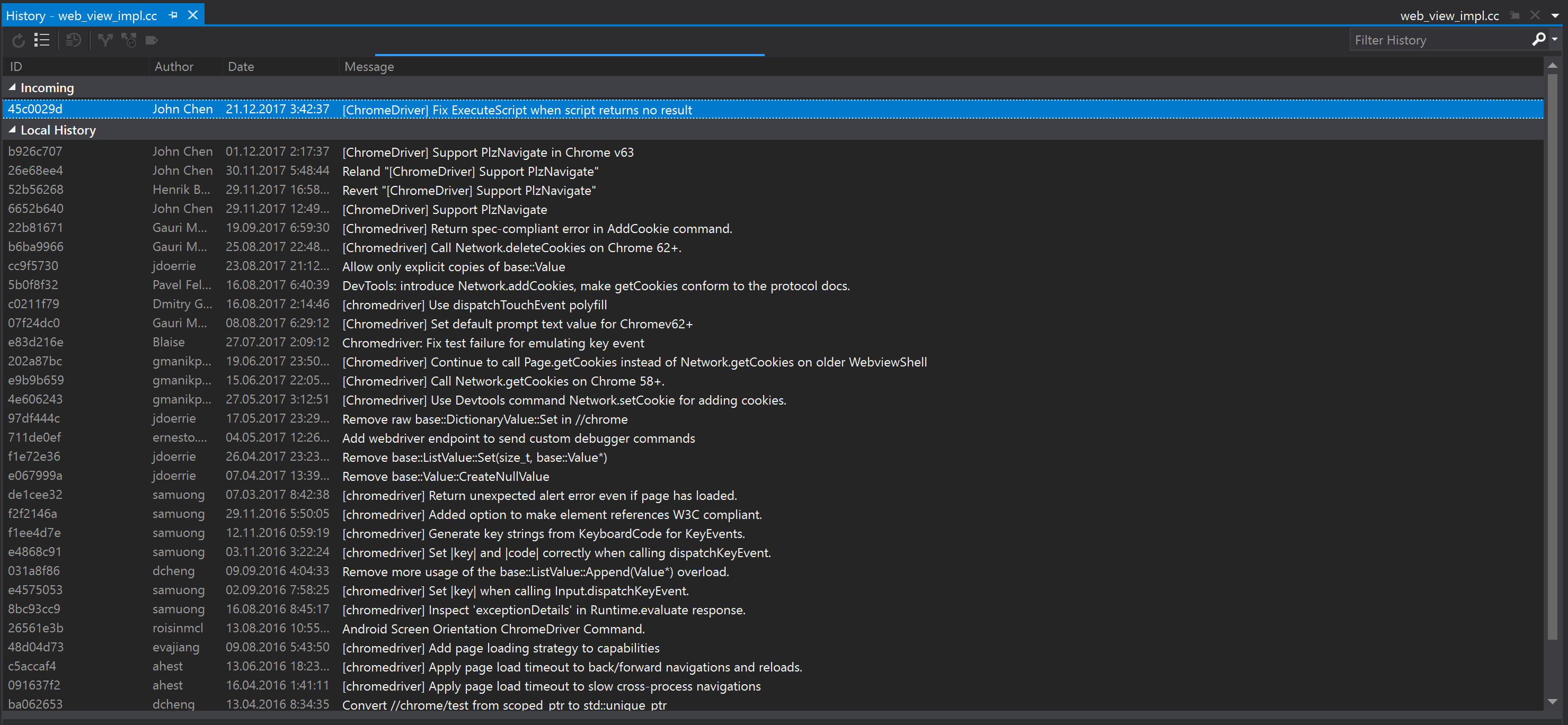
Коммит называется так: «Fix ExecuteScript when script returns no result».
Смотрим на содержимое коммита:
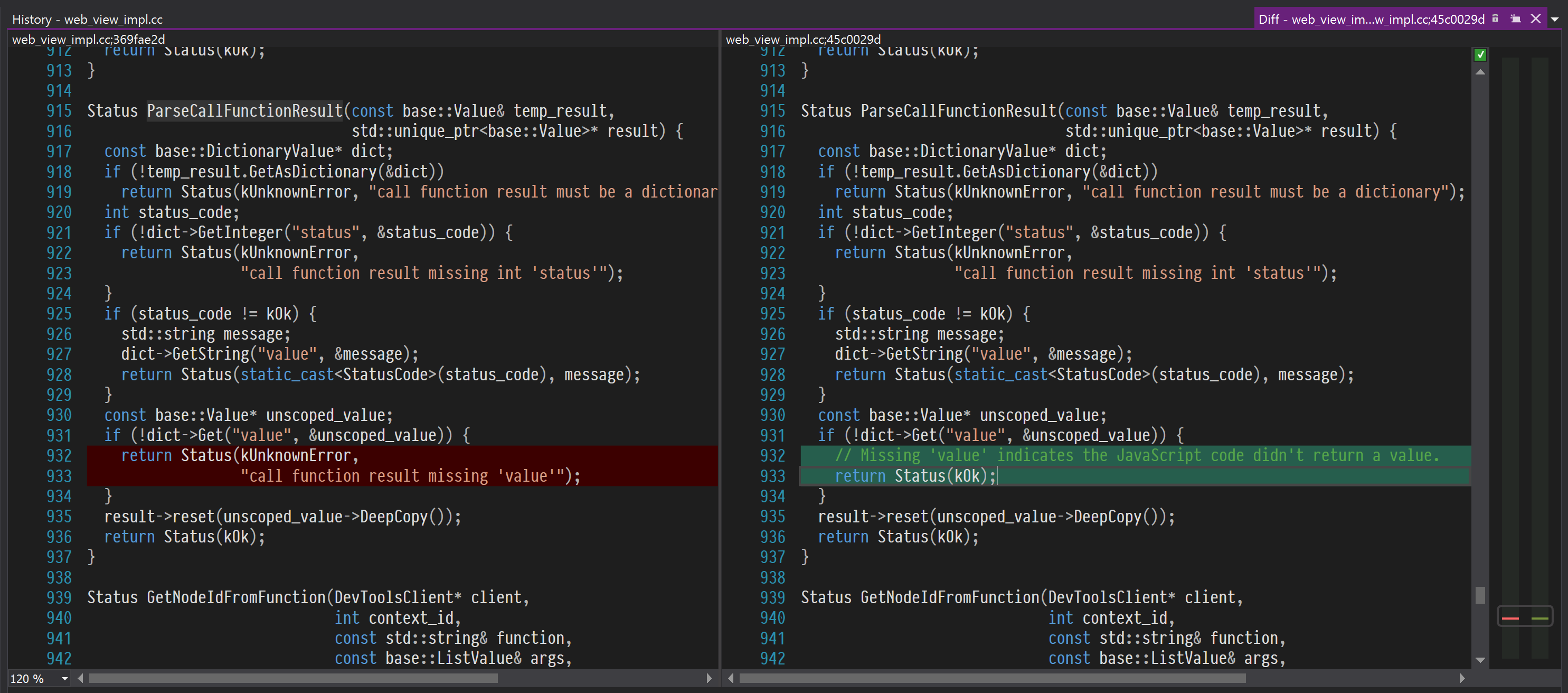
Вместо того, чтобы возвращать статус «неизвестная ошибка», предлагается возвращать статус «ок». А ЧТО, ТАК МОЖНО БЫЛО?
Но ведь этот коммит уже есть в самой свежей версии Хромдрайвера. Почему же оно у меня не работало?! Пробую скопировать файл chromedriver.exe на старое место — получаю ошибку. Идиот! Всё это время я запускался на устаревшем драйвере!
Убираю return true; из кода, обновляю свой бранч hacking до самой свежей версии Хромдрайвера, перезапускаю тесты. Тесты зеленеют.
executeScript всегда стоит возвращать какое-нибудь значение: на всякий случай, вдруг в будущем это поведение снова поменяют;WebDriver — это стандарт W3C. Его можно и нужно читать;У нас остался нерассмотренным еще один компонент — собственно, сам Chromium. Про него есть что сказать, но это будет уже совсем другая история, с новыми кровавыми подробностями.