https://habrahabr.ru/company/otus/blog/342974/Доброго всем! Мы тут потихоньку начали исследовать новое совсем для нас направление для обучения — блокчейны и нашли то, что оказалось интересным в рамках нашего курса по
Python, в том числе. Чем, собственно, и хотим поделиться с вами.
Я могу узнать, когда у меня появился первый Bitcoin, из истории кошелька в моем аккаунте на Coinbase — входящая транзакция в 2012 году в подарок за регистрацию. Bitcoin в то время стоил около 6.50$. Если бы я сохранил те 0.1 BTC, на момент написания статьи это бы уже стоило более 500$. Если кому-то интересно, я продал их, когда Bitcoin стоил 2000$. Так что я получил только 200$ вместо ныне возможных 550$. Не стоило торопиться.
О существовании Bitcoin я знал, но особо не интересовался. Я видел взлеты и падения курса $/BTC. Я видел, как люди говорят, что за ним будущее, а видел статьи о его полной бессмысленности. Но личного мнения у меня не было — просто наблюдал со стороны.
Точно так же я почти не следил за блокчейнами. Но в последнее время мой отец несколько раз упоминал, что на CNBC и Bloomberg, которые он смотрит по утрам, часто рассказывают о блокчейнах, и он понятия не имеет, что это.
И тогда я внезапно понял, что нужно чуть глубже разобраться в этой теме. И начал с “исследования” — прочитал огромное количество статей в интернете, объясняющую их суть. Некоторые были хорошие, некоторые плохие, некоторые глубокие, а некоторые очень поверхностные.
Чтения оказалось недостаточно, а если существует одна вещь, которую я знаю наверняка, так это то, что чтение не объяснит и сотой доли того, что объяснит программирование. И так я понял, что стоит написать свой собственный локальный блокчейн.
Нужно учитывать, что есть большая разница между базовым блокчейном, который я описываю и “профессиональным” блокчейном. Эта цепь не создаст криптовалюту. Блокчейны не требуют производства монет, которые можно продавать и менять на физические деньги.
Блокчейны используются для хранения и подтверждения информации. Монеты помогают стимулирующим узлами участвовать в валидации, но они не обязаны существовать.
Я пишу пост по нескольким причинам: 1) Чтобы люди, прочитавшие его, смогли узнать больше о блокчейнах; 2) Чтобы я смог понять больше, объяснив код, а не просто написав его.
В этом посте я покажу способ хранения данных блокчейна и генерации начального блока, синхронизацию узла с локальными данными блокчейна, отображение блокчейна (что впоследствии будет использоваться для синхронизации с другими узлами), а затем, майнинг и создание валидных новых блоков. В первом посте не будет никаких других узлов. Никаких кошельков, пиров, важных данных. О них поговорим позднее.
В двух словах
Если вы не хотите углубляться в детали и читать код, или если вы наткнулись на этот пост, рассчитывая на статью, которая бы понятным языком объясняла блокчейны, я постараюсь кратко резюмировать, как они работают.
На самом высоком уровне, блокчейн — база данных, где каждый, участвующий в блокчейне, может хранить, просматривать, подтверждать и никогда не удалять данные.
На более низком уровне, данные в этих блоках могут быть чем угодно, пока это позволяет конкретный блокчейн. Например, данные в Bitcoin блокчейне — исключительно транзакции Bitcoin между аккаунтами. Ethereum блокчейн позволяет как аналогичные транзакции Ether, так и транзакции, использующиеся для запуска кода.
Прежде чем блок будет создан и объединен в блокчейн, он подтверждается большинством людей, работающих над блокчейном — их называют узлами. Настоящий блокчейн — цепь, состоящая из огромного множества блоков, подтвержденных большинством узлов. Таким образом, если узел попытается изменить данные предыдущего блока, новые блоки не будут валидны, и узлы не будут доверять данным из некорректного блока.
Не волнуйтесь, если это сбивает с толку. Мне понадобилось время, чтобы самому вникнуть в это, и еще больше времени на написание такого поста, чтобы даже моя сестра (которая ничего не знает о блокчейнах) смогла понять.
Если хотите изучить код, посмотрите ветку
part 1 на Github. Смело присылайте мне любые вопросы, комментарии, правки и похвалы (если вы в настроении сделать что-то особо хорошее), или просто пишите в твиттер.
Шаг 1 — Классы и Файлы
Первый шаг — написание класса, обрабатывающего блоки при запуске узлов. Я назову этот класс Block. Честно говоря, много делать не придется. В функции __init__ мы будем верить, что вся необходимая информация уже представлена в словаре. Для производственного блокчейна — это не самое мудрое решение, но подходит в качестве примера, потому что код пишу только я. Также я напишу метод, запаковывающий важную информацию блока в словарь, а после заведу более удобный способ для отображения информации блока при его печати в терминал.
class Block(object):
def __init__(self, dictionary):
'''
We're looking for index, timestamp, data, prev_hash, nonce
'''
for k, v in dictionary.items():
setattr(self, k, v)
if not hasattr(self, 'hash'): #in creating the first block, needs to be removed in future
self.hash = self.create_self_hash()
def __dict__(self):
info = {}
info['index'] = str(self.index)
info['timestamp'] = str(self.timestamp)
info['prev_hash'] = str(self.prev_hash)
info['hash'] = str(self.hash)
info['data'] = str(self.data)
return info
def __str__(self):
return "Block<prev_hash: %s,hash: %s>" % (self.prev_hash, self.hash)
Чтобы создать первый блок, запустим этот простой код:
def create_first_block():
# index zero and arbitrary previous hash
block_data = {}
block_data['index'] = 0
block_data['timestamp'] = date.datetime.now()
block_data['data'] = 'First block data'
block_data['prev_hash'] = None
block = Block(block_data)
return block
Отлично. Последний вопрос в этой части — где хранить данные в файловой системе. Это необходимо, если мы не хотим потерять локальные данные блока при отключении узла.
Я назову папку с данными ‘chaindata’, в какой-то степени подражая схеме папок Etherium Mist. Каждому блоку теперь присвоен отдельный файл, названный по его индексу. Нужно убедиться, что имена файлов содержат в начале достаточное количество нулей, чтобы блоки перечислялись по порядку.
С учетом кода выше, нужно написать следующее для создание первого блока:
#check if chaindata folder exists.
chaindata_dir = 'chaindata'
if not os.path.exists(chaindata_dir):
#make chaindata dir
os.mkdir(chaindata_dir)
#check if dir is empty from just creation, or empty before
if os.listdir(chaindata_dir) == []:
#create first block
first_block = create_first_block()
first_block.self_save()
Шаг 2 — Синхронизация блокчейна, локально
Прежде чем начать майнинг, интерпретацию данных или отправку/создание новых данных для цепи, необходимо синхронизировать узел. В нашем случае других узлов нет, поэтому я говорю только о чтении блоков из локальных файлов. В будущем частью синхронизации будет не только чтение из файлов, но и коммуникация с пирами для сбора блоков, которые были сгенерированы, пока ваш узел не был запущен.
def sync():
node_blocks = []
#We're assuming that the folder and at least initial block exists
chaindata_dir = 'chaindata'
if os.path.exists(chaindata_dir):
for filename in os.listdir(chaindata_dir):
if filename.endswith('.json'): #.DS_Store sometimes screws things up
filepath = '%s/%s' % (chaindata_dir, filename)
with open(filepath, 'r') as block_file:
block_info = json.load(block_file)
block_object = Block(block_info) #since we can init a Block object with just a dict
node_blocks.append(block_object)
return node_blocks
Пока просто и красиво. Чтение строк из файлов их загрузка в структуры данных не требуют чрезмерно сложного кода. Пока это работает. Но в будущих постах, где я буду писать о возможностях коммуникации разных узлов, эта функция sync станет значительно сложнее.
Шаг 3 — Отображение блокчейна
Теперь наш блокчейн находится в памяти, и поэтому я хочу отобразить цепь в браузере. Для того, чтобы сделать это прямо сейчас, есть две причины. Во-первых, необходимо подтвердить в браузере, что изменения произошли. Во-вторых, я буду использовать браузер в будущем для просмотра и совершения каких-либо операций, связанных с блокчейном. Например, отправка транзакций или управление кошельком.
Для этого я использую Flask — у него низкий порог вхождения, и я решил, что он подходит для наших целей.
Ниже представлен код для отображения json блокчейна. Я проигнорирую импорты для экономии места.
node = Flask(__name__)
node_blocks = sync.sync() #inital blocks that are synced
@node.route('/blockchain.json', methods=['GET'])
def blockchain():
'''
Shoots back the blockchain, which in our case, is a json list of hashes
with the block information which is:
index
timestamp
data
hash
prev_hash
'''
node_blocks = sync.sync() #regrab the nodes if they've changed
# Convert our blocks into dictionaries
# so we can send them as json objects later
python_blocks = []
for block in node_blocks:
python_blocks.append(block.__dict__())
json_blocks = json.dumps(python_blocks)
return json_blocks
if __name__ == '__main__':
node.run()
Запустите этот код, зайдите на localhost:3000/blockchain.json и увидите текущий блок.
Шаг 4 — “Майнинг”, также известный как создание блока
Сейчас есть только генезис блок, но если у нас появится больше данных, которые необходимо хранить и распределять, нужен способ включить это в новый блок. Вопрос — как создать новый блок и соединить его с предыдущим.
Сатоши описывает это следующим образом в Bitcoin whitepaper. Учтите, что “timestamp сервер” назван “узлом”.
“Начнем описание нашего решения с timestamp сервера. Его работа заключается в хэшировании блока данных, на который нужно поставить timestamp, и открытой публикации этого хэша… Timestamp показывает, что в данный момент конкретные данные существовали и потому попали в хэш блока. Каждый хэш включает в себя предыдущий timestamp: так выстраивается цепь, где очередное звено укрепляет все предыдущие.”
Скриншот изображения, прикрепленного под описанием:
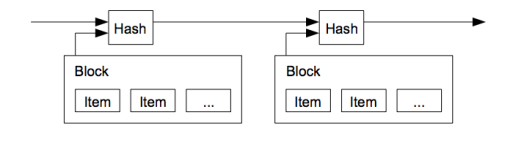
Основная идея раздела — при необходимости соединить блоки, мы создаем хэш информации о новом блоке, включая время создания блока, хэш предыдущего блока и информацию в самом блоке. Я буду называть всю эту информацию “хедером” блока. Таким образом, мы можем проверить корректность блока, посчитав все хэши перед ним, подтвердив последовательность.
В данном случае хедер, который я создаю, объединяет значения строки в одну огромную строку. Я включил следующие данные:
- Индекс, показывающий каким по счету является блок;
- Хэш предыдущего блока;
- Данные — просто случайные строки. Для bitcoin они называются Merkle root и содержат информацию о транзакциях;
- Timestamp майнинга этого блока.
def generate_header(index, prev_hash, data, timestamp):
return str(index) + prev_hash + data + str(timestamp)
Поясню один момент — объединение строк информации не является обязательным для создания хедера.
Требование состоит в том, чтобы каждый знал, как генерировать хедер блока и хэш предыдущего блока внутри него. Делается это для того, чтобы каждый мог убедиться в корректности хэша в новом блоке и подтвердить связь между двумя блоками. Хедер Bitcoin значительно сложнее объединения строк. Он использует хэши данных и времени и завязан на то, как данные расположены в памяти. Но в нашем случае объединения строк достаточно.
Теперь у нас есть хедер и можно вычислить валидность хэша. Я буду использовать метод, отличающийся от метода Bitcoin, но все равно запущу хедер блока через функцию sha256.
def calculate_hash(index, prev_hash, data, timestamp, nonce):
header_string = generate_header(index, prev_hash, data, timestamp, nonce)
sha = hashlib.sha256()
sha.update(header_string)
return sha.hexdigest()
Для майнинга блока мы используем функцию выше, чтобы получить хэш, положить его в новый блок и сохранить этот блок в директории chaindata.
node_blocks = sync.sync()
def mine(last_block):
index = int(last_block.index) + 1
timestamp = date.datetime.now()
data = "I block #%s" % (int(last_block.index) + 1) #random string for now, not transactions
prev_hash = last_block.hash
block_hash = calculate_hash(index, prev_hash, data, timestamp)
block_data = {}
block_data['index'] = int(last_block.index) + 1
block_data['timestamp'] = date.datetime.now()
block_data['data'] = "I block #%s" % last_block.index
block_data['prev_hash'] = last_block.hash
block_data['hash'] = block_hash
return Block(block_data)
def save_block(block):
chaindata_dir = 'chaindata'
filename = '%s/%s.json' % (chaindata_dir, block.index)
with open(filename, 'w') as block_file:
print new_block.__dict__()
json.dump(block.__dict__(), block_file)
if __name__ == '__main__':
last_block = node_blocks[-1]
new_block = mine(last_block)
save_block(new_block)
Готово! Но при таком типе создания блока кто угодно с самым быстрым CPU сможет создавать самые длинные цепи, которые другие узлы посчитают корректными. Нужен способ снизить скорость создания блока и подтверждение до перехода к следующему блоку.
Шаг 5 — Доказательство выполнения работы
Для снижения скорость я использую Доказательство выполнения работы, как и Bitcoin.
Доказательство доли владения — другой способ, используемый в блокчейнах для достижения консенсуса, но в этом случае я воспользуюсь работой.
Способ сделать это — установить требования к структуре хэша блока. Как и в случае с bitcoin, необходимо убедиться, что хэш начинается с определенного количества нулей, перед тем, как перейти к следующему. А для этого нужно добавить в хедер дополнительную информацию — случайно перебираемое число (nonce).
def generate_header(index, prev_hash, data, timestamp, nonce):
return str(index) + prev_hash + data + str(timestamp) + str(nonce)
Теперь функция майнинга настроена для создания хэша, но если хэш блока не содержит достаточного количества нулей, мы увеличиваем значение nonce, создаем новый хедер, вычисляем новый хэш и проверяем хватает ли нулей.
NUM_ZEROS = 4
def mine(last_block):
index = int(last_block.index) + 1
timestamp = date.datetime.now()
data = "I block #%s" % (int(last_block.index) + 1) #random string for now, not transactions
prev_hash = last_block.hash
nonce = 0
block_hash = calculate_hash(index, prev_hash, data, timestamp, nonce)
while str(block_hash[0:NUM_ZEROS]) != '0' * NUM_ZEROS:
nonce += 1
block_hash = calculate_hash(index, prev_hash, data, timestamp, nonce)
block_data = {}
block_data['index'] = int(last_block.index) + 1
block_data['timestamp'] = date.datetime.now()
block_data['data'] = "I block #%s" % last_block.index
block_data['prev_hash'] = last_block.hash
block_data['hash'] = block_hash
block_data['nonce'] = nonce
return Block(block_data)
Отлично. Новый блок содержит валидное значение nonce, поэтому другие узлы могут подтвердить хэш. Мы можем сгенерировать, сохранить и распределить новый блок остальным.
Заключение
На этом все! Пока что. Осталось еще много вопросов и фичей в блокчейнах, которые я не объяснил.
Например, как задействовать другие узлы? Как узлы передают данные, когда включаются в блок? Существуют ли иные способы хранения данных кроме огромных строк данных?
Ответы на эти вопросы можно будет найти в следующих частях этой серии постов, как только я сам найду на них ответы. Пожелания по содержанию можно писать мне в твиттер, в комментарии к посту или через форму обратной связи!
Спасибо моей сестре Саре за уточняющие вопросы о блокчейнах и помощь в редактировании поста!
THE END
Комментарии, вопросы, как всегда, приветствуются и тут, и на
дне открытых дверей. 