https://habrahabr.ru/company/odin_ingram_micro/blog/340524/- Open source
- JavaScript
- API
- Блог компании Odin (Ingram Micro)
Во фронтенде практически безраздельно правит OpenSource, а с недавних пор набирает популярность компонентный подход. Вроде бы всё чудесно. Небольшим компаниям компонентный подход помогает переиспользовать код, а крупным компаниям выравнивать UX во всей линейке продуктов, сервисов и прочего. И вот мы все такие замечательные крутые разработчики пилим свои фреймворки, библиотеки и виджеты, радостно полагая, что если они решают наши задачи, то решают и проблемы окружающего мира. Мы выкладываем их в паблик, ожидая благодарных пользователей, звезд на GitHub, скачиваний на NPM-е. Но почему-то одни библиотеки взлетают, а другие остаются незамеченными и позабытыми.
Почему же так происходит. Наверняка бывало, что когда вы искали какую-нибудь библиотеку с необходимой функциональностью или тот же NPM-ный пакет, находили что-то такое:
По сути просто кусок кода. Безо всякого объяснения, что это такое, что оно делает, как этим пользоваться. Если это NPM-ный пакет, то, наверно, можно залезть к нему в кишочки, понять, как он работает, и пользоваться на свой страх и риск. Но если это сервис, то уже ничего не поделаешь — не будешь ведь перебором выяснять, какие у него есть методы и какие данные они ожидают на вход.
Что же мы ожидаем увидеть, когда находим какой-нибудь публичный API? Наверно, что-то такое:

Это NPM от Babel. Здесь рассказывается, что это такое, что оно делает и как этим пользоваться. То есть когда мы выкладываем что-то в публичный доступ, мы должны приложить документацию. Иначе это просто бессмысленно.
Документация
Во фронтенде фреймворки и библиотеки появляются почти каждый день, поэтому сейчас стало очень популярно снабжать их еще и лендинговой страницей.

По сути это реклама, в которой нам рассказывают какую задачу решает этот API, чем он круче конкурентов, почему вы обязательно должны его использовать, даже если вам это не нужно и всё в таком духе. А уже с этой лендинговой страницы есть ссылки на документацию, в которой обычно есть разделы
Getting Started и
API Reference.
Getting Started — это раздел для пользователей, которые впервые видят ваш API. В этом разделе описано где скачать, как собрать, как запустить и тому подобное. Также здесь принято описывать, как использовать различные функции продукта. Например, мы в APS, в
Getting Started берем маленькое приложение и пошагово добавляем в него различную функциональность, доводя до полноценного боевого решения по которому уже можно делать какие-то свои приложения.
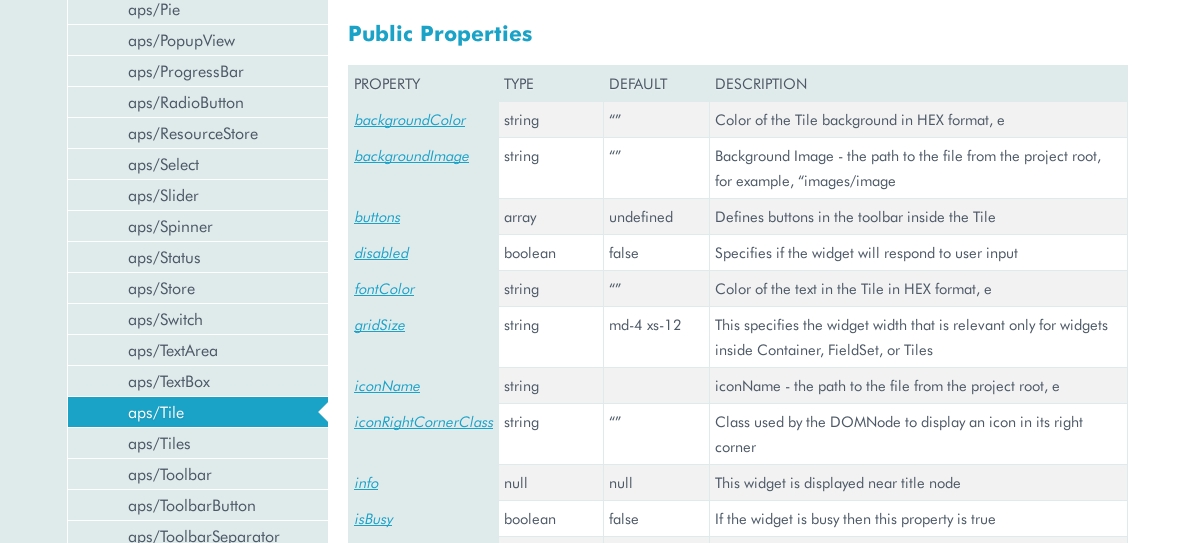 API Reference
API Reference же предназначен для продвинутых пользователей, которые знают, как пользоваться вашим API и просто хотят уточнить название какого-то свойства или параметры какого-то метода.
Может показаться, что документация это сложно и дорого, потому что её нужно поддерживать в актуальном состоянии, но это, к счастью, немножко не так. Я надеюсь, что вы все себя любите и пишете код с комментариями. Скорее всего, вы описываете свои модули и методы в формате JSDoc, ну просто потому, что это стандарт де-факто в индустрии. А если вы используете React, то у вас есть data-props. Существует много утилит, умеющих собрать JSDoc по вашему коду и выдать JSON-словари, которые можно отображать различными вьюверами так как вам удобно, то есть с сортировкой, поиском, подсветкой, разбиением на категории и всем остальным. С TypeScript
говорят тоже все хорошо.
В любой документации должны быть примеры. И очень важно следить за тем, чтобы они работали. Ничто так не портит впечатление о проекте, как сразу же неработающие примеры из документации. Удивительно, но это случается не так редко, как можно было бы подумать.
Песочница
Хорошо, у нас есть примеры, нам кажется что мы помогли людям. Но обычно люди хотят сами с этим поиграться, поэкспериментировать, то есть хотят сами понять, можно ли из этих примеров сделать то, что решает их задачи. Причем они хотят делать это быстро, просто, ничего не скачивая и не устанавливая. И это тоже решаемая задача, ведь мы JavaScript-разработчики, мы практически всё можем запустить в браузере, и у нас давным давно есть наши замечательные песочницы:
codepen,
jsfiddle,
jsbin. Вы можете собрать свой небольшой сниппет с использованием вашего API и добавить в документацию ссылку по которой люди будут сразу переходить и экспериментировать.
Вам может стать тесно в рамках публичной песочницы и вы захотите сделать свою. Это тоже не так сложно, потому что у нас есть две замечательные библиотеки редакторов кода в браузере. Первая —
CodeMirror, она используется, например, в jsfiddle и Firefox DevTools. Вторая —
Ace, она используется в Atom, многими любимом. Мы в APS-е не стали мелочится и сделали
собственную публичную песочницу, как раз с использованием CodeMirror.
Изначально мы рассчитывали, что песочницей будут пользоваться новички, поэтому сделали так, что любые примеры из документации можно открыть в песочнице, а также сразу добавили автодополнение кода. И в этом тоже нет никакого рокет сайнса, ведь у нас есть JSON-словари нашего API и их можно просто скормить редактору кода. Причем так можно делать не только с браузерными редакторами. К примеру, мне удалось завести такое автодополнение кода в Sublime. Позже мы добавили выбор версии API, одновременную работу нескольких пользователей с одним фрагментом кода и прочее, но это всё необязательные рюшечки. Главное — совсем не сложно сделать простую песочницу с редактором кода и результатами в Iframe. И опять же, для React-а есть уже готовый генератор таких песочниц.
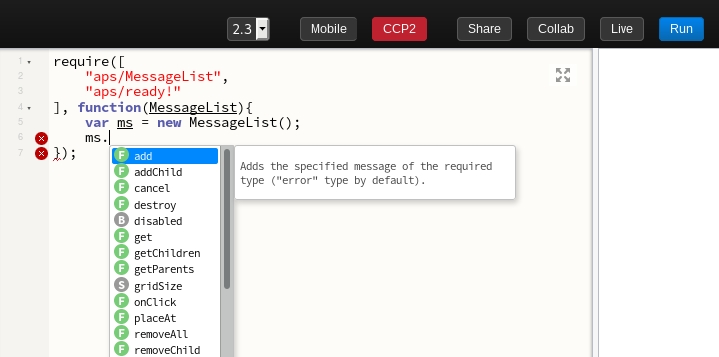
Взаимодействие с пользователем
Вот мы сделали документацию, сделали песочницу и кажется что на этом можно остановиться. Верно, но только если вы собирается остановится в развитии вашего API. Если вы хотите развивать его дальше, то лучше взаимодействовать со своими пользователями. Причем лицом к лицу, а не бросая им новую функциональность через как можно более высокую стену, чтобы не слышать их «благодарных” криков. Проще всего этого сделать с помощью каких-нибудь issues на GitHub-е или всевозможных чатиков и каналов в месенджерах. Но есть вещи о которых пользователи вам не расскажут. Например, у человека была проблема, он её как-то решил, даже пускай костылем, и он этот костыль любовно переносит ctrl-c/ctrl-v из проекта в проект. Но может оказаться, что такой сценарий вы не предусмотрели и в худшем случае пользователь мог даже залезть в какой-нибудь ваш приватный API. Как же с этим бороться?
Первый способ — это собирать различные метрики, то есть логировать вызовы методов и отсылать их куда-то. Можно отслеживать, какие создавались модули и виджеты, с какими параметрами и тому подобное. Разумеется, нужно ещё отслеживать окружение, в котором выполнялся ваш код (версии браузеров, мобильные устройства), потому что статистика по использованию браузеров в мире — вещь полезная, но ваши пользователи могут оказаться стильными/модными/молодежными, которые используют только современные браузеры, а вы зачем-то тратите время и силы на поддержку IE.
Второй способ взаимодействия больше подходит для крупных компаний, которые заинтересованы в использовании их публичного API — заводить специальные команды по обучению. Помните, как Яндекс нам всем мозг ковырял со своим БЭМом на различных субботниках и митапах? У нас в Odin тоже есть команда тренеров, которые катаются по всему миру и обучают людей APS-у. На занятиях тренеры видят, где у людей возникает больше всего затруднений, где они вставляют костыли, любовно переносимые из проекта в проект, тогда мы аккуратненько асфальтируем эти протоптанные людьми тропиночки и делаем им удобные дороги.
Обратная совместимость
Хорошо, мы наладили взаимодействие с пользователем, меняем API так, как они просят, делаем его лучше, лучше… И тут нас ожидает мина, которая называется обратная совместимость. Представьте, вы тихо мирно спите себе дома или нежитесь на райском острове в отпуске, и тут звонит начальник и кричит, что всё пропало, всё сломалось, сервер лежит, клиенты уходят, гипс снимают, сделай что-нибудь.
Вы начинаете вспоминать и понимаете, что там ничего не менялось уже месяц. Лезете разбираться — оказывается, там какая-то маленькая библиотечка обновила минорную версию, а тот, кто её поддерживает, решил, что метод А делает не то, что надо, и поменял его поведение. Но вы-то ожидали от метода старого поведения. И ваш код ожидал старого поведения. Если вы будете вести себя как владелец этой библиотечки, то очень быстро растеряете всех пользователей.
Как же с этим бороться?
Я не могу предложить здесь ничего оригинального: только тесты, тесты и еще раз тесты. Причем тесты не просто на покрытие кода, а на покрытие публичного API. Мы в Odin, подошли к этому совсем тоталитарно и проверяем на этапе pull-request-а, во-первых, деградацию по line of coverage, а, во-вторых, деградацию по публичному API. Поскольку у нас есть JSON-словари мы можем сопоставить их с отчетом о покрытии и выяснить какие методы не были покрыты тестами. Если такие появились, то проверка считается не пройденной и такой pull-request нельзя объединять с мастер-веткой.
Итого
Что нужно сделать, чтобы публичным API было приятно пользоваться?
Во-первых,
писать документацию. Выкладывать что либо в публичный доступ без документации, как минимум глупо, потому что этим никто не будет пользоваться. Причем с документацией есть интересный лайфхак. Попросите коллег-новичков, не знакомых еще с вашим API, что-нибудь с ним сделать по вашей документации. Потому что когда вы читаете документацию, то „накладываете“ её на знания об устройстве API и вам всё понятно. А у нового человека таких знаний нет, он делает строго по документации и, как показывает практика, обязательно находит какие-нибудь косяки. В качестве бонуса он вливается в работу уже имея некоторое представление чем вы тут занимаетесь и зачем все это надо.
Во-вторых,
нужно взаимодействовать с пользователями, чтобы не делать сферического коня в вакууме.
Ну и в-третьих, нужно
писать тесты. Причем заливая всё трехметровым слоем бетона, полностью контролируя любые изменения, то есть чтобы публичный API менялся
только при изменении мажорной версии.

