Как Reddit создал r/Place
- пятница, 21 апреля 2017 г. в 03:13:54
Над проектом работали несколько команд — фронтенд, бэкенд, мобильная разработка. По большей части он был реализован на уже существовавших в Reddit технологиях. В этой статье мы рассмотрим, как с технической стороны создавался Place. Если хотите посмотреть код Place, то он здесь.
Для начала было крайне важно определить требования к первоапрельскому проекту, потому что запустить его нужно было без «разгона», чтобы все пользователи Reddit сразу получили к нему доступ. Если бы он с самого начала не работал идеально, то вряд ли привлёк бы внимание большого количества людей.
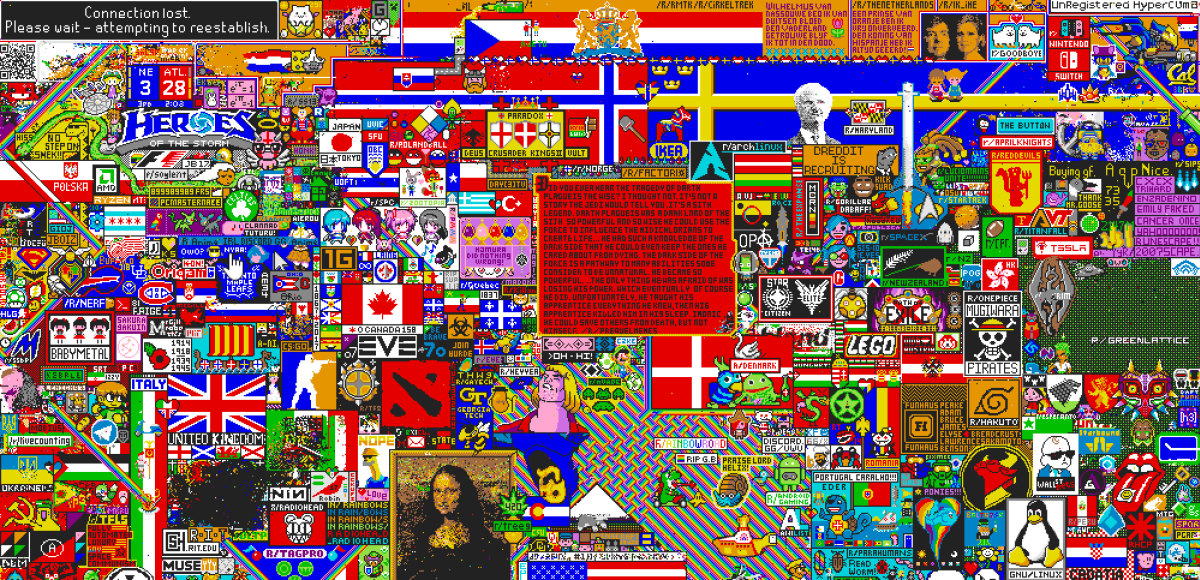
«Доска» должна быть размером 1000х1000 тайлов, чтобы выглядеть очень большой.
Все клиенты должны быть синхронизированы и отображать единое состояние доски. Ведь если у разных пользователей будут разные версии, им будет трудно взаимодействовать.
Нужно поддерживать как минимум 100 000 пользователей одновременно.
Пользователи могут размещать по одному тайлу в пять минут. Поэтому необходимо поддерживать среднюю частоту обновления 100 000 тайлов в пять минут (333 обновления в секунду).
Проект не должен негативно влиять на работу остальных частей и функций сайта (даже при условии высокого трафика на r/Place).
Главной трудностью при создании бэкенда было синхронизировать отображение состояния доски для всех клиентов. Было решено сделать так, чтобы клиенты в реальном времени прослушивали события размещения тайлов и немедленно запрашивали состояние всей доски. Иметь немного устаревшее полное состояние допустимо в случае подписки на обновления до того, как это полное состояние было сгенерировано. Когда клиент получает полное состояние, он отображает все тайлы, которые получил во время ожидания; все последующие тайлы должны отображаться на доске сразу же по мере получения.
Чтобы эта схема работала, запрос полного состояния доски должен выполняться как можно быстрее. Сначала мы хотели хранить всю доску в одной строке в Cassandra, и чтобы каждый запрос просто считывал эту строку. Формат каждой колонки в этой строке был таким:
(x, y): {‘timestamp’: epochms, ‘author’: user_name, ‘color’: color}Но поскольку доска содержит миллион тайлов, нам нужно было считывать миллион колонок. На нашем рабочем кластере это занимало до 30 секунд, что было неприемлемо и могло привести к чрезмерной нагрузке на Cassandra.
Тогда мы решили хранить всю доску в Redis. Взяли битовое поле на миллион четырёхбитовых чисел, каждое из которых могло кодировать четырёхбитный цвет, а координаты х и y определялись смещением (offset = x + 1000y) в битовом поле. Для получения полного состояния доски нужно было считать всё битовое поле.
Обновлять тайлы можно было посредством обновления значений с конкретными смещениями (не нужно блокировать или проводить целую процедуру чтения/ обновления/ записи). Но все подробности всё равно нужно хранить в Cassandra, чтобы пользователи могли узнать, кто и когда разместил каждый из тайлов. Также мы планировали использовать Cassandra для восстановления доски при сбое Redis. Считывание из него всей доски занимало меньше 100 мс, что было достаточно быстро.
Здесь показано, как мы хранили цвета в Redis на примере доски 2х2:

Мы переживали, что можем упереться в пропускную способность чтения в Redis. Если много клиентов одновременно подключались или обновлялись, то все они одновременно отправляли запросы на получение полного состояния доски. Поскольку доска представляла собой общее глобальное состояние, то очевидным решением было воспользоваться кешированием. Решили кешировать на уровне CDN (Fastly), потому что это было проще в реализации, да и кеш получался ближе всего к клиентам, что уменьшало время получения ответа.
Запросы полного состояния доски кешировались Fastly с тайм-аутом в секунду. Чтобы предотвратить большое количество запросов при истечении тайм-аута, мы воспользовались заголовком stale-while-revalidate. Fastly поддерживает около 33 POP, которые независимо друг от друга осуществляют кеширование, поэтому мы ожидали получать до 33 запросов полного состояния доски в секунду.
Для публикации обновлений для всех клиентов мы воспользовались своим вебсокет-сервисом. До этого мы успешно использовали его для обеспечения работы Reddit.Live с более чем 100 000 одновременных пользователей для уведомлений о личных сообщениях в Live и прочих фич. Сервис также был краеугольным камнем наших прошлых первоапрельских проектов — The Button и Robin. В случае с r/Place клиенты поддерживали вебсокет-подключения для получения обновлений о размещениях тайлов в реальном времени.
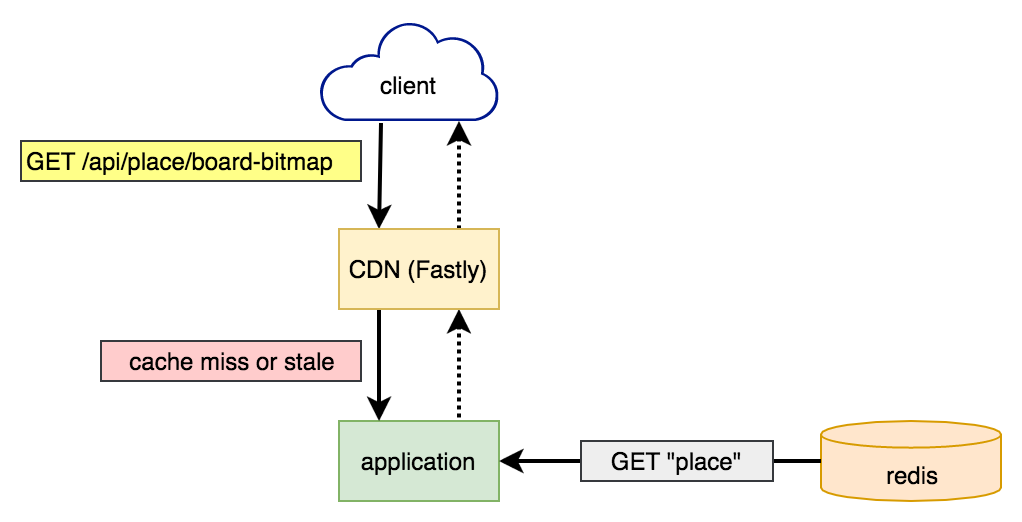
Сначала запросы попадали в Fastly. Если в нём была действующая копия доски, то он немедленно её возвращал без обращения к серверам приложений Reddit. Если же нет или копия была слишком старой, то приложение Reddit считывало полную доску из Redis и возвращало её в Fastly, чтобы тот закешировал и вернул клиенту.
Частота запросов и время ответов, измеренные приложением Reddit:

Обратите внимание, что частота запросов никогда не достигала 33 в секунду, то есть кеширование с помощью Fastly было очень эффективным средством защиты приложения Reddit от большинства запросов.

А когда запросы всё же доходили до приложения, то Redis отвечал очень быстро.

Этапы отрисовки тайла:
Чтобы соблюсти строгую консистентность, все записи и чтение в Cassandra выполнялись с помощью QUORUM консистентного уровня.
На самом деле, здесь у нас возникла гонка, из-за чего пользователи могли размещать за раз несколько тайлов. На этапах 1–3 не было блокировки, поэтому одновременные попытки отрисовки тайлов могли пройти проверку на первом этапе и быть отрисованы – на втором. Похоже, некоторые пользователи обнаружили этот баг (либо они использовали ботов, которые пренебрегали ограничением на частоту отправки запросов) – и в результате с его помощью было размещено около 15 000 тайлов (~0,09% от общего количества).
Частота запросов и время ответов, измеренные приложением Reddit:
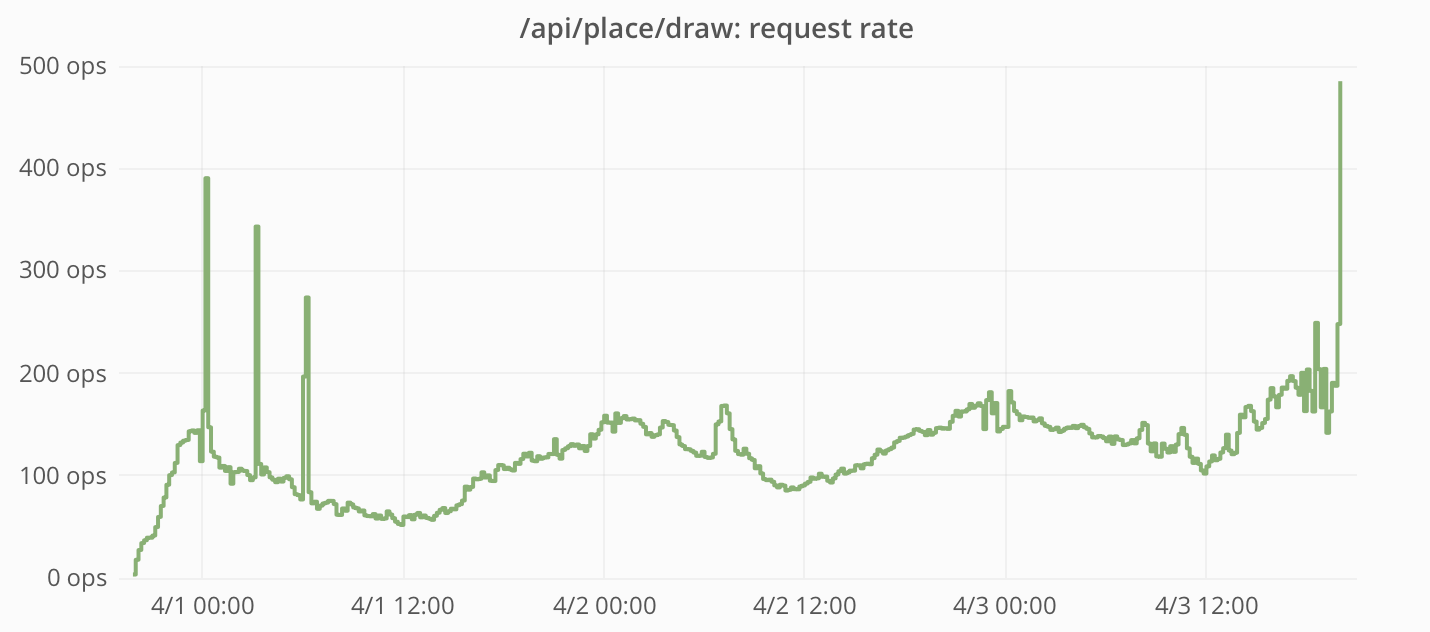
Пиковая частота размещения тайлов составила почти 200 в секунду. Это ниже нашего расчётного предела в 333 тайла/с (среднее значение при условии, что 100 000 пользователей размещают свои тайлы раз в пять минут).
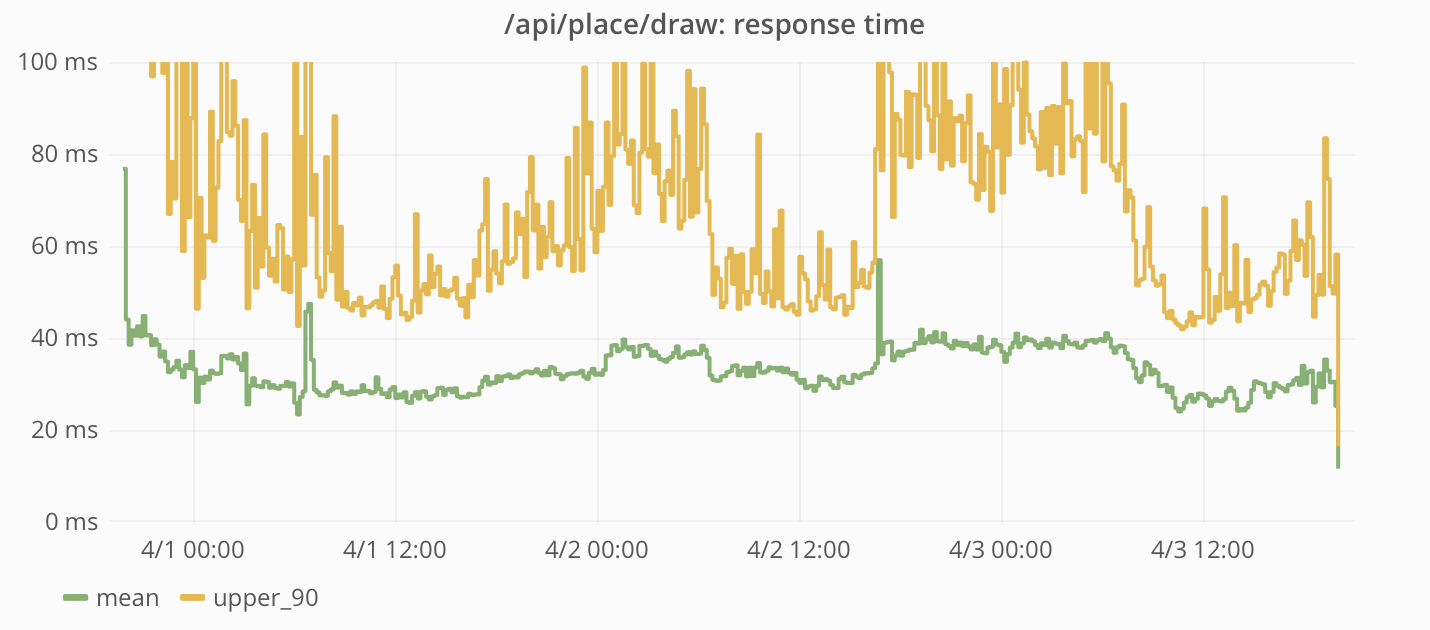
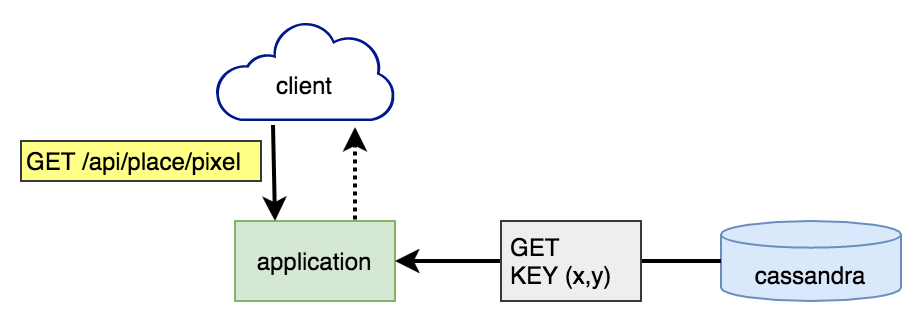
При запросе конкретных тайлов данные считывались напрямую из Cassandra.
Частота запросов и время ответов, измеренные приложением Reddit:
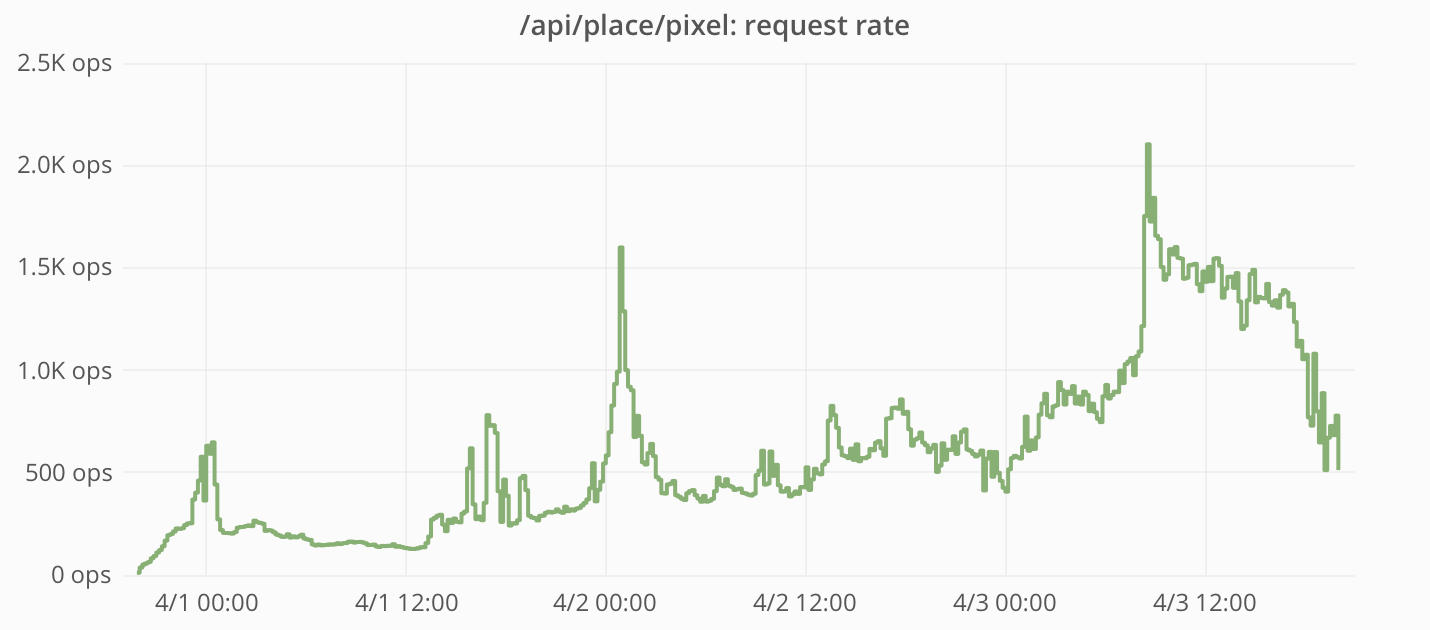
Этот запрос оказался очень популярным. Вдобавок к регулярным клиентским запросам люди написали скрипты для извлечения всей доски по одному тайлу за раз. Поскольку этот запрос не кешировался в CDN, то все запросы обслуживались приложением Reddit.
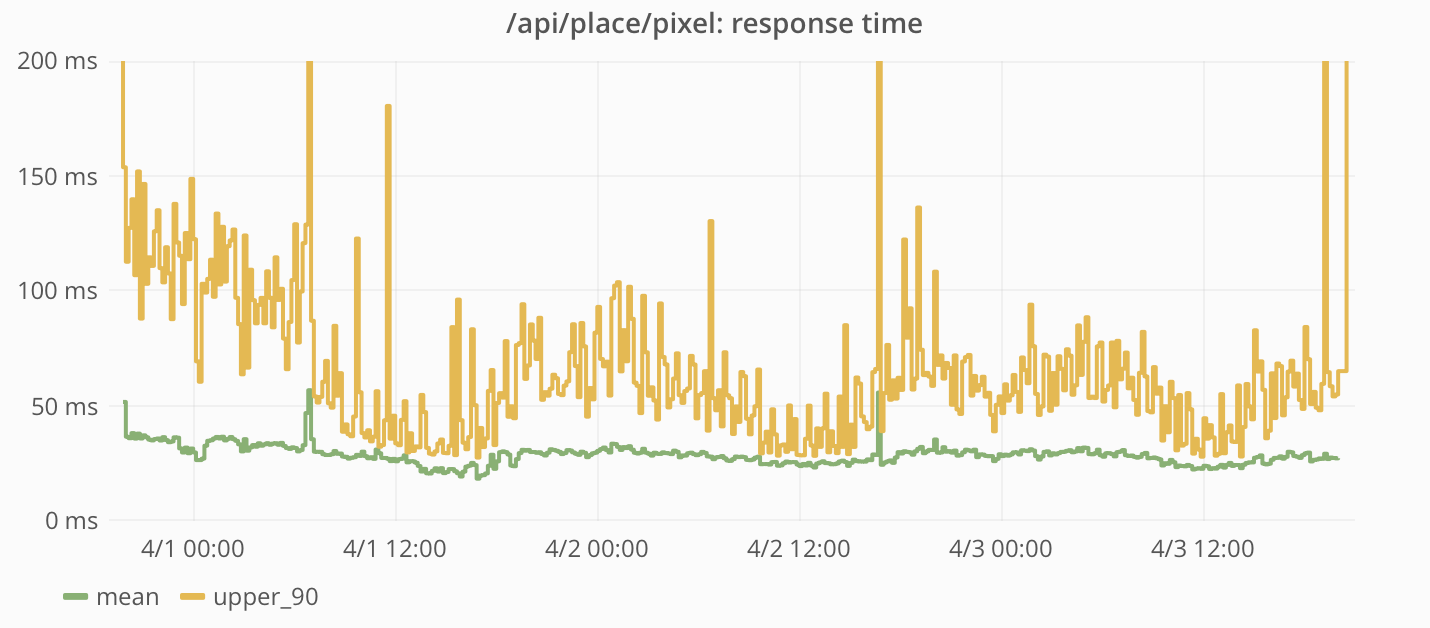
Время ответа на эти запросы было довольно небольшим и держалось на одном уровне в течение всего существования проекта.
У нас нет отдельных метрик, показывающих, как r/Place повлиял на работу вебсокет-сервиса. Но мы можем прикинуть значения, сравнив данные до запуска проекта и после его завершения.
Общее количество подключений к вебсокет-сервису:

Базовая нагрузка до запуска r/Place была около 20 000 подключений, пик — 100 000 подключений. Так что на пике мы, вероятно, имели около 80 000 одновременно подключённых к r/Place пользователей.
Пропускная способность вебсокет-сервиса:

На пике нагрузки на r/Place вебсокет-сервис передавал более 4 Гбит/с (150 Мбит/с на каждый инстанс, всего 24 инстанса).
В процессе создания фронтенда для Place нам пришлось решать много сложных задач, связанных с кроссплатформенной разработкой. Мы хотели, чтобы проект работал одинаково на всех основных платформах, включая настольные ПК и мобильные устройства на iOS и Android.
Пользовательский интерфейс должен был выполнять три важные функции:
Главным объектом интерфейса был канвас, и для него идеально подошёл Canvas API. Мы использовали элемент <canvas> размером 1000х1000, а каждый тайл отрисовывали как одиночный пиксель.
Канвас должен был отражать состояние доски в реальном времени. Нужно было нарисовать всю доску при загрузке страницы и дорисовывать обновления, приходящие через вебсокеты. Элемент canvas, использующий интерфейс CanvasRenderingContext2D, можно обновлять тремя способами:
drawImage().fillRect() заполняет прямоугольник каким-нибудь цветом.ImageData и рисовать его в канвасе с помощью putImageData().Первый вариант нам не подошёл, потому что у нас не было доски в форме готового изображения. Оставались варианты 2 и 3. Проще всего было обновлять отдельные тайлы с помощью fillRect(): когда приходит обновление через вебсокет, просто рисуем прямоугольник размером 1х1 на позиции (x, y). В целом способ работал, но был не слишком удобен для отрисовки начального состояния доски. Метод putImageData() подходил гораздо лучше: мы могли определять цвет каждого пикселя в одном-единственном объекте ImageData и рисовать весь канвас за раз.
Использование putImageData() требует определения состояния доски в виде Uint8ClampedArray, где каждое значение — восьмибитное беззнаковое число в диапазоне от 0 до 255. Каждое значение представляет какой-то цветовой канал (красный, зелёный, синий, альфа), и для каждого пикселя нужно четыре элемента в массиве. Для канваса 2х2 необходим 16-байтный массив, в котором первые четыре байта представляют верхний левый пиксель канваса, а последние четыре — правый нижний.
Здесь показано, как пиксели канваса связаны со своими Uint8ClampedArray-представлениями:
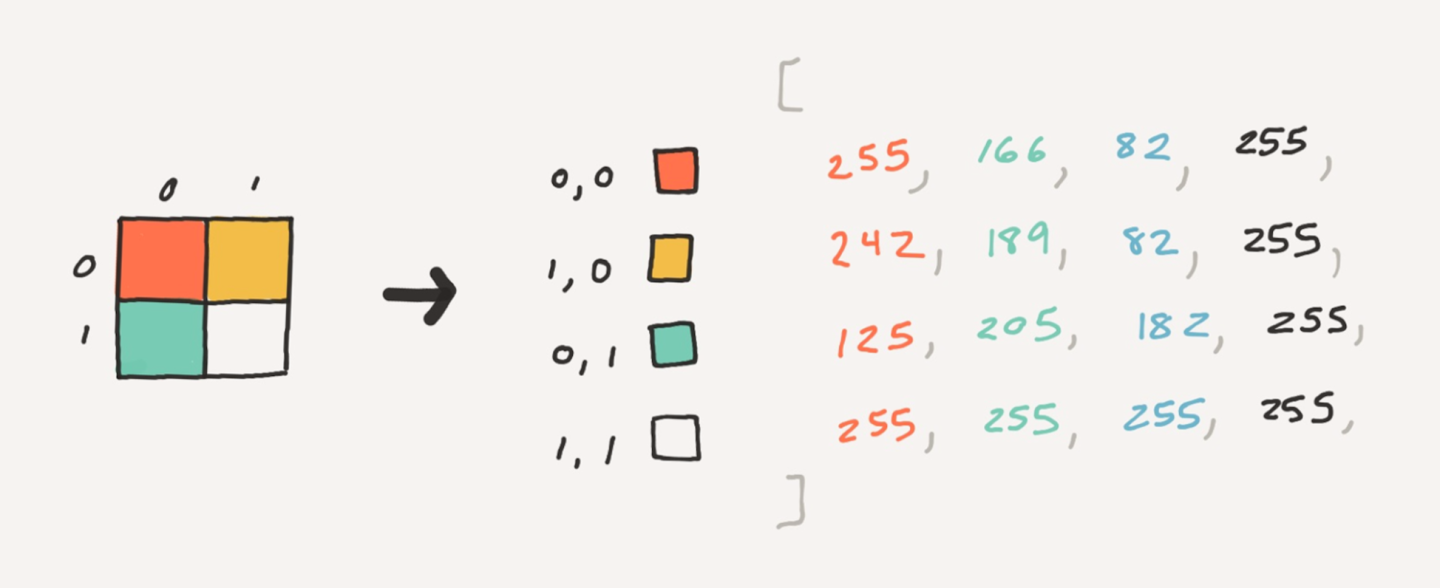
Для канваса нашего проекта понадобился массив на четыре миллиона байтов — 4 Мб.
В бэкенде состояние доски хранится в виде четырёхбитного битового поля. Каждый цвет представлен числом от 0 до 15, что позволило нам упаковать два пикселя в каждый байт. Чтобы использовать это на клиентском устройстве, нужно сделать три вещи:
Для передачи бинарных данных мы использовали Fetch API в тех браузерах, которые его поддерживают. А в тех, которые не поддерживают, использовали XMLHttpRequest с responseType, имеющим значение “arraybuffer”.
Бинарные данные, полученные от API, в каждом байте содержат два пикселя. Самый маленький конструктор TypedArray, что у нас был, позволяет работать с бинарными данными в виде однобайтовых юнитов. Но они неудобны в использовании на клиентских устройствах, так что мы распаковывали данные, чтобы с ними было проще работать. Процесс простой: мы итерировали по упакованным данным, вытаскивали старшеразрядные и младшеразрядные биты, а затем копировали их в отдельные байты в другой массив.
Наконец, четырёхбитные цвета нужно было преобразовать в 32-битные.

Структура ImageData, которая нам понадобилась для использования putImageData(), требует, чтобы конечный результат был в виде Uint8ClampedArray с байтами, кодирующими цветовые каналы в очерёдности RGBA. Это означает, что нам нужно было осуществить ещё одну распаковку, разбивая каждый цвет на компонентные канальные байты и помещяя их в правильный индекс. Не слишком-то удобно выполнять четыре записи на каждый пиксель. Но к счастью, был ещё один вариант.
Объекты TypedArray по сути являются представлениями ArrayBuffer в виде массивов. Тут есть один нюанс: многочисленные инстансы TypedArray могут читать и писать в один и тот же инстанс ArrayBuffer. Вместо записи четырёх значений в восьмибитный массив мы можем записать одно значение в 32-битный! Используя Uint32Array для записи, мы смогли легко обновлять цвета тайлов, просто обновляя один индекс массива. Правда, пришлось сохранять нашу палитру цветов в обратном байтовом порядке (ABGR), чтобы байты автоматически попадали на правильные места при считывании с помощью Uint8ClampedArray.

Метод drawRect() хорошо подходил для отрисовки обновлений по отдельным пикселям по мере их получения, но было одно слабое место: большие порции обновлений, приходящие одновременно, могли привести к торможению в браузерах. А мы понимали, что обновления состояния доски могут приходить очень часто, так что проблему нужно было как-то решать.
Вместо того чтобы немедленно перерисовывать канвас при каждом получении обновления через вебсокет, мы решили сделать так, чтобы вебсокет-обновления, приходящие одновременно, можно было объединять в пакеты и сразу скопом отрисовывать. Для этого были внесены два изменения:
drawRect() – мы нашли удобный способ обновлять много пикселей за раз с помощью putImageData().Благодаря переносу отрисовки в анимационный цикл мы смогли немедленно записывать вебсокет-обновления в ArrayBuffer, при этом откладывая фактическую отрисовку. Все вебсокет-обновления, приходящие между фреймами (около 16 мс), объединялись в пакеты и отрисовывались одновременно. Благодаря использованию requestAnimationFrame, если бы отрисовка заняла слишком много времени (дольше 16 мс), то это повлияло бы только на частоту обновления канваса (а не ухудшило бы производительность всего браузера).
Важно отметить, что канвас был нужен для того, чтобы пользователям было удобнее взаимодействовать с системой. Основной сценарий взаимодействия — размещение тайлов на канвасе.
Но делать точную отрисовку каждого пикселя в масштабе 1:1 было бы крайне сложно, и мы не избежали бы ошибок. Так что нам был необходим зум (большой!). Кроме того, пользователям нужна была возможность легко перемещаться по канвасу, ведь он был слишком велик для большинства экранов (особенно при использовании зума).
Поскольку пользователи могли размещать тайлы раз в пять минут, то ошибки при размещении были бы особенно неприятны для них. Нужно было реализовать зум такой кратности, чтобы тайл получался достаточно большим, и его можно было легко поместить в нужное место. Это было особенно важно на устройствах с сенсорными экранами.
Мы реализовали 40-кратный зум, то есть каждый тайл имел размер 40х40. Мы обернули элемент <canvas> в <div>, к которому применили CSS transform: scale(40, 40). Это было отличным решением для размещения тайлов, но затрудняло просмотр доски (особенно на маленьких экранах), поэтому мы сделали двухступенчатый зум: 40х — для рисования тайлов, 4х — для просмотра доски.
Использование CSS для масштабирования канваса позволило легко отделить код, отвечающий за отрисовку доски, от кода, отвечающего за масштабирование. Но у этого подхода оказалось несколько недостатков. При масштабировании картинки (канваса) браузеры по умолчанию применяют алгоритмы сглаживания изображений. В каких-то случаях это не доставляет неудобств, но пиксельную графику просто уничтожает, превращая её в мыльную кашу. Хорошая новость — есть CSS-свойство image-rendering, с помощью которого мы смогли «попросить» браузеры не применять сглаживание. Плохая новость — не все браузеры имеют полноценную поддержку этого свойства.
Размытие при зуме:

Для таких браузеров нужно было найти другой способ масштабирования. Выше я упоминал, что есть три способа рисования в канвасе. Первый, drawImage(), поддерживает отрисовку имеющегося изображения или другого канваса. Также он поддерживает масштабирование изображения при отрисовке (с увеличением или уменьшением). И хотя увеличение имеет те же проблемы с размытием, что и вышеупомянутый CSS, их можно решить более универсальным с точки зрения поддержки браузеров способом — сняв флаг CanvasRenderingContext2D.imageSmoothingEnabled.
Итак, мы решили проблему с размытием канваса, добавив ещё один этап в процесс рендеринга. Для этого мы сделали ещё один элемент <canvas>, который по размеру и позиции совпадает с элементом-контейнером (то есть с видимой зоной доски). После перерисовки канваса с помощью drawImage() в новом канвасе рисуется видимая его часть в нужном масштабе. Поскольку этот дополнительный этап немного увеличивает стоимость рендеринга, мы использовали его только в браузерах, которые не поддерживают CSS-свойство image-rendering.
Канвас — это довольно большое изображение, особенно в приближенном виде, поэтому нам нужно было обеспечить возможность перемещения по нему. Для настройки позиции канваса на экране мы применили тот же подход, что и в случае с масштабированием: обернули элемент <canvas> в другой <div>, к которому применили CSS transform: translate(x, y). Благодаря отдельному div’у мы смогли легко управлять порядком применения преобразований к канвасу, что было необходимо для предотвращения перемещения «камеры» при изменении зума.
В результате мы обеспечили поддержку разных способов настройки позиции «камеры»:
Каждый из этих методов реализован по-разному.
Это первичный способ навигации. Мы сохраняли координаты x и y события mousedown. Для каждого из таких событий мы находили смещение позиции курсора мыши относительно начальной позиции, а затем добавляли это смещение к имеющемуся смещению канваса. Сразу же обновлялась позиция камеры, так что навигация была очень отзывычивой.
При клике на тайл он помещался в центр экрана. Для реализации этого механизма нам пришлось отслеживать расстояние между событиями mousedown и mouseup, чтобы отделить «нажатия» от «перемещений». Если расстояние, на которое переместилась мышь, было недостаточным, чтобы считаться «перемещением», позиция «камеры» менялась на основании разницы между позицией мыши и точкой в центре экрана. В отличие от предыдущего способа навигации, позиция «камеры» обновлялась с применением функции плавности. Вместо того чтобы сразу задавать новую позицию, мы сохраняли её как «целевую». Внутри анимационного цикла (того же, что использовался для перерисовки канваса) текущая позиция «камеры» с помощью функции плавности перемещалась ближе к целевой. Это позволило избавиться от эффекта слишком резкого перемещения.
Можно было перемещаться по канвасу с помощью клавиатурных стрелок или WASD. Эти клавиши управляли внутренним вектором движения. Если ни одна из клавиш не была нажата, то вектор по умолчанию имел координаты (0, 0). Нажатие любой из клавиш навигации добавляло 1 к x или y. Например, если нажать «вправо» и «вверх», то координаты вектора будут (1, -1). Затем этот вектор использовался внутри анимационного цикла для перемещения «камеры».
В процессе анимации скорость движения вычислялась в зависимости от уровня приближения по следующей формуле:
movementSpeed = maxZoom / currentZoom * speedMultiplierКогда зум был отключён, управлять кнопками получалось быстрее и гораздо естественнее.
Затем вектор движения нормализовывался, умножался на скорость движения и применялся к текущей позиции «камеры». Нормализация использовалась, чтобы скорость диагональных и ортогональных перемещений совпадала. Наконец, мы применили функцию плавности к изменениям самого вектора движения. Это сгладило изменения направления перемещения и скорости, так что «камера» двигалась гораздо плавнее.
При встраивании канваса в iOS- и Android-приложения мы столкнулись с некоторыми сложностями. Во-первых, нам нужно было аутентифицировать пользователя, чтобы он мог размещать тайлы. В отличие от веб-версии, где аутентификация основана на сессии, в мобильных приложениях мы использовали OAuth: в этом случае приложения должны предоставлять залогиненному пользователю WebView с токеном доступа. Наиболее безопасно реализовать это можно с помощью внедрения авторизационных заголовков OAuth посредством JS-вызова из приложения к WebView. Это позволило бы нам при необходимости настроить другие заголовки. Затем нужно было просто парсить авторизационные заголовки при каждом вызове API:
r.place.injectHeaders({‘Authorization’: ‘Bearer <access token>’});В версии для iOS мы дополнительно реализовали поддержку уведомлений, когда тайл пользователя был готов к помещению в канвас. Поскольку размещение выполнялось полностью в WebView, нам пришлось реализовать колбэк нативного приложения. К счастью, в iOS 8 и выше это делается с помощью простого JS-вызова:
webkit.messageHandlers.tilePlacedHandler.postMessage(this.cooldown / 1000);Затем метод делегата в приложении диспетчеризировал уведомления на основании переданного ему таймера перезарядки.

Мы всё идеально спланировали. Мы знали, когда будет запуск. Всё должно было пройти как по маслу. У нас были протестированные под нагрузкой фронтенд и бэкенд. Мы, люди, просто не могли совершить ещё какие-то ошибки. Верно?
Запуск действительно прошёл гладко. В течение утра по мере роста популярности r/Place увеличивалось количество подключений и возрастал трафик на инстансы вебсокетов:
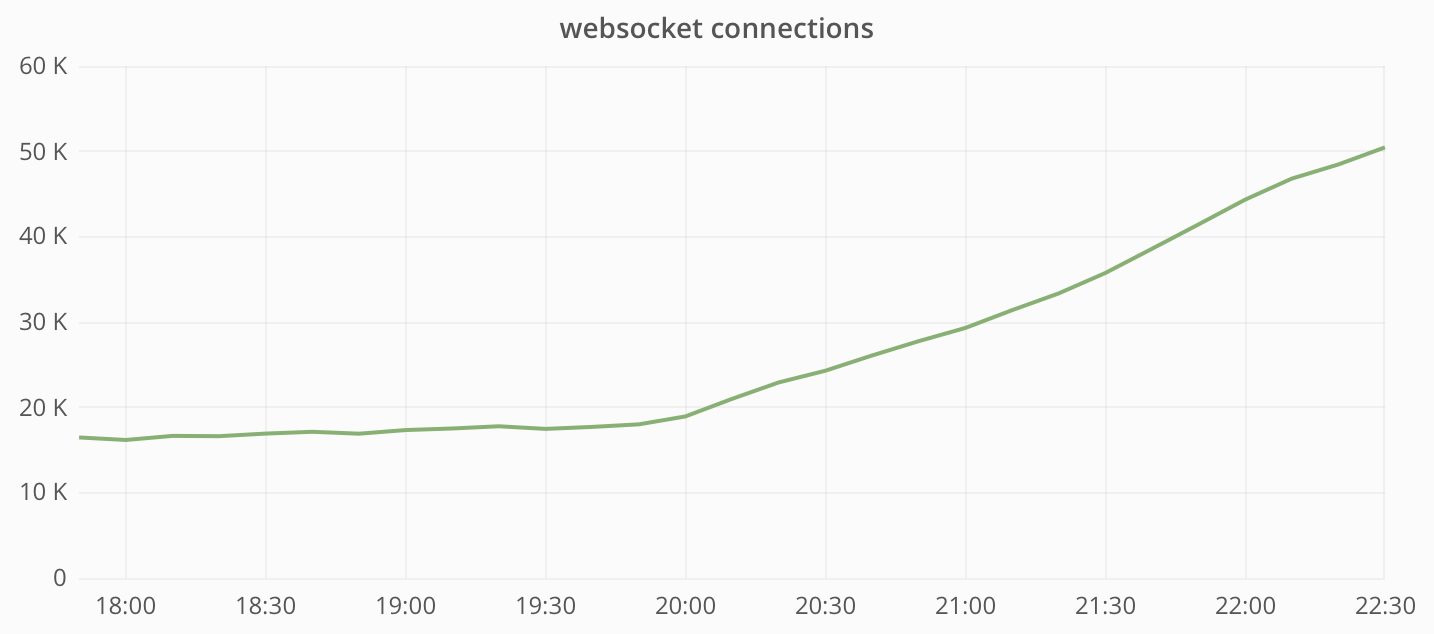

Мы это предвидели. И готовились к тому, что в результате сеть станет узким местом в нашей системе. Но оказалось, что у нас есть большой запас. Однако, посмотрев на загрузку ЦПУ, мы увидели совсем другую картину:

Это восьмиядерные машины, так что было очевидно, что они достигли своего предела. Почему эти «коробки» повели себя так неожиданно? Мы решили, что генерируемая Place нагрузка по своему характеру сильно отличается от того, что было раньше. Кроме того, использовалось большое количество очень маленьких сообщений, в то время как обычно мы отправляем сообщения большего размера вроде обновления Live-тредов и уведомлений. Также, как правило, у нас нет такого количества пользователей, получающих одно и то же сообщение. Так что условия работы сильно отличались от привычных.
Мы решили, что ничего страшного не происходит: масштабируемся – и дело с концом. Ответственный сотрудник просто удвоил количество инстансов и отправился к врачу без грамма волнения.
А потом случилось это:

На первый взгляд, ничего особенного. Если бы не тот факт, что это был наш production-инстанс RabbitMQ, обрабатывающий не только вебсокет-сообщения, но и вообще всё, от чего зависит функционирование reddit.com. И это было нехорошо. Совсем нехорошо.
После многочисленных расследований, заламываний рук и апгрейдов инстансов мы сузили область поиска источника проблемы до интерфейса управления. Он всегда казался каким-то медленным, и мы решили, что его регулярно запрашивает наш Rabbit Diamond collector. Мы подумали, что дополнительный обмен данными, связанный с запуском новых вебсокет-инстансов, в сочетании с массой сообщений, получаемых в связи с этим обменом, привели к перегрузке Rabbit, пытавшегося вести учёт выполнения запросов к админке. Поэтому мы просто выключили её – и ситуация улучшилась.
Но мы не любим пребывать в неведении, поэтому на скорую руку сварганили кустарный мониторинговый скрипт:
$ cat s****y_diamond.sh
#!/bin/bash
/usr/sbin/rabbitmqctl list_queues | /usr/bin/awk '$2~/[0-9]/{print "servers.foo.bar.rabbit.rabbitmq.queues." $1 ".messages " $2 " " systime()}' | /bin/grep -v 'amq.gen' | /bin/nc 10.1.2.3 2013Если вам интересно, почему мы продолжили настраивать тайм-ауты размещения пикселей, то ответ такой: мы пытались уменьшить нагрузку на весь проект. По той же причине в течение какого-то времени некоторые пиксели долго не отображались на доске.
К сожалению, несмотря на такие сообщения:

Упомянутые здесь изменения времени перезарядки имели чисто технические причины. Хотя после них занятно было наблюдать за веткой r/place/new:
Возможно, это было частью мотивации пользователей.
На финальной стадии работы проекта мы столкнулись ещё с одной неурядицей. У нас регулярно возникают проблемы с клиентами, плохо себя ведущими с точки зрения попыток повторного обращения. Немало клиентов, столкнувшись с ошибками, просто отправляют повторные запросы. И снова. И снова. То есть когда на сайте появляется какая-то проблема, это приводит к валу повторных запросов от клиентов, которые не знают, что такое выдержка.
Когда мы отключили Place, то конечные точки, к которым обращалось множество ботов, начали возвращать «не двухсотые» ошибки. Этот код был не слишком удачен. К счастью, все эти повторные обращения удалось легко блокировать на уровне Fastly.
r/Place не был бы так успешен, если бы не слаженная командная работа. Мы хотели бы поблагодарить u/gooeyblob, u/egonkasper, u/eggplanticarus, u/spladug, u/thephilthe, u/d3fect и всех остальных, кто помогал нам претворить в жизнь этот первоапрельский эксперимент.