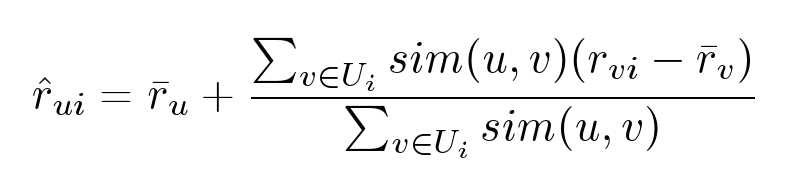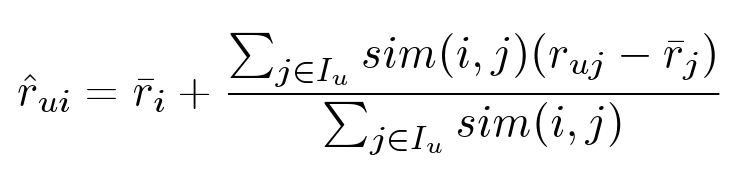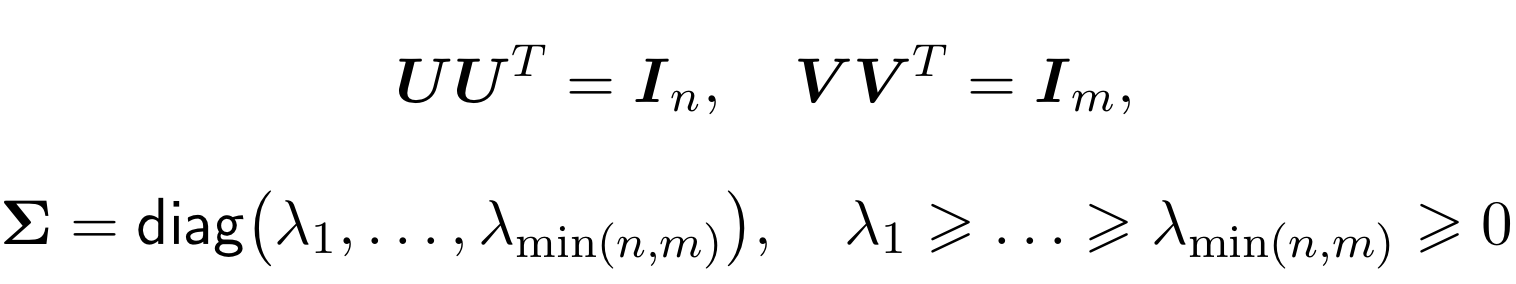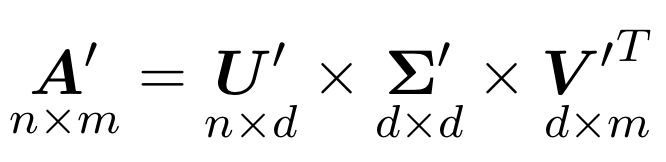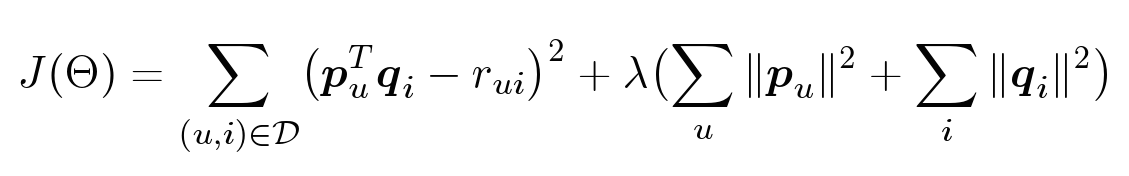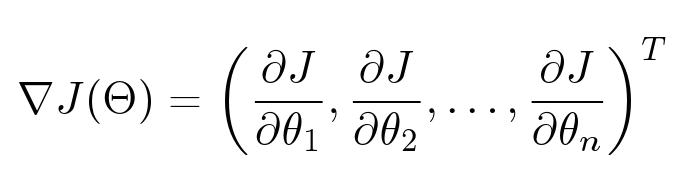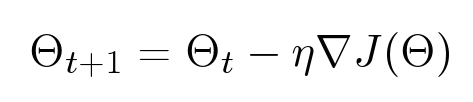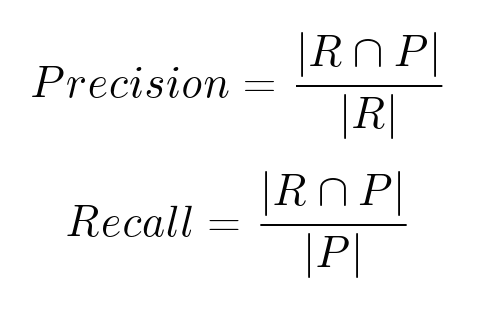http://habrahabr.ru/company/yandex/blog/241455/
Привет, меня зовут Михаил Ройзнер. Недавно я выступил перед студентами Малого Шада Яндекса с лекцией о том, что такое рекомендательные системы и какие методы там бывают. На основе лекции я подготовил этот пост.
План лекции:
- Виды и области применения рекомендательных систем.
- Простейшие алгоритмы.
- Введение в линейную алгебру.
- Алгоритм SVD.
- Измерение качества рекомендаций.
- Направление развития.
Начнем с простого: что вообще такое рекомендательные системы, и какими они бывают. Наверное, все уже сталкивались с ними в интернете. Первый пример — рекомендательные системы фильмов.

На сайте imdb.com пользователи могут оценивать фильмы по десятибалльной шкале. Оценки агрегируются, получается средний рейтинг фильма. На этом же сайте есть блок с рекомендациями для конкретного пользователя. Если я зашел на сайт и оценил несколько фильмов, imdb сможет порекомендовать мне еще какие-нибудь фильмы. Похожий блок есть и на фейсбуке.
Нечто сходное, но только для музыки, делает last.fm. Он рекомендует мне исполнителей, альбомы, мероприятия, на которые мне стоит сходить. Сервис Pandora в России почти неизвестен, т.к. у нас он не работает, однако в Америке он очень популярен. Это такое персональное радио, которое постепенно подстраивается под пользователя на основе его оценок, и в итоге играет только те треки, которые ему нравятся.
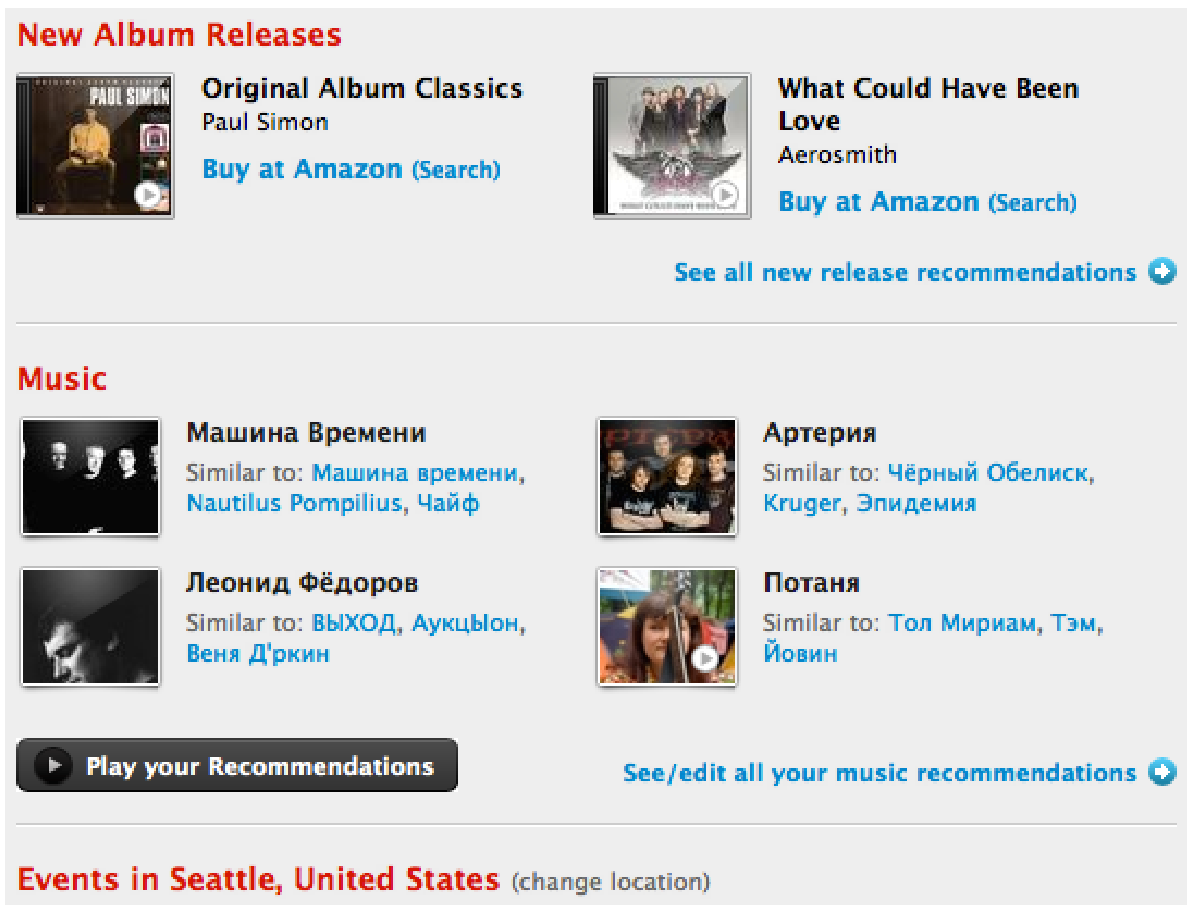
Еще одна известная область — рекомендация товаров. На картинке ниже у нас, конечно же, Amazon. Если вы купили что-то на амазоне, за вами будут охотиться с дополнительными предложениями: похожими товарами или аксессуарами. Это хорошо и для пользователей (им не нужно искать эти товары самостоятельно), и конечно, это хорошо для самого магазина.

Мы перечислили три категории, но на самом деле их гораздо больше: заведения на карте, новости, статьи, сайты, концерты, театры, выставки, видео, книги, приложения, игры, путешествия, социальные связи и многое другое.
Виды рекомендательных систем
Можно выделить два основных типа рекомендательных систем. Их, конечно же больше, но мы сегодня будем рассматривать именно эти и в особенности коллаборативную фильтрацию.
- Content-based
- Пользователю рекомендуются объекты, похожие на те, которые этот пользователь уже употребил.
- Похожести оцениваются по признакам содержимого объектов.
- Сильная зависимость от предметной области, полезность рекомендаций ограничена.
- Коллаборативная фильтрация (Collaborative Filtering)
- Для рекомендации используется история оценок ккак самого пользователя, так и других пользователей.
- Более универсальный подход, часто дает лучший результат.
- Есть свои проблемы (например, холодный старт).
Рекомендательные системы появились в интернете достаточно давно, около 20 лет назад. Однако настоящий подъем в этой области случился примерно 5-10 лет назад, когда произошло соревнование Netflix Prize. Компания Netflix тогда давала в прокат не цифровые копии, а рассылала VHS-кассеты и DVD. Для них было очень важно повысить качество рекомендаций. Чем лучше Netflix рекомендует своим пользователям фильмы, тем больше фильмов они берут в прокат. Соответственно, растет и прибыль компании. В 2006 году они запустили соревнование Netflix Prize. Они выложили в открытый доступ собранные данные: около 100 миллионов оценок по пятибалльной шкале с указанием ID проставивших их пользователей. Участники соревнования должны были как можно лучше предугадывать, какую оценку поставит определенному фильму тот или иной пользователь. Качество предсказания измерялось при помощи метрики
RMSE (средне-квадратичное отклонение). У Netflix уже был алгоритм, который предсказывал оценки пользователей с качеством 0.9514 по метрике RMSE. Задача была улучшить предсказание хотя бы на 10% — до 0.8563. Победителю был обещан приз в $ 1 000 000. Соревнование длилось примерно три года. За первый год качество улучшили на 7%, дальше все немного замедлилось. Но в конце две команды с разницей в 20 минут прислали свои решения, каждое из которых проходило порог в 10%, качество у них было одинаковое с точностью до четвертого знака. В задаче, над которой множество команд билось три года, все решили каких-то двадцать минут. Опоздавшая команда (как и многие другие, участвовавшие в конкурсе) остались ни с чем, однако сам конкурс очень сильно подстегнул развитие в этой области.
Простейшие алгоритмы
Для начала формализуем нашу задачу. Что мы имеем? У нас есть множество пользователей 𝑢 ∈ 𝑈, множество объектов 𝑖 ∈ 𝐼 (фильмы, треки, товары и т.п.) и множество событий (𝑟
𝑢𝑖, 𝑢, 𝑖, ...) ∈ 𝒟 (действия, которые пользователи совершают с объектами). Каждое событие задается пользователем 𝑢, объектом 𝑖, своим результатом 𝑟
𝑢𝑖 и, возможно, еще какими-то характеристиками. От нас требуется:
- предсказать предпочтение:
𝑟̂𝑢𝑖 = Predict (𝑢,𝑖,...) ≈ 𝑟𝑢𝑖.
- персональные рекомендации:
𝑢 ⟼ (𝑖1,...,𝑖𝘒) = Recommend𝘒(𝑢,...).
- похожие объекты:
𝑢 ⟼ (𝑖1,...,𝑖𝑀) = Similar𝑀(𝑖).
Таблица оценок
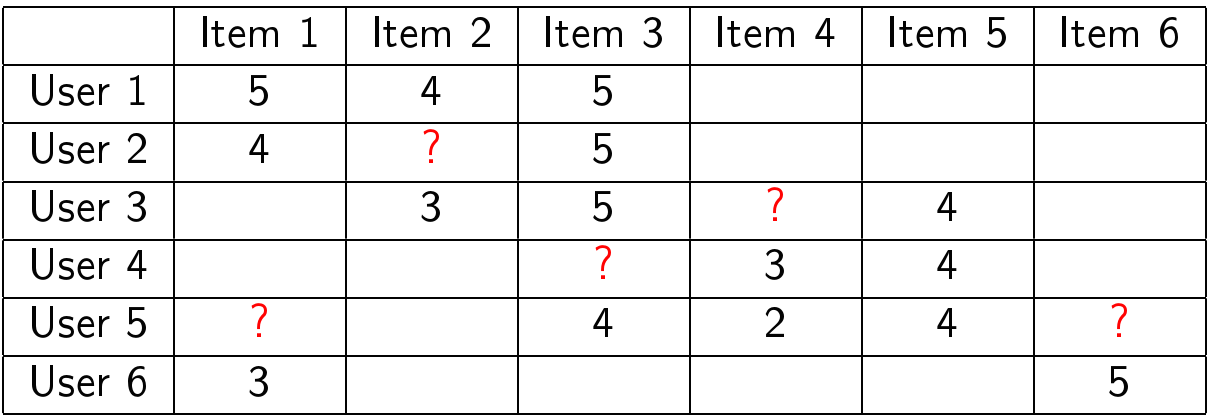
Допустим, нам дана таблица с оценками пользователей:

На нужно как можно лучше предсказать, какие оценки должны быть в ячейках со знаками вопроса:
Кластеризация пользователей
Напомним, что основная идея коллаборативной фильтрации — похожим пользователям обычно нравятся похожие объекты. Начнем с самого простого метода.
- Выберем некоторую условную меру схожести пользователей по их истории оценок 𝑠𝑖𝑚(𝑢, 𝑣).
- Объединим пользователей в группы (кластеры) так, чтобы похожие пользователи оказывались в одном кластере: 𝑢 ⟼ 𝐹(𝑢).
- Оценку пользователя объекту будем предсказывать как среднюю оценку кластера этому объекту:
У этого алгоритма есть несколько проблем:
- Нечего рекомендовать новым/нетипичным пользователям. Для таких пользователей не найдется подходящего кластера с похожими на них пользователями.
- Не учитывается специфика каждого пользователя. В каком-то смысле мы делим всех пользователей на какие-то классы (шаблоны).
- Если в кластере никто не оценивал объект, то предсказание сделать не получится.
User-based
Попробуем несколько улучшить предыдущий метод и заменить жесткую кластеризацию на следующую формулу:
Однако у этого алгоритма также есть свои проблемы:
- Нечего рекомендовать новым/нетипичным пользователям. Для таких пользователей мы все еще не можем найти похожих.
- Холодный старт — новые объекты никому не рекомендуются.
Item-based
Есть абсолютно симметричный алгоритм:
В предыдущем методе мы отталкивались от идеи, что, скажем, фильм понравится пользователю, если он понравился его друзьям. Здесь же мы считаем, что фильм понравится пользователю, если ему понравились похожие фильмы.
Проблемы:
- Холодный старт — новые объекты никому не рекомендуются.
- Рекомендации часто тривиальны.
Общие проблемы перечисленных методов
Все перечисленные методы обладают следующими недостатками:
- Проблема холодного старта.
- Плохие предсказания для новых/нетипичных пользователей/объектов.
- Тривиальность рекомендаций.
- Ресурсоемкость вычислений. Для того, чтобы делать предсказания нам нужно держать в памяти все оценки всех пользователей.
Поэтому перейдем к более сложному алгоритму, который практически лишен этих недостатков.
Алгоритм SVD
Для этого алгоритма нам потребуется несколько понятий из линейной алгебры: векторы, матрицы и операции с ними. Я не буду здесь приводить все определения, если вам нужно освежить эти знания, то все объяснения есть в видеозаписи лекции примерно с 33 минуты.
SVD (Singular Value Decomposition), переводится как сингулярное разложение матрицы. В теореме о сингулярном разложении утверждается, что у любой матрицы 𝐀 размера 𝑛×𝑚 существует разложение в произведение трех матриц: 𝑈, Ʃ и 𝑉
𝑇:
Матрицы 𝑈 и 𝑉 ортогональные, а Ʃ — диагональная (хотя и не квадратная).
Причем лямбды в матрице Ʃ будут упорядочены по невозрастанию. Сейчас мы эту теорему не будем доказывать не будем, просто воспользуемся самим разложением.
Но что нам с того, что мы можем какую-то матрицу в произведение трех еще более непонятных матриц. Для нас тут будет интересно следующее. Помимо обычного разложения бывает еще усеченное, когда из лямбд, остаются только первые 𝑑 чисел, а остальные мы полагаем равными нулю.
Это равносильно тому, что у матриц 𝑈 и 𝑉 мы оставляем только первые 𝑑
столбцов, а матрицу Ʃ обрезаем до квадратной 𝑑×𝑑.
Так вот, оказывается, что полученная матрица 𝐀′ хорошо приближает исходную матрицу 𝐀 и, более того, является наилучшим низкоранговым приближением с точки зрения средне-квадратичного отклонения.
SVD для рекомендаций
Как же использовать все это для рекомендаций? У нас была матрица, мы разложили ее в произведение трех матриц. При чем разложили не точно, а приблизительно. Упростим все немного, обозначив произведение первых двух матриц за одну матрицу:
Теперь отвлечемся немного от всех этих матриц и сконцентрируемся на получившемся алгоритме: чтобы предсказать оценку пользователя 𝑈 для фильма 𝐼, мы берем некоторый вектор 𝑝
𝑢 (набор параметров) для данного пользователя и вектор для данного фильма 𝑞
𝑖. Их скалярное произведение и будет нужным нам предсказанием: 𝑟̂
𝑢𝑖 = ⟨𝑝
𝑢,𝑞
𝑖⟩.
Алгоритм достаточно простой, но дает удивительные результаты. Он не просто позволяет нам предсказывать оценки. С его помощью мы можем по истории пользователей выявлять скрытые признаки объектов и интересы пользователей. Например, может так получиться, что на первой координате вектора у каждого пользователя будет стоять число, показывающее, похож ли пользователь больше на мальчика или на девочку, на второй координате — число, отражающее примерный возраст пользователя. У фильма же первая координата будет показывать, интересен ли он больше мальчикам или девочкам, а вторая — какой возрастной группе пользователей он интересен.
Но не все так просто. Есть несколько проблем. Во-первых, матрица оценок 𝑹 нам полностью не известна, поэтому мы не можем просто взять ее SVD-разложение. Во-вторых, SVD-разложение не единственное: (𝑈Ω)Ʃ(𝑉Ω)
𝑇=𝑈Ʃ𝑉
𝑇, поэтому даже если мы найдем хоть какое-то разложение, вряд ли именно в нем первая координата будет соответствовать полу пользователя, а вторая — возрасту.
Обучение
Попробуем разобраться с первой проблемой. Тут нам понадобится машинное обучение. Итак, мы не можем найти SVD-разложение матрицы, т.к. мы не знаем саму матрицу. Но мы хотим воспользоваться этой идеей и придумать модель предсказания, которая будет работать сходным с SVD образом. Наша модель будет зависеть от многих параметров — векторов пользователей и фильмов. Для заданных параметров, чтобы предсказать оценку, мы возьмем вектор пользователя, вектор фильма и получим их скалярное произведение:
Но так как векторов мы не знаем, их еще нужно получить. Идея заключается в том, что у нас есть оценки пользователей, при помощи которых мы можем найти такие оптимальные параметры, при которых наша модель предсказывала бы эти оценки как можно лучше:
Итак, мы хотим найти такие параметры θ, чтобы квадрат ошибки был как можно меньше. Но тут есть парадокс: мы хотим меньше ошибаться
в будущем, но мы не знаем, какие оценки у нас будут спрашивать. Соответственно и оптимизировать это мы не можем. Но нам известны уже проставленные пользователями оценки. Попробуем подобрать параметры так, чтобы на тех оценках, которые у нас уже есть, ошибка была как можно меньше. Кроме того, добавим еще одно слагаемое — регуляризатор.
Зачем нужен регуляризатор?
Регуляризация нужна для борьбы с переобучением — явлением, когда построенная модель хорошо объясняет примеры из обучающей выборки, но достаточно плохо работает на примерах, не участвовавших в обучении. Вообще, методов борьбы с переобучением существует несколько, хочется отметить два из них. Во-первых, нужно выбирать простые модели. Чем проще модель, тем лучше она обобщается на будущие данные (это похоже на известный принцип бритвы Оккама). А второй метод — это как раз регуляризация. Когда мы настраиваем модель для обучающей выборки, мы оптимизируем ошибку. Регуляризация заключается том, что мы оптимизируем не просто ошибку, а ошибку плюс некоторая функция от параметров (например, норма вектора параметров). Это позволяет ограничить размер параметров в решении, уменьшает степень свободы модели.
Численная оптимизация
Как же нам найти оптимальные параметры? Нам нужно оптимизировать вот такой функционал:
Параметров много: для каждого пользователя, для каждого объекта у нас есть свой вектор, который мы хотим оптимизировать. У нас есть функция, зависящая от большого количества переменных. Как найти ее минимум? Тут нам потребуется градиент — вектор из частных производных по каждому параметру.
Градиент очень удобно представлять себе визуально. На иллюстрации у нас изображена поверхность: функция от двух переменных. Например, высота над уровнем моря. Тогда градиент в какой-нибудь конкретной точке — это такой вектор, направленный в ту сторону, куда больше всего растет наша функция. А если пустить воду из этой точки, она потечет по направлению противоположному градиенту.
Самый известный метод оптимизации функций — градиентный спуск. Допустим у нас есть функция от многих переменных, мы хотим ее оптимизировать. Мы берем какое-нибудь изначальное значение, а потом смотрим, куда можно двигаться, чтобы минимизировать это значение. Метод градиентного спуска — это итеративный алгоритм: он многократно берет параметры определенной точки, смотрит на градиент и шагает против его направления:
Проблемы этого метода заключаются в том, что он, во-первых, в нашем случае работает очень медленно и, во-вторых, находит локальные, а не глобальные минимумы. Вторая проблема для нас не так страшна, т.к. в нашем случае значение функционала в локальных минимумах оказывается близким к глобальному оптимуму.
Alternating Least Squares
Однако метод градиентного спуска применять нужно не всегда. Например, если нам нужно посчитать минимум для параболы, действовать этим методом необходимости нет, мы точно знаем, где находится ее минимум. Оказывается, что функционал, который мы пытаемся оптимизировать — сумма квадратов ошибок плюс сумма квадратов всех параметров — это тоже квадратичный функционал, он очень похож на параболу. Для каждого конкретного параметра, если мы зафиксируем все остальные, это будет как раз параболой. Т.е. минимум по одной координате мы можем точно определить. На этом соображении и основан метод Alternating Least Squares. Я не буду на нем подробно останавливаться. Скажу лишь, что в нем мы попеременно точно находим минимумы то по одним координатам, то по другим:
Мы фиксируем все параметры объектов, оптимизируем точно параметры пользователей, дальше фиксируем параметры пользователей и оптимизируем параметры объектов. Действуем итеративно:
Работает все это достаточно быстро, при этом каждый шаг можно распараллелить.
Измерение качества рекомендаций
Если мы хотим улучшить качество рекомендаций, нам нужно научиться его измерять. Для этого алгоритм, обученный на одной выборке — обучающей, проверяется на другой — тестовой. Netflix предложил измерять качество рекомендаций по метрике RMSE:
Сегодня это стандартная метрика для предсказания оценки. Однако у нее есть свои недостатки:
- У каждого пользователя свое представление о шкале оценок. Пользователи, у которых разброс оценок более широкий, будут больше влиять на значение метрики, чем другие.
- Ошибка в предсказании высокой оценки имеет такой же вес, что и ошибка в предсказании низкой оценки. При этом предсказать оценку 9 вместо настоящей оценки 7 страшнее, чем предсказать 4 вместо 2 (по десятибалльной шкале).
- Можно иметь почти идеальную метрику RMSE, но иметь очень плохое качество ранжирования, и наоборот.
Метрики ранжирования
Существуют и другие метрики — метрики ранжирования, например, основанные на полноте и точности. Пусть 𝑹 — множество рекомендованных объектов, 𝑷 — множество объектов, которые на самом деле пользователю понравятся.
Тут тоже есть проблемы:
- Нет данных про рекомендованные объекты, которые пользователь не оценивал.
- Оптимизировать эти метрики напрямую почти невозможно.
Другие свойства рекомендаций
Оказывается, что на восприятие рекомендаций влияет не только качество ранжирования, но и некоторые другие характеристики. Среди них, например, разнообразие (не стоит выдавать пользователю фильмы только на одну тему или из одной серии), неожиданность (если рекомендовать очень популярные фильмы, то такие рекомендации будут слишком банальными и почти бесполезными), новизна (многим нравятся классические фильмы, но рекомендациями обычно пользуются, чтобы открыть для себя что-то новое) и многие другие.
Похожие объекты
Похожесть объектов не такая уж очевидная вещь. К этой задаче могут быть разные подходы:
- Похожие объекты — это объекты, похожие по своим признакам (content-based).
- Похожие объекты — это объекты, которые часто используют вместе («клиенты, купившие 𝑖, также покупали 𝑗»).
- Похожие объекты — это рекомендации пользователю, которому понравился данный объект.
- Похожие объекты — это просто рекомендации, в которых данный объект выступает в качестве контекста.
Направления развития
Концептуальные вопросы
- Как строить списки рекомендаций на основе предсказаний? (Обычный топ — не всегда лучшая идея.)
- Как улучшать качество именно рекомендаций, а не предсказаний?
- Как измерять похожести объектов?
- Как обосновывать рекомендации? (Оказывается, пользователи намного лучше воспринимают рекомендации, если снабжать их какими-то объяснениями.)
Технические вопросы
- Как решать проблему холодного старта для новых пользователей и новых объектов?
- Как быстро обновлять рекомендации? (От этого может сильно зависеть польза введения рекомендаций в ваш сервис.)
- Как быстро находить объекты с наибольшим предсказанием?
- Как измерять качество онлайн-рекомендаций? (Традиционный подход с обучающей и тестовой выборками может работать не очень хорошо.)
- Как масштабировать систему?
Как учитывать дополнительную информацию?
- Как учитывать не только явный (explicit), но и неявный (implicit) фидбек? (Неявного фидбека часто бывает на порядки больше.)
- Как учитывать контекст? (Context-aware recommendations)
- Как учитывать признаки объектов? (Гибридные системы)
- Как учитывать связи между объектами? (таксономию)
- Как учитывать признаки и связи пользователей?
- Как учитывать информацию из других источников и предметных областей? (Cross-domain recommendations)
Литература
- Введение в алгебру, Кострикин А. И.
- Математический анализ, Зорич В. А.
- Машинное обучение, Воронцов К. В., курс лекций