Как проверить данные во фрейме Pandas с помощью Pandera
- пятница, 1 апреля 2022 г. в 00:33:24
В науке о данных важно тестировать не только функции, но и данные, чтобы убедиться, что они работают так, как вы ожидали. Материалом о простой библиотеке Pandera для валидации фреймов данных Pandas делимся к старту флагманского курса по Data Science.
Чтобы установить Pandera, в терминале наберите:
pip install panderaНачнём с простого набора данных, чтобы понять, как работает Pandera:
import pandas as pd
fruits = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store": ["Aldi", "Walmart", "Walmart", "Aldi"],
"price": [2, 1, 3, 4],
}
)
fruits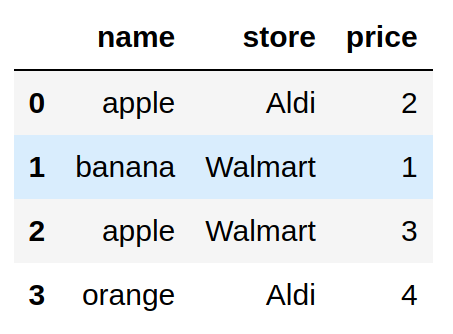
Представьте: ваш менеджер сказал вам, что в наборе данных могут храниться только определённые фрукты, а значение их цены должно быть меньше 4:
available_fruits = ["apple", "banana", "orange"]
nearby_stores = ["Aldi", "Walmart"]Проверка данных вручную может занять много времени, особенно когда их много. Есть ли способ автоматизировать проверку? Да, здесь и пригодится Pandera:
создадим тесты всего набора данных с помощью DataFrameSchema;
тесты для каждой колонки — при помощи Column;
тип теста определим при помощи Check.
import pandera as pa
from pandera import Column, Check
schema = pa.DataFrameSchema(
{
"name": Column(str, Check.isin(available_fruits)),
"store": Column(str, Check.isin(nearby_stores)),
"price": Column(int, Check.less_than(4)),
}
)
schema.validate(fruits)SchemaError: <Schema Column(name=price, type=DataType(int64))> failed element-wise validator 0:
<Check less_than: less_than(4)>
failure cases:
index failure_case
0 3 4Поясню этот код:
"name": Column(str, Check.isin(available_fruits)) проверяет, имеет ли столбец name тип string и все ли значения столбца name находятся внутри указанного списка;
"price": Column(int, Check.less_than(4)) проверяет, все ли значения в столбце price имеют тип int и меньше 4;
не все значения в столбце price меньше 4, поэтому тест не проходит.
Другие встроенные методы Checks вы найдёте здесь.
Проверки можно писать и через лямбда-выражения. В коде ниже Check(lambda price: sum(price) < 20) проверяет, меньше ли 20 сумма в price.
schema = pa.DataFrameSchema(
{
"name": Column(str, Check.isin(available_fruits)),
"store": Column(str, Check.isin(nearby_stores)),
"price": Column(
int, [Check.less_than(5), Check(lambda price: sum(price) < 20)]
),
}
)
schema.validate(fruits)Когда тесты сложные, чище код сделают не словари, а классы данных. К счастью, Pandera позволяет создавать тесты с классами данных.
from pandera.typing import Series
class Schema(pa.SchemaModel):
name: Series[str] = pa.Field(isin=available_fruits)
store: Series[str] = pa.Field(isin=nearby_stores)
price: Series[int] = pa.Field(le=5)
@pa.check("price")
def price_sum_lt_20(cls, price: Series[int]) -> Series[bool]:
return sum(price) < 20
Schema.validate(fruits)Как тестировать входные значения функции? Прямолинейный подход — добавить schema.validate(input) прямо в функцию:
fruits = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store": ["Aldi", "Walmart", "Walmart", "Aldi"],
"price": [2, 1, 3, 4],
}
)
schema = pa.DataFrameSchema(
{
"name": Column(str, Check.isin(available_fruits)),
"store": Column(str, Check.isin(nearby_stores)),
"price": Column(int, Check.less_than(5)),
}
)
def get_total_price(fruits: pd.DataFrame, schema: pa.DataFrameSchema):
validated = schema.validate(fruits)
return validated["price"].sum()
get_total_price(fruits, schema)Но он осложняет тестирование. Функция get_total_price имеет аргументы fruits and schema, а значит, в тест функции нужно включить оба:
def test_get_total_price():
fruits = pd.DataFrame({'name': ['apple', 'banana'], 'store': ['Aldi', 'Walmart'], 'price': [1, 2]})
# Need to include schema in the unit test
schema = pa.DataFrameSchema(
{
"name": Column(str, Check.isin(available_fruits)),
"store": Column(str, Check.isin(nearby_stores)),
"price": Column(int, Check.less_than(5)),
}
)
assert get_total_price(fruits, schema) == 3Функция test_get_total_price проверяет и данные, и функцию. Модульный тест должен проверять только одну вещь, поэтому включение проверки данных внутри функции — не идеальное решение.
Эту проблему Pandera решает декоратором check_input. Аргумент декоратора применяется в валидации входных значений:
from pandera import check_input
@check_input(schema)
def get_total_price(fruits: pd.DataFrame):
return fruits.price.sum()
get_total_price(fruits)Если входное значение некорректно, Pandera поднимает исключение до обработки значения в функции:
fruits = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store": ["Aldi", "Walmart", "Walmart", "Aldi"],
"price": ["2", "1", "3", "4"],
}
)
@check_input(schema)
def get_total_price(fruits: pd.DataFrame):
return fruits.price.sum()
get_total_price(fruits)SchemaError: error in check_input decorator of function 'get_total_price': expected series 'price' to have type int64, got objectТакая проверка до обработки в функции экономит много времени.
Для проверки вывода можно использовать декоратор check_output:
from pandera import check_output
fruits_nearby = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store": ["Aldi", "Walmart", "Walmart", "Aldi"],
"price": [2, 1, 3, 4],
}
)
fruits_faraway = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store": ["Whole Foods", "Whole Foods", "Schnucks", "Schnucks"],
"price": [3, 2, 4, 5],
}
)
out_schema = pa.DataFrameSchema(
{"store": Column(str, Check.isin(["Aldi", "Walmart", "Whole Foods", "Schnucks"]))}
)
@check_output(out_schema)
def combine_fruits(fruits_nearby: pd.DataFrame, fruits_faraway: pd.DataFrame):
fruits = pd.concat([fruits_nearby, fruits_faraway])
return fruits
combine_fruits(fruits_nearby, fruits_faraway)Проверить входные и выходные данные можно с помощью декоратора check_io:
from pandera import check_io
in_schema = pa.DataFrameSchema({"store": Column(str)})
out_schema = pa.DataFrameSchema(
{"store": Column(str, Check.isin(["Aldi", "Walmart", "Whole Foods", "Schnucks"]))}
)
@check_io(fruits_nearby=in_schema, fruits_faraway=in_schema, out=out_schema)
def combine_fruits(fruits_nearby: pd.DataFrame, fruits_faraway: pd.DataFrame):
fruits = pd.concat([fruits_nearby, fruits_faraway])
return fruits
combine_fruits(fruits_nearby, fruits_faraway)По умолчанию Pandera выдаёт ошибку, если в проверяемом столбце есть Null. Если нулевые значения допустимы, в класс Column добавьте nullable=True:
import numpy as np
fruits = fruits = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store": ["Aldi", "Walmart", "Walmart", np.nan],
"price": [2, 1, 3, 4],
}
)
schema = pa.DataFrameSchema(
{
"name": Column(str, Check.isin(available_fruits)),
"store": Column(str, Check.isin(nearby_stores), nullable=True),
"price": Column(int, Check.less_than(5)),
}
)
schema.validate(fruits)По умолчанию дубликаты допустимы. Чтобы они поднимали исключение, добавьте аргумент allow_duplicates=False:
schema = pa.DataFrameSchema(
{
"name": Column(str, Check.isin(available_fruits)),
"store": Column(
str, Check.isin(nearby_stores), nullable=True, allow_duplicates=False
),
"price": Column(int, Check.less_than(5)),
}
)
schema.validate(fruits)SchemaError: series 'store' contains duplicate values: {2: 'Walmart'}Аргумент coerce=True изменяет тип данных столбца, если тип не удовлетворяет условию проверки.
В коде ниже тип данных цены изменён с целого на строку:
fruits = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store": ["Aldi", "Walmart", "Walmart", "Aldi"],
"price": [2, 1, 3, 4],
}
)
schema = pa.DataFrameSchema({"price": Column(str, coerce=True)})
validated = schema.validate(fruits)
validated.dtypesname object
store object
price object
dtype: objectЧто, если мы хотим изменить все столбцы, которые начинаются со слова store?
favorite_stores = ["Aldi", "Walmart", "Whole Foods", "Schnucks"]
fruits = pd.DataFrame(
{
"name": ["apple", "banana", "apple", "orange"],
"store_nearby": ["Aldi", "Walmart", "Walmart", "Aldi"],
"store_far": ["Whole Foods", "Schnucks", "Whole Foods", "Schnucks"],
}
)Pandera позволяет нам применять одни и те же проверки к нескольким столбцам с определённым шаблоном, вот так: regex=True:
schema = pa.DataFrameSchema(
{
"name": Column(str, Check.isin(available_fruits)),
"store_+": Column(str, Check.isin(favorite_stores), regex=True),
}
)
schema.validate(fruits)YAML — отличный способ показать свои тесты коллегам, не знающим Python. Сохранить все проверки в файле YAML можно с помощью метода schema.to_yaml():
from pathlib import Path
# Get a YAML object
yaml_schema = schema.to_yaml()
# Save to a file
f = Path("schema.yml")
f.touch()
f.write_text(yaml_schema)Файл schema.yml должен выглядеть примерно так:
schema_type: dataframe
version: 0.7.0
columns:
name:
dtype: str
nullable: false
checks:
isin:
- apple
- banana
- orange
allow_duplicates: true
coerce: false
required: true
regex: false
store:
dtype: str
nullable: true
checks:
isin:
- Aldi
- Walmart
allow_duplicates: false
coerce: false
required: true
regex: false
price:
dtype: int64
nullable: false
checks:
less_than: 5
allow_duplicates: true
coerce: false
required: true
regex: false
checks: null
index: null
coerce: false
strict: falseЧтобы загрузить файл, используйте pa.io.from_yaml(yaml_schema):
with f.open() as file:
yaml_schema = file.read()
schema = pa.io.from_yaml(yaml_schema)Поздравляю! Вы только что узнали, как использовать Pandera для проверки вашего набора данных. Поскольку в науке о данных данные являются важным аспектом проекта, валидация входных и выходных ваших функций позволит сократить количество ошибок на всех этапах работы. Не стесняйтесь форкать исходный код для этой статьи.
А мы поможем вам прокачать навыки или с самого начала освоить профессию, востребованную в любое время:
Выбрать другую востребованную профессию.

Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также