Как построить систему распознавания лиц с помощью Elasticsearch и Python
- пятница, 14 мая 2021 г. в 00:41:13
Перевод материала подготовлен в рамках практического интенсива «Централизованные системы логирования Elastic stack».

Пытались ли вы когда-нибудь искать объекты на изображениях? Elasticsearch может помочь вам хранить, анализировать и искать объекты на изображениях или видео.
В этом кратком руководстве мы покажем вам, как создать систему распознавания лиц с помощью Python. Узнайте больше о том, как обнаруживать и кодировать информацию о внешности - и находить совпадения в поиске.
Вам нужно освежить информацию? Давайте вкратце рассмотрим несколько основных понятий.
Распознавание лиц - это процесс идентификации человека по его лицу, например, для реализации механизма аутентификации (как разблокировка смартфона). Он фиксирует, анализирует и сравнивает паттерны, основанные на деталях лица человека. Этот процесс можно разделить на три этапа:
Обнаружение лица: Идентификация человеческих лиц на цифровых изображениях.
Кодирование данных о лице: Преобразование черт лица в цифровое представление
Сопоставление лиц: Поиск и сравнение черт лица
Мы рассмотрим каждый этап на нашем примере.
Черты лица могут быть преобразованы в набор цифровой информации для хранения и анализа.
Elasticsearch предлагает тип данных dense_vector для хранения “плотных” векторов плавающих значений. Максимальное количество элементов в векторе не должно превышать 2048, что вполне достаточно для хранения репрезентаций черт лица.
Теперь давайте реализуем все эти концепции.
Для обнаружения лиц и кодирования информации вам понадобится следующее:
Python: В этом примере мы будем использовать Python 3, который вы можете найти здесь. Порядок установки и загрузки зависит от вашей операционной системы.
Кластер Elasticsearch: Вы можете создать кластер в бесплатной пробной версии Elastic Cloud.
Библиотека распознавания лиц: Простая библиотека Python для распознавания лиц.
Клиент Python Elasticsearch: Официальный клиент Python для Elasticsearch.
Обратите внимание, что мы протестировали следующие инструкции на Ubuntu 20.04 LTS и Ubuntu 18.04 LTS. В зависимости от вашей операционной системы могут потребоваться некоторые изменения.
Ubuntu 20 и другие версии Debian Linux поставляются с установленным Python 3. Если у вас не такой пакет, загрузите и установите Python по этой ссылке.
Чтобы убедиться, что ваша версия является самой свежей, вы можете выполнить следующую команду:
sudo apt update
sudo apt upgradeУбедитесь, что версия Python - 3.x:
python3 -VУстановите pip3 для управления библиотеками Python:
sudo apt install -y python3-pipУстановите cmake, необходимый для работы библиотеки face_recognition:
pip3 install CMakeДобавьте папку cmake bin в каталог $PATH:
export PATH=$CMake_bin_folder:$PATHВ завершение установите следующие библиотеки, прежде чем приступить к написанию сценария нашей основной программы:
pip3 install dlib
pip3 install numpy
pip3 install face_recognition
pip3 install elasticsearchИспользуя библиотеку face_recognition, мы можем обнаружить лица на изображении и преобразовать черты лица в 128-мерный вектор.
Создайте файл getVectorFromPicture.py:
touch getVectorFromPicture.pyДополните файл следующим сценарием:
import face_recognition
import numpy as np
import sys
image = face_recognition.load_image_file("$PATH_TO_IMAGE")
# detect the faces from the images
face_locations = face_recognition.face_locations(image)
# encode the 128-dimension face encoding for each face in the image
face_encodings = face_recognition.face_encodings(image, face_locations)
# Display the 128-dimension for each face detected
for face_encoding in face_encodings:
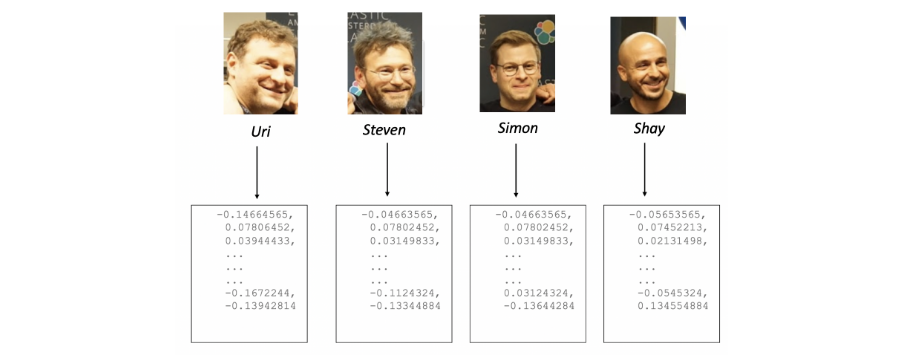
print("Face found ==> ", face_encoding.tolist())Давайте выполним getVectorFromPicture.py, чтобы получить репрезентацию черт лица для изображений основателей компании Elastic. В сценарии необходимо изменить переменную $PATH_TO_IMAGE, чтобы задать имя файла изображения.
Теперь мы можем сохранить представление черт лица в Elasticsearch.
Сначала создадим индекс с отображением, содержащим поле с типом dense_vector:
# Store the face 128-dimension in Elasticsearch
## Create the mapping
curl -XPUT "http://localhost:9200/faces" -H 'Content-Type: application/json' -d'
{
"mappings" : {
"properties" : {
"face_name" : {
"type" : "keyword"
},
"face_encoding" : {
"type" : "dense_vector",
"dims" : 128
}
}
}
}'Нам необходимо создать один документ для каждой репрезентации лица, это можно сделать с помощью Index API:
## Index the face feature representation
curl -XPOST "http://localhost:9200/faces/_doc" -H 'Content-Type: application/json' -d'
{
"face_name": "name",
"face_encoding": [
-0.14664565,
0.07806452,
0.03944433,
...
...
...
-0.03167224,
-0.13942884
]
}'Допустим, мы проиндексировали четыре документа в Elasticsearch, которые содержат отдельные изображения лиц основателей Elastic. Теперь мы можем использовать другое изображение наших основателей для сопоставления отдельных изображений.

Создайте файл recognizeFaces.py:
touch recognizeFaces.pyВ этом сценарии мы извлечем векторы для каждого лица, обнаруженного на входном изображении, и используем эти векторы при создании запроса для отправки в Elasticsearch:
Импортируйте библиотеки:
import face_recognition
import numpy as np
from elasticsearch import Elasticsearch
import sysДобавьте следующий раздел для подключения к Elasticsearch:
# Connect to Elasticsearch cluster
from elasticsearch import Elasticsearch
es = Elasticsearch(
cloud_id="cluster-1:dXMa5Fx...",
http_auth=("elastic", "<password>"),
)Мы будем использовать функцию cosineSimilarity для вычисления степени косинусного сходства между заданными векторами запросов и векторами документов, хранящихся в Elasticsearch.
i=0
for face_encoding in face_encodings:
i += 1
print("Face",i)
response = es.search(
index="faces",
body={
"size": 1,
"_source": "face_name",
"query": {
"script_score": {
"query" : {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.query_vector, 'face_encoding')",
"params": {
"query_vector":face_encoding.tolist()
}
}
}
}
}
)Предположим, что значение меньше 0,93 считается неизвестным лицом:
for hit in response['hits']['hits']:
#double score=float(hit['_score'])
if (float(hit['_score']) > 0.93):
print("==> This face match with ", hit['_source']['face_name'], ",the score is" ,hit['_score'])
else:
print("==> Unknown face")Давайте выполним наш скрипт:

Скрипт смог обнаружить все лица с совпадением результатов более 0,93.
Распознавание лиц и поиск можно объединить для расширенных сценариев использования. Вы можете использовать Elasticsearch для создания более сложных запросов, таких как geo-queries, query-dsl-bool-query и search-aggregations.
Например, следующий запрос применяет поиск cosineSimilarity к определенному местоположению в радиусе 200 км:
GET /_search
{
"query": {
"script_score": {
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "200km",
"pin.location": {
"lat": 40,
"lon": -70
}
}
}
}
},
"script": {
"source": "cosineSimilarity(params.query_vector, 'face_encoding')",
"params": {
"query_vector":[
-0.14664565,
0.07806452,
0.03944433,
...
...
...
-0.03167224,
-0.13942884
]
}
}
}
}
}Комбинирование cosineSimilarity с другими запросами Elasticsearch дает вам неограниченные возможности для реализации более сложных сценариев использования.
Распознавание лиц может быть полезно во многих случаях, и, возможно, вы уже используете его в своей повседневной жизни. Описанные выше концепции могут быть обобщены для любого обнаружения объектов на изображениях или видео, поэтому вы можете дополнить свой сценарий использования до очень широкого применения.
Elasticsearch может помочь в решении сложных задач. Попробуйте это с помощью бесплатной 14-дневной пробной версии Elastic Cloud, нашего официального управляемого предложения Elasticsearch, и сообщите о своем мнении на наших форумах для обсуждения.
Узнать больше об экспресс-курсе «Централизованные системы логирования Elastic stack».