https://habr.com/ru/company/plarium/blog/513316/- Блог компании Plarium
- Python
- SQL
В этой статье June Tao Ching рассказал, как с помощью Pandas добиться на Python такого же результата, как в SQL-запросах. Перед вами — перевод, а
оригинал вы можете найти в блоге towardsdatascience.com.
 Фото с сайта Unsplash. Автор: Hitesh Choudhary
Фото с сайта Unsplash. Автор: Hitesh Choudhary
Получение такого же результата на Python, как и при SQL-запросе
Часто при работе над одним проектом нам приходится переключаться между SQL и Python. При этом некоторые из нас знакомы с управлением данными в SQL-запросах, но не на Python, что мешает нашей эффективности и производительности. На самом деле, используя Pandas, можно добиться на Python такого же результата, как в SQL-запросах.
Начало работы
Нужно установить пакет Pandas, если его нет.
conda install pandas
Мы будем использовать знаменитый
Датасет Титаник от Kaggle.
После установки пакета и загрузки данных нам необходимо импортировать их в наше окружение Python.

Для хранения данных мы будем использовать DataFrame. Управлять этой структурой данных нам помогут различные функции Pandas.
SELECT, DISTINCT, COUNT, LIMIT
Начнем с простых SQL-запросов, которые мы часто используем.
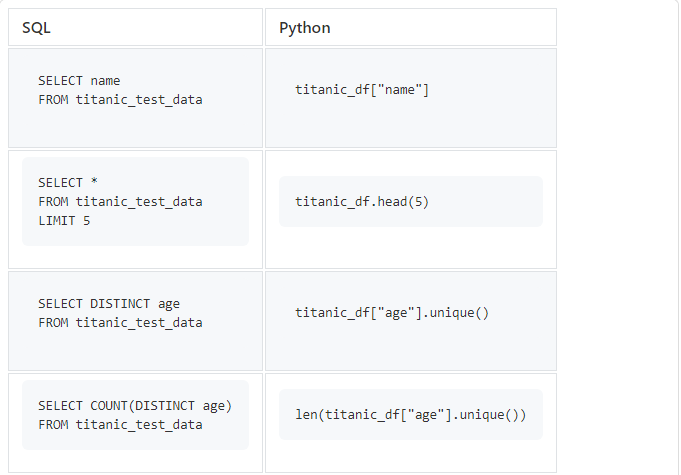
titanic_df["age"].unique() вернет массив уникальных значений, поэтому нам придется использовать
len(), чтобы посчитать их количество.
SELECT, WHERE, OR, AND, IN (SELECT с условиями)
После первой части вы узнали, как простыми способами исследовать DataFrame. Теперь попробуем сделать это с некоторыми условиями (это оператор
WHERE в SQL).

Если мы хотим выбрать только определенные столбцы из DataFrame, мы можем сделать это с помощью дополнительной пары квадратных скобок.
Примечание: если вы выбираете несколько столбцов, вам нужно поместить массив ["name","age"] внутри квадратных скобок.
isin() работает точно так же, как
IN в SQL-запросах. Чтобы использовать
NOT IN, на Python нам нужно использовать отрицание
(~).
GROUP BY, ORDER BY, COUNT
GROUP BY и
ORDER BY также являются популярными SQL-операторами при исследовании данных. А теперь давайте попробуем использовать их на Python.

Если мы хотим отсортировать только один столбец COUNT, то можем просто передать булево значение в метод
sort_values. Если мы собираемся сортировать несколько столбцов, то должны передать массив булевых значений в метод
sort_values.
Метод
sum() выдаст суммы для каждого из столбцов в DataFrame, которые могут быть численно агрегированы. Если нам нужен только определенный столбец, то нужно указать имя столбца, используя квадратные скобки.
MIN, MAX, MEAN, MEDIAN
И наконец, давайте попробуем некоторые стандартные статистические функции, которые важны при исследовании данных.
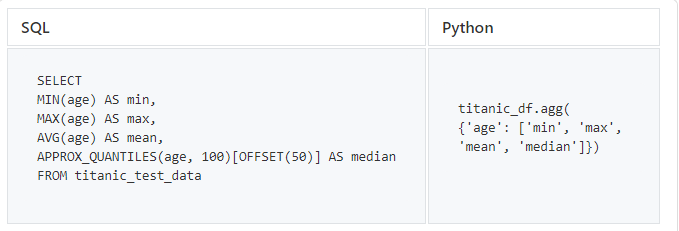
SQL не содержит операторов, возвращающих медианное значение, поэтому для получения медианного значения столбца с информацией о возрасте мы используем BigQuery
APPROX_QUANTILES
В Pandas метод агрегации
.agg() также поддерживает другие функции, например
sum.
Теперь вы научились
переписывать SQL-запросы на Python с помощью Pandas. Надеюсь, эта статья будет вам полезна.
Весь код можно найти в моем репозитории
Github.
Спасибо за внимание!