https://habr.com/ru/company/agima/blog/492204/- Блог компании Агентство AGIMA
- Python
- Google API
- Яндекс API
- Google Cloud Platform

За красивыми и понятными дашбордами Power BI часто скрываются недели подготовки и сведения данных. Особенно когда речь идет о построении полезной BI-отчетности в крупной организации с объемом трафика в десятки миллионов посетителей ежемесячно.
В данной статье я хочу описать ряд негативных моментов, с которыми столкнулся при построении BI-отчетности, основанной на данных из систем веб-аналитики в ряде компаний (крупные представители российского e-commerce, страховые компании и т.д.). Статья не имеет цель сделать антирекламу или наоборот рекламу тех или иных инструментов или решений. Она подготовлена для того, чтобы по возможности помочь избежать негативных моментов другим пользователям и указать на варианты решений.
Дисклеймер
Я говорю о больших объемах данных и показываю примеры выгрузки и сэмплинга из Google Analytics 360. На проектах с небольшим объемом данных таких сложностей может не быть. Со всеми обозначенными проблемами я встретился на практике и в статье описываю исключительно свой опыт решения — ваши могут быть совершенно другими.
Коннектор к Яндекс.Метрике
В Яндекс.Метрики более мягкие условия сэмплирования и интуитивно понятный интерфейс, по сравнению с Google Analytics. Поэтому многие маркетологи предпочитают Яндекс.Метрику и строят BI-отчетность на выгрузке данных оттуда. Для этого используют
коннектор Максима Уварова. Такой метод небезопасен и не позволяет обрабатывать сложные запросы.
Большим компаниям нужна гарантия, что конфиденциальная информация не попадет в руки недоброжелателей, а финансовые показатели будут использованы только для стейкхолдеров и исключительно внутри компании.
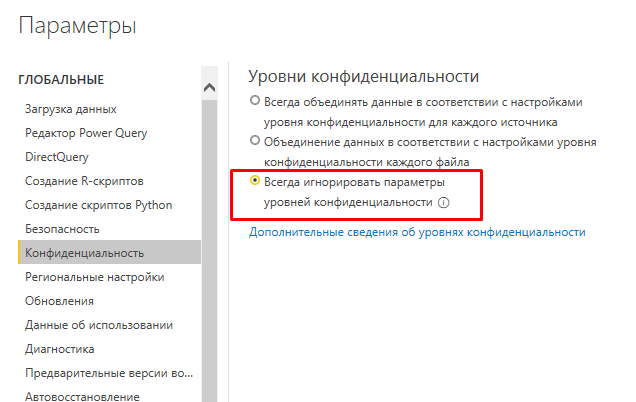
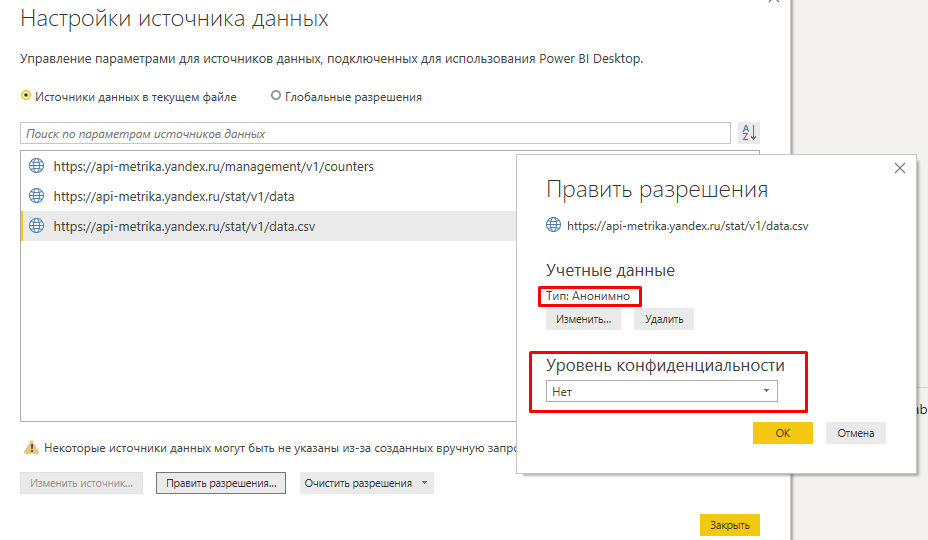
Первый большой минус — чтобы воспользоваться коннектором, в Power BI нужно включить настройку «Игнорирование уровней конфиденциальности», иначе он просто не будет работать.
Таким образом конфиденциальные данные могут попасть в руки любому неавторизованному пользователю. Это подтверждается выдержкой из справки Power BI.

Подключение к данным происходит анонимно. При этом нет никакой авторизации или проверки на разрешение использовать эти данные тем пользователям, которым это действительно разрешено.
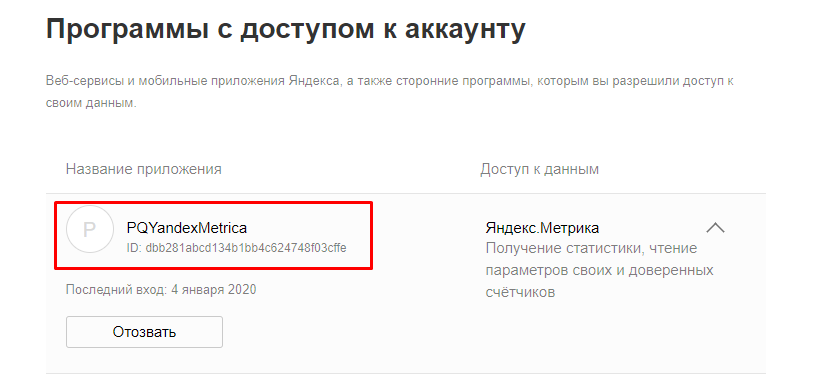
Для работы таких коннекторов необходимо получить oauth-токен доступа. В описании к коннектору приводится ссылка, как дать приложению доступ к своему аккаунту.

Фактически стороннее приложение получит доступ к вашему аккаунту. Гарантию за сохранность ваших данных никто не несет.
Второй минус — на крупных проектах API Яндекс.Метрики не может обработать большие объемы данных и как следствие коннектор также отказывается работать со сложными запросами к сырым данным Яндекс.Метрики, — он их не выгружает.
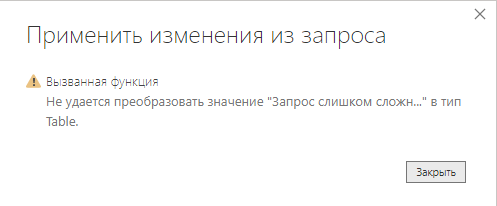
К примеру, нужно выгрузить данные за год, без каких-либо сложных фильтров. Коннектор выдает ошибку: «Запрос слишком сложный. Пожалуйста, уменьшите интервал дат или семплирование».

Конечно, это трансляция ошибки самого API Яндекс.Метрики. Однако, в данном случае у нас нет выбора сделать загрузку данных с разбиением по месяцу или дню — чтобы к примеру, циклично выкачать данные за каждый месяц и соединить их в единый датасет преодолев ошибку API.
Если значительно уменьшить период, то API позволяет выкачать данные, но это лишь малая часть того, что нам необходимо.
Для построения больших отчетов делать выгрузку за короткие периоды непрактично и неудобно. На практике, часто нужны выгрузки по сложным открытым воронкам сайта с огромным числом визитов в день. Особенно при использовании сложных сегментов визитов, практически нельзя выгрузить необходимые данные.
Даже если вам удалось загрузить данные, то не факт, что получится сделать выгрузку в модель данных, чтобы построить саму отчетность, потому что то и дело выскакивают различные ошибки загрузки. Почему-то даже с нормально загруженной таблицей возникают ошибки.
Чтобы все стейкхолдеры внутри компании смогли использовать отчет построенный на коннекторе API Яндекс.Метрики, нужно опубликовать отчет в PowerBI Service. В этом случае также придется игнорировать уровни конфиденциальности.
Когда визуализация настроена и отчет в облаке Microsoft опубликован, коннектор выдет ошибку комбинированных запросов и не обновляется через Power BI Service — вы не сможете настроить запланированное обновление вашего отчета. Ошибка происходит когда один из запросов, который формирует финальную таблицу выгрузки, содержит логику одновременной работы с внешним и внутренним запросом.
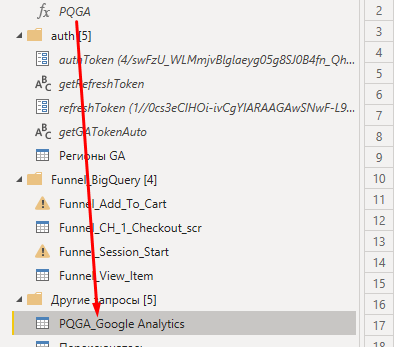
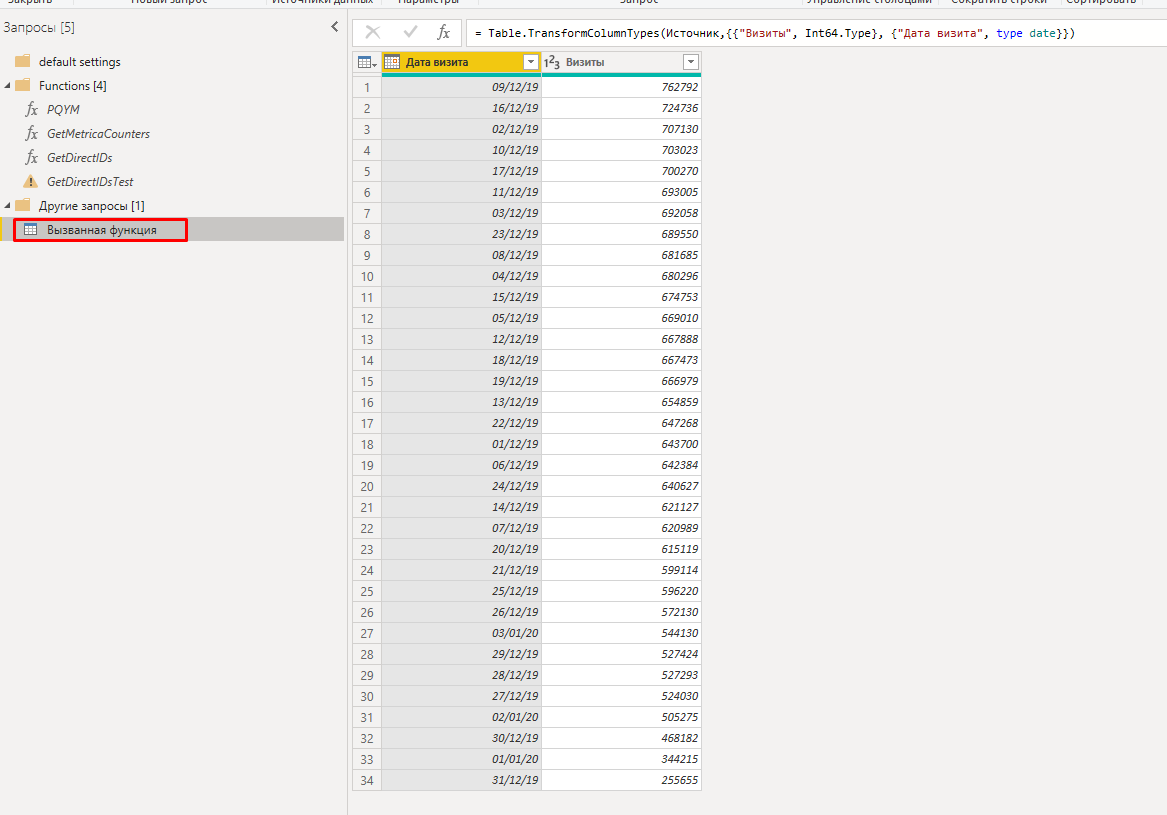
В ошибке как раз указана таблица «Вызванная функция»:
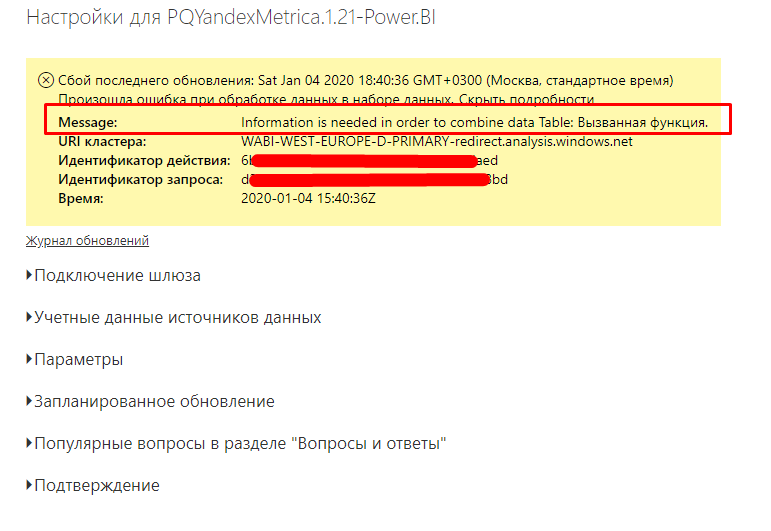
Такая таблица получается из-за функции PQYM, которая работает с внешним источником данных — API Яндекс.Метрики. Механизм обновления отчетности в Power BI не работает и просит переделать комбинацию запросов. Это происходит из-за внутренних ссылок одного запроса на соединение с внешним запросом, а также из-за структуры работы самой функции.
Мы решили не использовать такой коннектор при построении отчетности и перешли на выгрузку данных из API Яндекс.Метрики через скрипты Python, — об этом дальше в статье.
Коннектор к Google Analytics
Для построения отчетности на данных Google Analytics (речь идет о прямой выгрузке из системы аналитики) также есть
коннектор Максима Уварова.
Здесь тоже придется выставить «Игнорирование уровней конфиденциальности». Доступ к API вашей системы аналитики, который содержит данные по онлайн-продажам, происходит на анонимном подключении.
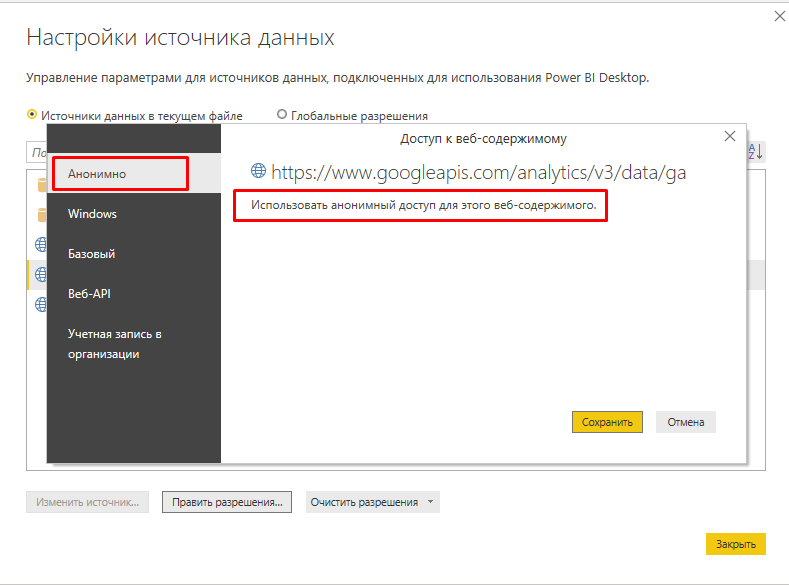
Согласно инструкции, снова придется открыть доступ на стороннее приложение, только уже для аккаунта Google, что содержит в себе угрозу конфиденциальности вашим данным.

Можно переписать некоторые данные в самом коннекторе и начать его использовать для собственного приложения. Для этого нужно зарегистрировать «Идентификатор клиента OAuth 2.0» на
cloud.google.com, получить токены доступа и внести необходимые ключи доступа в его механизм работы. Но даже эти действия не помогут в борьбе с сэмплингом и обновлением вашей отчетности.
При любом прикосновении к агрегированным данным API Google Analytics мы всегда будем сталкиваться с сэмплингом.
У коннектора есть опция выгрузки по одному дню, но даже она не всегда спасает. Встроенный в коннектор индикатор сэмплинга показывает, что он есть даже за один день.

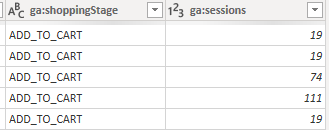
Например, данные по сессиям в разбивке Shopping Stage невозможно выгрузить без сэмплинга на таких объемах данных. Это приведет к большим погрешностям в данных и мерах при построении отчетов, особенно когда нужно точно рассчитать конверсию перехода от одного шага к другому, или выгрузить данные по воронкам со сложной структурой сегментов.
Даже если потеря данных для вас не критична, вы все также не сможете настроить запланированное обновление ваших отчетов через Power BI Service.
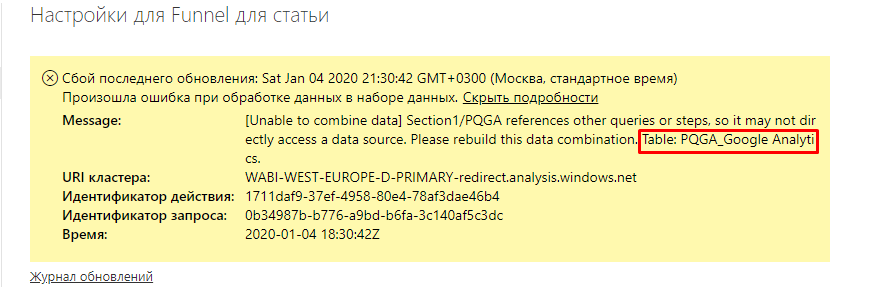
Мешает все та же ошибка механизма работы, только уже функции PQGA.
От работы с этим коннектором мы также отказались.
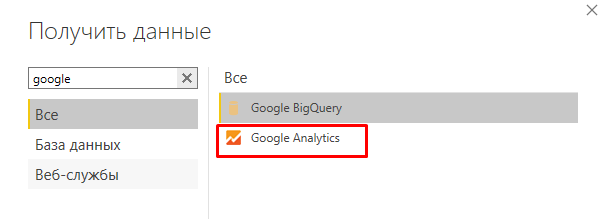
«Родной» коннектор к Google Analytics
Иногда Google и Microsoft идут друг другу на уступки: Power BI “из коробки” имеет стандартный коннектор к Google Analytics. К сожалению, для Яндекс.Метрики такой опции нет.
Механизм работы с API Google Analytics тут реализован удобнее, чем в коннекторе Максима Уварова, но при одновременной выгрузке большого количества показателей данные чересчур сэмплированы. Повторяющиеся цифры на скриншоте — и есть сэмплированные данные.
Избежать сэмплинга можно, если выгружать мини-таблицы в разбивке только даты и какого-либо одного показателя. Например, дата, количество сессий и тип устройств. И после из таких таблиц собирать необходимую отчетность.
Если у вас не миллионный трафик, возможно, это поможет. Однако отчетность будет не информативная и с ограничениями на масштабируемость: из-за множества мини-таблиц в модели данных сложно создавать связи между ними. Это накладывает ограничение на создание фильтров и срезов.
Можно переписать стандартный коннектор и заставить его выгружать данные за каждый день, при этом данные будут близки к реальным цифрам в интерфейсе GA, но избежать сэмплинга не удастся.
По моим наблюдениям, в разбивке сессий по Shopping Stage еще ни один коннектор не смог нормально выгрузить данные без сэмплинга на больших объемах данных.
В стандартном коннекторе нельзя кастомно регулировать даты загрузки. Все, что есть — это просто выбор параметров и показателей из API Google Analytics, разложенных по папкам.
Данный коннектор подойдет для малых и средних интернет-проектов с небольшим трафиком. Здесь складывается аналогичная ситуация с получением данных из Яндекс.Метрики. Всю необходимую информацию без потери точности можно выгрузить только напрямую через API с помощью скриптов или специальных сервисов стриминга данных — об этом дальше в статье.
«Палки в колеса» от Google
С недавнего времени мы заметили странную блокировку — при попытке настроить обновление для «родного» коннектора к Google Analytics стала появляться ошибка авторизации через аккаунт Google в интерфейсе Power BI Service.
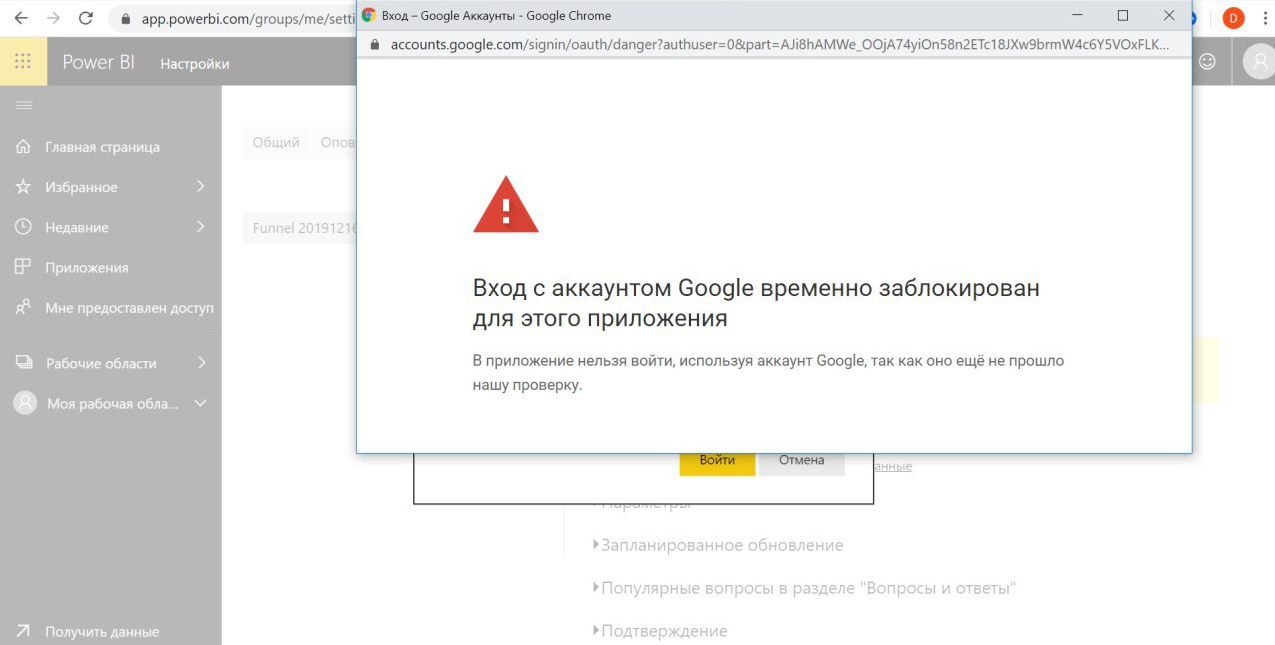
Мы пытались узнать у Google, что делать в такой ситуации и как “обелить” репутацию аккаунта, но наши попытки ни к чему не привели. Пробовали зарегистрировать новые аккаунты и авторизоваться через разные устройства — Google блокировал любые попытки авторизаций.
Примерно через месяц после блокировки нам все же удалось авторизоваться через тот же аккаунт, но такой инцидент может сильно помешать выпустить необходимую BI-отчетность в установленный срок и поставить в неловкое положение перед заказчиком. Сразу после блокировки мы начали искать возможный выход из ситуации. Чтобы избежать непредвиденных блокировок, мы решили создать собственную контролируемую среду с необходимыми данным для BI-отчетности.
Варианты решения
Получить необходимую BI-отчетность для средних и крупных организаций, и даже без сэмплинга можно. Но нужно немного постараться и выбрать один из нескольких путей.
Можно использовать готовые сервисы для стриминга данных. Их основное предназначение — выгрузка данных из системы аналитики, различных рекламных систем, CRM и других сервисов в какое-либо хранилище. Удобно, быстро и практично, но не бесплатно. На больших объемах данных или данных со множеством источников суммы ощутимые.
Наиболее известные сервисы:
Каждая из этих систем позволяет настроить ежедневный стриминг несэмплированных данных из систем веб-аналитики (Яндекс.Метрики и Google Analytics) в базы данных (например, BigQuery, Azure SQL Database, Microsoft SQL Server или ClickHouse) для подключения через Power BI и создания отчетов.
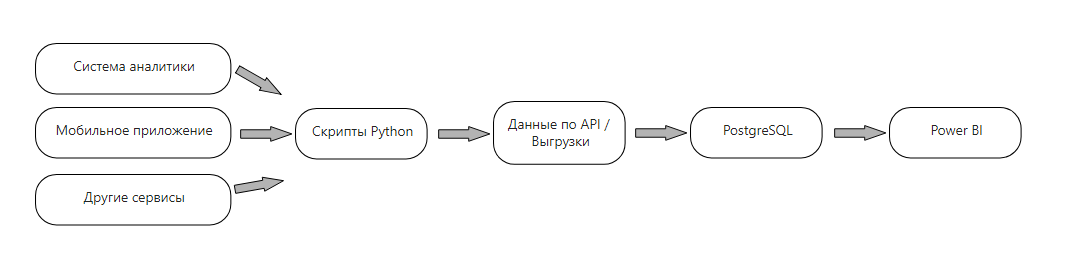
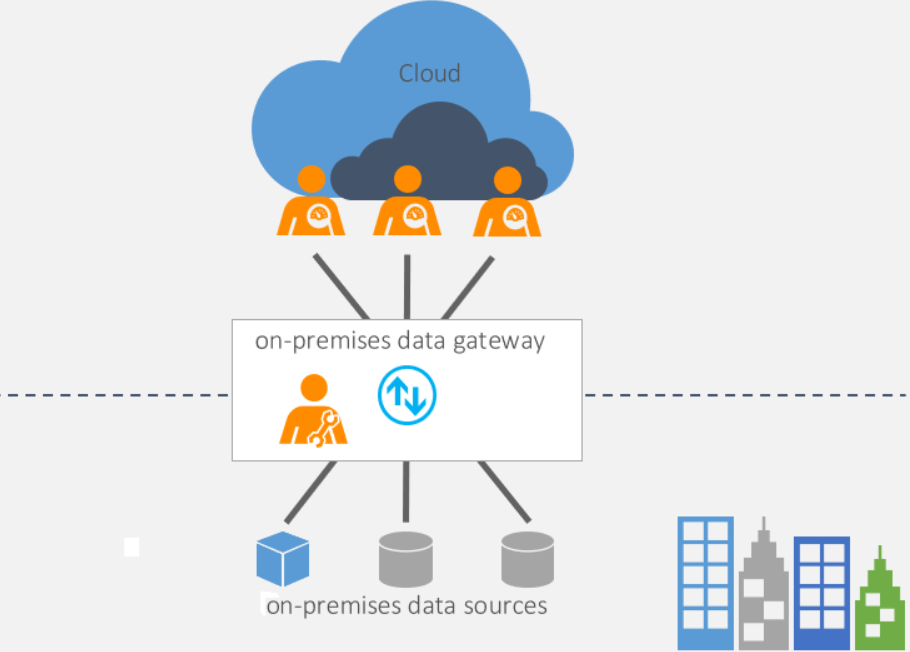
Если перечисленные инструменты обходятся компании слишком дорого, можно попробовать реализовать свою систему выгрузки данных и использовать Power BI + Python + Любой Cloud Server (или Яндекс.Облако) + PostgreSQL. Именно такой способ мы используем при построении BI-отчетности.
Схема взаимодействия систем:
Такая схема работы обеспечивает необходимую сохранность, автономность и агрегацию данных. Наладив такую схему один раз, вам не нужно будет тратить время на сбор информации, — все есть в хранилище, остается только подключиться и начать делать отчет на Power BI.
Скрипты Python «вытягивают» все данные по API из необходимых источников, записывают в базу данных или формируют выгрузки (к примеру, в формате csv). Скрипты для выгрузки из API и загрузки в базу данных заслуживают отдельной статьи, и когда-нибудь я ее напишу.
Конечно, в интернете много шаблонов и готовых решений, но для дальнейшего масштабирования необходимо знать индивидуальные потребности той системы, под которую создаются скрипты на выгрузку.
Данные записываются в заранее созданную и настроенную базу данных — в нашем случае PostgreSQL. Скрипты выкачивают данные за каждый день и записывают их в таблицы по расписанию. Они находятся на облачном сервере под нашим управлением или под управлением службы IT-безопасности клиента.
Существует большое количество компаний реализующих услугу предоставления облачных хранилищ данных. Исходя из личных предпочтений было выбрано
Яндекс.Облако.
Преимущества Яндекс.Облака:
- Удобная конфигурация и аренда сервера с предустановленной PostgreSQL.
- Обширная документацией на русском языке, которая понятно изложена и позволяет быстро научиться пользоваться сервисом.
- Удобное управление серверами.
- Быстрая поддержка специалистов.
- Гибкость различных настроек оборудования и тарифов: никто не навязывает какие-либо готовые пакеты настроек, вы сами выбираете конфигурацию своего оборудования, плюс можете сразу заказать предустановку любой базы данных.
Полученные выгрузки записываются в базу данных PostgreSQL. Была выбрана именно эта база данных, потому что это объектно-реляционная СУБД (работа с многомерными массивами и поддержка JSON из «коробки» — для сложных структур данных must have). Она гибкая, надежная, бесплатная, а еще у нее огромное комьюнити поддержки.
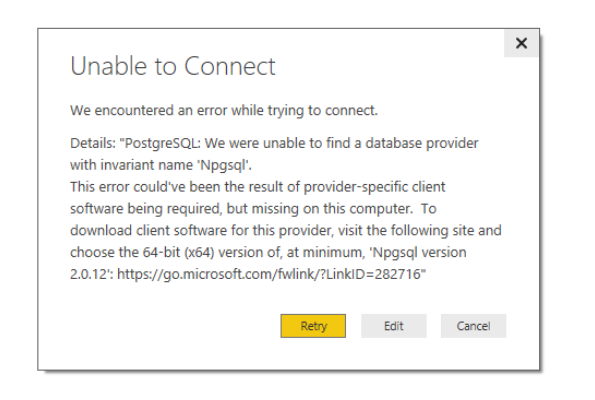
Power BI имеет встроенный прямой коннектор в PostgreSQL. При первом подключении нужно установить дополнительно
Npgsql. Power BI уведомляет об этом и дает ссылку.
Для настройки обновления отчетов при использовании облачных хранилищ, необходимо настроить шлюз
Power BI Gateway. Он нужен для настройки обновления BI-отчетности и обеспечения безопасности конфиденциальных данных при передаче их из базы данных, которая должна находиться во внутреннем IT-контуре вашей организации, либо на защищенном облачном сервере.
Шлюз обеспечивает быструю и безопасную пересылку данных между хранилищами данных, которые находятся во внутренней сети организации и облачными службами Microsoft. Передача данных между Power BI и шлюзом защищена, а все учетные данные, предоставляемые администраторами шлюза, шифруются для защиты информации в облаке и расшифровываются только на компьютере шлюза.
После скачивания
Power BI Gateway и его запуска появляется диалоговое окно.
Для регистрации и работы шлюза необходимы учетные данные облачного сервиса Power BI Service.
После всех настроек появится окно о работающем шлюзе. Далее нужно провести
дополнительные настройки.
Более простая альтернатива настройки PostgreSQL — Google BigQuery. У Power BI есть встроенный коннектор в Google BigQuery. В таком случае необходимо следовать принципу «Семь раз посчитать стоимость, один раз выполнить запрос».
BigQuery можно пользоваться год бесплатно, просто привязав банковскую карту при соглашении использования сервисом. Деньги после истечения срока без вашего ведома не спишутся. Дальнейшая тарификация — по тарифам самой системы, но с несколькими приятными «плюшками».
Если загружаемые данные из ваших систем не достигают 10 ГБ за месяц (!), за загрузку плата взиматься не будет.
Если обработка данных в месяц не превышает 1 ТБ, за это тоже не будет взиматься плата. Если больше, то $5 за каждую обработку 1 ТБ.
Если нужно хранить более 10 ГБ в месяц, каждый последующий гигабайт обойдется $0.010.
Более подробно тарифы описаны на
странице BigQuery.
Итоги
Если вам нужны данные из различных систем аналитики, и при этом вам принципиальна безопасность, сохранность, постоянная агрегация, удобство использования и отсутствие сэмплинга, у вас есть два пути.
Первый — стриминговые сервисы. Ими легко пользоваться, у них постоянная техническая поддержка и готовая интеграция с хранилищами данных.
Недостатки:
- Ощутимые затраты на больших объемах данных.
- Ограниченность по типам предоставляемых интеграций.
- Неконтролируемые процессы на стороне поставщика стриминговых услуг по работе с вашей информацией.
Второй — собственный поток выгрузки и агрегации данных. Масштабируемый, контролируемый, с обеспечением безопасности данных. Он может показаться сложным и долгим для реализации. Если компании нужны эффективная организация BI-отчетности, ее дальнейшая масштабируемость и защищенность данных, то этот вариант является наиболее приемлемым.
Всем тем, кто только задумывается о полноценной BI-отчетности, необходимо в корпоративную культуру добавить девиз «Накапливай, структурируй и береги данные смолоду». Нет ничего лучше полноценной отказоустойчивой базы данных с регулярным бэкапом и с разграниченными правами на её использования для разных категорий стейкхолдеров.
Необходимо накапливать, структурировать и агрегировать свои данные и из систем аналитики, и из мобильного приложения, и из других клиентских сервисов. Все это в дальнейшем поможет анализировать и свою аудиторию, и продукты в любых разрезах. Информация и данные сейчас правят миром и порой стоят дороже денег.
О том, как реализовать описанный в статье подход передачи данных систем аналитики в PostgreSQL базу, используя скрипты Python и деталями реализации, я расскажу в следующих статьях.