https://habr.com/ru/post/466599/На просторах интернета до сих пор остаются актуальными капчи, которые в качестве опции предлагают прослушать текст с картинки, нажав на соответствующую кнопку. Если кому-то знакома картинка ниже и/или есть интерес как ее обойти, используя систему оффлайн распознавания звука, предлагается к прочтению.
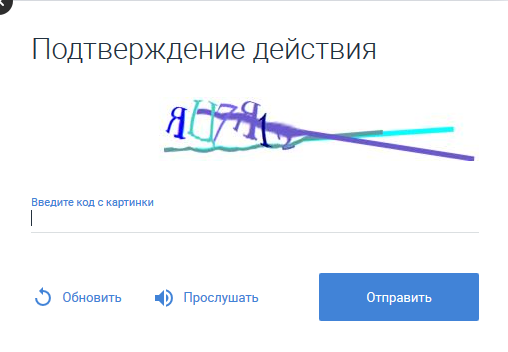
Не будем томить интригами специалистов в области speech recognition, сразу заявив, что никакая собственная система распознавания голоса под заявленные цели не разрабатывалась. В статье используется старый добрый Pocketsphinx, но с определенной степенью настройки.
Подготовка.
«Забегаешь в офис к конкурентам, у которых голосовое управление на компах, кричишь «Судо эрэм минус эрэф хоум» и убегаешь.» Из комментов.
Итак, капча предлагает себя прослушать, нажав на соответствующую кнопку. Если сохранить полученный звуковой файл, то можно выяснить, что он представляет из себя короткий отрезок аудио в .mp3. При этом, как выяснилось, капчи предлагаются с озвучкой женским голосом или мужским. «Рисунок» одних и тех же звуков, произнесенных мужчиной и женщиной разный:
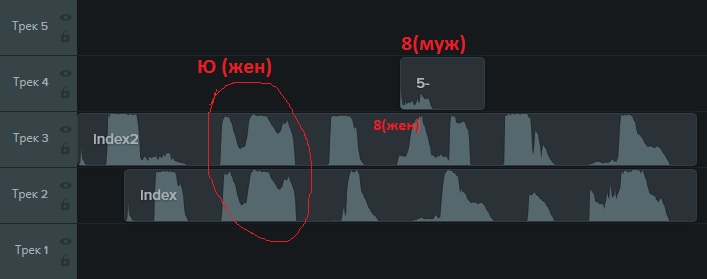
Озвучивают они как буквы (причем русские), так и цифры.
На первый взгляд все грустно. Но есть и позитивный момент в том, что звуки для одинаковых букв совпадает.
Пока эти знания не сильно помогают. Как это все затолкать в пакет Сфинкса?
Установка Pocketsphinx, русской звуковой модели.
*На хабре есть
статья, где звук скармливают онлайн google переводчику через перенаправление вывода звука. И на этом можно было закончить данный пост, если бы все это работало для данного случая.
Установка самого Pocketsphinx на windows (да и на linux) не сильно замысловата —
скачать, установить.
Так как по умолчанию pocketsphinx идет с английской языковой, акустической моделями, словарем, понадобится все то же самое для русского языка.
Скачаем русский вариант —
ссылка.
После распаковки русской модели в структуре файлов можно попробовать тестовый .wav файл decoder-text.wav cо следующим кодом на python:
import os
from pocketsphinx import AudioFile, get_model_path, get_data_path
#from pocketsphinx import Pocketsphinx
model_path = get_model_path()
data_path = get_data_path()
config = {
'verbose': False,
'audio_file': os.path.join(data_path, 'C://python3//decoder-test.wav'),
'buffer_size': 2048,
'no_search': False,
'full_utt': False,
'hmm': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//zero_ru.cd_cont_4000'),
'lm': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.lm'),
'dict': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.dic')
}
audio = AudioFile(**config)
for phrase in audio:
print(phrase)
Должно вывести в строку содержание аудиофайла: «илья ильф евгений петров золотой телёнок».
Если не вывело (как и в моей ситуации), то необходимо сконвертировать decoder-test.wav в другой аудиоформат.
Для этого понадобится ffmpeg.
Ffmpeg
.
После скачивания утилиты ffmpeg, положим decoder-test.wav в C:\python3\ffmpeg\bin.
Далее в командной строке конвертируем:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
Далее исправим в коде python ссылку на исходный аудиофайл:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
Теперь, после отработки кода:

Правда надо ждать как до второго пришествия, код очень медленно работает — около 20 сек.
Сконвертируем аудио капчи по тому же принципу из mp3 в wav и скормим аудио от капчи. Взглянем на работу кода:

Невесть какой, но результат есть. Было гораздо хуже, если если бы ничего не вывело. Как с женским голосом:

Посмотрим как улучшить результат и одновременно его ускорить.
Словарь
.
Понадобится собственный словарь. В данном случае он будет состоять из всех букв русского алфавита (кроме ь, ы, ъ) и цифр.
Все символы надо поместить в обычный текстовый файл по одному в каждой строке в кодировке UTF-8.
Теперь надо сконвертировать словарь.
Понадобится установка perl (он нужен для работы конвертатора).
Далее скачаем проект для конвертации
ru4sphinx.
И конвертируем ранее созданный словарь:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
На выходе получаем словарь для работы:

Расширение словаря надо переименовать из .txt в формат .dic, а сам файл положить в доступное место.
В коде python укажем расположение словаря, закомментировав старый словарь:
#'dict': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.dic')
'dict': os.path.join(model_path, 'C://python3//my_dict.dic')
Прогоним через программу и посмотрим результат:

Лучше, но так же медленно и не все буквы правильно определились.
Создадим собственную модель
.
Это позволит в разы увеличить скорость работы и немного точность результата.
Пойдем коротким путем из
инструкции.
Зайдем по
ссылке и загрузим на сайт наш словарь, ранее созданный в формате .txt (не .dic!):
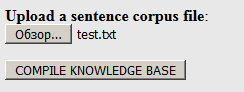
Нажмем «Compile...». На выходе можно скачать полученный пакет в архиве .tgz (он содержит все необходимые файлы):
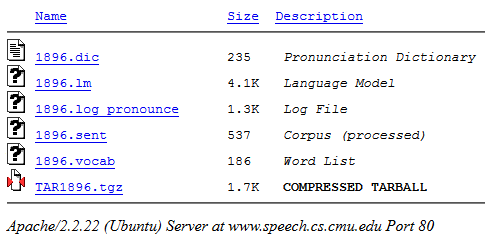
Далее из архива возьмем файл с расширением .lm(наша модель).
Поправим python скрипт распознавания, заменив модель на вновь изготовленную:
#'lm': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.lm'),
'lm': os.path.join(model_path, 'C://python3//my_model//1896.lm'),
Пробуем:

Работает заметно быстрее — менее секунды, кроме того, все буквы определены.
Но тут необходима небольшая ремарка.
Не все символы распознаются корректно, и если вместо правильной букву выдает другой символ, то можно вручную поправить ранее созданный словарь .dic, сопоставив соответствие буквы.
Например, вместо буквы а, выводит э. Необходимо взять строку из словаря э:
э r y
и
перенести(удалив старую) ее, поменяв букву:
а r y
Но так как буква «а» уже есть в словаре, то к букве надо добавить "(2)" (или 3,4), вообщем, порядковый номер, в зависимости сколько звуков уже есть в словаре:
a(2) r y
Заново конвертировать словарь не нужно. Таким нехитрым способом можно «подобрать» фонемы всех букв, почти.
Cherchez la femme.
Модель и словарь работают, но не с женским голосом. Если озвучка капчи женская, то на выходе не получаем ничего. Это и хорошо и плохо одновременно. Сначала о хорошем.
Если при запуске программы ничего не распознало — значит мы имеем дело с женским голосом, так можно фильтровать «женские» капчи.
Но что с ними делать?
Здесь надо поработать с конвертацией.
Например, с «мужской» капчей частота была 16000, а для женской «подойдет» 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

Все звуки определились (в каждой строке по звуку), но их соответствие хромает.
Лучше создать отдельный словарь под женскую модель и далее ее править.
Однако, это для самостоятельного изучения.
Полезные ссылки:
1.
home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom
2.https://itnan.ru/post.php?c=1&p=351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femme
Файлы:
1.
Программа.
2.
Модель.
3.
Русская модель.
4.
Словарь.
5.
Тестовые капчи.
6.
ffmpeg.
7.
Пачка капч.