https://habrahabr.ru/post/331754/- Ненормальное программирование
- Визуализация данных
- Python

Однажды, посреди рабочего дня мы внезапно осознали, что мы больше не можем так жить. Душа требовала совершить что-то бессмысленное и беспощадное во имя науки. И мы решили откалибровать кофе-машину. Нормальные люди тыкают в дефолтную кнопку и пьют все, что вытечет из кофеварки. Чуть более продвинутые для этого открывают инструкцию и тщательно ей следуют. Может быть еще читают рекомендации обжарщика, если конечно это не прогорклые noname зерна, которые пару лет лежали на безымянном складе. Нас к нормальным можно отнести с большой натяжкой, поэтому мы решили идти своим путем. Короче говоря, под легкой кофеиновой интоксикацией от седьмой чашки эспрессо мы решили задействовать весь возможный арсенал лаборатории, чтобы получить эталонный напиток.
Добро пожаловать в мир безумия, ультрацентрифуг, спектрофотометрии кофе в специальных планшетах и небольшого количества python, pandas и seaborn, чтобы визуализировать все это безобразие.
Правильная экстракция
Для начала, надо понять, что мы хотим получить. Основной смысл правильной настройки кофеварки в том, чтобы получить сбалансированный профиль экстракции. При этом не меньше половины успеха зависит от правильного зерна, которое было обжарено с соблюдением всех деталей термопрофиля. У хреновых обжарщиков зерна могут быть неравномерной обжарки или с другими дефектами. Но даже идеальный кофе можно превратить в жуткое пойло, если неправильно его приготовить.
Оптимальная температура для классического способа приготовления кофе — 90-95°С. При этом количество зерен должно быть примерно 10-20 г/ 100 мл воды. Также надо учитывать, что процесс экстракции идет неравномерно, от более легких и летучих к менее растворимым компонентам. Вся беда заключается в том, что при выходе за оптимальные значения температуры воды, степени компрессии кофейной таблетки (для эспрессо), степени помола, соотношения кофе к воде или времени мы можем не успеть «вытащить» из зерна все, что нам нужно. Или наоборот захватить чрезмерное количество тяжелых фракций, испортив вкус и баланс напитка. В частности, при гипер-экстракции в чашку попадает избыточное количество хлорогеновых кислот, которые заставляют кофе чрезмерно горчить и сдвигают баланс вкуса в кислую сторону. При недостаточной экстракции будет что-то водянистое и печальное на вкус.
 Хининовая и гидроксикоричные кислоты, структурная основа хлорогеновых кислот
Хининовая и гидроксикоричные кислоты, структурная основа хлорогеновых кислотПодготовка эксперимента
В автоматической кофе-машине нам доступны для регулировки только два параметра: помол и компрессия. Степень помола определяется механическим вращением регулятора, который устанавливает зазор между жерновами. Компрессия свежесмолотой кофейной таблетки предустановлена и имеет 5 условных уровней сжатия. Наша задача состоит в подборе оптимальных параметров, при которых концентрация и баланс растворенных веществ будут давать идеальный вкус.
Сам кофе для тестирования нам прислали для бесчеловечных экспериментов из Торрефакто, за что им огромное спасибо. Две основные категории: B и C (темная и светлая обжарка в их классификации).
 Гондурас Сан-Маркос (источник)
Гондурас Сан-Маркос (источник)
Темная обжарка. Мы как-то уже перешли на среднюю, но для сравнения этот сорт очень достойный вариант. Особенно хорош с молоком, но для наших задач мы будем готовить из него эспрессо. Вкус довольно простой, без тонких нюансов, но очень насыщенный.
 Бразилия Ипанема Дульче (источник)
Бразилия Ипанема Дульче (источник)
Просто офигительный ароматный сорт, с очень сбалансированным вкусом и сладкой фруктовой кислинкой. Само зерно содержит большое количество углеводов, что и придает легкую сладость.
Для каждого сорта и каждого из пяти уровней сжатия кофейной таблетки выбирается по 8 чашек образцов. Заодно сотрудники лаборатории плюются или радуются полученному результату. Вслепую, естественно. Выбирают оптимальные по вкусу образцы, чтобы потом сравнить с объективными показателями аппаратного исследования.
Глубокая заморозка
Нам себя стало жалко и мы не стали пить 80 чашек кофе за один день. Поэтому образцы маркировались и забрасывались в морозилку. Милая такая морозильная камера, с температурой около -90 градусов. Жрет 4 киловатта, но в итоге внутри даже углекислый газ выпадает в виде снежка на стенках. Идеальный вариант.

Когда все образцы готовы, достаем их из морозильной камеры и кладем в орбитальный шейкер. Да, мне тоже нравится, как это звучит. Почти как орбитальный планетарный лазер, но это просто шейкер. Ждем полной разморозки образцов и заодно все хорошо перемешиваем.
Разливаем по пробиркам и центрифугируем

Для начала надо очень глубокомысленно осмотреть образцы. Без этого чуда не произойдет)


Из больших пробирок забираем микропипеткой кофе и разливаем по маленьким пробиркам для центрифугирования. Каждую пробирку маркируем номером и вносим в отдельный журнал, чтобы потом не перепутать образцы.


Пробирки расставляем в центрифуге строго симметрично для соблюдения баланса. На больших скоростях вращения это критично. После центрифугирования мы получим чистый водный раствор того, что экстрагировалось из кофе, а все микрочастицы, прошедшие через фильтр кофемашины останутся в виде осадка.
Спектрофотометрия

Снова берем микропипетку и разливаем точные дозы образцов по отдельным лункам специального 48-луночного планшета.
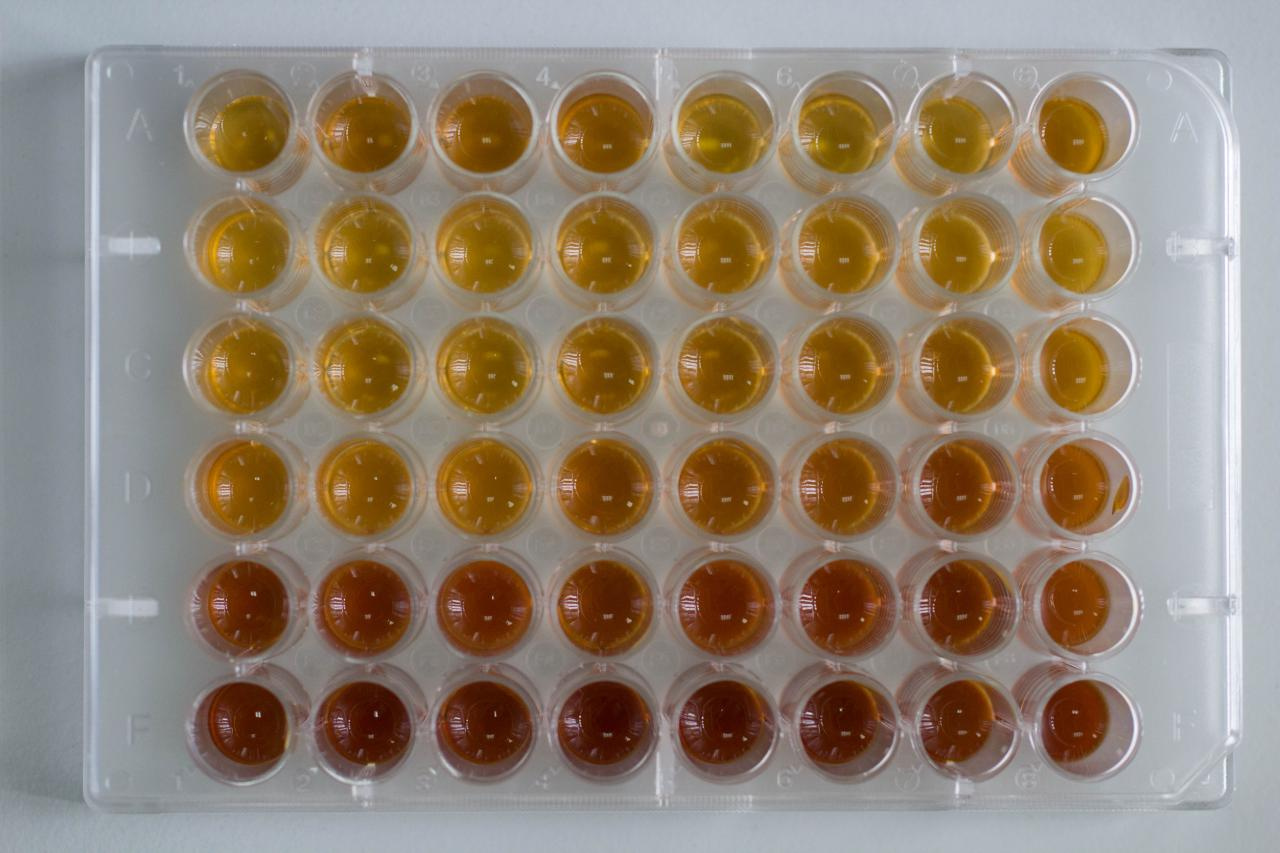
В результате образцы красиво распределяются по оттенкам. Сверху вниз идет увеличение степени сжатия и полноты экстракции.

Планшеты загружаются в спектрофотометр FilterMax от Molecular Devices. Там целая куча режимов исследования образца, различные варианты фильтров, лазерных источников излучения и тому подобного. Мы долго думали, что бы такого странного имело смысл измерить на кофе и решили, что измерять ту же флюоресценцию в ультрафиолете довольно бессмысленно. Решили оценить степень поглощения лазерного излучения на длине волны 450 нм. Эта длина волны синего лазера. В принципе, вполне логично. Насыщенный раствор кофе имеет красноватый оттенок и должен хорошо поглощать синюю часть спектра.
В результате мы получили таблицы поглощения для всех наших образцов. Однако было бы неплохо все это наглядно визуализировать. Так как я чаще всего в работе использую python и pandas с seaborn, то и данные мы сохраним в наиболее удобном для загрузки в pandas виде.
Степень поглощения в процентах в csv формате.Roast,Compression,Absorbance
medium,level 1,21.31
medium,level 1,20.57
medium,level 1,24.49
medium,level 1,26.95
medium,level 1,20.49
medium,level 1,20.06
medium,level 1,21.22
medium,level 1,23.32
medium,level 2,28.09
medium,level 2,28.27
medium,level 2,23.13
medium,level 2,25.72
medium,level 2,26.75
medium,level 2,26.05
medium,level 2,26.92
medium,level 2,25.92
medium,level 3,32.88
medium,level 3,32.23
medium,level 3,33.13
medium,level 3,28.72
medium,level 3,28.82
medium,level 3,31.49
medium,level 3,32.31
medium,level 3,33.81
medium,level 4,38.68
medium,level 4,40.54
medium,level 4,39.34
medium,level 4,43.3
medium,level 4,41.48
medium,level 4,42.26
medium,level 4,42.73
medium,level 4,42.35
medium,level 5,57.62
medium,level 5,70.62
medium,level 5,70.74
medium,level 5,57.94
medium,level 5,77.62
medium,level 5,76.64
medium,level 5,69.12
medium,level 5,66.39
dark,level 1,27.54
dark,level 1,26.8
dark,level 1,30.72
dark,level 1,33.18
dark,level 1,26.72
dark,level 1,26.29
dark,level 1,27.45
dark,level 1,29.55
dark,level 2,34.32
dark,level 2,34.5
dark,level 2,29.36
dark,level 2,31.95
dark,level 2,32.98
dark,level 2,32.28
dark,level 2,33.15
dark,level 2,32.15
dark,level 3,39.11
dark,level 3,38.46
dark,level 3,39.36
dark,level 3,34.95
dark,level 3,35.05
dark,level 3,37.72
dark,level 3,38.54
dark,level 3,40.04
dark,level 4,44.91
dark,level 4,46.77
dark,level 4,45.57
dark,level 4,49.53
dark,level 4,47.71
dark,level 4,48.49
dark,level 4,48.96
dark,level 4,48.58
dark,level 5,63.85
dark,level 5,76.85
dark,level 5,76.97
dark,level 5,64.17
dark,level 5,83.85
dark,level 5,82.87
dark,level 5,75.35
dark,level 5,72.62
Рисуем графики с python, pandas и seaborn
Для построения графика вначале импортируем наш csv в виде pandas dataframe. После этого с помощью замечательной библиотеки seaborn и функции barplot построим график, сгруппированный по степени обжарки. Для большей контрастности используем палитру «Paired», она очень хороша при сравнении разных групп. Кстати, как вы помните, мы ранжировали образцы по вкусовым качествам. Дегустаторы кофе из нас так себе, но на удивление консенсус был достигнут. Оптимальный вкус у напитка был в том случае, когда степень поглощения на длине 450 нм была в районе 32%. Отрисуем соответствующую линию на графике с помощью plt.axhline.

Код на pythonimport matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.read_csv("data.csv")
sns.set()
sns.set_style("whitegrid")
sns.set_context("talk")
ax = sns.barplot(x="Compression", y="Absorbance", hue="Roast", data=df, palette="Paired")
ax.set(ylim=(0, 100), xlabel='Compression level', ylabel='Absorbance at 450 nm, %')
plt.axhline(32, alpha=0.4, color='black', linestyle='dashed', label='Optimal concentration')
plt.legend(loc='upper left')
plt.savefig("plot.png", dpi=300)
plt.show()
На графике четко видно, что оптимальная степень сжатия для кофе темной обжарки вторая, а для средней — третья. Помимо этого восхитительного вывода из нашего эксперимента мы видим, что при максимальном сжатии увеличивается разброс в концентрации растворенных веществ между отдельными чашками эспрессо. То ли машина не обеспечивает повторяемость, то ли при такой компрессии начинают значительно влиять такие факторы как длина случайно пробитого канала в кофейной таблетке, по которому протекает горячая вода.
Чтобы сделать окончательно красиво, построим график отклонения нашего параметра от оптимума. Для этого из колонки Absorbance в нашем dataframe вычтем 32 (наш оптимум).
# Subtract optimal value
df['Absorbance'] = df['Absorbance'] - 32

Код на pythonimport matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.read_csv("data.csv")
# Subtract optimal value
df['Absorbance'] = df['Absorbance'] - 32
sns.set()
sns.set_style("whitegrid")
sns.set_context("talk")
ax = sns.barplot(x="Compression", y="Absorbance", hue="Roast", data=df, palette="Paired")
ax.set(xlabel='Compression level', ylabel='Deviation from optimal concentration')
plt.legend(loc='upper left')
plt.savefig("plot_diverging.png", dpi=300)
plt.show()
Как-то так, бессмысленно и беспощадно, можно получить чашку идеального эспрессо)
P.S. Если смогу найти время, то будет еще пост про скоростную ультразвуковую экстракцию ледяного кофе. Образцы есть, будем творить странное дальше.