Как мы строим UI для рекламных систем
- среда, 12 июня 2019 г. в 00:20:45

Ранее в нашем блоге мы писали, чем занимается компания IPONWEB — мы автоматизируем показ рекламы в интернете. Наши системы принимают решения не только на основе исторических данных, но и активно используют информацию, полученную в реальном времени. В случае DSP (Demand Side Platform — рекламная платформа для рекламодателей), рекламодатель (или его представитель) должен создать и загрузить рекламный баннер (креатив) в одном из форматов (картинка, видео, интерактивный баннер, картинка+текст и т.д.), выбрать аудиторию пользователей, которым этот баннер будет показан, определить сколько раз можно показать рекламу одному пользователю, в каких странах, на каких сайтах, на каких устройствах, и отразить это (и многое другое) в настройках таргетинга рекламной кампании, а также распределить рекламные бюджеты. Для SSP (Supply Side Platform — рекламная платформа для владельцев рекламных площадок) владелец сайта (мобильного приложения, билборда, телевизионного канала) должен определить рекламные места на своем ресурсе и указать, например, какие категории рекламы он готов на них показывать. Все эти настройки делаются вручную заблаговременно (не в момент показа рекламы) с помощью пользовательского интерфейса. В этой статье я расскажу про наш подход к построению таких интерфейсов при условии, что их много, они похожи друг на друга и при этом обладают индивидуальными особенностями.

Рекламным бизнесом мы начали заниматься еще в далеком 2007 году, но интерфейсы начали делать не сразу, а только с 2014 года. Мы традиционно занимаемся разработкой кастомных платформ, которые полностью проектируются в соответствии со спецификой бизнеса каждого отдельного клиента — среди десятков платформ, что мы построили, нет двух одинаковых. А раз наши рекламные платформы проектировались без ограничений по возможностям кастомизации, тем же требованиям должен был отвечать и пользовательский интерфейс.
Когда пять лет назад мы получили первый запрос на рекламный интерфейс для DSP, наш выбор пал на популярный и удобный стек технологий: JavaScript и AngularJS на фронтенде, а на бэкенде — Python, Django и Django Rest Framework (DRF). Из этого был сделан самый обычный проект, основной задачей которого было предоставление CRUD функциональности. Результатом его работы являлся файл с настройками для рекламной системы в формате XML. Сейчас такой протокол взаимодействия может показаться странным, но, как мы уже обсуждали, первые рекламные системы (еще без UI) мы начали строить еще в “нулевых”, и этот формат так и сохранился до сих пор.
После успешного запуска первого проекта следующие не заставили себя долго ждать. Это тоже были UI для DSP и требования к ним были такие же, как и к первому проекту. Почти. Несмотря на то, что все было очень похоже, дьявол скрывался в деталях — тут немного другая иерархия объектов, там добавлена пара полей… Самым очевидным способом получения второго проекта, очень похожего на первый, но с доработками, был метод реплицирования, которым мы и воспользовались. И он повлек за собой проблемы, знакомые многим — вместе с “хорошим” кодом копипастились и баги, патчи на которые нужно было распространять руками. То же самое происходило со всеми новыми фичами, которые раскатывались по всем активным проектам.
В таком режиме можно было работать, пока проектов было мало, но когда их количество перевалило за 20, привычный подход перестал масштабироваться. Поэтому мы решили вынести общие части проектов в библиотеку, из которой проект будет подключать нужные ему компоненты. Если обнаруживается баг, то он чинится один раз в библиотеке и распространяется на проекты автоматически при обновлении версии библиотеки, и то же самое с переиспользованием новых фичей.
У нас было несколько итераций в реализации этого подхода, и все они перетекали друг в друга эволюционно, начиная с нашего обычного проекта на чистом DRF. В последней реализации наш проект описывается с помощью DSL на базе JSON (см. картинку). Этот JSON описывает как структуру компонентов проекта, так и их взаимосвязи, причем его умеет считывать как фронтенд, так и бэкенд.
После инициализации Angular приложения фронтенд запрашивает JSON конфиг с бэкенда. Бэкенд не просто отдает статический файл с конфигурацией, а дополнительно обрабатывает его, дополняя различными метаданными или удаляя части конфига, которые отвечают за недоступные пользователю части системы. Это позволяет показывать разным пользователям интерфейс по-разному, включая интерактивные формы, CSS-стили всего приложения и специфические элементы дизайна. Последнее особенно актуально для пользовательских интерфейсов платформ, которыми пользуются разные типы клиентов с разными ролями и уровнями доступа.

Бэкенд, в отличие от фронтенда, считывает конфигурацию один раз на этапе инициализации Django-приложения. Таким образом, на бэкенде регистрируется полный объем функциональности, а доступ к различным частям системы проверяется “на лету”.
Прежде чем перейти к самому интересному — структуре базы данных — хочу ввести несколько понятий, которые мы используем, когда говорим о структуре наших проектов, чтобы быть на одной волне с читателем.
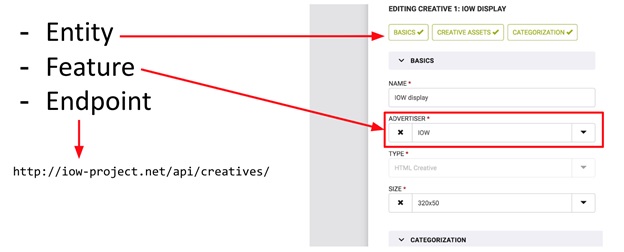
Эти понятия — Entity и Feature — хорошо иллюстрируются на форме ввода данных (см. картинку). Вся форма — это Entity (сущность), а отдельные поля на ней — это Feature (фича). На картинке также изображен Endpoint (на всякий случай). Так вот, Entity — это самостоятельный объект в системе, над которым можно производить CRUD операции, в то время как Feature — это только часть “чего-то большего”, часть Entity. С Feature нельзя производить CRUD операции без привязки к какой-либо Entity. Например: бюджет рекламной кампании без привязки к самой кампании — это просто число, которое невозможно использовать, не имея информации о родительской кампании.
Те же самые понятия можно найти и в JSON-конфигурации проекта (см. картинку).

Самой интересной частью наших проектов является структура базы данных и поддерживающая ее механика. Начав использовать PostgreSQL для самых первых версий наших проектов, мы и сегодня остаемся на этой технологии. Вместе с этим мы активно пользуемся Django ORM. В ранних реализациях мы использовали стандартную модель связей между объектами (сущностями) на Foreign Key, однако, этот подход вызывал сложности при необходимости изменения иерархии связей. Так, например, в стандартную иерархию DSP Business Unit -> Advertiser -> Campaign некоторым клиентам было необходимо ввести уровень Agency (Business Unit -> Agency -> Advertiser -> ...). Поэтому мы постепенно ушли от использования Foreign Key и организуем связи между объектами с помощью Many To Many связей через отдельную таблицу, у нас она называется LinkRegistry.
Кроме того, мы постепенно отказались от хардкода наполнения сущностей и стали хранить большинство полей в отдельных таблицах, связывая их также через LinkRegistry (см. картинку). Почему это было нужно? Для каждого клиента наполнение сущности может разниться — будут добавляться или удаляться какие-то поля. Получается, нам придется хранить в каждой сущности суперсет полей по всем нашим клиентам. При этом их все придется делать опциональными, чтобы “чужие” обязательные поля не мешали работе.

Рассмотрим пример на картинке: тут описана структура базы данных для креатива с одним дополнительным полем — image_url. В таблице креатива хранится только его id, а image_url хранится в отдельной таблице, их связь описывается еще одной записью в таблице LinkRegistry. Таким образом, этот креатив будет описываться тремя записями, по одной в каждой из таблиц. Соответственно, чтобы сохранить такой креатив, нужно сделать запись в каждую из них, а чтобы прочитать — точно так же, посетить 3 таблицы. Было бы очень неудобно писать такую обработку каждый раз с нуля, поэтому наша библиотека абстрагирует все эти детали от программиста. Для работы с данными в Django и DRF используются модели и сериалайзеры, описываемые кодом. В наших проектах набор полей в моделях и сериалайзерах определяется в рантайме по JSON конфигурации, классы моделей создаются динамически (с помощью функции type) и сохраняются в специальном регистре, откуда они доступны в процессе работы приложения. Также мы используем специальные базовые классы для этих моделей и сериалайзеров, которые помогают в работе с нестандартной структурой базы.
При сохранении нового объекта (или обновлении существующего) полученные от фронтенда данные попадают в сериалайзер, где происходит их валидация — тут ничего необычного, действуют стандартные механизмы DRF. А вот сохранение и обновление у нас переопределены. Сериалайзер всегда знает, с какой моделью он работает, и по внутреннему представлению нашей динамической модели он может понять, в какую таблицу нужно положить данные очередного поля. Эту информацию мы кодируем в кастомных полях моделей (вспомните, как описывается ForeignKey в Django — внутрь поля передается связанная модель, мы делаем так же). В этих специальных полях мы также абстрагируем необходимость добавления третьей связующей записи в LinkRegistry с помощью механизма дескрипторов — в коде вы пишете creative.image_url = 'http://foo.bar', а в переопределенном методе __set__ мы делаем запись в LinkRegistry.
Это что касается записи в базу. A теперь давайте разберемся с чтением. Как кортеж, вынутый из базы данных, преобразуется в инстанс Django модели? В базовой модели Django есть метод from_db, который вызывается для каждого полученного кортежа при выполнении запроса в queryset. На вход он получает кортеж и возвращает инстанс Django модели. Мы переопределили этот метод в своей базовой модели, где по полученному кортежу основной модели (где приходит только id) получаем данные из других связанных таблиц и, уже имея этот полный набор, инстанцируем модель. Конечно, мы также поработали над оптимизацией механизма префетчинга Django под наш нестандартный use case.
Наш фреймворк довольно сложный, поэтому мы пишем много тестов. Тесты у нас есть как для фронтенда, так и для бэкенда. Я остановлюсь подробно на тестах бекенда.
Для запуска тестов мы используем pytest. На бэкенде у нас есть два больших класса тестов: тесты нашего фреймворка (мы его еще называем “ядром”) и проектные тесты.
В ядре мы пишем как изолированные unit-тесты, так и функциональные для тестирования эндпоинтов с использованием плагина pytest-django. Вообще, вся работа с базой данных в основном тестируется через запросы к API — так, как это происходит в продакшн. Функциональным тестам можно указать JSON-конфигурацию. Чтобы не привязываться к проектной терминологии, мы используем “dummy” имена для сущностей, с которыми тестируем наши Features в ядре ("Эмма", "Алла", "Карл", "Мария" и так далее). Поскольку, написав фичу image_url, мы не хотим ограничивать сознание разработчика тем, что ее можно использовать только с сущностью Креатив — фичи и сущности универсальны, и их можно соединять друг с другом в любых комбинациях, актуальных для конкретного клиента.
Что касается тестирования проектов, в них все тестовые кейсы прогоняются с продакшн-конфигурацией, никаких dummy сущностей, поскольку для нас важно проверить именно то, с чем будет работать клиент. В проекте можно написать любые тесты, которые покроют особенности бизнес-логики проекта. При этом базовые CRUD-тесты можно подключать в проект из ядра. Они написаны в общем виде, и их можно подключать к любому проекту: тест на фичу умеет считывать JSON-конфигурацию проекта, определять, к каким сущностям эта фича подключена, и запускать проверки только для нужных сущностей. Для удобства подготовки тестовых данных мы разработали систему хелперов, которые также на основе JSON-конфигурации умеют подготавливать тестовые наборы данных. Особое место в тестировании проектов занимают E2E тесты на Protractor, которые проверяют все базовые функции проекта. Эти тесты также описываются с помощью JSON, их пишут и поддерживают фронтэнд-разработчики.
В этой статье мы рассмотрели подход модульного построения проектов, разработанный в UI департаменте компании IPONWEB. Это решение успешно работает в продакшн в течение трех лет. Однако у данного решения все еще есть ряд ограничений, которые не позволяют нам остановиться на достигнутом. Во-первых, наша кодовая база все еще достаточно сложна. Во-вторых, базовый код, поддерживающий динамические модели, связан с такими критически важными компонентами как поиск, массовая загрузка объектов, разграничение прав доступа и другие. Из-за этого изменения в одном из компонентов, могут заметно влиять на другие. Стремясь избавиться от этих ограничений, мы продолжаем активно перерабатывать нашу библиотеку, разбивая ее на множество независимых частей и уменьшая сложность кода. О результатах мы обязательно расскажем в следующих статьях.
Статья является расширенным транскриптом моего выступления на MoscowPythonConf++ 2019, поэтому также делюсь ссылками на видео и слайды.