https://habr.com/ru/company/exness/blog/493114/- Блог компании Exness
- Python
- Big Data
- DevOps
- Data Engineering
Привет, Хабр! Хочу рассказать вам, как мы писали и внедряли сервис для мониторинга качества данных. У нас есть множество источников данных: данные с финансовых рынков, торговая активность наших клиентов, котировки и многое другое. Все это генерирует миллиарды записей в день в наших процессах. Полнота и консистентность торговых данных — критический компонент бизнеса Exness.
Если вам близки проблемы обеспечения качества данных и вам интересно, как мы решили эту задачу у себя, то добро пожаловать под кат.

Меня зовут Дмитрий, я работаю в команде, которая занимается хранением как сырых данных, так и трансформацией, агрегацией и предоставлением всем отделам компании уже обработанных данных. Наши данные потребляют множество команд внутри компании, такие как Business Intelligence, Anti-Fraud, Finance, также мы предоставляем их нашим b2b партнёрам.
Работа с данными — это ответственная и сложная миссия, ведь остановка одного ETL-процесса может повлечь к парализации части бизнеса Exness.
Для решения ETL-задач мы используем разнообразные инструменты:

Вызовы, с которыми мы сталкиваемся каждый день:
- Десятки миллионов записей о сделках ежедневно;
- Миллиард записей о рынках ежедневно (котировки и др.);
- Разнородность источников данных (такие, как внешние источники Market Data, разные торговые платформы);
- Обеспечение exactly once семантики для важных данных (финансовые сделки);
- Обеспечение целостности и полноты данных;
- Предоставление гарантий, что за обусловленное время сделка добавится во все необходимые таблицы и агрегаты.
Для того, чтобы предоставлять такие гарантии, необходимо было самим научиться их отслеживать, измерять и проактивно реагировать на отклонения в качестве данных.
С учетом сложности наших процессов сбора и обработки данных, с учетом высокой скорости разработки и модификации ETL-процессов возникает необходимость следить за качеством данных уже в финальной точке. У нас обычно это база данных Clickhouse или PostgreSQL. Такие метрики расскажут нам, как быстро отрабатывают наши процессы:
SELECT server,
avg(updated - close_time)
FROM trades
WHERE close_time > subtractHours(Now(), 2)
GROUP BY server
Помогут находить дубли в данных (в Clickhouse нет constraint unique):
SELECT SUM(count) FROM (
SELECT
COUNT(*) AS count
FROM trades
GROUP BY order_id
HAVING count > 1
)
Можно придумать массу запросов (многие мы уже используем), которые помогают следить за качеством данных: сравнение количества строк в исходной таблице и таблице назначения, время последней вставки в таблицу, сравнение содержимого двух запросов и многое другое.
Получаются метрики-симптомы. Сами по себе они не укажут на причину проблемы, но позволяют показать, что проблема есть. Это будет триггером для того, чтобы инженер обратил внимание на проблему и выявил root cause. Аналогия: если у человека температура, то что-то сломалось в его организме. Температура — достаточный признак-симптом, чтобы начать разбираться и найти причину поломки.
Мы поискали готовое решение, которое могло бы собирать для нас такие метрики-симптомы. Наши требования:
- Поддержка разных источников данных (БД, очереди, http-запросы);
- Гибкое задание периодичности;
- Контроль за запросами (время выполнения, сбои);
- Простота добавления новых запросов.
В начале статьи я приводил список технологий, который мы используем в ETL. Как можно видеть, мы — сторонники open-source решений! Один пример: в качестве основного хранилища данных у нас используется column-oriented база данных Clickhouse. Наша команда несколько раз вносила правки в исходный код Clickhouse (в основном, устранение багов). В качестве инструментов работы с метриками и временными рядами мы используем: экосистему influxdb, prometheus и victoria metrics, zabbix.
На наше удивление, оказалось, что нет готового и удобного инструмента по мониторингу за качеством данных, который бы вписывался в выбранные нами технологии. Или мы плохо искали?
Да, zabbix имеет возможность запускать
Custom Scripts, а
telegraf можно научить запускать SQL запросы и превращать их результаты в метрики. Но это требовало серьезного допиливания и не работало из коробки так, как нам хотелось. Поэтому мы написали свой сервис (daemon) для слежения за качеством данных. Встречайте, nerve!
Возможности nerve
Идеологически, nerve можно описать следующей фразой:
Это сервис, который по расписанию запускает разнородные, кастомизированные задачи по сбору числовых значений, а результаты представляет в качестве метрик для разных систем сбора метрик.
Основные возможности программы:
- Поддержка разных типов задач: Query, CompareQueries и др.;
- Возможность написать свои типы задач на Python в виде runtime плагина;
- Работа с разными типами ресурсов: Clickhouse, Postgres и др.;
- Модель данных метрик, как в prometheus
metric_name{label="value"} 123.3;
- На данный момент поддержана pull модель сбора данных prometheus;
- Расписание запуска задач: период или crontab-style;
- WEB UI для анализа выполнения задач;
- Конфигурация задач может быть разбита на множество yaml файлов;
- Следование Twelve-Factor App.
Task и Resource — основные сущности конфигурирования и работы с nerve. Task — типизированное периодическое действие, в результате которого получаем метрики. Resource — объект, который содержит конфигурацию и логику, специфичную для работы с конкретным источником данных. Рассмотрим, как работает nerve на примере.
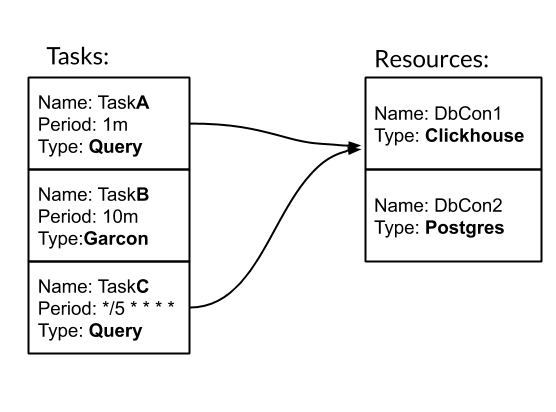
Имеем три задачи. Две из них имеют тип Query — SQL запрос. Одна имеет тип Garcon — это кастомизированная задача, которая ходит в один из наших сервисов. Периодичность задачи может быть задана временным периодом. Например, 10m означает раз в десять минут. Или crontab-style "*/5 * * * *" — каждую целую пятую минуту. Задачи TaskA и TaskC связаны с ресурсом DbCon1, который имеет тип Clickhouse. Посмотрим, как будет выглядеть конфиг:
tasks:
- name: TaskA
type: Query
resources: DbCon1
period: 1m
config:
query: SELECT COUNT(*) FROM ticks
gauge: metric_count{table="ticks"}
- name: TaskB
type: Garcon
period: 10m
config:
url: "http://hostname:9003/api/v1/orders/backups/"
gauge: backup_ago
- name: TaskC
type: Query
period: "*/5 * * * *"
resources: DbCon1
config:
query: SELECT now() - toDateTime(time_msc/1000)
FROM deals WHERE trade_server= 'Real'
ORDER BY deal DESC LIMIT 1
gauge: orders_lag
resources:
- name: DbCon1
type: Clickhouse
config:
host: clickhouse.env
port: 9000
user: readonly
password: "***"
database: data
results:
common_labels:
env="prod"
task_types_paths:
- "./tasks"
Путь "./tasks" — это путь до кастомизированных задач. В частности, там определен тип задачи Garcon. В данной статье я опущу момент создания своих типов задач.
В результате запуска сервиса nerve с таким конфигом, в WEB UI можно будет следить за тем, как отрабатывают задачи:

А по адресу /metrics будут доступны метрики для сбора:

Тип задачи Query наиболее часто используемый в нашей команде. Поэтому мы расширили его возможности для работы с GROUP BY и шаблонами. Эти механизмы дают возможность одним запросом за один раз собрать множество информации о данных:

Задача TradesLag будет раз в пять минут для каждого торгового сервера собирать максимальную задержку попадания закрытого ордера в таблицу trades, учитывая только ордера, закрытые за последние два часа.
Немного слов о реализации. Nerve — это многопоточное python3 приложение на ~3k LoC, которое легко запустить через Docker, дополнив его конфигурацией задач.
Что получилось
С nerve мы получили, что хотели. На данный момент, помимо нашей команды, к нему проявили интерес и другие команды в Exness. В нем крутится порядка 40 задач с периодичностью от 30 секунд до суток. Nerve собирает порядка 500 метрик о наших данных. Добавление новых метрик это дело 5-10 минут. Полный flow работы с метриками у нас выглядит так: nerve → prometheus → Victoria Metrics → Grafana dashboards → Alerts в PagerDuty.
С помощью nerve мы также начали собирать бизнес метрики: периодически селектим сырые события в торговой системе для оценки торговых условий.
Спасибо, хабровчанин, что дочитал мою статью до конца. Предвижу твой вопрос: а где ссылка на github? Ответ такой: мы пока не выложили nerve в Open Source. Для этого требуется дополнительная работа с нашей стороны по улучшению документации и допиливания пары фич. Если данная статья будет положительно воспринята сообществом, это даст нам дополнительный стимул поделиться с вами нашей разработкой!
Всем добра!