Jaeger для трассировки в микросервисной архитектуре
- среда, 17 мая 2023 г. в 00:02:05
Меня зовут Алексей Мясников, я тимлид на проекте YDB в Яндекс Облаке. А ещё — старший ментор на курсе «Go-разработчик» в Яндекс Практикуме и кандидат технических наук. В коммерческой разработке более 15 лет, стек — C++, Java, Go, TypeScript, а пробовал около 20 языков программирования, в том числе в продакшен.
Эта статья про Go и микросервисную архитектуру написана на основе вебинара для Яндекс Практикума.
Рассмотрим, как работает Jaeger, один из популярных инструментов, который помогает расследовать инциденты и находить узкие места в производительности в микросервисной архитектуре. Разберём, как правильно настроить трассировку и с какими проблемами можно столкнуться в процессе. Эта статья не для джунов: от должности джуна до состояния, когда можно осознанно подойти к пониманию observability, к OpenTelemetry-стандарту и Jaeger, может пройти несколько лет. До этого нужно дорасти.
Рассмотрим, как работает трассировка, и настроим Jaeger, спроектировав и отладив абстрактное приложение. Современные приложения довольно сложные. Как в меме: когда мы смотрим на фронтенд, перед глазами — прекрасная картинка. А заглядываешь под капот — там ужас. И эту сложность создаём мы сами (разработчики) — это, к сожалению, суровая реальность.

Из горячих примеров: вы пишете достаточно сложное приложение — сервис продажи билетов или абстрактный веб-сервис, а бизнес приходит с feature request. Так он обрастает функционалом всё больше и в какой-то момент становится таким, что не помещается в голову одного разработчика.
Есть такой спикер — Григорий Петров. Описывая, почему всё такое странное и сложное, он опирается на «кошелёк Миллера» — это некое волшебное число «7 плюс минус 2». Я тоже люблю эту концепцию и объясняю ею практически всё вокруг.
Психологи посчитали, сколько переменных среднестатистический человек может удерживать в кратковременной памяти и оперировать ими. Это число объясняет, откуда появилось объектно-ориентированное и функциональное программирование. Например, есть функция со множеством аргументов, которые считают, допустим, аэродинамику полёта. Если мы попытаемся посмотреть на все параметры и понять в моменте, что они из себя представляют, будет слишком сложно. Поэтому мы объединяем их в определённые объекты, соотносящиеся с внешним миром. Описывая утку, мы подразумеваем, что она летает, крякает, плавает, коряво ходит. Так мы N параметров объединяем в единый объект.
Когда мы пишем сложный бэкенд, очень трудно понять, что всё написанное делает одновременно. Поэтому мы разносим семантические штуки в отдельные микросервисы. У каждого — чёткая конкретная задача, отвечающая за определённую часть функционала. Это многое упрощает. Один микросервис узнаёт погоду, другой — формирует отчёт, третий — проводит оплату и так далее. Когда изолируем функции в отдельные микросервисы, проще разобраться, как это работает. Когда появился Kubernetes, он спровоцировал разработчиков писать микросервисные приложения и настраивать между ними взаимодействия.
Такое задание есть на курсе Go-разработчик Яндекс Практикума. URL Shortener — это простое приложение, но с каждой итерацией оно усложняется, появляются дополнительные требования с разных сторон — службы информационной безопасности или бизнеса: закрыть уязвимости, дать пользователям гарантии по устойчивости сервиса и сохранению данных, в том числе о списании или зачислении средств. С каждым новым требованием бэкенд усложняется.
У URL Shortener всего две функции: сократить длинную ссылку из интернета и отдать короткую; обратно из короткой ссылки сделать длинную с переходом по определённому http-коду. Это сервисы Bitly.com и Clck.ru. Кажется, всё просто. Но вдруг приходит бизнес и говорит, что сервис задуман как стартап и хочется начать уже зарабатывать деньги. Поэтому его нужно разделить на две части:
сокращение ссылок — только для платных пользователей, у которых есть учётная запись в нашей системе,
удлинение ссылок — общедоступно, без необходимости иметь учётную запись. Это выглядит так:

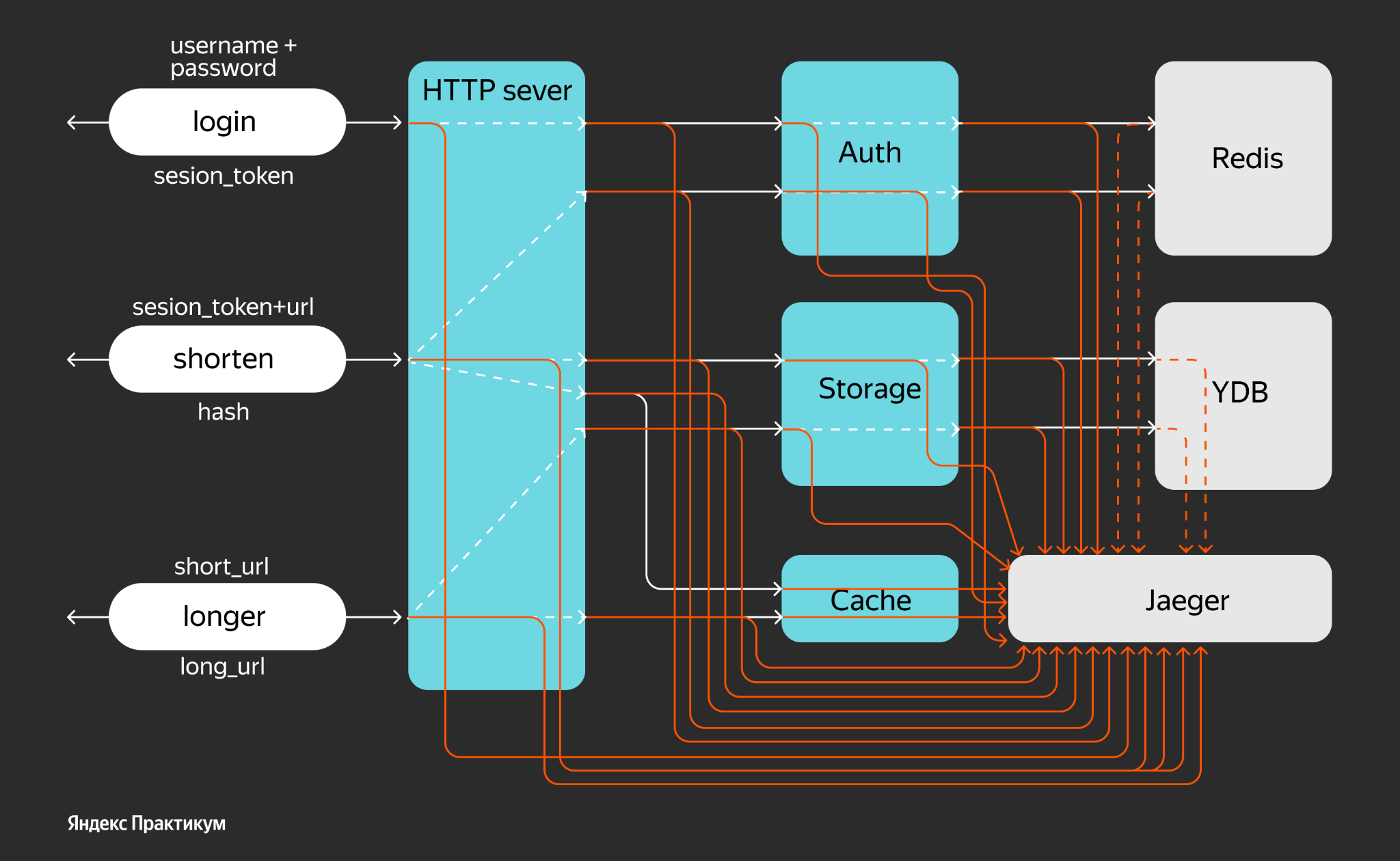
Часть, касающаяся аутентификации, усложняет сервис. На слайде представлен некий упрощённый алгоритм, как работает сокращение и удлинение.
Удлинение в правой части происходит так: в сервис поступает запрос с коротким URL. В хвосте у него записан hash, по которому мы обращаемся в некое хранилище и ищем оригинальный длинный URL, а потом делаем на него редирект. Правая часть достаточно простая и понятная: есть фолбэки, то есть, если в хранилище по hash ничего не найдено, сервис возвращает ошибку.
Левая часть начинается со сценария, когда пользователь авторизуется. У него есть платная учётная запись, где хранятся данные, сколько ссылок он может сократить. В http-handler или «ручку» приходит юзернейм и пароль. Соответственно, часть сервиса, отвечающая за логин, должна по юзернейму и паролю вернуть короткоживущий токен. Если даже злоумышленники завладеют этим токеном, спустя какое-то время из-под учётной записи конкретного пользователя они не смогут воспользоваться сервисом, получить какие-то суперправа или навредить ему.
Итак, пользователь залогинился, получил токен и с этим токеном может прийти в «ручку» shorten. Токен нужно проверить. Соответственно, если он в системе не протух, его пропускают дальше. Если протух, мы должны возвратить unauthenticated или сделать редирект на страницу логина.
Если токен валидный, мы можем его безопасно сократить. Помимо токена есть ещё и длинный URL, который пользователь хочет сократить. По нему мы вычисляем hash, сохраняем в storage и формируем короткий URL, который отдаём пользователю, а он его сохраняет и рассылает дальше.

Кажется, всё просто. Давайте попробуем описать это приложение с точки зрения микросервиса. Пример намеренно усложнён, чтобы продемонстрировать возможности распределённой трассировки.
Все голубые микросервисы написаны на Go, кроме Auth, написанного на Rust. Это та часть, которая должна помочь понять, что распределённая трассировка от языка почти не зависит. Конечно же, есть библиотеки, фреймворки, которые должны обеспечивать распределённую трассировку. Но в целом вы можете писать свои микросервисы на чём удобно.
Обычно так и бывает: в компаниях джависты пишут свои части на Java, гошники пишут на Go, шарписты — на C#, и всё это вместе должно как-то настроиться.
Можно проследить, что «ручка» login идёт в микросервис Auth. Auth хранит свои короткоживущие токены в Redis. Redis в этом примере специально выбран как ненадёжное хранилище. Это база данных in-memory, если сервер вышел из строя или рестартовался, то хранящиеся в нём данные будут потеряны. При определённых настройках дампы можно сбрасывать раз в минуту, но полагаться на его круглосуточную доступность не стоит. Поэтому в Redis сохраняем токены.
Вторая фича Redis — возможность конкретному ключу задать TTL, то есть время, сколько этот ключ будет действовать. И если мы пришли позже назначенного часа, то Redis ответит, что по этому ключу ничего нет, и нас этот сценарий устраивает.
«Ручка» ведёт в микросервис Auth, чтобы убедиться, что токен живой. Соответственно, микросервис Auth в «Redis» проверит, что по ключу (токену) есть записи, и вернёт результат. Затем можно вновь отправляться в Storage — это микросервис, у которого есть цель: сохранять данные и отдавать их назад. Под ним находится база данных YDB, которая персистентно хранит данные и, в принципе, может быть любой.
Команда YDB обеспечивает многие функции, например персистентное хранение данных между тремя дата-центрами. Это нужно на случай, если кто-то дёрнул рубильник, из-за чего потерялась зона энергетической доступности, а данные сохранены. YDB для этого и создавался.
Есть ещё один микросервис — Cache, чтобы иметь возможность быстро получить длинный URL по короткому хэшу. Этот Cache можно было реализовать на стороне http-сервера, но в этом примере мы специально вынесли его в отдельный микросервис.
Есть такой кейс: работа с базой данных типа serverless. Это бессерверная архитектура, когда пользователь платит за запрос — если делается Select или Insert, микро- и наноценты (копейки) списываются с биллинг-счёта, и при маленьких нагрузках эксплуатация обходится дешевле dedicated инсталляций баз данных. Примеры serverless баз данных: YDB, Amazon DynamoDB.
Если вы поднимаете сервер PostgreSQL в Яндекс Облаке, то он в средней конфигурации будет стоить около 4000 рублей в месяц. Это dedicated-сервер с выделенными ресурсами. В YDB в режиме serverless действует плата за запрос, которая списывается со счёта. Соответственно, никаких выделенных ресурсов отдельно не существует. Обычно на практике получается так, что мы можем противопоставить сервер PostgreSQL за 4000 рублей и YDB в режиме serverless, который при небольшой нагрузке обойдётся, скажем, в 150 рублей в месяц (или вообще бесплатно, т. к. Яндекс Облако предоставляет FreeTier в 1 млн request unit’ов). Так YDB становится дешёвым решением.
Итак, Cache становится полезен тем, что, если мы все запросы будем отправлять в PostgreSQL, в какой-то момент ему станет плохо. Когда много пользователей придут в наш сервис, выделенный сервис перестанет справляться. Сеньоры знают, что можно масштабироваться вертикально — «докинуть» ресурсов (ядер, оперативки, сменить HDD на SSD), а можно горизонтально, но это сложнее. Так вот Cache нас спасает от того, чтобы не за-DOS-ить базу данных. В случае YDB в режиме Serverless мы с помощью Cache уменьшаем количество запросов к базе данных и тем самым потребление и размер счёта.
Третья фича, которую решает Cache, — возможность наиболее быстрым образом отдать длинный URL, совершить редирект, когда данные уже известны, по горячим следам. Например, у нас есть N пользователей, которых мы любим, холим, лелеем. И один из них запустил промоакцию — распродажу по ссылке — и поделился ею в чатах и соцсетях. По этой ссылке стало приходить много пользователей. Когда переходов много, хотелось бы закэшировать данные, а не ходить за ними каждый раз в базу данных.
Если HTTP-сервер перестаёт справляться с нагрузкой, мы поставим рядом точно такой же и примитивный балансировщик нагрузки (типа L3) и сможем принять бОльшее количество запросов. Точно так же мы сможем горизонтально масштабировать любой другой микросервис.
Есть и другие нюансы. Например, микросервис Auth сохраняет в свой Redis, а его дубль сохраняет в свой Redis токены. Если повторный запрос пришёл не в тот сервис Auth, то может оказаться, что по этому токену запрос пользователя не сработает. Тут нужна более хитрая схема и более продвинутый балансировщик (типа L7).
В целом микросервисная архитектура позволяет эти узкие места масштабировать и расти вместе с нашей аудиторией.

Как видно на этой иллюстрации, у приложения URL Shortener есть только три «ручки», спрятанные за http-портом 8080. А всё общение с микросервисами реализуется через GRPC в закрытом контуре, куда внешние пользователи не попадают. Это сделано, прежде всего, по соображениям безопасности. GRPC хорош для удалённого вызова процедур. В этом приложении он решает свою задачу довольно хорошо.

А вот слайд про реальные распределённые микросервисные приложения. В примере с URL Shortener всё обосновано, но излишне усложнено. Но реальные приложения могут быть гораздо сложнее. Взаимодействие микросервисов может быть витиеватым. Картинка слева — прохождение сигнала в нейронной сети. Примерно так же происходит распределённый вызов. А справа — картинка из статьи Яндекса про архитектуру Apphost. Тут всё мелко, но примерно каждая нитка — это взаимодействие разных микросервисов.
Всё хорошо, пока работает. Но как только работать перестаёт, не отвечает нужными нам кодами 200 на запросы, тормозит, возникает нарушение целостности данных или их утечка, — надо как-то расследовать инцидент. В больших компаниях есть так или иначе устоявшиеся процессы заведения, разбора инцидентов и action items, чтобы не допустить эти инциденты в будущем.
Есть позитивный сценарий — перешли по URL, сократили, затем направились по другому URL, получили редирект на нужную страницу. Но есть и негативный, когда всё работает настолько медленно, что браузер умудряется обрубить соединение, и пользователь разочарован. Или ещё хуже — неприятности, что чувствительные данные утекли.
Чтобы этого избежать, существуют логи, метрики, алерты, трейсинг. Иногда “reset” помогает в моменте, но не помогает предотвратить эту же ситуацию в будущем.
Три вида инструментов разбора инцидентов — логирование, метрики и трассировка. Ещё один вариант — профилирование, но оно работает, когда мы знаем проблемное место и дальше можем попрофилировать по CPU или памяти. Это подходит для монолита, но не для микросервисов. Ну или отдельно взятого микросервиса.

Логирование. Варианты с логированием сложны и обычно расследуют конкретный сценарий: направились от короткого URL к длинному, зашли в http-сервис, посмотрели логи, нашли там request ID или что-то идентифицирующее, а затем попытались отследить, куда направлен запрос, — на Auth, Storage, в Cache или куда-то ещё. Для этого нужно направиться в соответствующий микросервис, достать логи, сматчить их так, чтобы входящий запрос дальше обрабатывался и направлялся.
Сложно решить эту проблему, особенно быстро. Обычный сценарий: люди нажимают кнопку «сократить URL» или «купить билет». Видят, что что-то тормозит, курсор-колёсико (на javascript или CSS) крутится, но ничего не происходит. Тогда пользователи пытаются перезагружать страницу — снова и снова. Это массовая история: сервису и так плохо, а его DOS-ят абсолютно валидные пользователи. Хотя если бы пользователи в моменте ушли, сервис бы справился с нагрузкой. Это психология, так часто происходит.

Метрики. Они не позволяют расследовать конкретную цепочку, но позволяют оценить среднюю температуру по больнице. Например, посмотреть время выполнения запроса. Когда мы приблизимся к инциденту, могут начать расти задержки. Можно настроить алерты, что при переходе отметки на 99 перцентиле в 500 миллисекунд. Если аллерт сработал, нужно всю команду поднимать «на уши».
По метрикам мы можем понять, что началась деградация. Или что мы раскатили новую версию, у нас уменьшились latency и всё стало слишком хорошо. Так мы можем определить, что новая версия стала лучше и дала какой-то boost. Тем не менее расследование по метрикам конкретного запроса практически невозможно.
Вообще всё это — логи, метрики, профилирование — про observability или наблюдаемость, возможность внимательнее рассмотреть систему, изучить под лупой конкретный сценарий. Писать приложение можно, вообще не логируя. У нас в Яндекс Практикуме на первых спринтах студенты логи даже не добавляют и затем приходят с вопросом, почему всё зависло.
Опытные разработчики пишут логи и проставляют их везде. Логи надо писать правильными логерами, чтобы само логирование не увеличивало latency. Но всё это нужно для наблюдаемости — чтобы увидеть, как работает сервис.
На рынке известно много систем для трассировки. Есть закрытые, проприетарные, платные, лицензионные и Open Source. Open Source системы — это OpenTracing и OpenCensus. OpenTracing — это стандарт, реализованный Uber в продукте под названием Jaeger. OpenCensus — другой стандарт, альтернативный. Он тоже про наблюдаемость, но разработан Google. Стандарты много лет сосуществовали бок о бок, компании выбирали один из них. Наконец, в 2021 году эти два стандарта объединились в OpenTelemetry.
Однако суть осталась та же: записать некое состояние системы и как-то отслеживать его по времени. По моему опыту в прошлом году он ещё не был готов для продакшена, но уже готов в этом году.

Jaeger поддерживает и OpenTracing API, и OpenTelemetry API. Cуть в том, чтобы поднять Jaeger и настроить свои приложения, микросервисы, чтобы они отправляли туда данные о своей жизнедеятельности. У Jaeger есть хранилище, где записываются эти данные. На слайде нарисован Data Store Cassandra. А у нас в Яндекс Облаке в качестве Data Store используется тот же YDB или ClickHouse. Это всё, что нужно знать с точки зрения DevOps. Есть сервер Jaeger, куда мы направляем данные.

Вспомним теорию распределённой трассировки. Ключевое понятие — это трасса, это тот самый вызов от момента, когда пользователь из браузера послал запрос. Он пришёл в наш сервис, и дальше направился по цепочке вызовов между микросервисами. Трасса состоит из спанов — атомарных кусочков трассы. Спаны могут быть расположены внутри одного микросервиса. Например, если есть функция — тот же http-хендлер, то мы чётко понимаем, где у неё начало, а где конец, получилось ли её реализовать или произошла ошибка.
Из спанов, составляя соотношение «родительский / дочерний спан», можно выстроить трассу. Конкретная система трассировки типа Jaeger занимается тем, чтобы выстроить её и как-то визуально показать, а затем расследовать неприятности.

Стандарт OpenTelemetry, по сути, решил несколько задач наблюдаемости. Это и логирование, то есть OpenTelemetry стандарт, и соответствующие фреймворки. Они позволяют писать логи прямо в OpenTelemetry провайдер. Данные, связанные с построением метрик, также можно туда направлять.
Спан — это сущность, у которой есть начало и конец. Из конца вычли начало и получили latency в выполнении конкретного кусочка кода. А дальше можем строить графики, что позволяет реализовывать распределённую трассировку.
Конкретно в этом микросервисе URL shortener выглядит примерно так, как на картинке выше. Логируем некие моменты начала и конца для каждого span. Если известен родительский span, сохраняем его как атрибут. И по каждой проблеме микросервиса отправляем в Jaeger span. Jaeger занимается сочленением в Единый Граф вызовов.

Вот так примерно выглядит трасса сокращения ссылок. Можно увидеть общее время выполнения — 165 миллисекунд — и посмотреть, где каждая часть, сколько потребовалось на выполнение каждой конкретной.
Практическую часть лучше смотреть в записи вебинара. Ниже собраны основные шаги с пояснениями.
Ниже скриншот проекта Jaeger, где по папочкам разложены все микросервисы: Auth, Cache, http.
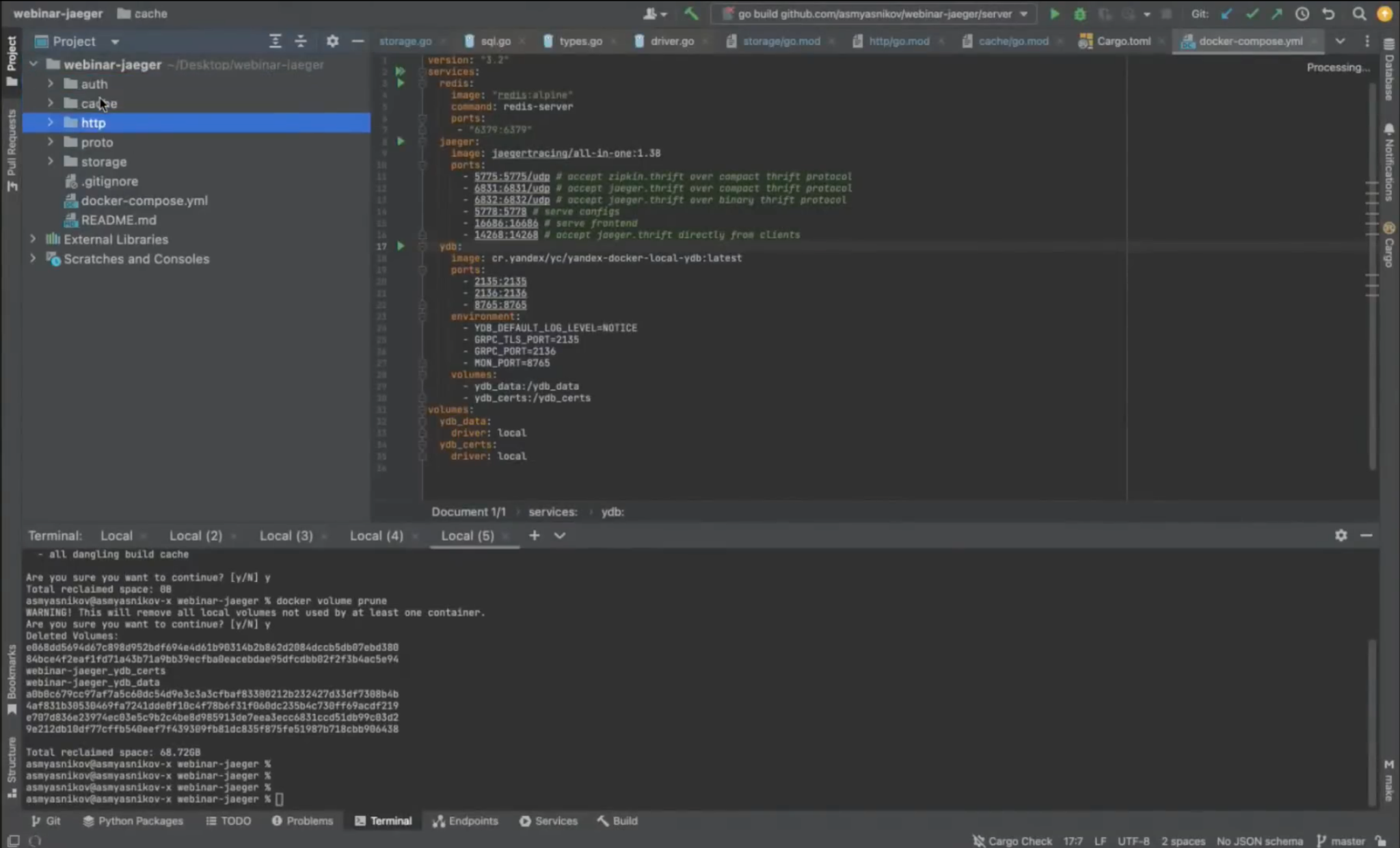
Синим выделен входной HTTP сервер Storage. Proto — это кодогенерация. Кодогенерация вынесена в отдельную папочку, чтобы ею могли воспользоваться микросервисы http, Cache и Storage. Для Auth кодогенерация не требуется, т. к. в Rust во фреймворке Tokio кодогенерация происходит в момент компиляции проекта.
Чтобы всё это заработало, нужен Docker и docker-compose. В корне проекта есть docker-compose файл, а в нём все необходимые пререквизиты: Redis, сам Jaeger с пачкой портов, которые он экспоузит наружу, YDB со своими портами.
Мы запускаем команду docker compose up -d, чтобы поднять все эти пререквизиты. Когда пререквизиты стартовали — можем поднимать все микросервисы. Если перейти в папку Auth, то увидим довольно примитивный проект на Rust. Введём команду cargo run и поднимем микросервис Auth.
У него есть некий порт, чтобы к нему могли обращаться по GRPC-протоколу. Поднимаем микросервис Storage, написанный на Go. Делаем go run и запускаем.
Затем поднимаем микросервис Cache, тоже написанный на Go. Можем поднять и entry point — http-сервис на порту 8080.
Всё стартовало и готово выполнять запрос. Идём в браузер, запускаем localhost 8080 и смотрим, что получилось. Индексная страница содержит приглашение, где нужно ввести логин и пароль.
Если ввели неправильный логин и пароль, получим об этом соответствующий вывод. Когда что-то не работает, можно пойти в Jaeger. Чтобы понять, какой порт у Jaeger, нужно посмотреть Docker-файл.
Я зашёл на проект Jaeger и скопировал этот кусочек docker-compose файла: serve frontend, port 16 686.
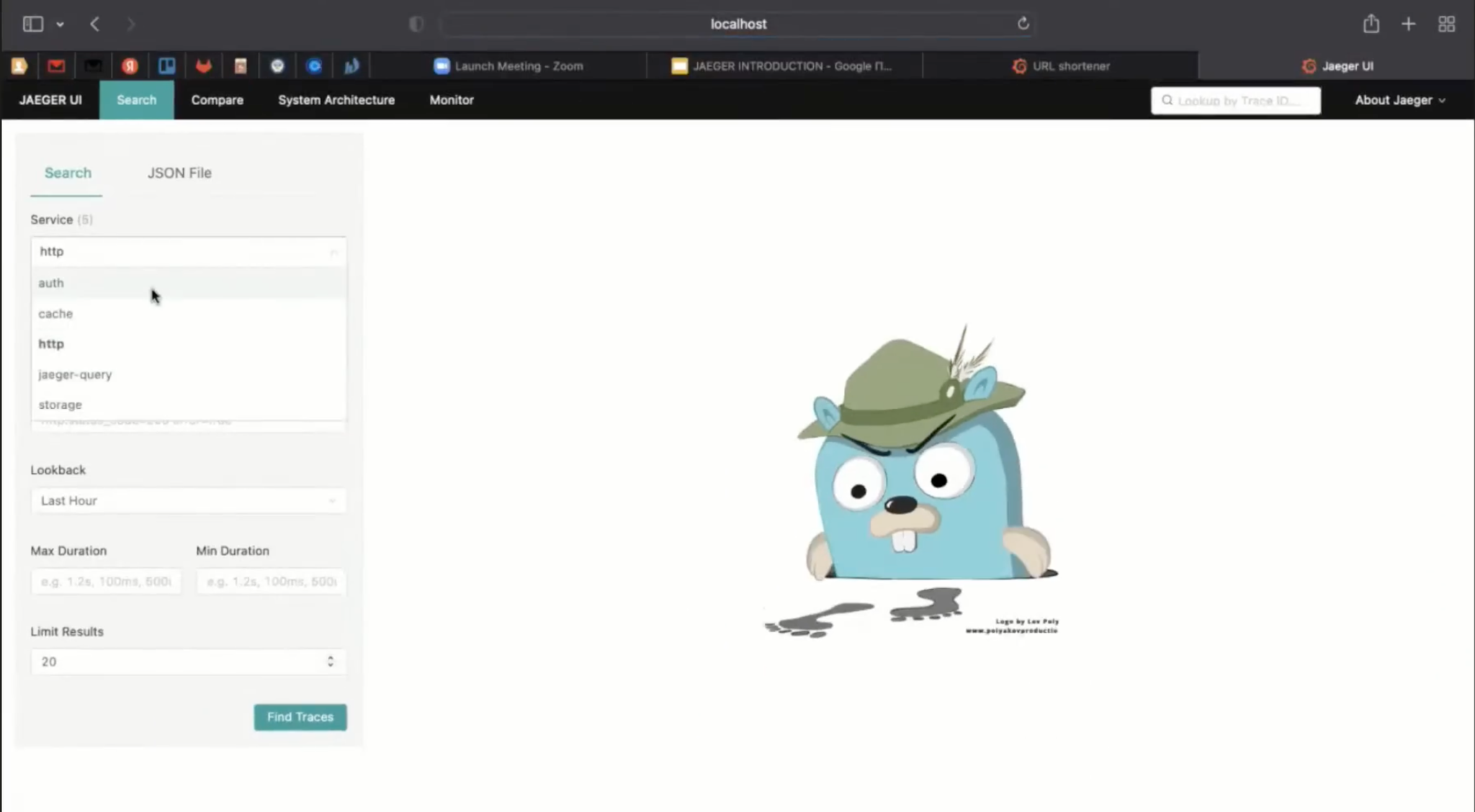
Service — это конкретные микросервисы, прописанные у Jaeger. А ещё из коробки есть служебный Jaeger-query.

Нас интересует микросервис http — голубого цвета. Если вместо голубого появится красный — это ошибка. В интерфейсе это можно фильтровать. Например, выставить, что нас не интересуют безошибочные запросы.
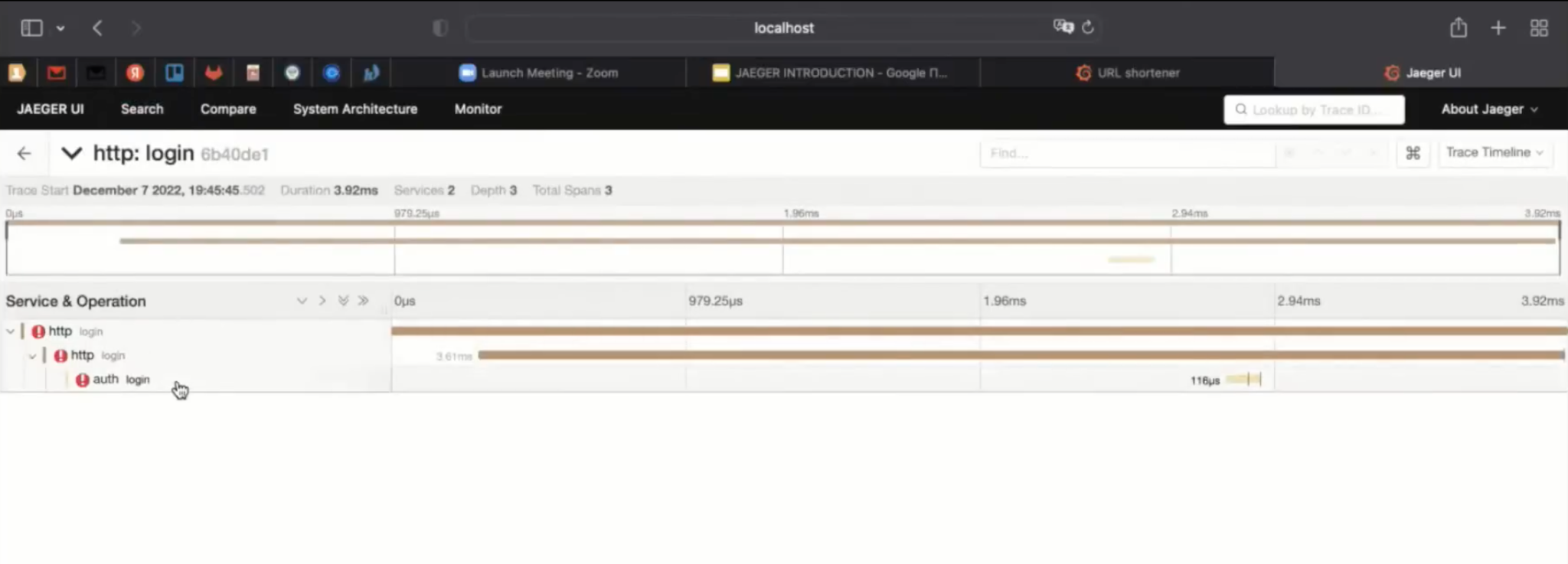
Так у нас отфильтровался один-единственный запрос, построилась трасса и мы приняли запрос на «ручку» логин, где написано wrong password.

otel.library.name задаёт имя микросервиса в трассе при инициализации провайдера. При создании корневой трассы указали http, и дальше оно будет присутствовать в интерфейсе.
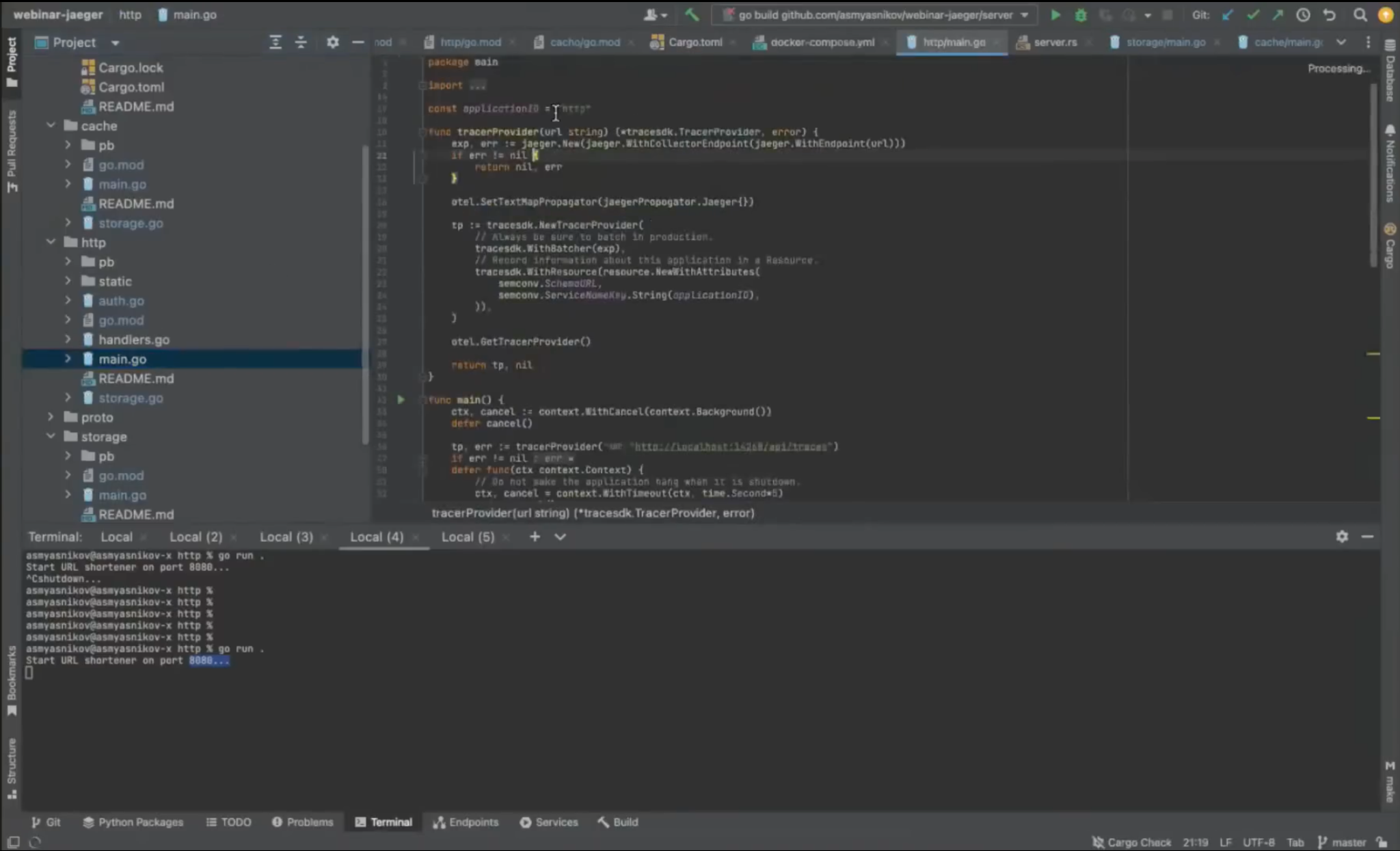
На этом этапе создаётся корневой span с именем приложения (микросервиса) http. Из контекста можно получить идентификатор родительского span. Но в данном случае этот запрос пришёл из интернета, поэтому никакого родительского span нет.
Auth логин — это поле в структуре, которое, по сути, инкапсулирует в себе работу с микросервисом Auth. Здесь мы прописали, что сейчас выполняет логин:

Первый логин — это http-хендлер. Второй — это структура Auth, инкапсулятор работы с микросервисом Auth. Здесь тоже есть ошибки.
Эти логи пишутся вот так: RecordError. В случае успешного логина — Event. В этом примере все выходы обёрнуты в defer, старт span’а — понятный.
Нас интересует код в конце, который прячется за ошибкой.

Здесь подписано: Auth. Если посмотреть теги, otel.library.name auth — это тот же микросервис на Rust.
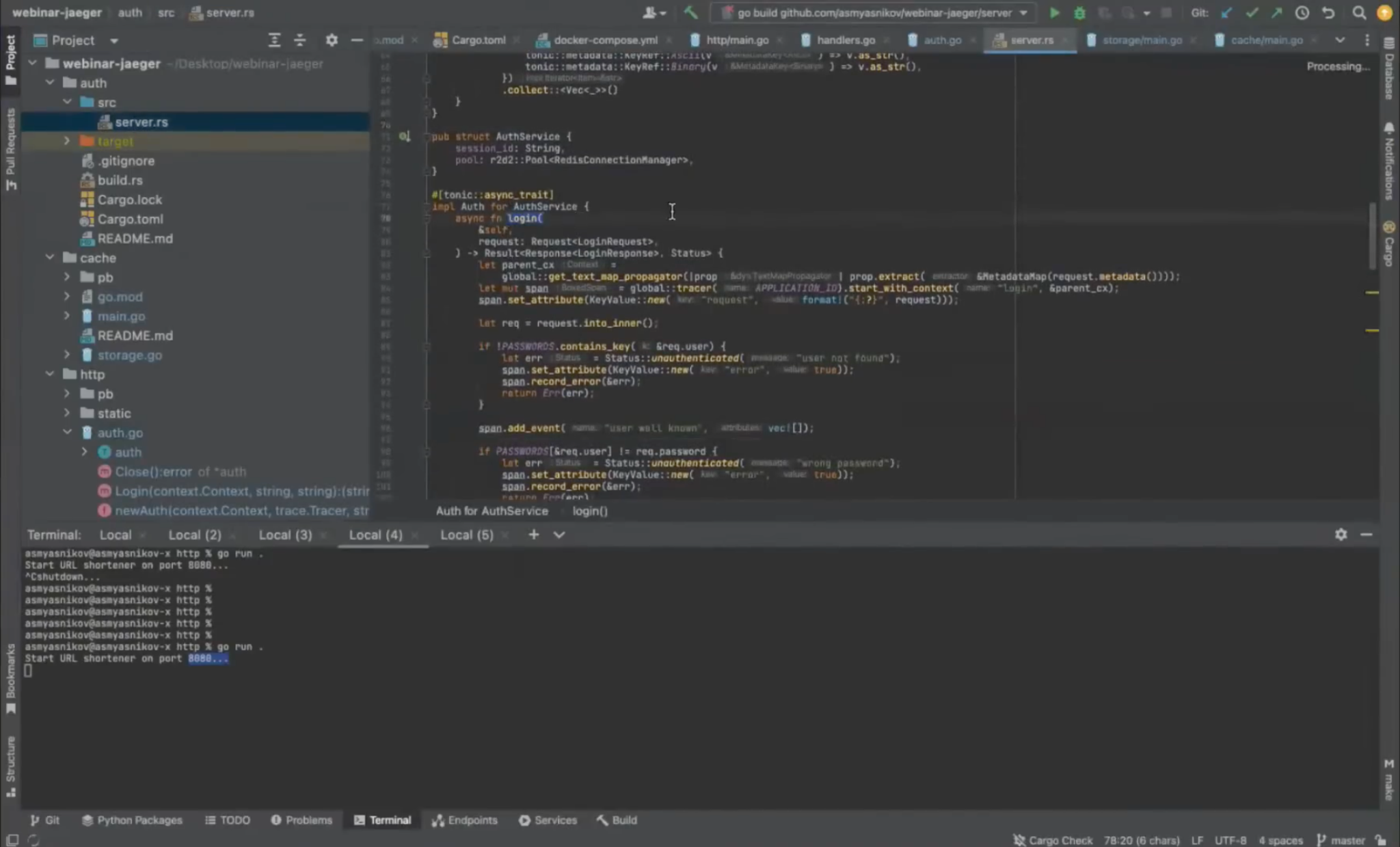
У него есть GRPC-хендлер, в котором тоже создаётся span с именем логин. Он указал свой Application name — auth и пытается из некоего родительского контекста вынуть родительский span, чтобы Jaeger смог построить это дерево вызовов и логировать:

Создаётся AddEvent. user well known, если вызов успешный. Если нет, делаем RecordError и это фиксируется.
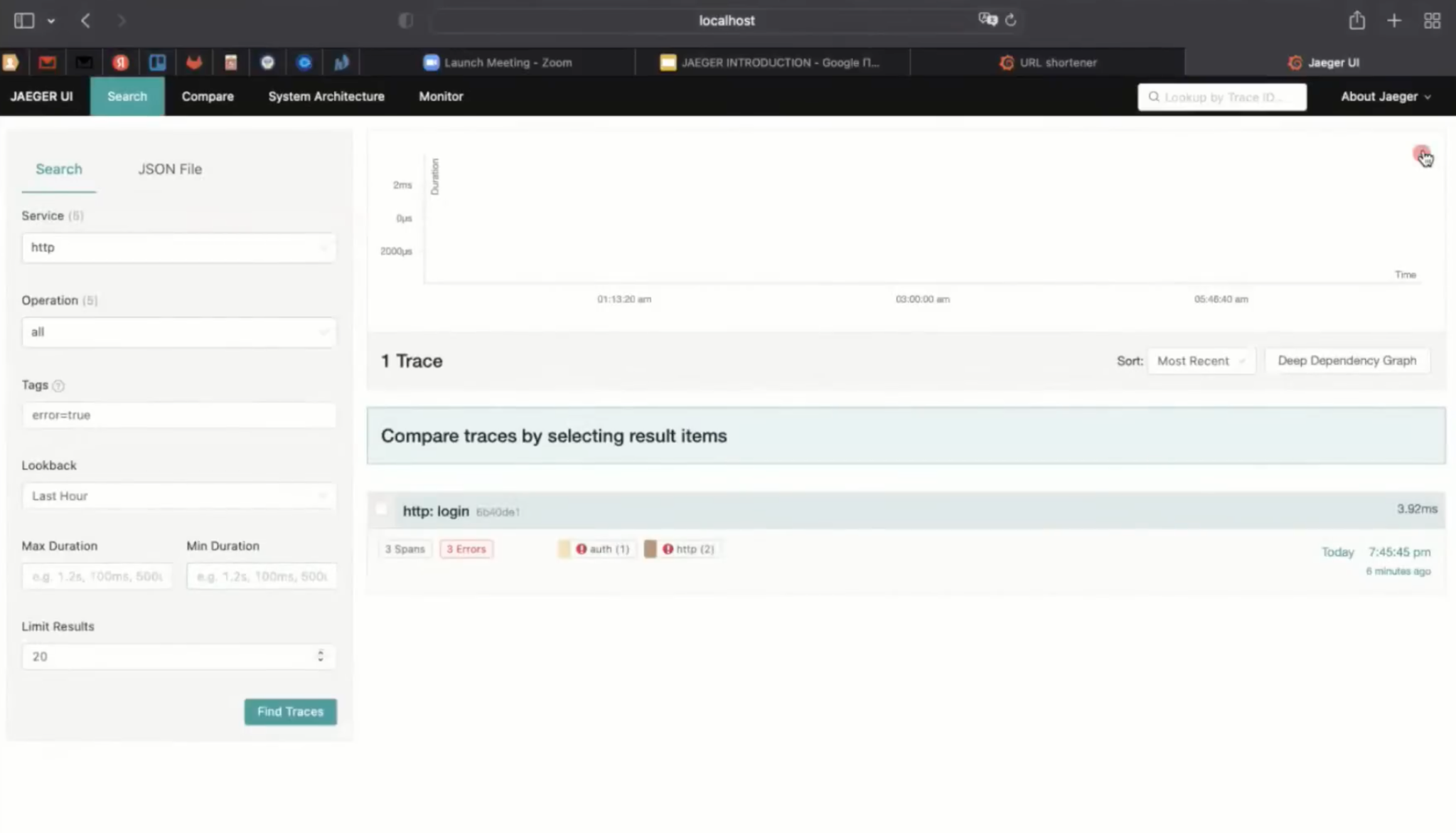
За то, чтобы точечки были красными или синими, отвечает tag “error” со значением true.

Error всегда ставится со значением True и User well known. Ищем пользователя по имени, но пароль не подходит. На самом деле это валидная ситуация, когда человек пришёл с неправильным паролем. А мы на конкретном примере посмотрели на трассу.
Теперь можно посмотреть на трассу для успешного логина. Убираем фильтрацию по ошибкам и смотрим:
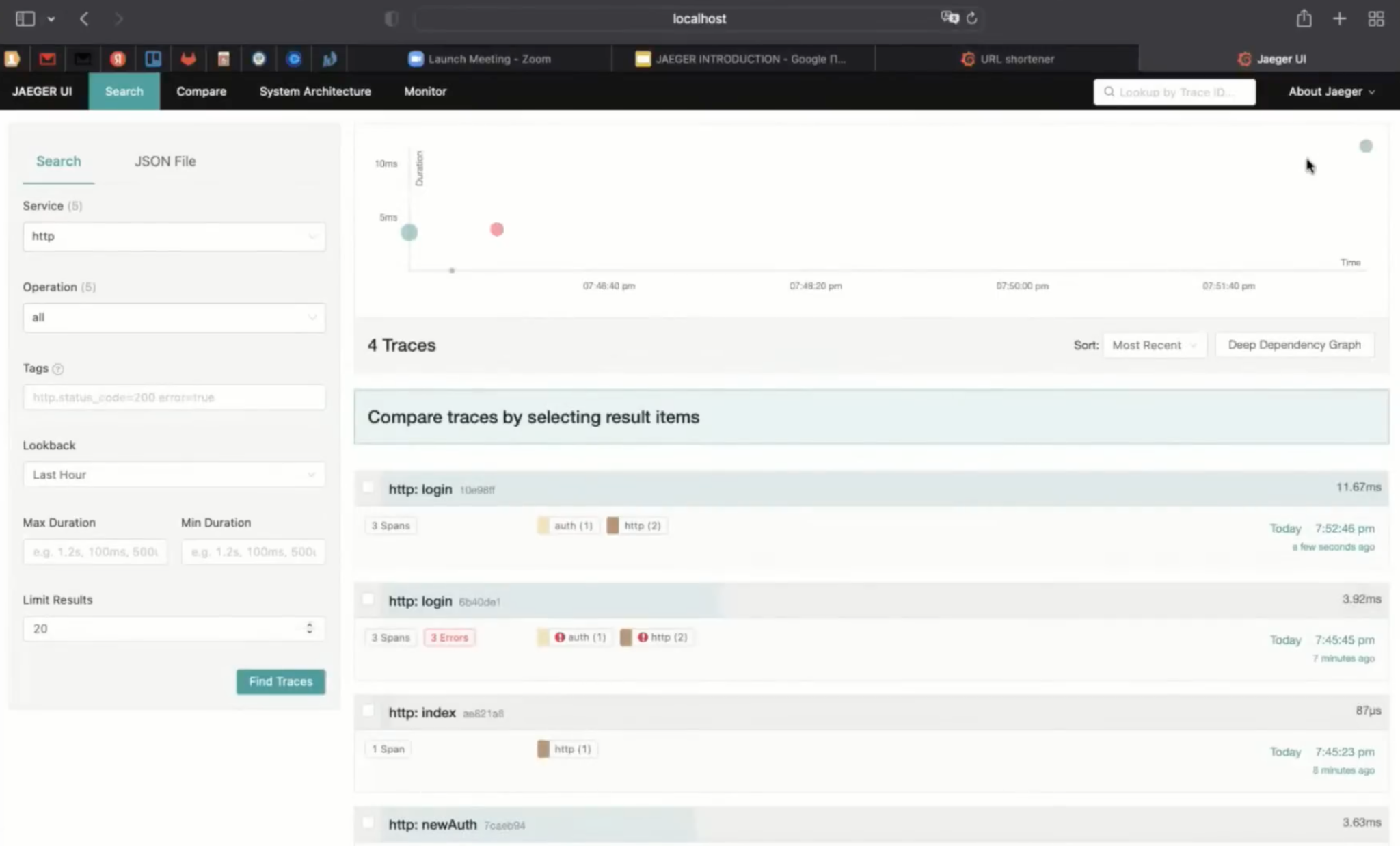
Была индексная страница, логин — и вот успешная трасса, микросервис Auth. User well known сделал одну запись. Можно добавить ещё одну, например, что пароль — хороший.
Посетим ещё раз индексную страницу, введём логин, пароль и посмотрим на последнюю трассу, где добавили ещё одно сообщение, и должны увидеть два.
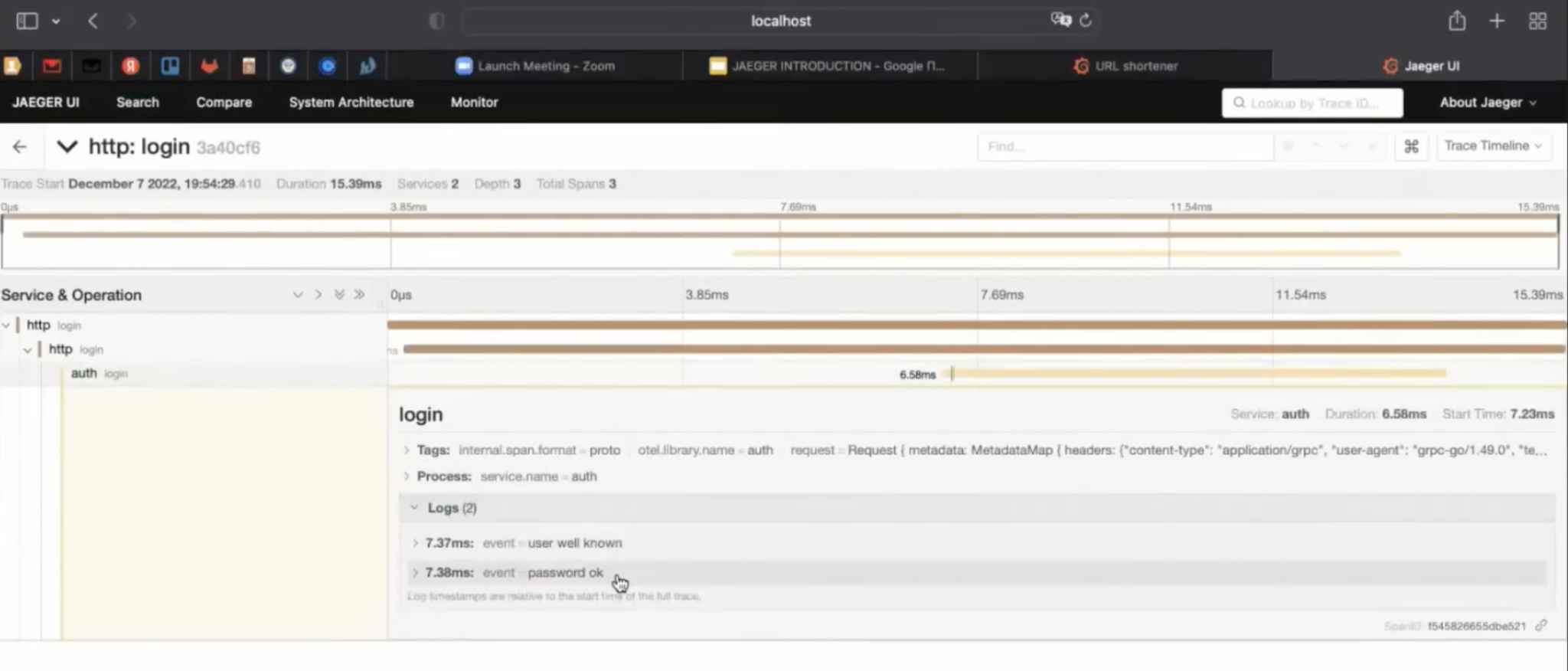
Высветилось, что password ok.
Теперь попробуем сократить ссылку.

Здесь я на самом деле сделал так, что по вводу всё время формируются хэши. Кнопочка «Дай мне короткую ссылку» в этом случае нужна для того, чтобы посмотреть, что поступит в Jaeger.
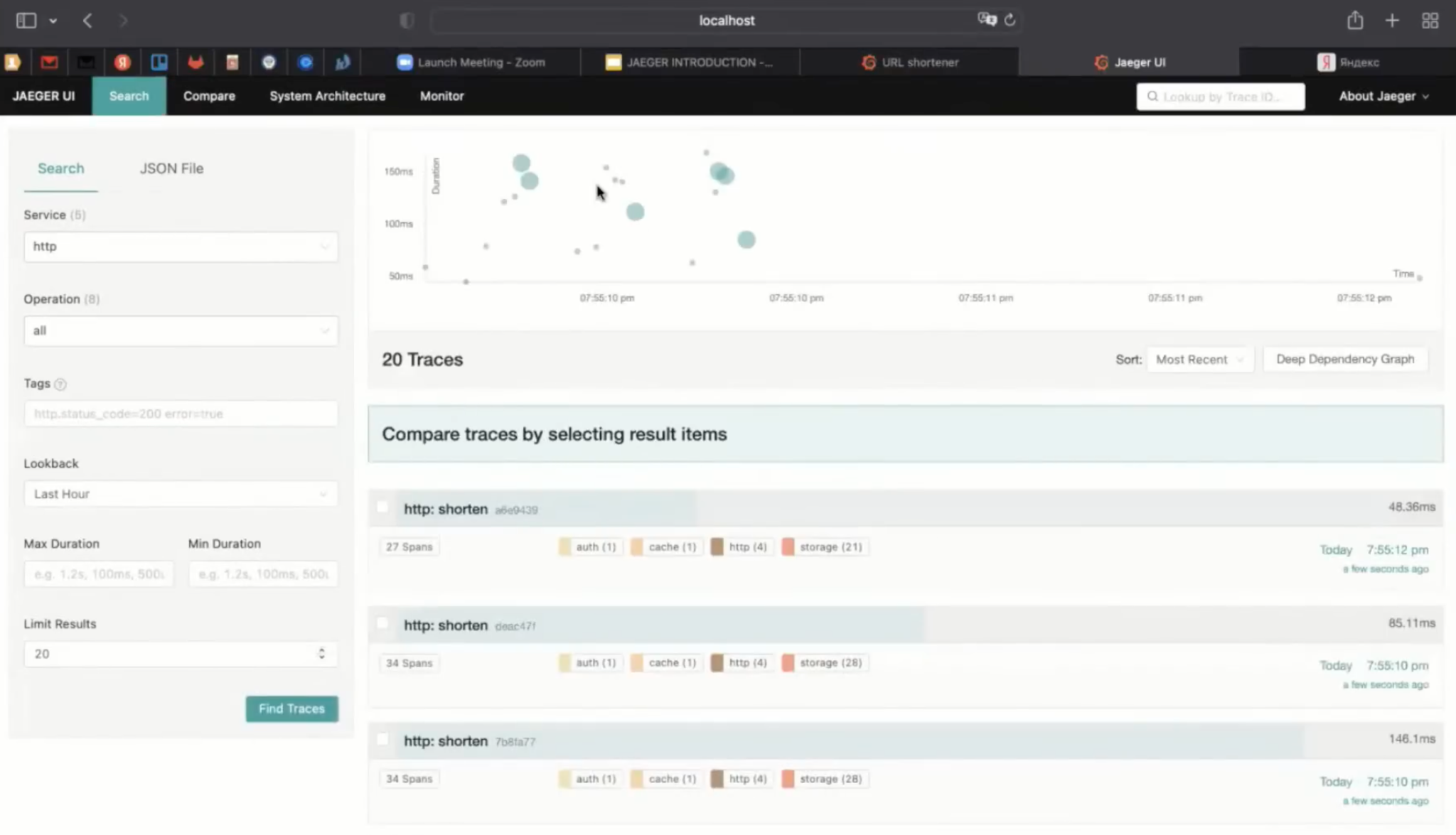
Теперь попробуем сократить Google. Ссылки все сокращаются и работают — на Jaeger тоже всё хорошо, лишь россыпь голубых фишечек. Теперь попробуем всё-таки остановить Redis и посмотреть, что микросервис Auth не сможет предоставить какую-то функциональность.

Добавили дедлайн 1 секунду, и всё открылось. Найдём эту трассу, проверим токен DeadlineExceeded.

Ещё раз поднимем Redis: взглянем на валидную трассу, где я должен был сделать некую observability драйвера для YDB.
А теперь давайте сократим что-нибудь длинное — результат поиска «вебинар Jaeger» и найдём эту трассу.
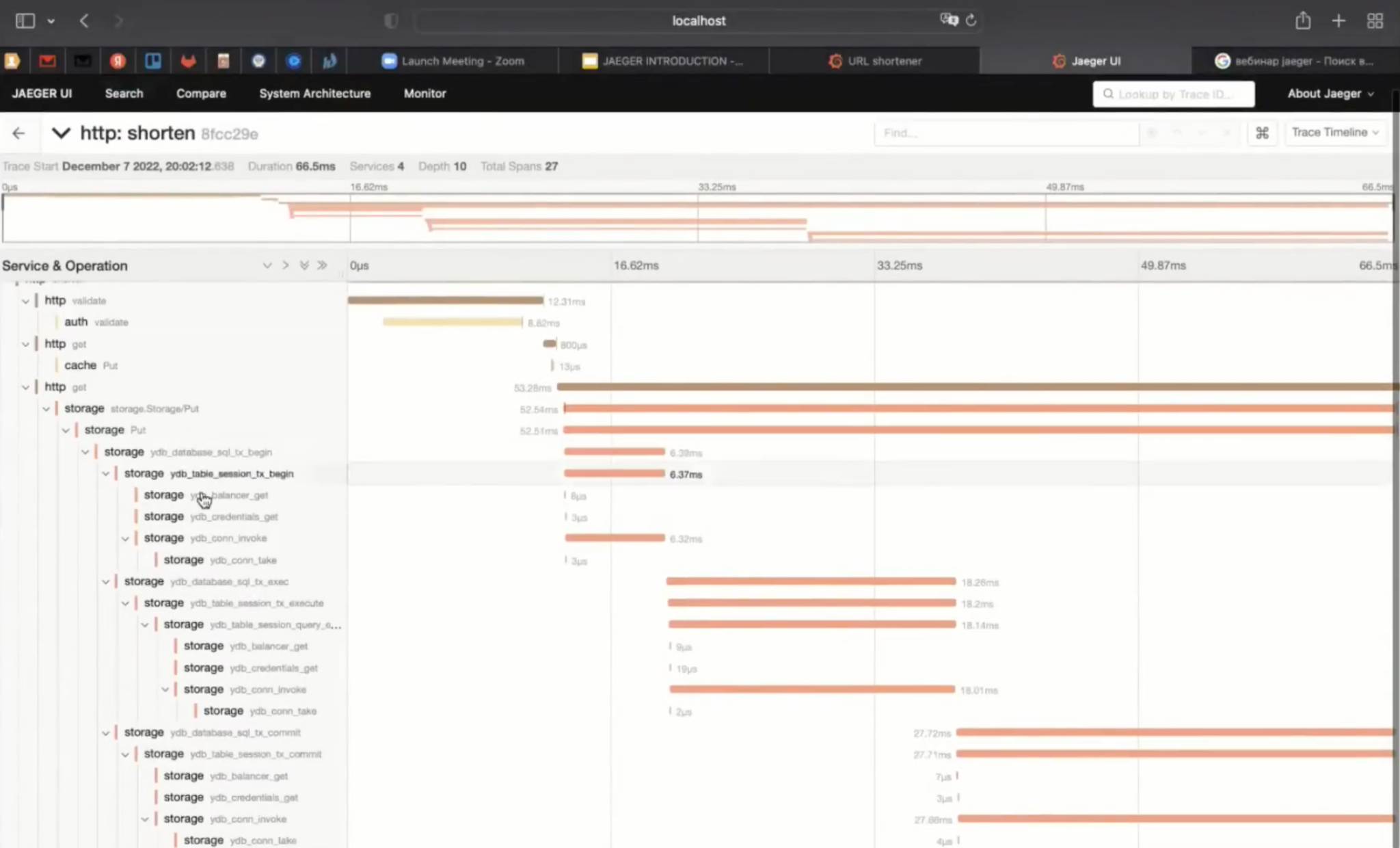
Получилась довольно подробная трасса. Та внутрянка, которую я делаю в драйвере для YDB, здесь подробно расписана.

Можно попытаться проследить, какое дефолтное значение ttl, time to live для Cache. Посмотрим, где инициализируется поле urls.
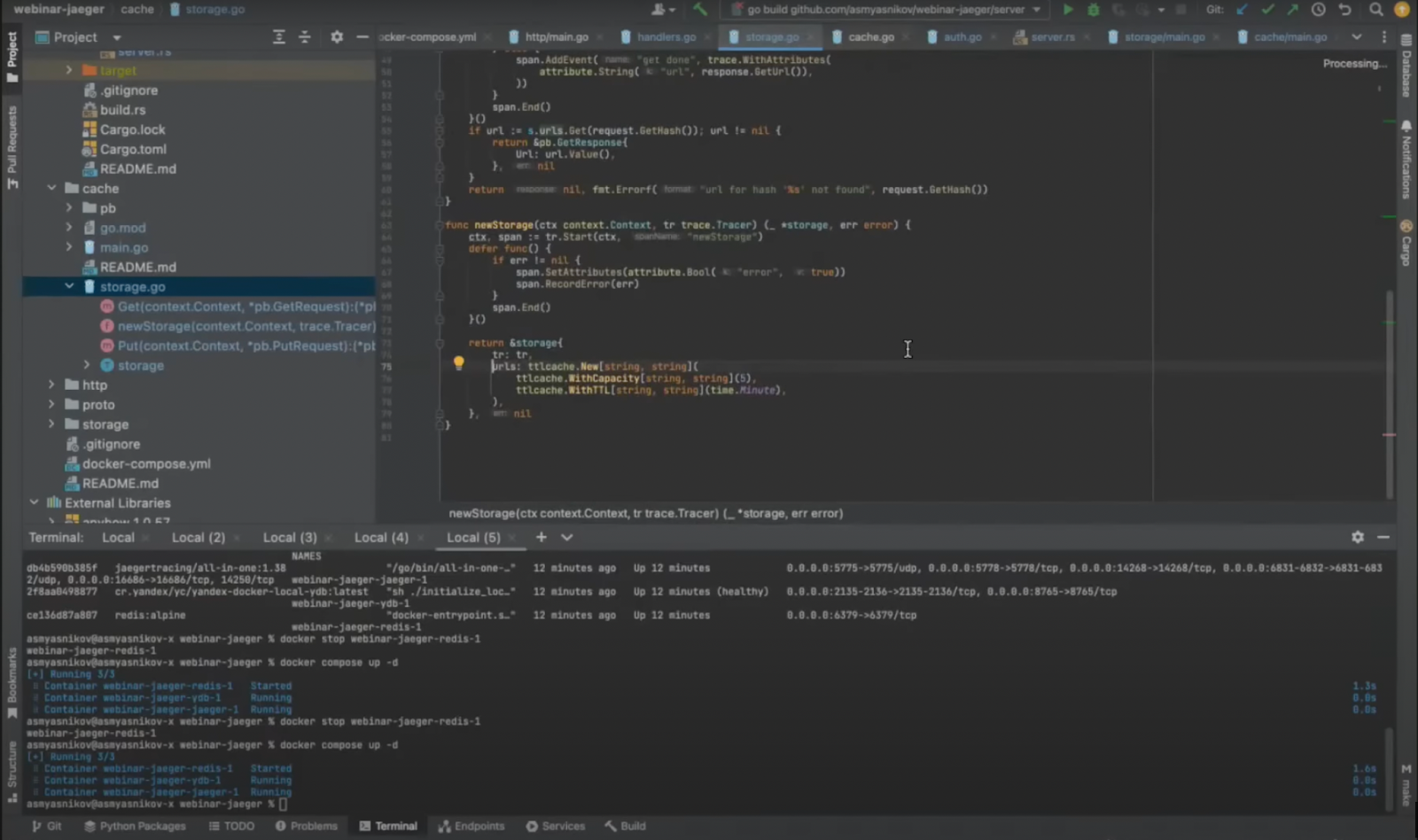
В данном случае тот ключ, который давно не использовался, будет вытеснен. Ttl составляет примерно минуту. Возможно, протоколировать его стоит как промежуточное лог-сообщение.
Тогда мы снова идём в YDB, открываем транзакцию, выполняем запрос.
В URL таблице можно посмотреть, что сохранилось. Направляемся в базу данных и смотрим, почему долго работает запрос. У YDB есть для этого встроенный интерфейс. А ещё YDB умеет сохранять свои трассы в Jaeger, но эта конкретная локальная инсталляция в виде Docker не умеет.
Весь код проект выложен на гитхаб.
Jaeger помогает находить узкие места в производительности с помощью логирования и метрик. Это идеальное решение для observability микросервисов. Позволяет распутаться во взаимодействии сервисов и найти проблемные места. А чтобы было понятнее, как использовать этот инструмент, мы разобрали его работу на примере реального проекта.