http://habrahabr.ru/post/273241/

СУБД Neo4j — это NoSQL база данных, ориентированная на хранение графов. Изюминкой продукта является декларативный язык запросов Cypher.
Cypher позаимствовал ключевые слова типа WHERE, ORDER BY из SQL; синтаксис из таких разных языков как Python, Haskell, SPARQL; и в результате появился язык, позволяющий делать запросы к графам в визуальной форме наподобие
ASCII art. Например, заголовок данной статьи я бы представил в виде графа
(Neo4j) — [изучаем] -> (Wordnet). И это почти готовый запрос к базе данных!
Для изучения граф-ориентированной базы данных нужен какой-нибудь граф. Это может быть социальная сеть, дамп википедии или схема железных дорог. Мы пойдём простым путём и воспользуемся огромным общедоступным графом лексической базы
Wordnet. Лингвисты из Принстона проделали гигантскую работу по систематизации словарного запаса английского языка, а энтузиасты перевели базу данных на многие языки, включая русский. Например, в этой базе свыше 80 тысяч существительных, связанных между собой лексическими отношениями, такими как «синоним», «часть большего», «материал для» и т. п. Эта база является естественным графом, и мы её импортируем в Neo4j.
Установка Neo4j
Процесс установки для разных ОС описан на
сайте. Всё описываемое здесь ПО платформенно-независимое, но для определенности все инструкции будут для Debian/Ubuntu.
1. Добавить репозиторий
wget -O - https://debian.neo4j.org/neotechnology.gpg.key | sudo apt-key add -
echo 'deb http://debian.neo4j.org/repo stable/' >/tmp/neo4j.list
sudo mv /tmp/neo4j.list /etc/apt/sources.list.d
sudo apt-get update
2. Установить Neo4j (community edition)
sudo apt-get install neo4j
Эта команда установит ПО в вашу домашнюю директорию и запустит сервис, который будет работать от имени пользователя neo4j.
3. Разрешить удалённый доступ
Если вы установили Neo4j на свой компьютер, этот шаг пропустите. Если же требуется доступ к серверу с других компьютеров в локальной сети, отредактируйте файл /var/lib/neo4j/conf/neo4j-server.properties
Для доступа с любого компьютера локальной сети установите параметры:
org.neo4j.server.webserver.address=0.0.0.0
dbms.security.auth_enabled=false
По умолчанию используется порт 7474, изменить порт можно, добавив строку в тот же файл:
org.neo4j.server.webserver.port=7474
Обратите внимание, что мы не настроили безопасность СУБД! Более подробно читайте
инструкцию.
Проверить установку можно, набрав в браузере адрес и порт сервера. Neo4j реализует роскошную графическую консоль через браузер. Через этот же порт идут REST-запросы к базе от клиентского программного обеспечения, которое мы установим на следующем шаге.
Установка клиента (Python)
Для того, чтобы импортировать базу Wordnet в Neo4j, воспользуемся скриптом на Питоне.
1. Сначала нужно установить библиотеку py2neo
pip install py2neo
2. Скачайте с гитхаба мой скрипт
mkdir habrawordnet2neo4j
cd habrawordnet2neo4j
git clone https://github.com/sergey-zarealye-com/wordnet2neo4j.git
Скрипт вряд-ли претендует на промышленное качество кода, но если вы захотите поэкспериментировать с Neo4j из Питона, то просмотрите код, это поможет вам быстрее начать программировать.
Получение лексической базы данных Wordnet
На странице
Download проекта Wordnet предлагается скачать базу вместе с программным обеспечением для её просмотра. Но мы-то хотим использовать для просмотра Neo4j! Поэтому достаточно скачать только файлы с данными:
Разархивируйте файлы в доступное место.
Импорт данных в Neo4j
Лексические данные в Wordnet лежат в файлах по частям речи. Например, существительные находятся в файле data.noun; глаголы — в data.verb; а с другими частями речи я и не пробовал.
1. Импорт существительных
Для импорта существительных перейдите в директорию, куда поместили мои скрипты (мы ее назвали просто habrawordnet2neo4j) и выполните команду в консоли:
python wordnet2neo4j.py -i rwn3/data.noun --neo4j http://127.0.0.1:7474 --nodelabel Ruswordnet --reltype Pointer --encoding cp1251 --limit 1000
Давайте разберём параметры поподробнее.
-i путь к файлу данных Wordnet
--neo4j URL сервера базы данных Neo4j
--nodelabel Метка узлов, соответствующих словам Wordnet
в создаваемом графе (в Neo4j узлы графа снабжают
текстовыми метками; это просто идентификатор)
--reltype Тип ребер графа, соответствующих указателям Wordnet
(в Neo4j ребра графа могут иметь тип; это просто
идентификатор)
--encoding Кодировка файла данных; русскоязычная база записана
в кодировке cp1251; для англоязычных файлов этот
параметр не нужно указывать
--limit Максимальное количество обрабатываемых строк файла;
дело в том, что мой скрипт работает довольно медленно,
и чтобы попробовать можно ограничить объем импортируемых
данных, например первыми 1000 строками файла; для импорта
полного файла этот параметр не нужно указывать,
и приготовьтесь подождать час-полтора.
2. Импорт глаголов
Для импорта глаголов выполните команду в консоли:
python wordnet2neo4j.py -i rwn3/data.verb --neo4j http://127.0.0.1:7474 --nodelabel Ruswordnet --reltype Pointer --encoding cp1251 --limit 1000
Импортировать глаголы необязательно, хотя некоторые из них связаны с существительными, и это интересно поизучать.
3. Убедитесь, что данные импортированы
Для этого откройте в браузере консоль Neo4j (введите адрес и порт сервера СУБД) и введите следующий запрос:
MATCH (node)-[relation]-() RETURN node, relation LIMIT 100
Если получили в экране изображение графа, то все прошло успешно.
Выполняем простые запросы
Все дальнейшие действия будем выполнять в браузере, в консоли Neo4j. Я буду считать, что в качестве меток узлов вы использовали Ruswordnet, а в качестве типа рёбер Pointer (как указано в предыдущем разделе). И что вы импортировали именно русскую базу Wordnet
целиком.
1. Hello World
Как указано на сайте русской базы
Wordnet, переведены около половины смысловых единиц, содержащих самые общеупотребимые слова. Поэтому попробуем найти в базе первое, что пришло в голову:
MATCH (n:Ruswordnet {name: "выкапывание_трупа"}) RETURN n
Выполните запрос, убедитесь, что это понятие найдено, значит, по мнению российских лингвистов, оно входит в число самых общеупотребимых. Давайте разберём этот простой запрос.
Ключевое слово
MATCH означает примерно то же самое, что SELECT в SQL. Грубо говоря, «найти подходящие к шаблону элементы графа».
Круглыми скобками обозначаются узлы графа. Шаблон
(n:Ruswordnet) обозначал бы, что мы хотим найти все узлы с меткой «Ruswordnet». Здесь
n — идентификатор, можно сказать «переменная».
Узлы графа (и рёбра тоже) можно снабжать произвольными атрибутами. Чтобы найти конкретный узел, мы задали в запросе условие на атрибуты в формате, похожем на JSON:
{name: «выкапывание_трупа»}. Таким образом, фраза
MATCH (n:Ruswordnet {name: "выкапывание_трупа"})
означает, что из всего графа будут выбраны все узлы с меткой Ruswordnet и атрибутом name равным указанному там понятию.
Ключевое слово
RETURN говорит нам, какие переменные нас интересуют. В данном случае мы хотели просто увидеть узел (узлы), соответствующие заданным условиям, поэтому пишем
RETURN n. Важно понимать, что
n — это коллекция узлов, удовлетворяющих запросу. Чтобы убедиться в этом, просто замените понятие в запросе:
MATCH (n:Ruswordnet {name: "лев"}) RETURN n
Если вы импортировали базу Wordnet целиком, вы увидите шесть узлов понятий «лев». Давайте разберёмся, почему.
2. Переменные = коллекции
Выполним такой запрос:
match (n:Ruswordnet {name: "лев"})--(m) return n,m
Здесь мы задали уже более сложный шаблон для поиска. Мы хотим найти все узлы
(n), соответствующие понятию «лев», а также все узлы
(m), связанные с львами. Связь, т. е. ребро графа обозначается двумя дефисами. Можно в явном виде указывать интересующее нас направление символом --> (это я и называл ASCII art).

Если у вас не отображаются имена смысловых единиц, нажмите на кнопку Ruswordnet(23) в левом верхнем углу графа, и в строке состояния внизу консоли выберите «name» в поле Caption. Так будет нагляднее.
Теперь мы поняли, что лев это, оказывается не только болгарская валюта (bulgarian_money), копейкой для которой является стотинка, но и большая кошка, и созвездие, астрологический знак, и что-то, связанное с гордостью.
3. Подключаем рёбра
В базе Wordnet ребра называются указателями (Pointer), и используется большое количество лингвистических типов указателей. Они обозначаются символами, некоторые из которых я привожу в таблице:
| Символ |
Английское наименование лингвистического отношения |
Лингвистическое отношение |
|---|
| ! |
Antonym |
Антоним |
| @ |
Hypernym |
Обобщение |
| @i |
Instance Hypernym |
Экземпляр обобщения |
| ~ |
Hyponym |
Уточнение |
| ~i |
Instance Hyponym |
Экземпляр уточнения |
| #m |
Member holonym |
Понятие, включающее в себя данное понятие |
| #s |
Substance holonym |
Вещество, из которого состоит предмет |
| #p |
Part holonym |
Предмет, включающий в себя как часть данный предмет |
| %m |
Member meronym |
Часть более общего понятия |
| %s |
Substance meronym |
Из какого вещества состоит предмет |
| %p |
Part meronym |
Часть предмета |
| = |
Attribute |
Атрибут |
| + |
Derivationally related form |
Производная форма |
В процессе импорта мы присвоили рёбрам графа атрибут pointer_symbol, и теперь можем делать запросы с учётом атрибутов рёбер. Давайте разберемся, что такое обобщение (hypernum):
MATCH (n:Ruswordnet {name: "лев"})-[p:Pointer {pointer_symbol: "@"}]->(m)
RETURN n,m
Квадратными скобками обозначаются спецификации рёбер. В этом запросе мы хотим найти рёбра типа Pointer, атрибут которых pointer_symbol равен «@» т. е. символу обобщения. Кстати, противоположный обобщению символ уточнения «~».
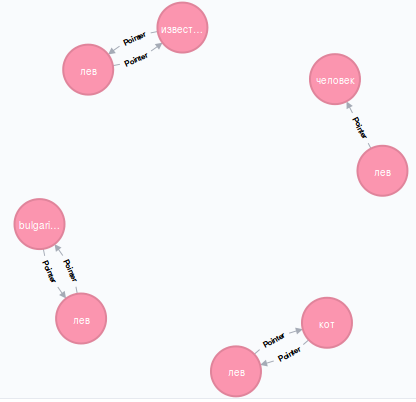
Теперь понятно, что обобщение для льва это кот, а также человек. Конечно, речь идет о разных смысловых единицах: лев (кот) это один узел графа, а лев (человек) — другой узел, соответствующий знаку зодиака. Лев (известность) — это результат плохого перевода на русский; имеется в виду лев (celebrity), т. е. знаменитость, светский лев.
Давайте разберемся, что такое part holonym:
MATCH (n:Ruswordnet {name: "лев"})-[p:Pointer {pointer_symbol: "#p"}]->(m)
RETURN n,m
А, теперь понятно: лев входит в зодиак в качестве составной части, значит зодиак является part holonym для льва.
Из таблицы видно, что Wordnet содержит много интересных отношений, например, из каких веществ что сделано. К сожалению, нет информации, что лев сделан из мяса, поэтому поставим вопрос по другому: найти такие узлы графа, которые связаны отношением «из какого вещества сделано».
MATCH (n)-[p:Pointer {pointer_symbol: "#s"}]->(m)
RETURN n,m LIMIT 10
В этом запросе мы не накладываем никаких условий на узлы
(n) и
(m). Мы только хотим, чтобы их связывали рёбра с атрибутом «#s». Обратите внимание, появилось ключевое слово
LIMIT, знакомое нам из SQL. Если бы его здесь не было, сервер вернул бы нам очень много результатов, и плохо было бы нашему браузеру.
В результате запроса мы узнали, что сигареты состоят из марихуаны, а суп из воловьих хвостов — из воловьих хвостов.
4. Цепочки произвольной длины
В детстве все играли в такую игру: превратить муху в слона. Для этого нужно было менять по одной букве в слове, пока слово МУХА не превратилось в слово СЛОН. Давайте узнаем в лексическом графе, связаны ли между собой ЛЕВ и ОВЦА.
MATCH (n:Ruswordnet {name: "лев"})-[p:Pointer*1..3]-(m:Ruswordnet {name: "овца"})
RETURN n,m,p
Конструкция
[p:Pointer*1..3] говорит, что требуется найти цепочку рёбер типа Pointer длиной от одного до трех, связывающую узел «лев» с узлом «овца».

Это отличается от классической детской игры, но тоже интересно: ОВЦА — ПРОСТАК — ЧЕЛОВЕК — ЛЕВ… это звучит гордо. Кстати, можно попытаться найти связь и между мухой и слоном, только немного увеличить предельную длину цепочки. Я использовал значение 6. Кстати, не пытайтесь сразу поставить 100 — процесс поиска скорее всего сорвется т. к. число вариантов для перебора путей в графе будет слишком велико. Итак, вот как связаны слон и муха лексически:
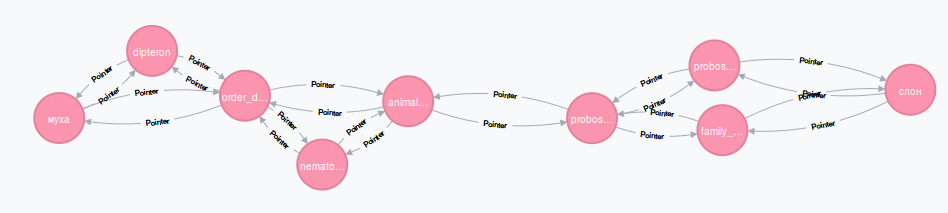
Думаю, на этом этапе вы многое поняли о базе данных Neo4j, и способны самостоятельно открыть много интересного в базе данных Wordnet, а может применить Neo4j в своих проектах. Мы применяем связку Neo4j c Wordnet в системе поиска по киноархивам. Если вы хотите заниматься исследованиями в области машинного обучения, приглашаю на стажировку или на постоянную работу в НИКФИ — научно-исследовательский кинофотоинститут.