Использование NLP для построения классификатора сарказма
- среда, 2 сентября 2020 г. в 00:29:36
В этой статье мы попробуем написать классификатор определяющий саркастические статьи используя машинное обучение и TensorFlow
Статья является переводом с Machine Learning Foundations: Part 10 — Using NLP to build a sarcasm classifier
В качестве обучающего набора данных используется датасет «Sarcasm in News Headlines» Ришаба Мишры. Это интересный набор данных, который собирает заголовки новостей из обычных источников новостей, а также еще несколько комедийных с поддельных новостных сайтов.
Набор данных представляет собой файл JSON с тремя столбцами.
is_sarcastic — 1, если запись саркастическая, иначе 0headline — заголовок статьиarticle_link — URL-адрес текста статьиЗдесь мы просто рассмотрим заголовки. Итак, у нас есть очень простой набор данных для работы. Заголовок — это наша особенность, а is_sarcastic наш ярлык.
Данные в JSON выглядят примерно так.
{
"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5",
"headline": "former versace store clerk sues over secret 'black code' for minority shoppers",
"is_sarcastic": 0
}Каждая запись представляет собой поле JSON с парами имя-значение, показывающими столбец и связанные данные.
Вот код для загрузки данных в Python
import json
with open("sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
urls = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link'])Разберем этот код. Во-первых, import json позволяет использовать парсеры json в Python. Затем мы открываем файл sarcasm.json. Используя метод json.load(), мы можем все загрузить и проанализировать. Далее инициализируем массивы для предложений, меток и URL-адресов. И теперь можно просто пройтись по хранилищу данных. И для каждого элемента добавляем его заголовок, метку сарказма и URL-адрес в соответствующий массив.
Следующий код выполнит токенизацию и упорядочивание набора данных.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(oov_token="")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(len(word_index))
print(word_index)
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding='post')
print(padded[0])
print(padded.shape)Создаем токенизатор и сопоставляем его предложениям. В данном случае предложения представляют собой большой массив из более чем 25 000 предложений, которые мы читаем из набора данных сарказма. Можно использовать токенизатор для вывода word_index который нам покажет какие слова были выучены из набораданных. А вот пример некоторых слов.
... 'blowing': 4064, 'packed': 4065, 'deficit': 4066, 'essential': 4067, 'explaining': 4068, 'pollution': 4069, 'braces': 4070, 'protester': 4071, 'uncle': 4072 ...Теперь можно превратить все наши предложения в последовательности, в которых вместо слов будут токены, представляющие эти слова. Все предложения будут иметь длину самого длинного из них, а все что короче, будет дополнено нулями в конце предложений, чтобы сохранить их одинаковую длину.
[ 308 15115 679 3337 2298 48 382 2576 15116 6 2577 8434
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
(26709, 40)Это первое предложение после токенизации и заполнения. Оно короче, поэтому заканчивается кучей нулей. Нижнее значение означает что у нас есть 26 709 дополненных предложений, и каждое из них имеет длину 40 значений.
С помощью всего нескольких строк кода мы загрузили данные из датасета в массивы предложений, токенизировали и дополнили их.
Далее в коде будут использоваться следующие параметры
voiceab_size = 10000
embedding_dim = 16
max_length = 100
trunc_type = 'post'
padding_type = 'post'
oov_tok = ""
training_size = 20000У нас есть 26 000 предложений их которых 20 000 будут использоваться для обучения, значение training_size, а 6000 оставим для проверки.
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]Поскольку мы разделили данные на обучающий и тестовый наборы, мы должны сделать то же самое для дополненных наборов, вместо того, чтобы иметь один большой главный набор, который у нас был ранее.
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)Сначала мы создадим токенизатор и укажем количество слов, которое нам нужно, и какой должен быть токен вне словарного запаса. Мы приспособим токенизатор только к корпусу training_sentence. Это поможет нам точно отразить любое использование в реальном мире. Наши test_sentences можно протестировать на основе словаря, полученного из обучающего набора. Теперь мы можем создать набор training_sequences из набора training_sentences. Далее дополним их, чтобы получить набор дополненных обучающих предложений. То же самое проделаем для testing_sentences и для всех ярлыков.
Прежде чем мы сможем обучить модель, давайте взглянем на концепцию встраивания, которая помогает нам превратить тональность слова в число почти так же, как мы токенизировали слова ранее. В этом случае вложение — это вектор, указывающий в направлении, и мы можем использовать эти направления для определения значений слов. Я знаю, что все это очень расплывчато. Позвольте мне объяснить это визуально.
Например, рассмотрите слова «Bad» и «Good». Теперь мы знаем, что они имеют противоположное значение. Так что мы можем нарисовать их в виде стрелок, указывающих в противоположных направлениях.

Тогда мы могли бы описать слово «meh» как нечто плохое, но не совсем такое уж плохое. Так что это может быть такая стрелка.
И тогда фраза «not bad», она не так сильна, как «Good», но более или менее в том же направлении, что и хорошо. Итак, мы могли нарисовать его такой стрелкой.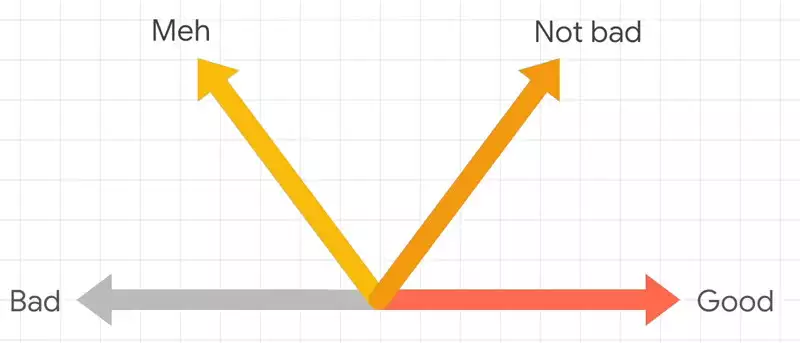
Если мы затем нанесем их на график, мы сможем получить координаты этих стрелок. Затем эти координаты можно рассматривать как вложения для тональности этих слов.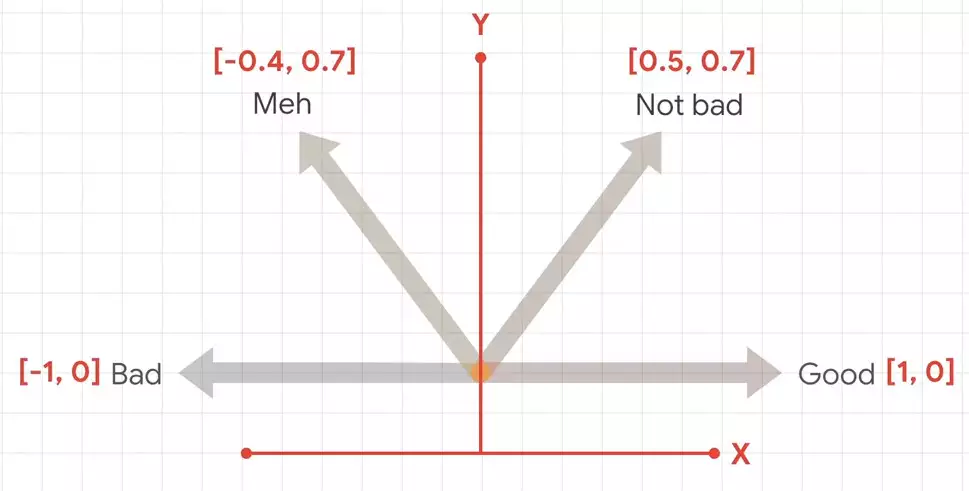
Абсолютного значения нет, но значения относительно друг друга мы можем установить.
Чтобы сделать это в коде, мы можем просто использовать слой Keras, называемый Embedding.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])Embedding должно быть определено как вектор для каждого слова. Итак, мы возьмем слова размером со словарь, а затем определим, сколько измерений мы хотим использовать в направлении стрелки. В данном случае это 16, которые мы создали ранее. Таким образом, слой Embedding будет изучать 10 016 размерных векторов, где направление вектора определяет тональность слова. Сопоставив слова с метками, у него будет направление, в котором он сможет начать учиться.
После того как мы определили модель, мы можем обучить ее следующим образом.
num_epochs = 30
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)Мы просто указываем функции и метки training_padded, а также валидационные данные.
Вот и все, весь код доступен на Google Colab, где вы можете с ним поиграть.