https://habrahabr.ru/company/yandex/blog/341710/- Интерфейсы
- Open source
- JavaScript
- Ajax
- Блог компании Яндекс
Паттерны
инверсии контроля (dependency inversion, DI) известны уже давно, но пока не нашли широкого распространения в мире фронтенда. Этот доклад отвечает на вопрос о том, как за счет возможностей JS построить надежную архитектуру на основе DI-контейнера. Автор доклада — Евгений
ftdebugger Шпилевский, руководитель группы разработки интерфейсов в Яндекс.Коллекциях.
— Насколько мне известно, инверсия зависимостей, DI-контейнеры и прочие паттерны, придуманные еще в 70-е годы, не очень плотно вошли в мир разработки фронтенда. На это наверняка есть причина. Отчасти дело в том, что многим людям непонятно, зачем они вообще нужны.
Я попытаюсь объяснить, что такое DI, что такое инверсия зависимостей, чем она может помочь вам в проекте и какие приятные бонусы вы можете получить, если начнете ее использовать.
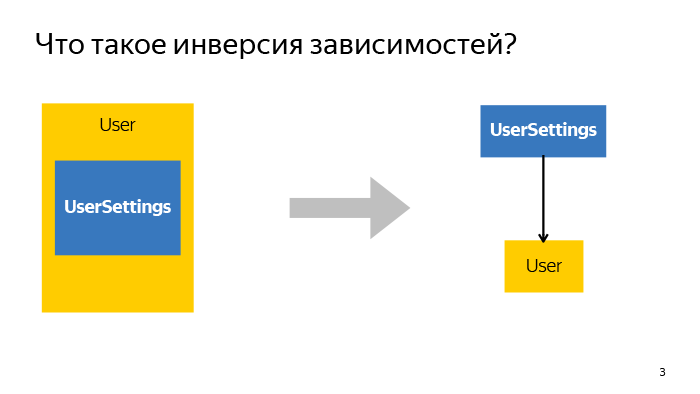
Для начала самая базовая концепция. Что такое инверсия зависимостей? Когда мы занимаемся проектированием любой фичи, мы хотим декомпозировать ее до такого маленького состояния, чтобы конкретный отдельный класс выполнял строго одну функцию и не более того.
В примере на слайде есть User и UserSettings. Все, что относится к настройкам пользователей, было вынесено в отдельный класс. Как это можно сделать? Есть два подхода: создать инстанс такого класса внутри или принять его снаружи. В этом и заключается основной принцип инверсии зависимостей. Если мы создаем какие-то инстансы снаружи и затем передаем вовнутрь, мы получаем некоторое преимущество.


На самом деле причина одна — мы больше не опираемся на конкретную реализацию, а начинаем опираться исключительно на интерфейсы. Когда мы говорим, что какая-то маленькая декомпозированная функция вынесена в отдельный класс, нам уже становится неважно, как она была реализована. Мы просто можем ее использовать, и неважно, какой инстанс какого класса будет подсунут, если интерфейсы совпадают. А так как интерфейса в JS нет, то из большего метод вызывается и хорошо.

Пример с UserSettings немного вырван из контекста, вряд ли это код, который вы пишете каждый день.
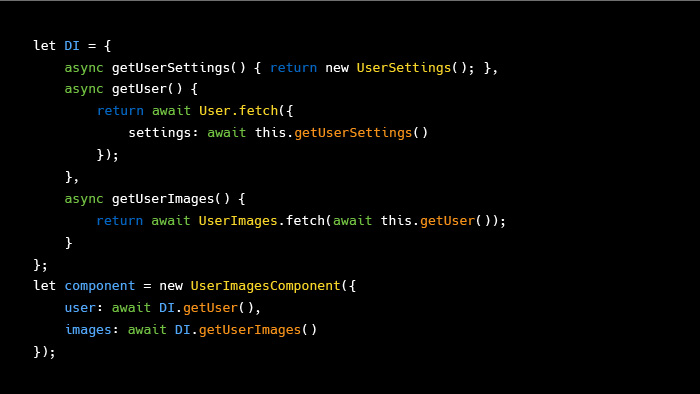
Чуть более приземленный код, приближенный к реальности и реалиям JS, — синхронный. Если мы хотим создать модель данных, нам необходимо откуда-то эти данные получить. Один из способов, самый распространенный — сходить по Ajax на сервер, получить синхронно данные, создать их.
Если мы начинаем писать этот код в стиле инверсии зависимостей, то получаем примерно такое. Мало того, что данный код написан не самым оптимальным образом, он еще и довольно монстрообразен. Мы вроде хотели всего один компонент, который выведет список картинок нашего пользователя, а кода для этого нам потребовалось написать вот столько.
В реальном проекте счет компонентов идет на десятки, и такая сборка даже на страницу будет довольно монстрообразной.
Что можно сделать? Сделать код еще хуже. Мы можем сделать наш первый DI-контейнер, самый примитивный, в лоб. Мы возьмем все, что писали раньше, и упакуем в методы. Поместим их в хеши, которые назовем DI, и будем считать это DI-контейнером. Тогда мы получаем первый шаг к тому, чтобы сделать наше будущее немного лучше.
Суть в том, что в любой момент времени, когда вам потребуется пользователь, настройки, картинки или какой-то из сотен других методов, которые могли бы быть здесь описаны, вы можете взять DI, вызвать его, и вам будет неважно, каким образом он был сконструирован.
Весь код, который отвечает за построение ваших моделей, классов, компонентов будет изолирован в одном контейнере. Естественно, писать код таким образом будет сложно, этот файл быстро станет большим. В нем уже сейчас есть проблемы. Кто немного поизучает код, найдет, что, по меньшей мере, пользователь загружается дважды. Это плохо, такого надо избегать.
Помимо этого, весь код шаблонный. Мы можем заменить его использованием каких-то функций. И можем написать собственный контейнер, который решит все наши проблемы, будет классный, быстрый. Все, что захотите.
Вот что я от него захотел.

Он должен сам искать классы. Их нужно откуда-то импортировать, потом создать, использовать. Я этого не хочу, пускай контейнер сам этим занимается.
Я хочу, чтобы он асинхронно создавал инстансы. Если мы изначально поставим такое требование к контейнеру, у нас не возникнет проблем с тем, как мы в дальнейшем будем создавать инстансы, будут ли они ходить в Ajax, будет ли на это тратиться время или нет, или же они будут ходить синхронно. Если создание идет асинхронно, все уже предусмотрено.
Повторное использование. Это очень важно. Если мы начнем писать большой контейнер и не будем повторно использовать в нем инстансы, мы рискуем получить множество бесполезных ненужных запросов к серверу. Этого хочется избегать.
Последний пункт. Я почти уверен, что императивный обычный код, который я продемонстрировал на предыдущем слайде, никому не понравился. Вместо него я хочу писать обычный декларативный JSON, в котором это все было бы описано, и у меня все работало бы.

Узнаем шаг за шагом, как можно каждую проблему решать.
Как мы можем научить динамически находить классы? Можно воспользоваться webpack, у него есть функция динамического импорта. Такой код, который кажется немного странным, вполне себе после бандлирования Webpack будет работать. Более того: все классы, которые попадут под эти условия, автоматически станут отдельными бандлами и начнут загружаться асинхронно. А весь наш код по загрузке класса будет выглядеть так. Мы просто синхронно просим получить класс и получаем его. Функция getClass может выглядеть абсолютно так, как вам хочется. Если вы хотите какие-то зависимости загружать статически — можете их написать здесь. Хотите более умное бандлирование — можно его здесь описать. Все это, в общем и целом, up to you.

Есть два способа создавать инстансы. Можно придумать жуткую конфигурацию того, как это будет происходить, или ввести какую-то конвенцию. Мне нравится путь с конвенцией, потому что не надо кодить, надо просто что-нибудь запомнить и затем всегда следовать этим нормам.
В данном случае я ввожу следующую конвенцию: у любого класса должен быть статический метод factory. Он будет отвечать за то, как этот класс будет построен, какие в него будут проброшены зависимости. Он отвечает за все.
CreateInstance получился очень простым, фабрика может быть как синхронной, так и асинхронной. Ну а код, чтобы банально создать пользователя, стал другим, но все еще страшненьким.

Повторное использование инстансов. Чтобы этого достичь, мы вводим новое понятие. Любому инстансу, который создан в рамках DI-контейнера, мы будем присваивать идентификатор. Мы будем придумывать эти идентификаторы, они будут описывать какие-то сущности из нашей системы. В данном случае на последней строке мы опишем текущего пользователя. Мы получим каким-то образом класс ранее написанной функции, создадим от него инстанс и положим в кэш.
В данном примере допущена пара багов. Полная реализация метода СreateInstance с учетом кэша занимает примерно 100 строк. Кому интересно,
может потом его почитать.

Последнее — зависимости. Мы опишем обычный хэш, где ключами будут идентификаторы из DI-контейнера, а значениями — конфигурация, с помощью которой мы сможем создавать все вышеописанное. Возьмем и создадим класс UserSettings. В currentUser мы возьмем класс user, засунем его в качестве зависимостей в UserSettings. А что такое UserSettings? То, что мы раньше объявили.
Описав такую структуру, можно разработать нехитрый алгоритм, который пройдется по всему дереву с зависимостями, которое образуется. На самом деле там граф образуется по этому дереву. Такой алгоритм соберет нам все, что необходимо.
Чтобы уменьшить количество шума на слайде, я введу другую конвенцию.

Почему бы не писать не в JSON, а в чем угодно, и почему бы не описать все в более простой форме? Если нужен класс — возьмем просто строкой, если хотим класс и зависимости — используем массив. Неважно, какой вы выберете формат. Главное, чтобы он был вам приятен и вы понимали, что здесь происходит. Это тот же слайд, только переписанный.

В итоге, если мы это все реализовали, собрали, мы получим автоматическое бандлирование. Здесь вы получите такую интересную опцию, что если вы запрашиваете текущего пользователя, то ваш DI-контейнер сможет одновременно загружать бандл, содержащий этот класс, и уже асинхронно загружать зависимости, которые ему необходимы. Дело в том, что теперь он располагает информацией, где класс расположен — возможно, в каком-то бандле — и какие зависимости ему будут нужны. Приземленный пример: если мы хотим сделать компонент, который будет выводить список картинок, то JS, где лежит код, который рисует эти компоненты с картинками, у нас еще только будет прогружаться, и в этот же момент может пойти запрос на сервер за данными. Когда они оба наконец выполнятся, мы получим это.
Это можно получить, просто используя DI-контейнер, больше ни в чем нет необходимости. У нас простота доставки зависимостей. Когда вы только начинаете пользоваться DI-контейнером по полной, у вас там начинает оказываться вообще все из вашего мира: все либы, все общие утилиты, компоненты, модели данных. И если в какой-то момент вам необходимо что-то получить, вы можете просто описать одну строчку зависимостей, и не заботиться о том, как она должна создаваться, конфигурироваться, описывать целиком сложный процесс, который должен пройти все стадии. Вы просто получите его из контейнера в качестве зависимости.
Переиспользование кода. Если мы начинаем писать так, что ни в каком отдельно взятом классе мы явно не создаем инстансы других классов, то мы перестаем быть завязаны на реализацию. Мы можем подсовывать какие угодно инстансы в класс в качестве зависимостей. В рамках того же компонента картинок мы можем подгружать какие угодно картинки и откуда угодно их подсовывать. В рамках контейнера это все будет отличаться просто строчкой в конфигурации. Вы просто возьмете другую зависимость и все, для вас это будет очень просто.

Как только контейнер закрепляется у вас в проекте на очень важном месте, вы его начинаете использовать просто как основу всего. Я хочу продемонстрировать, как можно сделать обычную многостраничную SPA, используя DI-контейнер.
Мы возьмем какой-то Router. Реализация его не важна. Важно, что когда он сматчится на какой-то url, он назначит этой странице какое-то имя. В данном случае, возможно, home и profile.
Возьмем наш контейнер и опишем там в качестве ключей home и profile. Опишем все, что мы не хотим там получить. А хотим мы получить какой-то компонент, который мы возьмем и вставим в body. В данном случае это какой-то Layout. Layout используется и там, и там, просто в него подкладываются разные зависимости. Как быть дальше? Какие компоненты будут глубже идти, уже на этом этапе неважно, потому что они уже как-то работают, кто-то их настроил. Нам важен только тот уровень абстракции, над которым мы работаем прямо сейчас.
Все, мы можем из DI-контейнера по ключу, по имени страницы запросить какую-то зависимость. В данном случае это признак на Layout, и этот Layout уже будет содержать в себе все необходимые данные, все компоненты, все, что мы хотим сделать. Останется только добавить его к body.

Что насчет тестируемости всего этого? Как только мы начинаем это использовать, возникает такое обстоятельство, что классы не зависят от контейнера напрямую. Вы нигде и никогда не будете контейнер использовать напрямую в том смысле, что мне нужна такая зависимость, возьму и получу. Нет, скорее он будет лежать в самом низу архитектуры, в самом bootstrap вашего приложения, как и продемонстрировано на предыдущем слайде.
На самом деле, ваши классы от него никак не зависят, вы можете их брать откуда угодно и куда угодно портировать.
Все зависимости передаются при создании, и если мы говорим про тестирование, в этом месте мы можем легко подкладывать моки, фикстурные данные и все что угодно — просто потому что уже так и работает. DI-контейнер заставил нас так писать код, чтобы все работало именно так.

Немного примеров. При создании, когда мы занимаемся тестированием и хотим промокать настройки пользователей, чтобы они делали ровно то, что мы хотим, а не то, что у них написано, мы можем создать пользователя, подсунуть под него тестовые данные. Мы можем для этого воспользоваться контейнером — уже сформировано дерево зависимостей, мы можем переопределить какие-то из них. В дальнейшем просто по своей логике работы с DI все, кто когда-либо хотел получить UserSettings, их получат, где бы они ни были. Мы и для тестирования можем его использовать.

Есть еще один интересный пример. Если предположить, что все модели данных, которые ходят куда-то на сервер за данными, будут для этого использовать некоторый ajaxAdapter, написанный специально, то во время тестов мы можем подменить его на наш собственный класс TestAjaxAdapter, который может реализовывать логику. Именно так оно реализовано, например, в синоне, если кто-то пытался мокать с его помощью.

Или мы можем пойти даже глубже. Мы реализовали в этом адаптере такую логику, чтобы при первом использовании в тестах он начинал записывать запросы и ответы от настоящего сервера, а при повторных запусках он просто воспроизводит его из кэша. Этот кэш мы добавляем в репозиторий к нашим тестовым данным. И когда мы хотим сделать тестирование на фикстурах и боимся, что они со временем будут меняться от того, что здесь уже реализована логика общения с сервером, мы подменяем TestAjaxAdapter. В репозитории образовывается какой-то кэш, который потом будет переиспользоваться.

Как это можно использовать еще интереснее? Здесь уже упоминали про
Gemini-тестирование. Это один из видов визуально регрессивного тестирования. Кто не знает, Gemini — способ тестирования, при котором мы делаем скриншот какого-то нашего блока на готовой странице, помещаем его к тестовым данным в репозиторий, а когда мы хотим делать обратный тест, мы заново запускаем, заново делаем скриншот и попиксельно его сравниваем. Если где-то пиксели не совпали — тест упал. Это очень простой и эффективный вид тестирования, проверки визуальных регрессов. Мы же работаем с CSS, в нем есть особенность: он постоянно ломается. Gemini помогает нам избавляться от этих поломок.
Что мы сделали в этом месте? Так как все было реализовано через DI-контейнер, мы специально подготовили сервер, которому можно было передать в качестве параметров идентификаторы из DI-контейнера. Он его просто формировал, отрисовывал на странице в одиночестве этот компонент, который мы хотели. В данном случае здесь что-то связано с рецептами, какая-то карточка, реальные данные, на которых были прогоны тестов, настоящий скриншот.
После прогона теста были подменены ajaxAdapters, и образовывался кэш, связанный с тем, как общался сервер. У нас эти данные — постоянно воспроизводимые со временем, и тесты становятся стабильными.
Такой подход применим к любым видам тестов. Если вы хотите покомпонентно зайти браузером в Selenium и пощелкать, ничто вам не мешает, потому что вы получаете полностью работающий кусочек функциональности, на которой вы хотите закоммититься. И вы даже можете делать несколько блоков одновременно, просто выводить их на страницу и кликать по ним. Между собой блоки имеют какие-то связи событийные или еще что-то. Даже если блоки не будут соответствовать настоящему сайту, вы таким образом сможете протестировать некоторую логику.
Я прочитал беглый доклад о том, что такое DI. Надеюсь, кого-то это заинтересовало. Если нужны подробности, я доступен по ссылкам:
почта,
GitHub,
Telegram,
Твиттер.
Вот ссылки, по которым можно найти новую информацию о том, что было здесь. Например, полностью реализованный DI-контейнер, о котором я говорил, DI-контейнер inversify — это очень прикольная штука для TypeScript. Здесь есть еще некоторые ссылки, чтобы понять, как все собрать вместе.
Спасибо.