https://habrahabr.ru/company/ruvds/blog/344970/- Разработка веб-сайтов
- Node.JS
- JavaScript
- Блог компании RUVDS.com
Сегодня публикуем вторую часть перевода материала, посвящённого разработке чат-ботов с использованием ChatScript и JavaScript. В
прошлый раз мы занимались, в основном, теорией. А именно, говорили о сценариях использования чат-ботов и о внутреннем устройстве CS-приложений. Сегодня будет больше практики. А именно, мы обсудим рабочее окружение ChatScript, поговорим об интеграции CS и JS, обсудим подходы к решению проблем, характерных для чат-ботов.
Окружение ChatScript
▍Интерфейс командной строки
ChatScript имеет интерфейс командной строки (CLI, Command Line Interface), который используется, в ходе разработки, как вспомогательное средство. В частности, он необходим для сборки чат-ботов.
Основная команда, которая понадобится в ходе работы — это, конечно,
:build. С её помощью, в первую очередь, нужно собрать нулевой уровень бота для использования концептов, предопределённых в системе (например —
~yes,
~timeinfo,
~number). Затем собирают всё то, что относится к конкретному боту, задавая в этой команде то же имя, которое использовалось для файла со списком топиков, применяющимся в скрипте.
Ещё одна полезная команда — это
:reset. Она возвращает бота в исходное состояние, и, кроме того, очищает все переменные для долговременного хранения данных (эти значения сохраняются даже после сборки).
Команда
:trace позволяет выполнить полную трассировку стека правил и топиков, вызванных в ходе разбора последней порции данных, полученных от пользователя.
Команда
:why предназначена для вывода правил, применение которых сказалось на последних выходных данных, сгенерированных ботом. Для переключения между пользователями применяется команда
:user, которая, в качестве параметра, принимает имя пользователя.
Команда
:quit позволяет остановить процесс ChatScript.
В процессе добавления новых правил полезно проверять, не нарушают ли они работу ранее созданных шаблонов. Для этого имеется весьма полезная команда
:verify. Разработчику, для того, чтобы ей пользоваться, нужно добавить перед каждым шаблоном набор фраз, которым он должен соответствовать. Синтаксис этих проверочных фраз выглядит так:
#! I want burger
#! I will take salad
#! I need icecream
u: BURGER (I {will} [want need take] ~food_type)
При выполнении команды будет выведен подробный отчёт о том, на каких фразах система успешно прошла проверку, а на каких — нет:
fastfood> :verify fastfood
VERIFYING ~fastfood ......
Pattern failed to match 1 ~fastfood.1.0: I need icecream => u: FOOD ( ^want ( _~food_type ) )
Adjusted Input: I need ice_cream
Canonical Input: I need ice_cream
1 verify findings of 3 trials.
▍Производительность
CS — это легковесный процесс, поэтому вполне можно запустить несколько его экземпляров на одном компьютере. Более того, такие операции, как сравнение шаблонов и поиск концептов, хорошо оптимизированы, работают они очень быстро и поддерживают множество подключений. Для того, чтобы проверить, действительно ли CS достаточно быстр, мы написали собственный небольшой бенчмарк, направленный на исследование производительности чат-бота под нагрузкой. Наш класс-обёртка, написанный на JS, отправляет набор из 10000 запросов и измеряет время, необходимое движку для того, чтобы на них ответить. Вот результаты этих испытаний:
Total messages count: 10000
Chunks count: 100
Chunks size: 100
Percentage of the requests served within a certain time (ms)
10%: 10
20%: 13
30%: 15
40%: 17
50%: 19
60%: 21
70%: 23
80%: 25
90%: 27
100%: 29
Time taken for tests: 19.972 seconds.
Requests per second: 500.70098137392347 [#/sec]
Time per request: 1.9972 [ms]
Показатель числа запросов в секунду оказывается меньше, чем можно было ожидать, учитывая время, затраченное на обработку одного запроса.
Происходит это из-за того, что группы сообщений отправляются асинхронно, с использованием промисов. Поэтому при умножении полученного числа запросов в секунду на общее число секунд, которое занял тест, мы получаем число, которое меньше 10000.
▍Непрерывная интеграция в CS
Когда вы работаете над ботом, расширяете его функционал, полезно периодически проверять, продолжает ли, с учётом последних изменений, нормально работать то, что было написано раньше. Такое, на самом деле, возникает довольно часто, особенно если создаваемые вами шаблоны являются слишком общими и могут соответствовать тем входным данным, соответствия с которыми вы не ожидали. Для того, чтобы справляться с подобными проблемами, в CS есть механизм регрессионного тестирования, которым можно пользоваться в процессе разработки. Для того, чтобы подготовить набор данных для регрессионного тестирования, нужно сделать следующее:
1. Создайте свежую сборку со стабильной версией чат-бота. Для этого в CLI CS нужно выполнить следующие команды:
./BINARIES/ChatScript local debug=":build 0" > /dev/null
./BINARIES/ChatScript local debug=":build food" > /dev/null
2. Создайте список со всеми фразами, которые вы хотите проверить в ходе выполнения тестирования. Вы можете поместить файл с ним куда угодно, но я предпочитаю хранить такие файлы в директории
REGRESS CS-проекта. В начале этого файла должна идти команда установки пользователя, используемого при тестировании, и команда
reset, которая позволяет очистить переменные долговременного хранения данных. В конце файла тоже надо вставить
reset. Для нашего чат-бота соответствующий файл может выглядеть так:
:user test
:reset
I want burger
I will take salad
I need ice-cream
:reset
3. Теперь нужно организовать вывод выходных данных, которые сгенерировал бот на основе тестового списка, в журнал. Система будет брать входные данные, отправлять их чат-боту и получать от него ответы. Команда должна включать в себя имя пользователя, который используется для выполнения регрессионного теста, и указание пути для сохранения выходных данных. Опять же, можно использовать любой путь, но я советую хранить эти выходные данные в директории
RAWDATA_YOURBOT. Для этой цели можно создать отдельную папку, в нашем случае использовалась папка
RAWDATA_FOOD/TEST. Сгенерировать выходные данные можно с помощью следующей команды:
./BINARIES/ChatScript local login=test_user source=REGRESS/food.txt > /dev/null
4. Инициализируйте файл для регрессионного теста (после завершения этой операции введите :
quit в консоли CS):
./BINARIES/ChatScript local login=test_user debug=":regress init test_user RAWDATA/FOOD/TEST/food.txt"
5. Проведите тест, и проверьте, прошла его система или нет:
./BINARIES/ChatScript local login=test_user debug=":regress RAWDATA/TEST/food.txt"
Практика разработки чат-ботов на CS
▍Разрешение коллизий в концептах
Занимаясь разработкой бота, рассчитанного на работу с входными данными, имеющими отношение к некоей теме, нужно создавать собственные концепты.
Полезно группировать лишь слова и фразы, связанные по смыслу. Это помогает повторно использовать концепты в различных шаблонах и позволяет заранее знать о значениях понятий в концепте. В идеале, если все используемые слова различаются, этот механизм работает отлично. Однако, при работе с большими списками терминов, некоторые слова могут появляться в различных концептах. Вполне нормальный подход заключается в том, чтобы не использовать эти концепты в одном шаблоне. Однако, мне пришлось работать с концептами, при совместном использовании которых, в одном из видов фраз возникали коллизии. Основная проблема заключалась в том, что мы, на самом деле, ничего не знали о порядке терминов из концепта во фразах. Именно поэтому мне пришлось использовать конструкцию вида
<< … >> для того, чтобы система находила совпадения со словами, расположенными в любом порядке:
u: ANY_ORDER_MATCH (I want << {_~concept_A} {_~concept_B} >>)
Вот как работает этот шаблон. После того, как движок CS находит первое значение в
~concept_A, он уже не выполняет его поиск в
~concept_B. Это даёт нам ошибки первого типа, или ложно-положительные совпадения. Так как из-за коллизии нельзя терять правильные значения, совпадения с которыми есть в системе, я нашёл три способа разрешения подобных проблем.
Первый способ состоит в исключении значений, которые вызывают коллизию между
~concept_A и
~concept_B. Однако, такой подход не окажется особенно полезным, если есть потребность в точных результатах распознавания фраз, так как некий набор значений будет потерян.
Второй подход заключается в том, чтобы предложить пользователям применять параметры в том же порядке, в котором они присутствуют в шаблоне. Подобным решением можно воспользоваться только в том случае, если имеется чёткий протокол общения с ботом, а пользователи заранее знают, когда используются те или иные фразы.
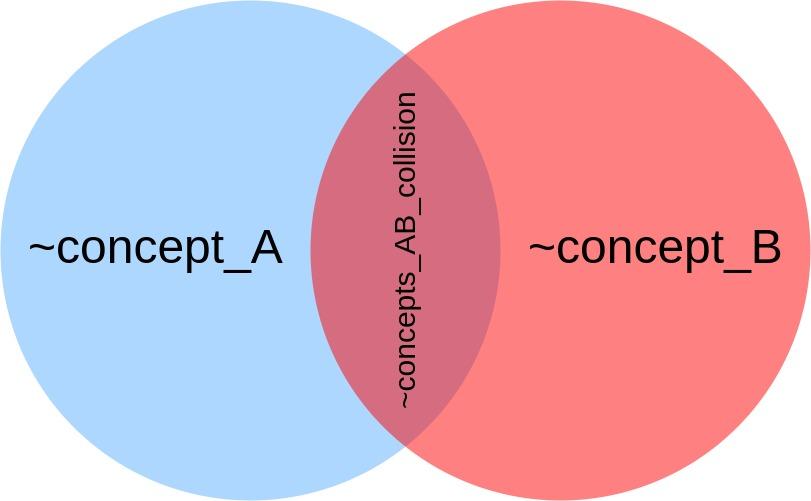 Коллизия концептов
Коллизия концептов
И, наконец, третий способ борьбы с коллизиями заключается в такой организации наборов терминов, когда все коллизии перемещают в отдельный концепт, а затем этот концепт добавляют к шаблону. Тогда можно узнать, соответствуют ли переданные боту данные коллизии между концептами или одному из концептов. Выглядит это так:
u: ANY_ORDER_MATCH (I want << {_~concept_A} {_~concept_B} {_~concept_A_collision} >>)
▍Несколько тем в одном чат-боте, или несколько тем в нескольких ботах?
В нашем проекте я столкнулся с непростой задачей реализации чат-бота для нескольких разных тем. К каждой из них могли относиться одни и те же фразы пользователя, но обрабатываться эти сообщения должны были по-разному в зависимости от темы, на которую идёт разговор с ботом. Я нашёл два варианта решения этой проблемы.
Первый вариант относится к уровню сообщений. Можно задать дополнительный префикс, который будет относиться к отдельной теме и добавлять его к каждому сообщению, которое должно быть обработано в контексте конкретной темы. Например, у нас имеется вегетарианский и обычный рестораны. В данном случае на вопрос вида «какие салаты у вас есть?» («which salads do you have?») следует давать разные ответы. Правила при таком подходе будут выглядеть примерно так:
u: (< vegetarian fastfood what salads)
We have $list_of_vegeterain_salads
u: (< common fastfood what salads)
We have $list_of_salads_with_meat
Видно, что фразы «vegetarian fastfood» и «common fastfood», указывающие, соответственно, на вегетарианскую и обычную кухню, будут добавлены к сообщению перед отправкой его в ChatScript. Основной плюс такого подхода заключается в том, что имеется лишь один экземпляр чат-бота, который будет обрабатывать фразы из всех возможных тем. Но, в то же время, это усложняет процесс разработки, так как размер скрипта увеличивается, его оказывается сложнее расширять и поддерживать. Кроме того, это, на каком-то этапе работы, может привести к дополнительным коллизиям между разными темами.
Второй вариант решения проблемы обработки одних и тех же высказываний на разные темы заключается в переносе схожих тем в различные чат-боты. При таком подходе, прежде чем запускать ботов на сервере, у каждого из них должны быть свои папки для хранения CS-сборок и данных пользователей. Каждый бот будет работать независимо, на собственном порту. Перед запуском каждого экземпляра нужно задать расположение папок со сборкой, данные о пользователях и номер порта в виде дополнительных параметров (например —
./BINARIES/ChatScript topic=./TOPIC_VEGETARIAN users=./USERS_VEGETARIAN port=1045).
Подобный подход, когда применяется несколько экземпляров бота, упрощает расширение каждого из них. Минус же заключается в дополнительной нагрузке на сервер.
Создатель ChatScript заявляет, что, на самом деле, нет нужды размещать разных ботов на разных портах, и я полагаю, что он прав. Боты могут существовать совместно, в одной сборке. В приложении, над которым я работал, применён подход с использованием разных портов для того, чтобы разделить экземпляры ботов и, если в этом возникнет необходимость, упростить отключение части реализованной в системе логики (например, если некоторым клиентам не нужна поддержка всех реализованных тем, для которых созданы боты). В результате, использование разных портов для разных ботов — приём необязательный, однако, в моём случае, был использован именно он, да и в похожих случаях его тоже вполне можно применить.
▍Обработка опечаток
В движок CS встроен механизм для обработки слов, введённых с ошибками. Обычно длинные слова могут быть распознаны даже если в них имеются опечатки. Однако, может случиться так, что часто встречающаяся ошибка в некоем слове движком не распознаётся. Существует несколько способов справиться с этой проблемой.
Первый подход заключается в описании слова внутри шаблона с использованием знака подстановки в той части слова, в котором может появиться опечатка:
u: TYPO_PATTERN (I [want need will] use first app*ach)
Этот шаблон, а именно — его часть «app*ach», будет соответствовать словам, начинающимся с «app» и оканчивающимся на «ach», при этом неважно — сколько между ними находится символов, и то, какие это символы. В результате этому правилу будут соответствовать и верные, и неверные, с точки зрения правильности написания слова, варианты.
Второй подход заключается в создании концепта для слова с часто встречающимися опечатками и включения в этот концепт всех вариантов таких опечаток. После чего данный концепт можно использовать в шаблонах вместо слова:
concept: ~frequency IGNORESPELLING [frequency ferquency freuqency]
topic: ~topic_with_typos keep repeat []
u: TYPO_CONCEPT (I know ~frequency of typo)
Обратите внимание на то, что я тут использовал флаг
IGNORESPELLING. Это позволяет избежать предупреждений об ошибках в концепте в ходе сборки бота.
Третий вариант подходит мне лучше всего. Заключается он в том, что можно расширить существующую базу исправлений движка. Для того, чтобы это сделать, нужно внести в файл
ChatScript_LIVEDATA_ENGLISH_SUBSTITUTES_spellfix.txt строки, содержащие слово и варианты написания этого слова с опечатками:
misspell mispell
После этого достаточно перезапустить движок.
▍Взаимодействие ChatScript с JavaScript
Средствами ChatScript легко реализовать логику обработки фраз и изучения информации о пользователе, но, в любом случае, если возможности CS нужны в некоем веб-проекте, нужно наладить связь с сервером, на котором запущен бот. К сожалению, CS не позволяет организовать обмен данными по HTTP. Однако, для этих целей можно воспользоваться TCP-сокетами.
При использовании Node.js-сервера, для того, чтобы установить соединение с ботом, нужно подключить пакет
net и, перед отправкой строки сообщения боту, особым образом её подготовить. В первую очередь, необходимо добавить к отправляемому сообщению префикс и постфикс. Префикс состоит из имени пользователя и имени макроса
outputmacro, используемого в управляющем скрипте. Между этими сведениями нужно использовать особые символы-разделители. В нашем примере используется
simplecontrol.top из чат-бота Harry, макрос называется
harry. Для того, чтобы с ботом можно было установить соединение, он должен быть запущен без параметра
local (по умолчанию он находится на порту 1024, но это можно изменить, воспользовавшись ключом вида
port=PORT_NUMBER, например —
./BINARIES/ChatScript port=1055).
Как правило, все подключения к чат-ботам из JS выглядят так:
const net = require('net');
const prefix = 'username\x00harry\x00';
const post = '\x00'
const client = new net.Socket();
client.connect(1024, '127.0.0.1', (err) => {
client.write(prefix + ‘some message’ + post);
});
client.on('data', (data) => response.toString());
Упростить подключение, добавив дополнительный уровень абстракции, можно с использованием методов объекта
Socket, написав на JS класс-обёртку для организации взаимодействия с CS. В подобном классе достаточно наличия асинхронного метода отправки данных и конструктора для установки имени хоста сервера и порта перед началом взаимодействия с движком CS. В качестве дополнительного параметра в подобный конструктор можно передать имя пользователя. CS умеет общаться с различными пользователями, так как он сохраняет состояние и хранит все данные, которые он узнал о пользователе, в долговременной памяти.
▍Архитектура интеграции CS и JS
Для того, чтобы чётко представлять себе то, как CS интегрируется с JS, и узнать об архитектуре веб-приложения на JavaScript, которое будет использовать ChatScript в качестве движка для распознавания сообщений пользователей, взгляните на следующий рисунок.
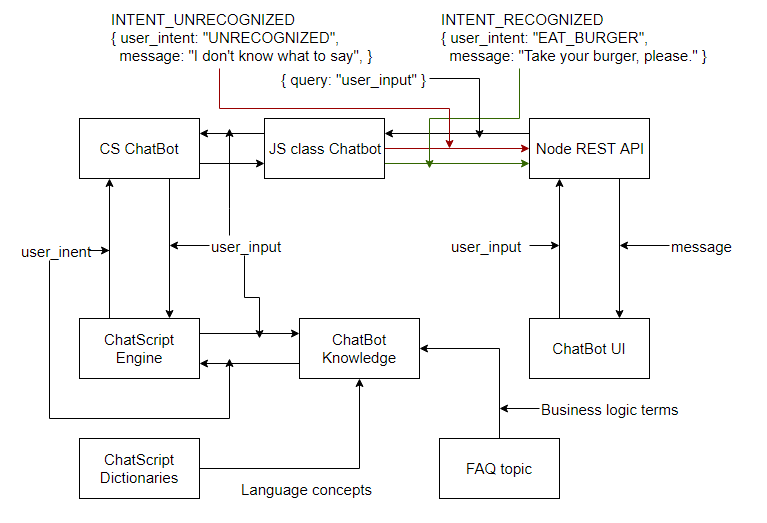 Архитектура приложения, использующего чат-бота на CS
Архитектура приложения, использующего чат-бота на CS
Как видите, процесс начинается в пользовательском интерфейсе. Эта часть системы зависит от того, какие именно технологии используются для реализации интерфейса чата, обеспечивающего взаимодействие пользователя с ботом. Затем идёт слой REST API (в нашем случае это — сервер на Node.js). На сервере REST API используется класс-обёртка для CS, написанный на JS, описанный выше. Именно эта часть системы отправляет чат-боту сообщения пользователя, используя TCP-сокеты, и обрабатывает ответы бота, который либо распознал сообщение, либо нет. Следующий компонент — это реализация чат-бота на CS, которая и выполняет распознавание сообщений. Тут может быть, например, один огромный топик, содержащий в себе все правила, или логика, реализованная в виде нескольких сущностей. Мы об этом уже говорили, ещё раз отмечу, что внутреннее устройство бота зависит от потребностей конкретного проекта. Для распознавания фраз пользователя и выдачи ответов чат-бот использует движок CS, где выполняется сравнение с шаблонами, поиск в базе знаний и в словарях. Кроме того, тут можно добавить дополнительную возможность: собственный концепт с терминами, связанными с предметной областью приложения. Это может понадобиться для того, чтобы чат-бот мог давать определения терминов и отвечать на часто задаваемые вопросы.
▍Отладка
После того, как в скрипте создано множество правил, может быть непросто выяснить, какое в точности правило было вызвано для обработки некоей фразы, в ситуации, когда два шаблона пересекаются. В данном случае создатель CS
советует использование конструкции
:verify blocking, которая позволяет получить сведения о пересекающихся топиках. Тут имеется ещё один удобный подход. Мне подошёл именно он. Я решил создать переменную, которая предназначена для хранения имени правила. Затем эта переменная просто присоединяется ко всему тому, что выдаёт бот. Как результат, можно сразу же видеть, какой из существующих шаблонов вызывает конфликт при обработке неких входных данных. В коде это выглядит так:
u: BURGER (I {will} [want need take] _~burger)
$rule = BURGER
$order = _0
^respond(~make_order)
u: DRINKS (I {will} [want need take] _~drink_type)
$rule = DRINKS
$order = _0
^respond(~make_order)
topic: ~make_order keep repeat nostay []
u: ()
Okay, you can take your $order. (Catched in rule $rule)
▍Структура проекта
В нашем маленьком примере весь код размещается в одном файле. Но, когда размеры подобного файла растут, имеет смысл разделить скрипт на части. Именно поэтому я решил создать отдельные директории для концептов (директория
CONCEPTS), ответов (
RESPONDERS) и тестов (
TESTS):
- FOOD
- CONCEPTS
- RESPONDERS
- TESTS
- food.top
- simplecontroll.top
Главный скрипт, в котором содержатся правила, связанные с одной категорией ответов, может быть заменён на пустой шаблон и на метод
^respond для вызова топиков из другого файла (в подобном топике должен использоваться флаг
nostay, так как, после обработки ответа, нам нужно вернуться в главный топик). Вот файл
food.top, в котором содержится главный топик:
# main topic in file RAWDATA/FOOD/food.top
topic: ~food keep repeat []
u: DRINKS ()
^respond(~drinks)
u: MEALS ()
^respond(~meals)
Вот пример файла со вспомогательным топиком:
# topic in file RAWDATA/FOOD/RESPONDERS/drinks.top
topic: ~drinks keep repeat nostay []
u: DRINK (^want(_~drink_type))
Ok, take and drink your _0 .
Если концепт включает в себя огромное количество терминов, их тоже можно объявить в разных файлах. Это упростит поддержку и расширение проекта.
# concepts in file RAWDATA/FOOD/CONCEPTS/food_concepts.top
concept: ~food_type [burger potato salad ice-cream vegan_'s_burger]
concept: ~drink_type [~alcohol ~non_alcohol]
concept: ~non_alcohol [cola juice milk water]
concept: ~alcohol [rum gean wiskey vodka]
Итоги
Из этого материала вы узнали всё необходимое для того, чтобы приступить к разработке собственного чат-бота на ChatScript с использованием сервера на Node.js, который играет роль промежуточного звена между пользовательским веб-интерфейсом и движком CS. Для того, чтобы лучше разобраться в CS, можете посетить
страницу проекта на GitHub.
Уважаемые читатели! Если вы прочли этот материал в поисках платформы для собственного чат-бота, расскажите пожалуйста, планируете ли вы использовать CS?
