HDB++ TANGO Archiving System
- вторник, 22 декабря 2020 г. в 00:33:31

Это система архивирования TANGO, позволяет сохранять данные полученные с устройств в системе TANGO.
Здесь будет описана работа с Linux (TangoBox 9.3 на основе Ubuntu 18.04), это уже готовая система где все настроено.
У меня ушло ~ 2 недели что бы разобраться в архитектуре и написать свои скрипты для python под это дело.
Позволяет хранить историю показаний Вашего оборудования.
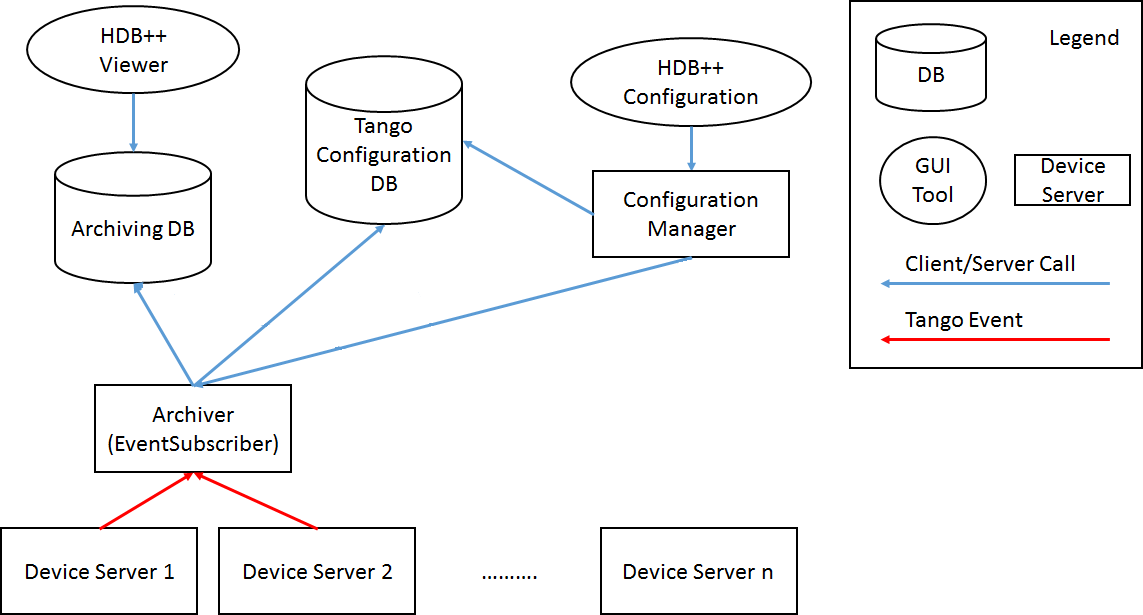
Здесь две самые важные вещи — это Archiver и Archiving DB. HDB++ Configuration графическая утилита для управления Archiver. HDB++ Viewer утилита просмотра Archiving DB.
Archiver опрашивает наши Device Server-а и записывает историю в Archiving DB.
Archiver это такой же Device Server:

Archiving DB в нашей системе базируется на MySQL, она находится в докере tangobox-hdbpp.

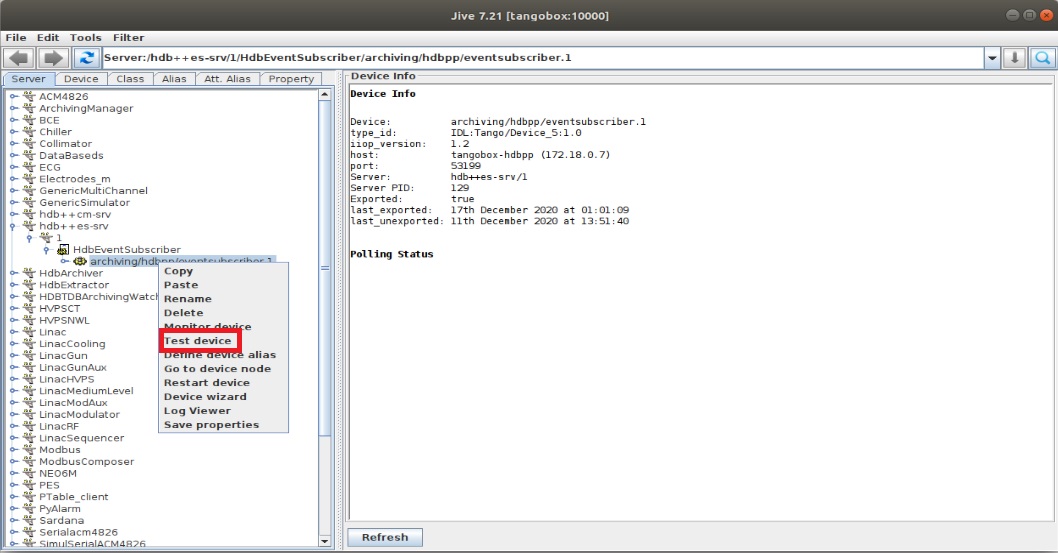
Посмотрим список команд этого сервера.
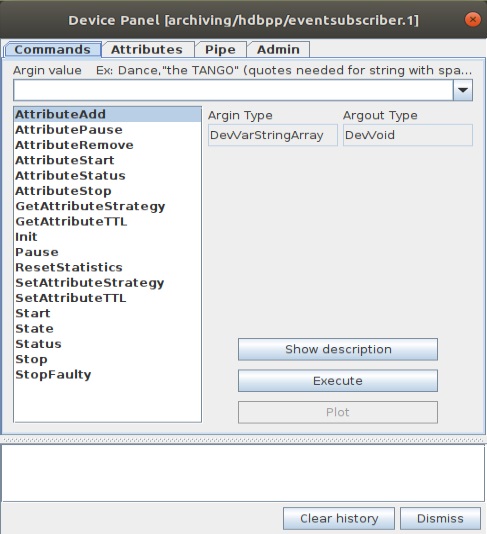
На картинке список команд управления этим Device Server-ом
Здесь нас интересуют:
Посмотрим через Jive список атрибутов за которыми следит Archiver:
jive
Дважды щелкаем на устройство.

Управнее этим Device Server-ом осуществляется через утилиту HDB++ Configuration, это графическая утилита которая отправляет выше показанные команды в archiving/hdbpp/eventsubscriber.1. Дальше будет показано как делать это программно.
hdbpp-configurator -configure
С помощью нее запускается/останавливается архивация и задаются параметры архивирования. Дважды щелкаем по атрибуту:
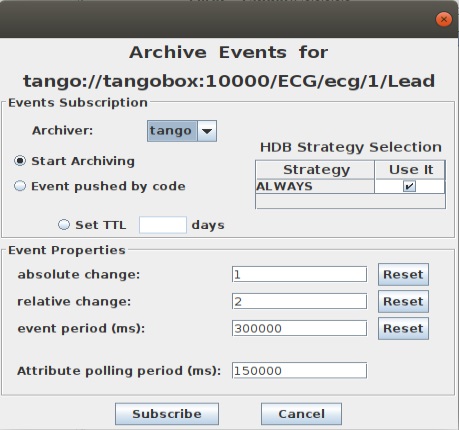
В ней нас будет интересовать БД hdbpp:
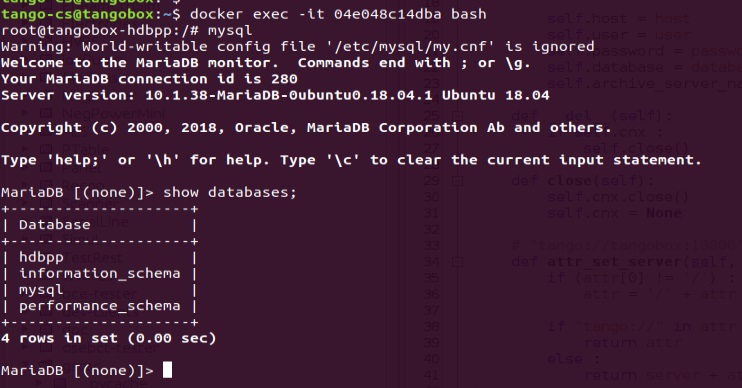
Так же потребуется настроить доступ к БД, с какой машины и кому разрешено подключаться (Потому что изучать как система была уже настроена мне было лень, легче задать своего пользователя.):
GRANT ALL PRIVILEGES on *.* to 'root'@'172.18.0.1' IDENTIFIED BY 'tango';
FLUSH PRIVILEGES;Наша основная система имеет адрес 172.18.0.1, docker с БД находится на 172.18.0.7.
Теперь перейдем к структуре БД, здесь основная таблица att_conf. В ней прописаны атрибуты которые попали в систему архивации:
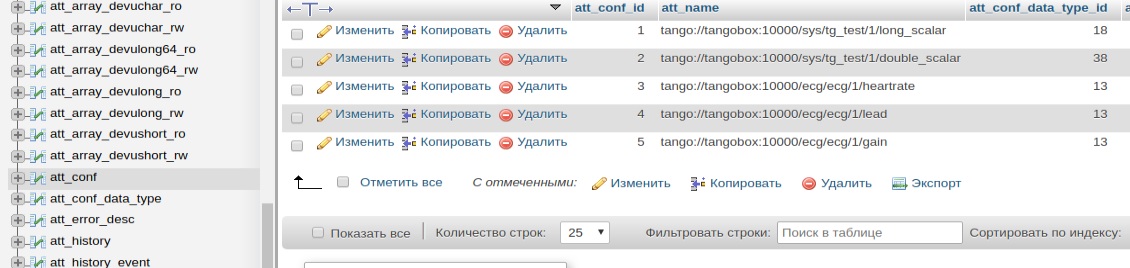
Здесь важные поля att_conf_id и att_conf_data_type_id. По att_conf_data_type_id из таблицы att_conf_data_type получим тип данных атрибута. Например scalar_devushort_ro, получив тип данных узнаем таблицу в которой хранится история. Имя таблицы будет att_scalar_devushort_ro, из этой таблицы по att_conf_id получаем архив данных интересующего нас атрибута.
Механизмы python для работы с HDB++.
Есть официальная библиотека для python2.7 для работы с HDB++ PyTangoArchiving. Разобраться с ней удалось только когда написал свою библиотеку. По ней не хватает документации, что передается в методы, какие типы данных, что передавать в аргументах (Это мое мнение).
Мой модуль создан для версии 3.7. Здесь все стандартные настройки для работы на TangoBox 9.3 заданы по умолчанию.
sudo python3.7 setup.py installЗависимости:
from hdbpp import HDBPP
if __name__ == '__main__':
hdbpp = HDBPP()
# Подключиться к серверу архивации и к БД с архивами.
if hdbpp.connect() == False :
exit(0)
# Получить историю атрибута за все время.
archive = hdbpp.get_archive('tango://tangobox:10000/ECG/ecg/1/Lead')
for a in archive:
print(a)
# Текущий статус архивации атрибута
ret = hdbpp.archiving_status('tango://tangobox:10000/ECG/ecg/1/Lead')
print(ret)
# Добавить атрибут на сервер архивации
hdbpp.archiving_add(['tango://tangobox:10000/ECG/ecg/1/Lead'])
# Начать архивацию атрибута
hdbpp.archiving_start('tango://tangobox:10000/ECG/ecg/1/Lead', 10 * 60 * 1000, 5 * 60 * 1000, 2, 1)
# где:
# 10 * 60 * 1000 - опрашивать и архивировать атрибут каждые мс
# 5 * 60 * 1000 - архивировать атрибут каждые мс, если значение вышло за порог
# 2 - порог изменения атрибута в единицах
# 1 - порог изменения атрибута в процентах
# Остановить архивацию атрибута
hdbpp.archiving_stop('tango://tangobox:10000/ECG/ecg/1/Lead')
# Закрыть соединение
hdbpp.close()Более подробная документация в коде.
Ее можно посмотреть например так:
pydoc3.7 hdbpp.HDBPPСтатью писал для себя, потому что спустя некоторое время начинаю забывать как и что делать.
Спасибо за внимание.