Генерируем странные кулинарные рецепты с помощью TensorFlow и рекуррентной нейронной сети (пошаговая
- пятница, 26 июня 2020 г. в 00:27:15
Я натренировал LSTM (Long short-term memory) рекуррентную нейронную сеть (RNN) на наборе данных, состоящих из ~100k рецептов, используя TensorFlow. В итоге нейронная сеть предложила мне приготовить "Сливочную соду с луком", "Клубничный суп из слоеного теста", "Чай со вкусом цукини" и "Лососевый мусс из говядины" .
Используя следующие ссылки вы сможете генерировать новые рецепты самостоятельно и найти детали тренировки модели:
В этой статье описаны детали тренировки LSTM модели на Python с использованием TensorFlow 2 и Keras API.
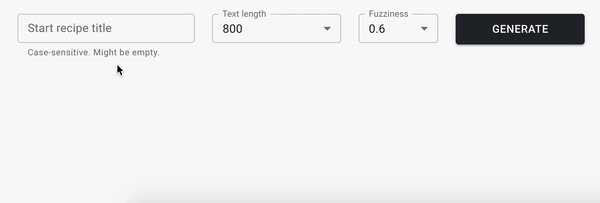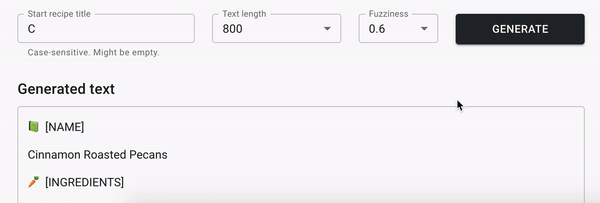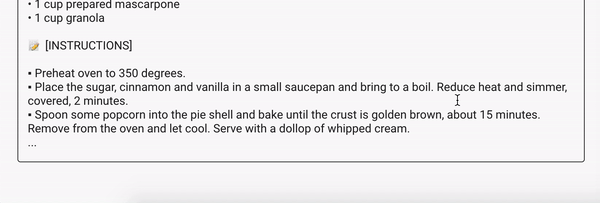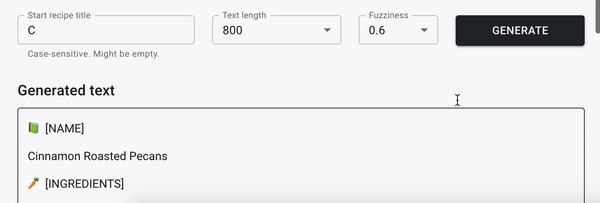
За несколько часов тренировки наша RNN модель выучит основы английской грамматики и пунктуации (вот бы самому так быстро учить языки!). Модель также поймет, что каждый рецепт состоит из трех частей: ◘ названия рецепта, ❖ ингредиентов и ✼ инструкции по приготовлению. Иногда модель будет генерировать довольно интересные комбинации продуктов, а иногда — глупые и смешные.
Вот несколько примеров сгенерированных рецептов (они на английском поскольку тренировочный набор данных был на английском):
◘ [NAME]
Orange Club Tea Sandwich Cookies
❖ [INGREDIENTS]
• 1 cup (2 sticks) unsalted butter, softened
• 1 cup confectioners' sugar
• 1/2 cup flaxseed meal
• 1/2 cup shelled pumpkin seeds (pecans, blanched and sliced)
• 2 teaspoons vanilla extract
✼ [INSTRUCTIONS]
︎ Preheat oven to 350 degrees F.
︎ Combine cake mix, milk, egg and sugar in a large bowl. Stir until combined and smooth but not sticky. Using a spatula, sprinkle the dough biscuits over the bottom of the pan. Sprinkle with sugar, and spread evenly. Bake for 20 minutes. Remove from the oven and cool on a rack. To serve, add the chocolate.Вот еще один пример:
◘ [NAME]
Mushrooms with Lentil Stewed Shallots and Tomatoes
❖ [INGREDIENTS]
• 1 tablespoon olive oil
• 3 cloves garlic, smashed
• Kosher salt
• 1 1/2 pounds lean ground turkey
• 1 cup coarsely peeled tart apples
• 2 tablespoons chopped garlic
• 1 teaspoon ground cumin
• 1/2 teaspoon cayenne pepper
• 1 teaspoon chopped fresh thyme
• 3/4 cup chopped fresh basil
• 1/2 small carrot, halved lengthwise and cut into 1/2-inch pieces
• 1 roasted red pepper, halved and sliced vertically diced and separated into rough chops
• 3 tablespoons unsalted butter
• 2 cups shredded mozzarella
• 1/4 cup grated parmesan cheese
• 1/4 cup prepared basil pesto
✼ [INSTRUCTIONS]
︎ Stir the olive oil, garlic, thyme and 1 teaspoon salt in a saucepan; bring to a simmer over medium heat. Remove from the heat. Add the basil and toast the soup for 2 minutes.
︎ Meanwhile, heat 4 to 4 inches vegetable oil in the skillet over medium-high heat. Add the olive oil, garlic, 1/2 teaspoon salt and 1/2 teaspoon pepper and cook, stirring often, until cooked through, aМодель умеет "писать" на узконаправленном кулинарном английском, придумывает имена рецептов, разбивает их на секции и даже использует списки внутри секций.
Первый недостаток модели, который может бросится в глаза — это то, что ингредиенты зачастую никак не связаны с инструкцией по приготовлению. Например в списке ингредиентов могут быть апельсины, но в пошаговой инструкции мы будем готовить лосося. Это будет следующим шагом по улучшению модели, в данной статье мы его опустим.

️ _На всякий случай отмечу, что рецепты в этой статье сгенерированы исключительно с обучающей целью. Эти рецепты не для готовки! Для готовки лучше используйте что-то более проверенное._
Предполагается, что читатель знаком с концепцией рекуррентных нейронных сетей (RNNs) и, в частности, с архитектурой Long short-term memory (LSTM).
Если эти концепции для вас незнакомы, я бы порекомендовал пройти курс Deep Learning Specialization на Coursera от Andrew Ng. Также статья Unreasonable Effectiveness of Recurrent Neural Networks от Andrej Karpathy может быть интересной и полезной в данном случае.
В общих чертах, рекуррентные нейронные сети (RNN) представляют собой класс глубоких нейронных сетей, наиболее часто применяемых к данным, основанным на последовательности, таким как речь, голос, текст или музыка. Они используются для машинного перевода, распознавания речи, синтеза голоса и т.д. Ключевая особенность RNN состоит в том, что они имеют внутреннюю память (state, состояние), в которой может храниться некоторый контекст для последовательности. Например, если первым словом последовательности было He, то RNN может предложить, что следующим словом будет speaks вместо speak, чтобы сформировать фразу He speaks, потому что предшествующее знание о первом слове He уже находится во внутренней памяти.

_Изображение взято с Wikipedia_

Изображение взято с Towards Data Science
Интересный момент заключается в том, что RNN (и LSTM в частности) может запоминать не только зависимости слово-слово, но и зависимости символ-символ! Не важно, что образует последовательность: это могут быть слова, могут быть символы. Важно то, что эти данные распределены во времени и идут один за другим. Например, мы имеем последовательность символов ['H', 'e']. Если мы спросим LSTM модель, какой символ может быть следующим, она может предложить <stop_word> (имея в виду, что последовательность, которая формирует слово He, уже завершена, и мы можем остановиться), или она может предложить l (имея в виду, что она пытается построить для нас последовательность Hello). Такой тип RNN называется символьной RNN (character-level RNN).
В этой статье мы воспользуемся умением рекуррентной сети запоминать контекст для последовательности и будем генерировать кулинарные рецепты, используя архитектуру LSTM на символьном уровне (модель будет учиться на последовательности букв, а не слов).
Давайте пройдемся по нескольким доступным наборам данных и исследуем их плюсы и минусы. Одними из требований, которым я хочу, чтобы набор данных соответствовал, это то, что каждый рецепт должен иметь не только список ингредиентов, но и инструкцию по приготовлению вместе с пропорциями.
Вот несколько наборов данных, который удалось найти:
Попробуем использовать набор данных "Recipe box". Количество рецептов выглядит достаточно большим, также он содержит как ингредиенты, так и инструкции по приготовлению.
Есть несколько способов, как вы можете экспериментировать с Python кодом данной статьи:
Я бы предложил воспользоваться GoogleColab, поскольку эта опция не требует никаких локальных установок (вы можете экспериментировать прямо в браузере), а также GoogleColab предоставляет поддержку GPU для обучения, что может значительно ускорить тренировку модели.
Давайте начнем с импорта библиотек, которые нам понадобятся в дальнейшем.
# Библиотеки для тренировки и работы с данными.
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import json
# Утилиты.
import platform
import time
import pathlib
import osДля начала давайте убедимся, что мы работаем именно со 2-й версией Tensorflow.
print('Python version:', platform.python_version())
print('Tensorflow version:', tf.__version__)
print('Keras version:', tf.keras.__version__)➔ вывод:
Python version: 3.7.6 Tensorflow version: 2.1.0 Keras version: 2.2.4-tf
Для загрузки данных воспользуемся утилитой tf.keras.utils.get_file. Использование get_file() для загрузки удобно, так как эта функция поддерживает кэширование данных. Это означает, загрузка файлов с данными произойдет только один раз, а затем, даже если вы запустите тот же блок кода в ноутбуке еще раз, он будет использовать кэшированные данные.
Создаем папку для кэша:
CACHE_DIR = './tmp'
pathlib.Path(CACHE_DIR).mkdir(exist_ok=True)Загружаем и распаковываем данные:
dataset_file_name = 'recipes_raw.zip'
dataset_file_origin = 'https://storage.googleapis.com/recipe-box/recipes_raw.zip'
dataset_file_path = tf.keras.utils.get_file(
fname=dataset_file_name,
origin=dataset_file_origin,
cache_dir=CACHE_DIR,
extract=True,
archive_format='zip'
)
print(dataset_file_path)Вот так выглядит путь к загруженным данным:
➔ вывод:
./tmp/datasets/recipes_raw.zip
Давайте посмотрим, что находится у нас в кэше:
!ls -la ./tmp/datasets/➔ вывод:
total 521128 drwxr-xr-x 7 224 May 13 18:10 . drwxr-xr-x 4 128 May 18 18:00 .. -rw-r--r-- 1 20437 May 20 06:46 LICENSE -rw-r--r-- 1 53355492 May 13 18:10 recipes_raw.zip -rw-r--r-- 1 49784325 May 20 06:46 recipes_raw_nosource_ar.json -rw-r--r-- 1 61133971 May 20 06:46 recipes_raw_nosource_epi.json -rw-r--r-- 1 93702755 May 20 06:46 recipes_raw_nosource_fn.json
Как видите, набор данных состоит из 3-х файлов. В дальнейшем нам необходимо объединить информацию из этих 3-х файлов в одну коллекцию.
Загружаем данные из json файлов:
def load_dataset(silent=False):
# Список файлов с данными, которые мы хотим объединить в один набор.
dataset_file_names = [
'recipes_raw_nosource_ar.json',
'recipes_raw_nosource_epi.json',
'recipes_raw_nosource_fn.json',
]
dataset = []
for dataset_file_name in dataset_file_names:
dataset_file_path = f'{CACHE_DIR}/datasets/{dataset_file_name}'
with open(dataset_file_path) as dataset_file:
json_data_dict = json.load(dataset_file)
json_data_list = list(json_data_dict.values())
dict_keys = [key for key in json_data_list[0]]
dict_keys.sort()
dataset += json_data_list
# Этот блок кода выводит превью с данными из каждого файла.
if silent == False:
print(dataset_file_path)
print('===========================================')
print('Number of examples: ', len(json_data_list), '\n')
print('Example object keys:\n', dict_keys, '\n')
print('Example object:\n', json_data_list[0], '\n')
print('Required keys:\n')
print(' title: ', json_data_list[0]['title'], '\n')
print(' ingredients: ', json_data_list[0]['ingredients'], '\n')
print(' instructions: ', json_data_list[0]['instructions'])
print('\n\n')
return dataset
dataset_raw = load_dataset() ➔ вывод:
./tmp/datasets/recipes_raw_nosource_ar.json =========================================== Number of examples: 39802 Example object keys: ['ingredients', 'instructions', 'picture_link', 'title'] Example object: {'title': 'Slow Cooker Chicken and Dumplings', 'ingredients': ['4 skinless, boneless chicken breast halves ADVERTISEMENT', '2 tablespoons butter ADVERTISEMENT', '2 (10.75 ounce) cans condensed cream of chicken soup ADVERTISEMENT', '1 onion, finely diced ADVERTISEMENT', '2 (10 ounce) packages refrigerated biscuit dough, torn into pieces ADVERTISEMENT', 'ADVERTISEMENT'], 'instructions': 'Place the chicken, butter, soup, and onion in a slow cooker, and fill with enough water to cover.\nCover, and cook for 5 to 6 hours on High. About 30 minutes before serving, place the torn biscuit dough in the slow cooker. Cook until the dough is no longer raw in the center.\n', 'picture_link': '55lznCYBbs2mT8BTx6BTkLhynGHzM.S'} Required keys: title: Slow Cooker Chicken and Dumplings ingredients: ['4 skinless, boneless chicken breast halves ADVERTISEMENT', '2 tablespoons butter ADVERTISEMENT', '2 (10.75 ounce) cans condensed cream of chicken soup ADVERTISEMENT', '1 onion, finely diced ADVERTISEMENT', '2 (10 ounce) packages refrigerated biscuit dough, torn into pieces ADVERTISEMENT', 'ADVERTISEMENT'] instructions: Place the chicken, butter, soup, and onion in a slow cooker, and fill with enough water to cover. Cover, and cook for 5 to 6 hours on High. About 30 minutes before serving, place the torn biscuit dough in the slow cooker. Cook until the dough is no longer raw in the center. ./tmp/datasets/recipes_raw_nosource_epi.json =========================================== Number of examples: 25323 Example object keys: ['ingredients', 'instructions', 'picture_link', 'title'] Example object: {'ingredients': ['12 egg whites', '12 egg yolks', '1 1/2 cups sugar', '3/4 cup rye whiskey', '12 egg whites', '3/4 cup brandy', '1/2 cup rum', '1 to 2 cups heavy cream, lightly whipped', 'Garnish: ground nutmeg'], 'picture_link': None, 'instructions': 'Beat the egg whites until stiff, gradually adding in 3/4 cup sugar. Set aside. Beat the egg yolks until they are thick and pale and add the other 3/4 cup sugar and stir in rye whiskey. Blend well. Fold the egg white mixture into the yolk mixture and add the brandy and the rum. Beat the mixture well. To serve, fold the lightly whipped heavy cream into the eggnog. (If a thinner mixture is desired, add the heavy cream unwhipped.) Sprinkle the top of the eggnog with the nutmeg to taste.\nBeat the egg whites until stiff, gradually adding in 3/4 cup sugar. Set aside. Beat the egg yolks until they are thick and pale and add the other 3/4 cup sugar and stir in rye whiskey. Blend well. Fold the egg white mixture into the yolk mixture and add the brandy and the rum. Beat the mixture well. To serve, fold the lightly whipped heavy cream into the eggnog. (If a thinner mixture is desired, add the heavy cream unwhipped.) Sprinkle the top of the eggnog with the nutmeg to taste.', 'title': 'Christmas Eggnog '} Required keys: title: Christmas Eggnog ingredients: ['12 egg whites', '12 egg yolks', '1 1/2 cups sugar', '3/4 cup rye whiskey', '12 egg whites', '3/4 cup brandy', '1/2 cup rum', '1 to 2 cups heavy cream, lightly whipped', 'Garnish: ground nutmeg'] instructions: Beat the egg whites until stiff, gradually adding in 3/4 cup sugar. Set aside. Beat the egg yolks until they are thick and pale and add the other 3/4 cup sugar and stir in rye whiskey. Blend well. Fold the egg white mixture into the yolk mixture and add the brandy and the rum. Beat the mixture well. To serve, fold the lightly whipped heavy cream into the eggnog. (If a thinner mixture is desired, add the heavy cream unwhipped.) Sprinkle the top of the eggnog with the nutmeg to taste. Beat the egg whites until stiff, gradually adding in 3/4 cup sugar. Set aside. Beat the egg yolks until they are thick and pale and add the other 3/4 cup sugar and stir in rye whiskey. Blend well. Fold the egg white mixture into the yolk mixture and add the brandy and the rum. Beat the mixture well. To serve, fold the lightly whipped heavy cream into the eggnog. (If a thinner mixture is desired, add the heavy cream unwhipped.) Sprinkle the top of the eggnog with the nutmeg to taste. ./tmp/datasets/recipes_raw_nosource_fn.json =========================================== Number of examples: 60039 Example object keys: ['ingredients', 'instructions', 'picture_link', 'title'] Example object: {'instructions': 'Toss ingredients lightly and spoon into a buttered baking dish. Top with additional crushed cracker crumbs, and brush with melted butter. Bake in a preheated at 350 degrees oven for 25 to 30 minutes or until delicately browned.', 'ingredients': ['1/2 cup celery, finely chopped', '1 small green pepper finely chopped', '1/2 cup finely sliced green onions', '1/4 cup chopped parsley', '1 pound crabmeat', '1 1/4 cups coarsely crushed cracker crumbs', '1/2 teaspoon salt', '3/4 teaspoons dry mustard', 'Dash hot sauce', '1/4 cup heavy cream', '1/2 cup melted butter'], 'title': "Grammie Hamblet's Deviled Crab", 'picture_link': None} Required keys: title: Grammie Hamblet's Deviled Crab ingredients: ['1/2 cup celery, finely chopped', '1 small green pepper finely chopped', '1/2 cup finely sliced green onions', '1/4 cup chopped parsley', '1 pound crabmeat', '1 1/4 cups coarsely crushed cracker crumbs', '1/2 teaspoon salt', '3/4 teaspoons dry mustard', 'Dash hot sauce', '1/4 cup heavy cream', '1/2 cup melted butter'] instructions: Toss ingredients lightly and spoon into a buttered baking dish. Top with additional crushed cracker crumbs, and brush with melted butter. Bake in a preheated at 350 degrees oven for 25 to 30 minutes or until delicately browned.
Давайте посчитаем общее количество рецептов после слияния файлов с данными:
print('Total number of raw examples: ', len(dataset_raw))➔ вывод:
Total number of raw examples: 125164
Возможно, что некоторые рецепты не имеют обязательных полей (name, ingredients или instructions). Нам необходимо очистить наш набор данных от этих неполных рецептов. Следующая функция поможет нам это сделать:
def recipe_validate_required_fields(recipe):
required_keys = ['title', 'ingredients', 'instructions']
if not recipe:
return False
for required_key in required_keys:
if not recipe[required_key]:
return False
if type(recipe[required_key]) == list and len(recipe[required_key]) == 0:
return False
return TrueТеперь воспользуемся функцией recipe_validate_required_fields() для фильтрации неполных рецептов:
dataset_validated = [recipe for recipe in dataset_raw if recipe_validate_required_fields(recipe)]
print('Dataset size BEFORE validation', len(dataset_raw))
print('Dataset size AFTER validation', len(dataset_validated))
print('Number of incomplete recipes', len(dataset_raw) - len(dataset_validated))➔ вывод:
Dataset size BEFORE validation 125164 Dataset size AFTER validation 122938 Number of incomplete recipes 2226
Как вы можете увидеть, из 125164 рецептов 2226 были неполными.
RNN не умеет работать с объектами, она понимает только числа. Поэтому нам нужно сначала преобразовывать наши рецепты из объектов в строки, а затем в числа (индексы). Начнем с преобразования рецептов в строки.
Чтобы RNN было легче распознать секции (имя, ингредиенты и шаги приготовления) в тексте рецептов, мы можем расставить уникальные "маячки" или "ориентиры", которые будут разделять эти секции.
STOP_WORD_TITLE = '◘ '
STOP_WORD_INGREDIENTS = '\n❖\n\n'
STOP_WORD_INSTRUCTIONS = '\n✼\n\n'The following function converts the recipe object to a string (sequence of characters) for later usage in RNN input.
Следующая функция преобразует объект в строку (последовательность символов) для последующего использования на входе RNN.
def recipe_to_string(recipe):
# Эта рекламная строка присутствует в рецептах, поэтому нам необходимо ее очистить.
noize_string = 'ADVERTISEMENT'
title = recipe['title']
ingredients = recipe['ingredients']
instructions = recipe['instructions'].split('\n')
ingredients_string = ''
for ingredient in ingredients:
ingredient = ingredient.replace(noize_string, '')
if ingredient:
ingredients_string += f'• {ingredient}\n'
instructions_string = ''
for instruction in instructions:
instruction = instruction.replace(noize_string, '')
if instruction:
instructions_string += f'︎ {instruction}\n'
return f'{STOP_WORD_TITLE}{title}\n{STOP_WORD_INGREDIENTS}{ingredients_string}{STOP_WORD_INSTRUCTIONS}{instructions_string}'Применяем функцию recipe_to_string() к dataset_validated:
dataset_stringified = [recipe_to_string(recipe) for recipe in dataset_validated]
print('Stringified dataset size: ', len(dataset_stringified))➔ вывод:
Stringified dataset size: 122938
Давайте выведем первые несколько рецептов:
for recipe_index, recipe_string in enumerate(dataset_stringified[:3]):
print('Recipe #{}\n---------'.format(recipe_index + 1))
print(recipe_string)
print('\n')➔ вывод:
Recipe #1 --------- ◘ Slow Cooker Chicken and Dumplings ❖ • 4 skinless, boneless chicken breast halves • 2 tablespoons butter • 2 (10.75 ounce) cans condensed cream of chicken soup • 1 onion, finely diced • 2 (10 ounce) packages refrigerated biscuit dough, torn into pieces ✼ ︎ Place the chicken, butter, soup, and onion in a slow cooker, and fill with enough water to cover. ︎ Cover, and cook for 5 to 6 hours on High. About 30 minutes before serving, place the torn biscuit dough in the slow cooker. Cook until the dough is no longer raw in the center. Recipe #2 --------- ◘ Awesome Slow Cooker Pot Roast ❖ • 2 (10.75 ounce) cans condensed cream of mushroom soup • 1 (1 ounce) package dry onion soup mix • 1 1/4 cups water • 5 1/2 pounds pot roast ✼ ︎ In a slow cooker, mix cream of mushroom soup, dry onion soup mix and water. Place pot roast in slow cooker and coat with soup mixture. ︎ Cook on High setting for 3 to 4 hours, or on Low setting for 8 to 9 hours. Recipe #3 --------- ◘ Brown Sugar Meatloaf ❖ • 1/2 cup packed brown sugar • 1/2 cup ketchup • 1 1/2 pounds lean ground beef • 3/4 cup milk • 2 eggs • 1 1/2 teaspoons salt • 1/4 teaspoon ground black pepper • 1 small onion, chopped • 1/4 teaspoon ground ginger • 3/4 cup finely crushed saltine cracker crumbs ✼ ︎ Preheat oven to 350 degrees F (175 degrees C). Lightly grease a 5x9 inch loaf pan. ︎ Press the brown sugar in the bottom of the prepared loaf pan and spread the ketchup over the sugar. ︎ In a mixing bowl, mix thoroughly all remaining ingredients and shape into a loaf. Place on top of the ketchup. ︎ Bake in preheated oven for 1 hour or until juices are clear.
Исключительно из любопытства давайте посмотрим на рецепт где-то из середины набора данных, чтобы увидеть, что он имеет ожидаемую структуру:
print(dataset_stringified[50000])➔ вывод:
◘ Herbed Bean Ragoût ❖ • 6 ounces haricots verts (French thin green beans), trimmed and halved crosswise • 1 (1-pound) bag frozen edamame (soybeans in the pod) or 1 1/4 cups frozen shelled edamame, not thawed • 2/3 cup finely chopped onion • 2 garlic cloves, minced • 1 Turkish bay leaf or 1/2 California bay leaf • 2 (3-inch) fresh rosemary sprigs • 1/2 teaspoon salt • 1/4 teaspoon black pepper • 1 tablespoon olive oil • 1 medium carrot, cut into 1/8-inch dice • 1 medium celery rib, cut into 1/8-inch dice • 1 (15- to 16-ounces) can small white beans, rinsed and drained • 1 1/2 cups chicken stock or low-sodium broth • 2 tablespoons unsalted butter • 2 tablespoons finely chopped fresh flat-leaf parsley • 1 tablespoon finely chopped fresh chervil (optional) • Garnish: fresh chervil sprigs ✼ ︎ Cook haricots verts in a large pot of boiling salted water until just tender, 3 to 4 minutes. Transfer with a slotted spoon to a bowl of ice and cold water, then drain. Add edamame to boiling water and cook 4 minutes. Drain in a colander, then rinse under cold water. If using edamame in pods, shell them and discard pods. Cook onion, garlic, bay leaf, rosemary, salt, and pepper in oil in a 2- to 4-quart heavy saucepan over moderately low heat, stirring, until softened, about 3 minutes. Add carrot and celery and cook, stirring, until softened, about 3 minutes. Add white beans and stock and simmer, covered, stirring occasionally, 10 minutes. Add haricots verts and edamame and simmer, uncovered, until heated through, 2 to 3 minutes. Add butter, parsley, and chervil (if using) and stir gently until butter is melted. Discard bay leaf and rosemary sprigs. ︎ Cook haricots verts in a large pot of boiling salted water until just tender, 3 to 4 minutes. Transfer with a slotted spoon to a bowl of ice and cold water, then drain. ︎ Add edamame to boiling water and cook 4 minutes. Drain in a colander, then rinse under cold water. If using edamame in pods, shell them and discard pods. ︎ Cook onion, garlic, bay leaf, rosemary, salt, and pepper in oil in a 2- to 4-quart heavy saucepan over moderately low heat, stirring, until softened, about 3 minutes. Add carrot and celery and cook, stirring, until softened, about 3 minutes. ︎ Add white beans and stock and simmer, covered, stirring occasionally, 10 minutes. Add haricots verts and edamame and simmer, uncovered, until heated through, 2 to 3 minutes. Add butter, parsley, and chervil (if using) and stir gently until butter is melted. Discard bay leaf and rosemary sprigs.
Перед началом тренировки RNN нам необходимо привести все тексты рецептов к одной длине. Чем больше эта длина, тем больше информации из каждого рецепта будет участвовать в тренировке (в случае если все рецепты будут подогнаны по длине к самому большому из них). С другой стороны длинные последовательности замедлят скорость обучения. Также возможна ситуация, когда у нас, пускай 99 рецептов имеют длину 1000 символов, а 1 рецепт имеет длину 5000 символов. Подгонка 99 рецептов по длине к 5000 символам (путем добавления стоп-символов в конец рецепта) из-за одного другого рецепта вряд ли сильно улучшит точность модели, но уж точно замедлит ее тренировку. Поэтому давайте проанализируем длины рецептов, которые есть у нас в наборе данных и выберем подходящую:
recipes_lengths = []
for recipe_text in dataset_stringified:
recipes_lengths.append(len(recipe_text))
plt.hist(recipes_lengths, bins=50)
plt.show()➔ вывод:

Большинство рецептов имеют длину меньше 5000 символов. Давайте приблизим график, чтобы увидеть более детальную картину:
plt.hist(recipes_lengths, range=(0, 8000), bins=50)
plt.show()➔ вывод:

Похоже на то, что ограничение в 2000 символов для текста рецептов может быть оптимальным в нашем случае.
MAX_RECIPE_LENGTH = 2000Теперь мы можем отфильтровать все рецепты, которые длиннее MAX_RECIPE_LENGTH:
def filter_recipes_by_length(recipe_test):
return len(recipe_test) <= MAX_RECIPE_LENGTH
dataset_filtered = [recipe_text for recipe_text in dataset_stringified if filter_recipes_by_length(recipe_text)]
print('Dataset size BEFORE filtering: ', len(dataset_stringified))
print('Dataset size AFTER filtering: ', len(dataset_filtered))
print('Number of eliminated recipes: ', len(dataset_stringified) - len(dataset_filtered))➔ вывод:
Dataset size BEFORE filtering: 122938 Dataset size AFTER filtering: 100212 Number of eliminated recipes: 22726
Мы потеряли 22726 рецептов после фильтрации, но зато теперь список рецептов стал более однородным (плотным)
с точки зрения количества символов. Позже, каждый рецепт будет "подогнан" по длине к MAX_RECIPE_LENGTH путем добавления стоп-символа в конец строки. Фильтрация, которую мы только что сделали, по сути, снизит общее количество стоп-символов и увеличит "полезность" данных при тренировке. Например, 10 стоп-символов в наборе данных из 100 символов (90% полезных для тренировки сети данных) может быть лучше для обучения, чем 50 стоп-символов в наборе данных из 100 символов (50% полезных для тренировки сети данных).
TOTAL_RECIPES_NUM = len(dataset_filtered)
print('MAX_RECIPE_LENGTH: ', MAX_RECIPE_LENGTH)
print('TOTAL_RECIPES_NUM: ', TOTAL_RECIPES_NUM)➔ вывод:
MAX_RECIPE_LENGTH: 2000 TOTAL_RECIPES_NUM: 100212
В итоге мы имеем ~100000 рецептов, каждый из которых будет иметь длину в 2000 символов.
Рекуррентные нейронные сети не понимают ни символов, ни слов. Вместо этого они понимают числа. Поэтому нам необходимо преобразовать текст рецептов (последовательность символов) в последовательность чисел.
В этом эксперименте мы будем использовать модель символьного уровня (не словарного уровня), с архитектурой LSTM (Long Short-Term Memory). Это означает, что вместо создания уникальных индексов для слов мы будем создавать уникальные индексы для символов. Таким образом, мы позволяем сети предсказывать индекс следующего символа вместо индекса следующего слова в последовательности.
Более детально про языковую модель символьного уровня вы можете прочитать в статье Unreasonable Effectiveness of Recurrent Neural Networks.
Для создания словаря из текста рецептов мы будем использовать tf.keras.preprocessing.text.Tokenizer.
Нам также необходимо выбрать уникальный символ, который мы будем использовать в качестве стоп-символа. Этот стоп-символ будет означать конец текста рецепта. Он нам понадобится во время генерации новых текстов.
STOP_SIGN = '␣'
tokenizer = tf.keras.preprocessing.text.Tokenizer(
char_level=True,
filters='',
lower=False,
split=''
)
# Стоп-символ не является частью рецептов, но токенайзер должен знать о нем.
tokenizer.fit_on_texts([STOP_SIGN])
tokenizer.fit_on_texts(dataset_filtered)
tokenizer.get_config()➔ вывод:
{'num_words': None, 'filters': '', 'lower': False, 'split': '', 'char_level': True, 'oov_token': None, 'document_count': 100213, 'word_counts': '{"\\u2423": 1, "\\ud83d\\udcd7": 100212, " ": 17527888, "S": 270259, "l": 3815150, "o": 5987496, "w": 964459, "C": 222831, "k": 890982, "e": 9296022, "r": 4760887, "h": 2922100, "i": 4911812, "c": 2883507, "n": 5304396, "a": 6067157, "d": 3099679, "D": 63999, "u": 2717050, "m": 1794411, "p": 2679164, "g": 1698670, "s": 4704222, "\\n": 1955281, "\\ud83e\\udd55": 100212, "\\u2022": 922813, "4": 232607, ",": 1130487, "b": 1394803, "t": 5997722, "v": 746785, "2": 493933, "(": 144985, "1": 853931, "0": 145119, ".": 1052548, "7": 31098, "5": 154071, ")": 144977, "f": 1042981, "y": 666553, "\\ud83d\\udcdd": 100212, "\\u25aa": 331058, "\\ufe0e": 331058, "P": 200597, "6": 51398, "H": 43936, "A": 134274, "3": 213519, "R": 101253, "x": 201286, "/": 345257, "I": 81591, "L": 46138, "8": 55352, "9": 17697, "B": 123813, "M": 78684, "F": 104359, "j": 110008, "-": 219160, "W": 61616, "\\u00ae": 10159, "N": 12808, "q": 69654, "T": 101371, ";": 72045, "\'": 26831, "Z": 2428, "z": 115883, "G": 52043, ":": 31318, "E": 18582, "K": 18421, "X": 385, "\\"": 6445, "O": 28971, "Y": 6064, "\\u2122": 538, "Q": 3904, "J": 10269, "!": 3014, "U": 14132, "V": 12172, "&": 1039, "+": 87, "=": 113, "%": 993, "*": 3243, "\\u00a9": 99, "[": 30, "]": 31, "\\u00e9": 6727, "<": 76, ">": 86, "\\u00bd": 166, "#": 168, "\\u00f1": 891, "?": 327, "\\u2019": 111, "\\u00b0": 6808, "\\u201d": 6, "$": 84, "@": 5, "{": 8, "}": 9, "\\u2013": 1228, "\\u0096": 7, "\\u00e0": 26, "\\u00e2": 106, "\\u00e8": 846, "\\u00e1": 74, "\\u2014": 215, "\\u2044": 16, "\\u00ee": 415, "\\u00e7": 171, "_": 26, "\\u00fa": 48, "\\u00ef": 43, "\\u201a": 20, "\\u00fb": 36, "\\u00f3": 74, "\\u00ed": 130, "\\u25ca": 4, "\\u00f9": 12, "\\u00d7": 6, "\\u00ec": 8, "\\u00fc": 29, "\\u2031": 4, "\\u00ba": 19, "\\u201c": 4, "\\u00ad": 25, "\\u00ea": 27, "\\u00f6": 9, "\\u0301": 11, "\\u00f4": 8, "\\u00c1": 2, "\\u00be": 23, "\\u00bc": 95, "\\u00eb": 2, "\\u0097": 2, "\\u215b": 3, "\\u2027": 4, "\\u00e4": 15, "\\u001a": 2, "\\u00f8": 2, "\\ufffd": 20, "\\u02da": 6, "\\u00bf": 264, "\\u2153": 2, "|": 2, "\\u00e5": 3, "\\u00a4": 1, "\\u201f": 1, "\\u00a7": 5, "\\ufb02": 3, "\\u00a0": 1, "\\u01b0": 2, "\\u01a1": 1, "\\u0103": 1, "\\u0300": 1, "\\u00bb": 6, "`": 3, "\\u0092": 2, "\\u215e": 1, "\\u202d": 4, "\\u00b4": 2, "\\u2012": 2, "\\u00c9": 40, "\\u00da": 14, "\\u20ac": 1, "\\\\": 5, "~": 1, "\\u0095": 1, "\\u00c2": 2}', 'word_docs': '{"\\u2423": 1, "k": 97316, "0": 61954, "o": 100205, "r": 100207, "d": 100194, "u": 100161, "S": 89250, "\\u25aa": 100212, "D": 40870, "1": 99320, "g": 99975, "n": 100198, "b": 99702, "t": 100202, ".": 100163, " ": 100212, "7": 24377, "3": 79135, "\\ud83d\\udcd7": 100212, "i": 100207, "5": 65486, "f": 98331, "c": 100190, "4": 82453, "a": 100205, "2": 96743, "v": 97848, "C": 83328, "s": 100204, "\\n": 100212, "6": 35206, "\\ud83d\\udcdd": 100212, ",": 98524, "\\ufe0e": 100212, "l": 100206, "e": 100212, "y": 96387, ")": 67614, "p": 100046, "H": 31908, "\\ud83e\\udd55": 100212, "m": 99988, "w": 99227, "(": 67627, "A": 60900, "h": 100161, "\\u2022": 100212, "P": 79364, "R": 54040, "9": 14114, "8": 37000, "L": 32101, "x": 72133, "I": 46675, "/": 89051, "j": 47438, "F": 57940, "B": 64278, "M": 48332, "-": 74711, "T": 53758, "\\u00ae": 5819, "N": 9981, "W": 38981, "q": 36538, ";": 33863, "G": 35355, "\'": 18120, "z": 42430, "Z": 2184, ":": 18214, "E": 12161, "K": 14834, "X": 321, "\\"": 2617, "O": 20103, "Y": 5148, "\\u2122": 448, "Q": 3142, "J": 8225, "!": 2428, "U": 10621, "V": 9710, "&": 749, "+": 32, "=": 48, "%": 717, "*": 1780, "\\u00a9": 91, "]": 26, "[": 25, "\\u00e9": 2462, ">": 33, "<": 27, "\\u00bd": 81, "#": 139, "\\u00f1": 423, "?": 207, "\\u2019": 64, "\\u00b0": 3062, "\\u201d": 3, "@": 4, "$": 49, "{": 7, "}": 8, "\\u2013": 491, "\\u0096": 7, "\\u00e0": 22, "\\u00e2": 45, "\\u00e8": 335, "\\u00e1": 38, "\\u2014": 95, "\\u2044": 9, "\\u00ee": 122, "\\u00e7": 120, "_": 8, "\\u00fa": 25, "\\u00ef": 24, "\\u201a": 10, "\\u00fb": 29, "\\u00f3": 40, "\\u00ed": 52, "\\u25ca": 2, "\\u00f9": 6, "\\u00d7": 4, "\\u00ec": 4, "\\u00fc": 19, "\\u2031": 2, "\\u00ba": 9, "\\u201c": 2, "\\u00ad": 11, "\\u00ea": 4, "\\u00f6": 4, "\\u0301": 6, "\\u00f4": 5, "\\u00c1": 2, "\\u00be": 18, "\\u00bc": 55, "\\u00eb": 2, "\\u0097": 1, "\\u215b": 2, "\\u2027": 3, "\\u00e4": 8, "\\u001a": 1, "\\u00f8": 1, "\\ufffd": 4, "\\u02da": 3, "\\u00bf": 191, "\\u2153": 1, "|": 2, "\\u00e5": 1, "\\u00a4": 1, "\\u201f": 1, "\\u00a7": 3, "\\ufb02": 1, "\\u0300": 1, "\\u01a1": 1, "\\u00a0": 1, "\\u01b0": 1, "\\u0103": 1, "\\u00bb": 2, "`": 3, "\\u0092": 2, "\\u215e": 1, "\\u202d": 1, "\\u00b4": 1, "\\u2012": 1, "\\u00c9": 15, "\\u00da": 5, "\\u20ac": 1, "\\\\": 5, "~": 1, "\\u0095": 1, "\\u00c2": 1}', 'index_docs': '{"1": 100212, "165": 1, "25": 97316, "41": 61954, "5": 100205, "8": 100207, "11": 100194, "14": 100161, "33": 89250, "31": 100212, "58": 40870, "26": 99320, "18": 99975, "6": 100198, "19": 99702, "4": 100202, "21": 100163, "66": 24377, "37": 79135, "51": 100212, "7": 100207, "40": 65486, "22": 98331, "13": 100190, "34": 82453, "3": 100205, "29": 96743, "27": 97848, "35": 83328, "9": 100204, "16": 100212, "62": 35206, "53": 100212, "20": 98524, "32": 100212, "10": 100206, "2": 100212, "28": 96387, "43": 67614, "15": 100046, "64": 31908, "52": 100212, "17": 99988, "23": 99227, "42": 67627, "44": 60900, "12": 100161, "24": 100212, "39": 79364, "50": 54040, "71": 14114, "60": 37000, "63": 32101, "38": 72133, "54": 46675, "30": 89051, "47": 47438, "48": 57940, "45": 64278, "55": 48332, "36": 74711, "49": 53758, "76": 5819, "73": 9981, "59": 38981, "57": 36538, "56": 33863, "61": 35355, "68": 18120, "46": 42430, "84": 2184, "65": 18214, "69": 12161, "70": 14834, "92": 321, "79": 2617, "67": 20103, "80": 5148, "90": 448, "81": 3142, "75": 8225, "83": 2428, "72": 10621, "74": 9710, "86": 749, "105": 32, "100": 48, "87": 717, "82": 1780, "103": 91, "115": 26, "116": 25, "78": 2462, "106": 33, "108": 27, "98": 81, "97": 139, "88": 423, "93": 207, "101": 64, "77": 3062, "137": 3, "141": 4, "107": 49, "133": 7, "131": 8, "85": 491, "136": 7, "119": 22, "102": 45, "89": 335, "109": 38, "95": 95, "126": 9, "91": 122, "96": 120, "120": 8, "111": 25, "112": 24, "123": 10, "114": 29, "110": 40, "99": 52, "144": 2, "129": 6, "138": 4, "134": 4, "117": 19, "145": 2, "125": 9, "146": 2, "121": 11, "118": 4, "132": 4, "130": 6, "135": 5, "153": 2, "122": 18, "104": 55, "154": 2, "155": 1, "149": 2, "147": 3, "127": 8, "156": 1, "157": 1, "124": 4, "139": 3, "94": 191, "158": 1, "159": 2, "150": 1, "166": 1, "167": 1, "142": 3, "151": 1, "171": 1, "169": 1, "168": 1, "160": 1, "170": 1, "140": 2, "152": 3, "161": 2, "172": 1, "148": 1, "162": 1, "163": 1, "113": 15, "128": 5, "173": 1, "143": 5, "174": 1, "175": 1, "164": 1}', 'index_word': '{"1": " ", "2": "e", "3": "a", "4": "t", "5": "o", "6": "n", "7": "i", "8": "r", "9": "s", "10": "l", "11": "d", "12": "h", "13": "c", "14": "u", "15": "p", "16": "\\n", "17": "m", "18": "g", "19": "b", "20": ",", "21": ".", "22": "f", "23": "w", "24": "\\u2022", "25": "k", "26": "1", "27": "v", "28": "y", "29": "2", "30": "/", "31": "\\u25aa", "32": "\\ufe0e", "33": "S", "34": "4", "35": "C", "36": "-", "37": "3", "38": "x", "39": "P", "40": "5", "41": "0", "42": "(", "43": ")", "44": "A", "45": "B", "46": "z", "47": "j", "48": "F", "49": "T", "50": "R", "51": "\\ud83d\\udcd7", "52": "\\ud83e\\udd55", "53": "\\ud83d\\udcdd", "54": "I", "55": "M", "56": ";", "57": "q", "58": "D", "59": "W", "60": "8", "61": "G", "62": "6", "63": "L", "64": "H", "65": ":", "66": "7", "67": "O", "68": "\'", "69": "E", "70": "K", "71": "9", "72": "U", "73": "N", "74": "V", "75": "J", "76": "\\u00ae", "77": "\\u00b0", "78": "\\u00e9", "79": "\\"", "80": "Y", "81": "Q", "82": "*", "83": "!", "84": "Z", "85": "\\u2013", "86": "&", "87": "%", "88": "\\u00f1", "89": "\\u00e8", "90": "\\u2122", "91": "\\u00ee", "92": "X", "93": "?", "94": "\\u00bf", "95": "\\u2014", "96": "\\u00e7", "97": "#", "98": "\\u00bd", "99": "\\u00ed", "100": "=", "101": "\\u2019", "102": "\\u00e2", "103": "\\u00a9", "104": "\\u00bc", "105": "+", "106": ">", "107": "$", "108": "<", "109": "\\u00e1", "110": "\\u00f3", "111": "\\u00fa", "112": "\\u00ef", "113": "\\u00c9", "114": "\\u00fb", "115": "]", "116": "[", "117": "\\u00fc", "118": "\\u00ea", "119": "\\u00e0", "120": "_", "121": "\\u00ad", "122": "\\u00be", "123": "\\u201a", "124": "\\ufffd", "125": "\\u00ba", "126": "\\u2044", "127": "\\u00e4", "128": "\\u00da", "129": "\\u00f9", "130": "\\u0301", "131": "}", "132": "\\u00f6", "133": "{", "134": "\\u00ec", "135": "\\u00f4", "136": "\\u0096", "137": "\\u201d", "138": "\\u00d7", "139": "\\u02da", "140": "\\u00bb", "141": "@", "142": "\\u00a7", "143": "\\\\", "144": "\\u25ca", "145": "\\u2031", "146": "\\u201c", "147": "\\u2027", "148": "\\u202d", "149": "\\u215b", "150": "\\u00e5", "151": "\\ufb02", "152": "`", "153": "\\u00c1", "154": "\\u00eb", "155": "\\u0097", "156": "\\u001a", "157": "\\u00f8", "158": "\\u2153", "159": "|", "160": "\\u01b0", "161": "\\u0092", "162": "\\u00b4", "163": "\\u2012", "164": "\\u00c2", "165": "\\u2423", "166": "\\u00a4", "167": "\\u201f", "168": "\\u00a0", "169": "\\u01a1", "170": "\\u0103", "171": "\\u0300", "172": "\\u215e", "173": "\\u20ac", "174": "~", "175": "\\u0095"}', 'word_index': '{" ": 1, "e": 2, "a": 3, "t": 4, "o": 5, "n": 6, "i": 7, "r": 8, "s": 9, "l": 10, "d": 11, "h": 12, "c": 13, "u": 14, "p": 15, "\\n": 16, "m": 17, "g": 18, "b": 19, ",": 20, ".": 21, "f": 22, "w": 23, "\\u2022": 24, "k": 25, "1": 26, "v": 27, "y": 28, "2": 29, "/": 30, "\\u25aa": 31, "\\ufe0e": 32, "S": 33, "4": 34, "C": 35, "-": 36, "3": 37, "x": 38, "P": 39, "5": 40, "0": 41, "(": 42, ")": 43, "A": 44, "B": 45, "z": 46, "j": 47, "F": 48, "T": 49, "R": 50, "\\ud83d\\udcd7": 51, "\\ud83e\\udd55": 52, "\\ud83d\\udcdd": 53, "I": 54, "M": 55, ";": 56, "q": 57, "D": 58, "W": 59, "8": 60, "G": 61, "6": 62, "L": 63, "H": 64, ":": 65, "7": 66, "O": 67, "\'": 68, "E": 69, "K": 70, "9": 71, "U": 72, "N": 73, "V": 74, "J": 75, "\\u00ae": 76, "\\u00b0": 77, "\\u00e9": 78, "\\"": 79, "Y": 80, "Q": 81, "*": 82, "!": 83, "Z": 84, "\\u2013": 85, "&": 86, "%": 87, "\\u00f1": 88, "\\u00e8": 89, "\\u2122": 90, "\\u00ee": 91, "X": 92, "?": 93, "\\u00bf": 94, "\\u2014": 95, "\\u00e7": 96, "#": 97, "\\u00bd": 98, "\\u00ed": 99, "=": 100, "\\u2019": 101, "\\u00e2": 102, "\\u00a9": 103, "\\u00bc": 104, "+": 105, ">": 106, "$": 107, "<": 108, "\\u00e1": 109, "\\u00f3": 110, "\\u00fa": 111, "\\u00ef": 112, "\\u00c9": 113, "\\u00fb": 114, "]": 115, "[": 116, "\\u00fc": 117, "\\u00ea": 118, "\\u00e0": 119, "_": 120, "\\u00ad": 121, "\\u00be": 122, "\\u201a": 123, "\\ufffd": 124, "\\u00ba": 125, "\\u2044": 126, "\\u00e4": 127, "\\u00da": 128, "\\u00f9": 129, "\\u0301": 130, "}": 131, "\\u00f6": 132, "{": 133, "\\u00ec": 134, "\\u00f4": 135, "\\u0096": 136, "\\u201d": 137, "\\u00d7": 138, "\\u02da": 139, "\\u00bb": 140, "@": 141, "\\u00a7": 142, "\\\\": 143, "\\u25ca": 144, "\\u2031": 145, "\\u201c": 146, "\\u2027": 147, "\\u202d": 148, "\\u215b": 149, "\\u00e5": 150, "\\ufb02": 151, "`": 152, "\\u00c1": 153, "\\u00eb": 154, "\\u0097": 155, "\\u001a": 156, "\\u00f8": 157, "\\u2153": 158, "|": 159, "\\u01b0": 160, "\\u0092": 161, "\\u00b4": 162, "\\u2012": 163, "\\u00c2": 164, "\\u2423": 165, "\\u00a4": 166, "\\u201f": 167, "\\u00a0": 168, "\\u01a1": 169, "\\u0103": 170, "\\u0300": 171, "\\u215e": 172, "\\u20ac": 173, "~": 174, "\\u0095": 175}'}
Для того, чтобы узнать окончательный размер словаря, нам необходимо добавить +1 к числу ранее зарегистрированных символов потому что нулевой индекс зарезервирован токенайзером и не будет присвоен ни одному из символов.
VOCABULARY_SIZE = len(tokenizer.word_counts) + 1
print('VOCABULARY_SIZE: ', VOCABULARY_SIZE)➔ вывод:
VOCABULARY_SIZE: 176
Давайте посмотрим, как теперь мы можем конвертировать символы в индексы и индексы в символы с помощью созданного словаря:
print(tokenizer.index_word[5])
print(tokenizer.index_word[20])➔ вывод:
o ,
Конвертируем символ в индекс:
tokenizer.word_index['r']➔ вывод:
8
Список всех символов, образующих весь набор данных с рецептами выглядит так:
array_vocabulary = tokenizer.sequences_to_texts([[word_index] for word_index in range(VOCABULARY_SIZE)])
print([char for char in array_vocabulary])➔ вывод:
['', ' ', 'e', 'a', 't', 'o', 'n', 'i', 'r', 's', 'l', 'd', 'h', 'c', 'u', 'p', '\n', 'm', 'g', 'b', ',', '.', 'f', 'w', '•', 'k', '1', 'v', 'y', '2', '/', '', '︎', 'S', '4', 'C', '-', '3', 'x', 'P', '5', '0', '(', ')', 'A', 'B', 'z', 'j', 'F', 'T', 'R', '◘', '❖', '✼', 'I', 'M', ';', 'q', 'D', 'W', '8', 'G', '6', 'L', 'H', ':', '7', 'O', "'", 'E', 'K', '9', 'U', 'N', 'V', 'J', '', '°', 'é', '"', 'Y', 'Q', '*', '!', 'Z', '–', '&', '%', 'ñ', 'è', '', 'î', 'X', '?', '¿', '—', 'ç', '#', '½', 'í', '=', '’', 'â', '', '¼', '+', '>', '$', '<', 'á', 'ó', 'ú', 'ï', 'É', 'û', ']', '[', 'ü', 'ê', 'à', '_', '\xad', '¾', '‚', '�', 'º', '⁄', 'ä', 'Ú', 'ù', '́', '}', 'ö', '{', 'ì', 'ô', '\x96', '”', '×', '˚', '»', '@', '§', '\\', '◊', '‱', '“', '‧', '\u202d', '⅛', 'å', 'fl', '`', 'Á', 'ë', '\x97', '\x1a', 'ø', '⅓', '|', 'ư', '\x92', '´', '‒', 'Â', '␣', '¤', '‟', '\xa0', 'ơ', 'ă', '̀', '⅞', '€', '~', '\x95']
Это весь набор символов с которым будет работать нейронная сеть. Она будет учиться собирать эти символы в последовательности, которые в итоге должны быть читабельными и похожи на кулинарные рецепты.
Попробуем теперь конвертировать не один символ, а строку в последовательность индексов, используя tokenizer:
tokenizer.texts_to_sequences(['◘ yes'])➔ вывод:
[[51, 1, 28, 2, 9]]
Под векторизацией будем понимать преобразования данных (в нашем случае строк) в числовые векторы (в нашем случае в одномерный массив индексов).
Теперь, когда у нас есть словарь (зависимости символ --> индекс and индекс --> символ) мы можем конвертировать строки с рецептами в последовательности индексов (RNN на входе принимает числа, а не символы).
dataset_vectorized = tokenizer.texts_to_sequences(dataset_filtered)
print('Vectorized dataset size', len(dataset_vectorized))➔ вывод:
Vectorized dataset size 100212
Вот так выглядит начало векторизированного рецепта:
print(dataset_vectorized[0][:10], '...')➔ вывод:
[51, 1, 33, 10, 5, 23, 1, 35, 5, 5] ...
Попробуем теперь конвертировать векторизированный рецепт обратно в строку:
def recipe_sequence_to_string(recipe_sequence):
recipe_stringified = tokenizer.sequences_to_texts([recipe_sequence])[0]
print(recipe_stringified)
recipe_sequence_to_string(dataset_vectorized[0])➔ вывод:
◘ Slow Cooker Chicken and Dumplings ❖ • 4 skinless, boneless chicken breast halves • 2 tablespoons butter • 2 (10.75 ounce) cans condensed cream of chicken soup • 1 onion, finely diced • 2 (10 ounce) packages refrigerated biscuit dough, torn into pieces ✼ ︎ Place the chicken, butter, soup, and onion in a slow cooker, and fill with enough water to cover. ︎ Cover, and cook for 5 to 6 hours on High. About 30 minutes before serving, place the torn biscuit dough in the slow cooker. Cook until the dough is no longer raw in the center.
Как синоним подгонки по длине мы также будем использовать слово "паддинг"
Все рецепты должны иметь одинаковую длину перед тренировкой модели. Для паддинга рецептов мы воспользуемся утилитой tf.keras.preprocessing.sequence.pad_sequences. С помощью этой функции мы добавим стоп-символ в конец каждого рецепта так, что все рецепты будут одинаковой длины.
На данный момент длины первых 10-и рецептов выглядят следующим образом:
for recipe_index, recipe in enumerate(dataset_vectorized[:10]):
print('Recipe #{} length: {}'.format(recipe_index + 1, len(recipe)))➔ вывод:
Recipe #1 length: 546 Recipe #2 length: 401 Recipe #3 length: 671 Recipe #4 length: 736 Recipe #5 length: 1518 Recipe #6 length: 740 Recipe #7 length: 839 Recipe #8 length: 667 Recipe #9 length: 1264 Recipe #10 length: 854
Добавим STOP_SIGN в конец каждого рецепта:
dataset_vectorized_padded_without_stops = tf.keras.preprocessing.sequence.pad_sequences(
dataset_vectorized,
padding='post',
truncating='post',
# Используем -1 здесь и +1 ниже, чтобы каждый рецепт имел как минимум
# один стоп-символ в конце, поскольку в дальнейшем каждый текст будет
# обрезан на один символ с конца строки для формирования последовательностей X и Y.
# (см. ниже по тексту)
maxlen=MAX_RECIPE_LENGTH-1,
value=tokenizer.texts_to_sequences([STOP_SIGN])[0]
)
dataset_vectorized_padded = tf.keras.preprocessing.sequence.pad_sequences(
dataset_vectorized_padded_without_stops,
padding='post',
truncating='post',
maxlen=MAX_RECIPE_LENGTH+1,
value=tokenizer.texts_to_sequences([STOP_SIGN])[0]
)
for recipe_index, recipe in enumerate(dataset_vectorized_padded[:10]):
print('Recipe #{} length: {}'.format(recipe_index, len(recipe)))➔ вывод:
Recipe #0 length: 2001 Recipe #1 length: 2001 Recipe #2 length: 2001 Recipe #3 length: 2001 Recipe #4 length: 2001 Recipe #5 length: 2001 Recipe #6 length: 2001 Recipe #7 length: 2001 Recipe #8 length: 2001 Recipe #9 length: 2001
После подгонки каждый рецепт в наборе данных имеет одинаковую длину и стоп-символ в конце.
Длина рецепта на данный момент на один символ больше запланированной (2001 вместо 2000). Это сделано по той причине, что ниже из каждого рецепта мы будем формировать входную последовательность X (длиной в 2000) и целевую последовательность Y (длиной в 2000), которые будут сдвинуты друг относительно друга на 1 символ.
Вот как выглядит первый рецепт после паддинга:
recipe_sequence_to_string(dataset_vectorized_padded[0])➔ вывод:
◘ Slow Cooker Chicken and Dumplings ❖ • 4 skinless, boneless chicken breast halves • 2 tablespoons butter • 2 (10.75 ounce) cans condensed cream of chicken soup • 1 onion, finely diced • 2 (10 ounce) packages refrigerated biscuit dough, torn into pieces ✼ ︎ Place the chicken, butter, soup, and onion in a slow cooker, and fill with enough water to cover. ︎ Cover, and cook for 5 to 6 hours on High. About 30 minutes before serving, place the torn biscuit dough in the slow cooker. Cook until the dough is no longer raw in the center. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣
Все рецепты сейчас заканчиваются одним или несколькими символами ␣. Ожидается, что наша LSTM модель научится предлагать этот символ как следующий рекомендуемый, если она будет считать, что текст рецепта уже закончен.
До сих пор мы работали с набором данных, как и с NumPy массивом. В процессе обучения будет удобнее, если мы преобразуем NumPy массив данных в TensorFlow dataset. Это даст нам возможность использовать такие вспомогательные функции, как batch(), shuffle(), repeat(), prefecth() и пр.:
dataset = tf.data.Dataset.from_tensor_slices(dataset_vectorized_padded)
print(dataset)➔ вывод:
<TensorSliceDataset shapes: (2001,), types: tf.int32>
Выведем первый рецепт из набора данных, используя API набора данных TensorFlow:
for recipe in dataset.take(1):
print('Raw recipe:\n', recipe.numpy(), '\n\n\n')
print('Stringified recipe:\n')
recipe_sequence_to_string(recipe.numpy())➔ вывод:
Raw recipe: [ 51 1 33 ... 165 165 165] Stringified recipe: ◘ Slow Cooker Chicken and Dumplings ❖ • 4 skinless, boneless chicken breast halves • 2 tablespoons butter • 2 (10.75 ounce) cans condensed cream of chicken soup • 1 onion, finely diced • 2 (10 ounce) packages refrigerated biscuit dough, torn into pieces ✼ ︎ Place the chicken, butter, soup, and onion in a slow cooker, and fill with enough water to cover. ︎ Cover, and cook for 5 to 6 hours on High. About 30 minutes before serving, place the torn biscuit dough in the slow cooker. Cook until the dough is no longer raw in the center. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣
входную и целевую последовательностиНейронная сеть нуждается в подсказках во время обучения. Например, когда мы будем подавать на вход символ H мы должны сообщить сети, какой символ мы ждем следующим (пускай е). Получив от нас подсказки по поводу каждого символа каждого рецепта, модель будет пытаться найти зависимости между символами.
Поэтому для последовательности с текстом рецепта нам необходимо продублировать и сместить ее на один символ, чтобы сформировать входную и целевую последовательности. Например, если sequence_length равна 4, а наш текст — это Hello, то входная последовательность будет Hell, а целевая последовательность — ello.
def split_input_target(recipe):
input_text = recipe[:-1]
target_text = recipe[1:]
return input_text, target_text
dataset_targeted = dataset.map(split_input_target)
print(dataset_targeted)➔ вывод:
<MapDataset shapes: ((2000,), (2000,)), types: (tf.int32, tf.int32)>
Вы можете заметить теперь, что каждый экземпляр данных из нашего набора теперь представляет собой tuple из двух последовательностей: входящей и целевой:
for input_example, target_example in dataset_targeted.take(1):
print('Input sequence size:', repr(len(input_example.numpy())))
print('Target sequence size:', repr(len(target_example.numpy())))
print()
input_stringified = tokenizer.sequences_to_texts([input_example.numpy()[:50]])[0]
target_stringified = tokenizer.sequences_to_texts([target_example.numpy()[:50]])[0]
print('Input: ', repr(''.join(input_stringified)))
print('Target: ', repr(''.join(target_stringified)))➔ вывод:
Input sequence size: 2000 Target sequence size: 2000 Input: '◘ S l o w C o o k e r C h i c k e n a n d D u m p l i n g s \n \n ❖ \n \n • 4 s k i n l e' Target: ' S l o w C o o k e r C h i c k e n a n d D u m p l i n g s \n \n ❖ \n \n • 4 s k i n l e s'
Каждый индекс этих двух последовательностей будет пошагово обрабатываться нашей нейронной сетью. На нулевом шаге модель получит индекс символа ◘ на входе и для него она должна будет предсказать индекс символа ` (символ пробела в данном случае) в качестве следующего символа. На следующем шаге модель получит индекс символа (пробел) на входе и должна будет предсказать индекс символаS` на выходе. При этом на каждом следующем шаге на вход модели будет поступать не только новый символ, но также и сохраненное внутреннее состояние модели, которое позволит ей принимать во внимание не только один символ, но также и историю нескольких предыдущих символов.
for i, (input_idx, target_idx) in enumerate(zip(input_example[:10], target_example[:10])):
print('Step {:2d}'.format(i + 1))
print(' input: {} ({:s})'.format(input_idx, repr(tokenizer.sequences_to_texts([[input_idx.numpy()]])[0])))
print(' expected output: {} ({:s})'.format(target_idx, repr(tokenizer.sequences_to_texts([[target_idx.numpy()]])[0])))➔ вывод:
Step 1 input: 51 ('◘') expected output: 1 (' ') Step 2 input: 1 (' ') expected output: 33 ('S') Step 3 input: 33 ('S') expected output: 10 ('l') Step 4 input: 10 ('l') expected output: 5 ('o') Step 5 input: 5 ('o') expected output: 23 ('w') Step 6 input: 23 ('w') expected output: 1 (' ') Step 7 input: 1 (' ') expected output: 35 ('C') Step 8 input: 35 ('C') expected output: 5 ('o') Step 9 input: 5 ('o') expected output: 5 ('o') Step 10 input: 5 ('o') expected output: 25 ('k')
В наборе данных мы имеем около ~100000 рецептов каждый из которых имеет длину 2000 символов.
print(dataset_targeted)➔ вывод:
<MapDataset shapes: ((2000,), (2000,)), types: (tf.int32, tf.int32)>
Выведем параметры набора данных:
print('TOTAL_RECIPES_NUM: ', TOTAL_RECIPES_NUM)
print('MAX_RECIPE_LENGTH: ', MAX_RECIPE_LENGTH)
print('VOCABULARY_SIZE: ', VOCABULARY_SIZE)➔ вывод:
TOTAL_RECIPES_NUM: 100212 MAX_RECIPE_LENGTH: 2000 VOCABULARY_SIZE: 176
Если во время тренировочного процесса мы передадим полный набор данных модели, а затем попробуем рассчитать backpropagation для всех рецептов сразу, то у нас может закончиться память, и каждая тренировочная эпоха может занять слишком много времени. Чтобы избежать такой ситуации, нам нужно разделить наш набор данных на пакеты.
# Batch size.
BATCH_SIZE = 64
# Размер буфера для перемешивания данных.
# Перемешать все 100000 рецептов может быть ресурсозатратно.
# Поэтому можем перемешивать пачками по 1000 рецептов.
SHUFFLE_BUFFER_SIZE = 1000
dataset_train = dataset_targeted \
# Вначале перемешиваем рецепты.
.shuffle(SHUFFLE_BUFFER_SIZE) \
# Разбиваем на группы.
.batch(BATCH_SIZE, drop_remainder=True) \
# Зацикливаем набор данных.
.repeat()
print(dataset_train)➔ вывод:
<RepeatDataset shapes: ((64, 2000), (64, 2000)), types: (tf.int32, tf.int32)>
Из вывода в консоль выше можно заметить, что теперь каждый экземпляр нашего набора данных состоит из все тех же двух tuples для входящей и целевой последовательностей, но теперь они сгруппированы в пачки по 64.
for input_text, target_text in dataset_train.take(1):
print('1st batch: input_text:', input_text)
print()
print('1st batch: target_text:', target_text)➔ вывод:
1st batch: input_text: tf.Tensor( [[ 51 1 54 ... 165 165 165] [ 51 1 64 ... 165 165 165] [ 51 1 44 ... 165 165 165] ... [ 51 1 69 ... 165 165 165] [ 51 1 55 ... 165 165 165] [ 51 1 70 ... 165 165 165]], shape=(64, 2000), dtype=int32) 1st batch: target_text: tf.Tensor( [[ 1 54 4 ... 165 165 165] [ 1 64 5 ... 165 165 165] [ 1 44 6 ... 165 165 165] ... [ 1 69 3 ... 165 165 165] [ 1 55 3 ... 165 165 165] [ 1 70 2 ... 165 165 165]], shape=(64, 2000), dtype=int32)
Возьмем tf.keras.Sequential модель за основу. В данном эксперименте мы будем использовать следующие слои:
embedding_dim),VOCABULARY_SIZE количеством выходов.Embedding layer принимает на вход последовательность (группу, пачку) индексов и кодирует каждый индекс в вектор длиной tmp_embedding_size:
tmp_vocab_size = 10
tmp_embedding_size = 5
tmp_input_length = 8
tmp_batch_size = 2
tmp_model = tf.keras.models.Sequential()
tmp_model.add(tf.keras.layers.Embedding(
input_dim=tmp_vocab_size,
output_dim=tmp_embedding_size,
input_length=tmp_input_length
))
# The model will take as input an integer matrix of size (batch, input_length).
# The largest integer (i.e. word index) in the input should be no larger than 9 (tmp_vocab_size).
# Now model.output_shape == (None, 10, 64), where None is the batch dimension.
tmp_input_array = np.random.randint(
low=0,
high=tmp_vocab_size,
size=(tmp_batch_size, tmp_input_length)
)
tmp_model.compile('rmsprop', 'mse')
tmp_output_array = tmp_model.predict(tmp_input_array)
print('tmp_input_array shape:', tmp_input_array.shape)
print('tmp_input_array:')
print(tmp_input_array)
print()
print('tmp_output_array shape:', tmp_output_array.shape)
print('tmp_output_array:')
print(tmp_output_array)➔ вывод:
tmp_input_array shape: (2, 8) tmp_input_array: [[2 4 7 5 1 6 9 7] [3 6 8 1 4 0 1 2]] tmp_output_array shape: (2, 8, 5) tmp_output_array: [[[-0.02229502 -0.02800617 -0.0120693 -0.01681594 -0.00650246] [-0.03046973 -0.03920818 0.04956308 0.04417323 -0.00446874] [-0.0215276 0.01532575 -0.02229529 0.02834387 0.02725342] [ 0.04567988 0.0141306 0.00877035 -0.02601192 0.00380837] [ 0.02969306 0.02994296 -0.00233263 0.00716375 -0.00847433] [ 0.04598364 -0.00704358 -0.01386416 0.01195388 -0.00309662] [-0.00137572 0.01275543 -0.02348721 -0.04825885 0.00527108] [-0.0215276 0.01532575 -0.02229529 0.02834387 0.02725342]] [[ 0.01082945 0.03824175 -0.00450991 -0.02865709 0.02502238] [ 0.04598364 -0.00704358 -0.01386416 0.01195388 -0.00309662] [ 0.02275398 0.03806095 -0.03491788 0.04705564 0.00167596] [ 0.02969306 0.02994296 -0.00233263 0.00716375 -0.00847433] [-0.03046973 -0.03920818 0.04956308 0.04417323 -0.00446874] [-0.02909902 0.04426369 0.00150937 0.04579213 0.02559013] [ 0.02969306 0.02994296 -0.00233263 0.00716375 -0.00847433] [-0.02229502 -0.02800617 -0.0120693 -0.01681594 -0.00650246]]]
Начнем собирать модель.
В статье Text generation with an RNN вы можете найти более детальную информацию о слоях модели.
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Embedding(
input_dim=vocab_size,
output_dim=embedding_dim,
batch_input_shape=[batch_size, None]
))
model.add(tf.keras.layers.LSTM(
units=rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer=tf.keras.initializers.GlorotNormal()
))
model.add(tf.keras.layers.Dense(vocab_size))
return model
model = build_model(
vocab_size=VOCABULARY_SIZE,
embedding_dim=256,
rnn_units=1024,
batch_size=BATCH_SIZE
)
model.summary()➔ вывод:
Model: "sequential_13" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_13 (Embedding) (64, None, 256) 45056 _________________________________________________________________ lstm_9 (LSTM) (64, None, 1024) 5246976 _________________________________________________________________ dense_8 (Dense) (64, None, 176) 180400 ================================================================= Total params: 5,472,432 Trainable params: 5,472,432 Non-trainable params: 0 _________________________________________________________________
Визуализируем модель:
tf.keras.utils.plot_model(
model,
show_shapes=True,
show_layer_names=True,
to_file='model.png'
)➔ вывод:

Для каждого символа модель находит соответствующий embedding вектор, подает его на вход LSTM, вывод LSTM подается на выходной слой модели, который для каждого символа в словаре генерирует его вероятность появления следующим.

Источник изображения: Text generation with an RNN.
Изображение выше иллюстрирует случай с сетью GRU, но оно также справедливо и для случая с LSTM.
Протестируем как работает необученная модель и посмотрим, что она предсказывает перед тренировкой:
for input_example_batch, target_example_batch in dataset_train.take(1):
example_batch_predictions = model(input_example_batch)
print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")➔ вывод:
(64, 2000, 176) # (batch_size, sequence_length, vocab_size)
Для того, чтобы выбрать символ, который по мнению модели должен идти следующим нам необходимо сделать sampling по вероятностям появления каждого символа.
print('Prediction for the 1st letter of the batch 1st sequense:')
print(example_batch_predictions[0, 0])➔ вывод:
Prediction for the 1st letter of the batch 1st sequense: tf.Tensor( [-9.0643829e-03 -1.9503604e-03 9.3381782e-04 3.7442446e-03 -2.0541784e-03 -7.4054599e-03 -7.1884273e-03 2.6014952e-03 4.8721582e-03 3.0045470e-04 2.6016519e-04 -4.1374690e-03 5.3856964e-03 2.6284808e-03 -5.6002503e-03 2.6019611e-03 -1.9491187e-03 -3.1097094e-04 6.3465843e-03 1.4640498e-03 2.4560774e-03 -3.1256995e-03 1.4104056e-03 2.5478401e-04 5.4266443e-03 -4.1188141e-03 3.6904984e-03 -5.8337618e-03 3.6372752e-03 -3.1899021e-05 3.2178329e-03 1.5033322e-04 5.2770867e-04 -8.1920059e-04 -2.2364906e-03 -2.3271297e-03 4.4109682e-03 4.2381673e-04 1.0532180e-03 -1.4208974e-03 -3.2446394e-03 -4.5869066e-03 4.3250201e-04 -4.3490473e-03 3.7889536e-03 -9.2122913e-04 7.8936084e-04 -9.7079907e-04 1.7070504e-03 -2.5260956e-03 6.7904620e-03 1.5470090e-03 -9.4337866e-04 -1.5072266e-03 6.8939931e-04 -1.0795534e-03 -3.1912089e-03 2.3665284e-03 1.7737487e-03 -2.3504677e-03 -6.8649277e-04 9.6421910e-04 -4.1204207e-03 -3.8750230e-03 1.9077851e-03 4.7145790e-05 -2.9846188e-03 5.8050319e-03 -5.6210475e-04 -2.5910907e-04 5.2890396e-03 -5.8653783e-03 -6.0040038e-06 2.3905798e-03 -2.9405006e-03 2.0132761e-03 -3.5594390e-03 4.0282350e-04 4.7719614e-03 -2.4438011e-03 -1.1028582e-03 2.0007135e-03 -1.6961874e-03 -4.2196750e-03 -3.5689408e-03 -4.1934610e-03 -8.5307617e-04 1.5773368e-04 -1.4612130e-03 9.5826073e-04 4.0543079e-04 -2.3562380e-04 -1.5394683e-03 3.6650903e-03 3.5997448e-03 2.2390878e-03 -6.8982318e-04 1.4068574e-03 -2.0531749e-03 -1.5443334e-03 -1.8235333e-03 -3.2099178e-03 1.6660831e-03 1.2230751e-03 3.8084832e-03 6.9559496e-03 5.7684043e-03 3.1751506e-03 7.4234616e-04 1.1971325e-04 -2.7798198e-03 2.1485630e-03 4.0362971e-03 6.4410735e-05 1.7432809e-03 3.2334479e-03 -6.1469898e-03 -2.2205685e-03 -1.0864032e-03 -2.0876178e-07 2.3065242e-03 -1.5816523e-03 -2.1492387e-03 -4.4033155e-03 1.1003019e-03 -9.7132073e-04 -6.3941808e-04 3.0277157e-03 2.9096641e-03 -2.4778468e-03 -2.9532036e-03 7.7463314e-04 2.7473709e-03 -7.6333171e-04 -8.1811845e-03 -1.3959130e-03 3.2840301e-03 6.0461317e-03 -1.3022404e-04 -9.4000692e-04 -2.0096730e-04 3.3895797e-03 2.9710699e-03 1.9046264e-03 2.5092331e-03 -2.0799250e-04 -2.2211851e-04 -3.4621451e-05 1.9962704e-03 -2.3159904e-03 2.9832027e-03 3.3852295e-03 3.4411502e-04 -1.9019389e-03 -3.6734296e-04 -1.4232489e-03 2.6938838e-03 -2.8015859e-03 -5.7366290e-03 8.0239226e-04 -6.2909431e-04 1.1508183e-03 -1.5899434e-04 -5.9326587e-04 -4.1618512e-04 5.2454891e-03 1.2823739e-03 -1.7550631e-03 -3.0120560e-03 -3.8433261e-03 -9.6873334e-04 1.9963509e-03 1.8154597e-03 4.7434499e-03 1.7146189e-03 1.1544267e-03], shape=(176,), dtype=float32)
Для каждого символа на входе модели массив example_batch_predictions содержит вектор (массив) вероятностей того, какой символ может быть следующим. Если вероятность в позиции 15 этого вектора, пускай, равна 0.3, а вероятность в позиции 25 равна 1.1 это означает, что стоит выбрать символ с индексом 25 в качестве прогнозируемого (следующего).
Поскольку мы хотим, чтобы наша модель генерировала разные рецепты (даже при условии одинаковых входных данных), мы не можем всегда выбирать символ с максимальной вероятностью в качестве следующего. Если бы выбирали следующий символ по критерию его максимальной вероятности, то наша модель генерировала бы один и тот же рецепт снова и снова (при одинаковых входных данных). Вместо этого, мы можем попробовать sampling по вероятностям с помощью функции tf.random.categorical(). Это привнесет своего рода "случайность" или "импровизацию" в предсказания модели. Например, допустим, мы имеем в качестве входа символ H. После семплинга, наша сеть может предсказать не только слово He, но и слова Hello, Hi и т.п.
tf.random.categorical()Одним из параметров функции tf.random.categorical() является logits. Логиты — это матрица размерностью [batch_size, num_classes]. Каждый ряд этой матрицы [i, :] представляет собой вероятности для каждого класса (в нашем случае дла каждого символа из словаря). В примере ниже вероятность для класса с индексом 0 низкая, но вероятность для класса с индексом 2 — выше. Теперь, предположим, что мы хотим сделать семплинг по этим вероятностям и генерировать, пускай, 5 следующих предсказаний. В таком случае вероятности появления каждого класса будут учтены функцией tf.random.categorical() и она выдаст нам тензор с 5-ю индексами классов. Мы ожидаем, что класс с индексом 2 будет встречаться чаще остальных.
tmp_logits = [
[-0.95, 0, 0.95],
];
tmp_samples = tf.random.categorical(
logits=tmp_logits,
num_samples=5
)
print(tmp_samples)➔ вывод:
tf.Tensor([[2 1 2 2 1]], shape=(1, 5), dtype=int64)
sampled_indices = tf.random.categorical(
logits=example_batch_predictions[0],
num_samples=1
)
sampled_indices = tf.squeeze(
input=sampled_indices,
axis=-1
).numpy()
sampled_indices.shape➔ вывод:
(2000,)
Посмотрим, что модель предсказывает для первых 100 символов рецепта:
sampled_indices[:100]➔ вывод:
array([ 64, 21, 91, 126, 170, 42, 146, 54, 125, 164, 60, 171, 9, 87, 129, 28, 146, 103, 41, 101, 147, 3, 134, 171, 8, 170, 105, 5, 44, 173, 5, 105, 17, 138, 165, 32, 88, 96, 145, 83, 33, 65, 172, 162, 8, 29, 147, 58, 81, 153, 150, 56, 156, 38, 144, 134, 13, 40, 17, 50, 27, 35, 39, 112, 63, 139, 151, 133, 68, 29, 91, 2, 70, 112, 135, 31, 26, 156, 118, 71, 49, 104, 75, 27, 164, 41, 117, 124, 18, 137, 59, 160, 158, 119, 173, 50, 78, 45, 121, 118])
После трансформации предсказанных индексов в символы мы можем увидеть, как еще необученная модель генерирует рецепты:
print('Input:\n', repr(''.join(tokenizer.sequences_to_texts([input_example_batch[0].numpy()[:50]]))))
print()
print('Next char prediction:\n', repr(''.join(tokenizer.sequences_to_texts([sampled_indices[:50]]))))➔ вывод:
Input: '◘ R e s t a u r a n t - S t y l e C o l e s l a w I \n \n ❖ \n \n • 1 ( 1 6 o u n c e ) p' Next char prediction: 'H . î ⁄ ă ( “ I º Â 8 ̀ s % ù y “ 0 ’ ‧ a ì ̀ r ă + o A € o + m × ␣ ︎ ñ ç ‱ ! S : ⅞ ´ r 2 ‧ D Q Á'
В качестве оптимизатора возьмем tf.keras.optimizers.Adam, а для функции потерь воспользуемся функцией tf.keras.losses.sparse_categorical_crossentropy():
# Функция потерь.
# Сигнатура: scalar_loss = fn(y_true, y_pred).
def loss(labels, logits):
entropy = tf.keras.losses.sparse_categorical_crossentropy(
y_true=labels,
y_pred=logits,
from_logits=True
)
return entropy
example_batch_loss = loss(target_example_batch, example_batch_predictions)
print("Prediction shape: ", example_batch_predictions.shape, " # (batch_size, sequence_length, vocab_size)")
print("scalar_loss.shape: ", example_batch_loss.shape)
print("scalar_loss: ", example_batch_loss.numpy().mean())➔ вывод:
Prediction shape: (64, 2000, 176) # (batch_size, sequence_length, vocab_size) scalar_loss.shape: (64, 2000) scalar_loss: 5.1618285
Компилируем модель:
adam_optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(
optimizer=adam_optimizer,
loss=loss
)Во время тренировки модели мы можем воспользоваться колбеком tf.keras.callbacks.EarlyStopping. Он останавливает процесс тренировки автоматически, если показатели модели ухудшаются в течение определенного количества эпох:
early_stopping_callback = tf.keras.callbacks.EarlyStopping(
patience=5,
monitor='loss',
restore_best_weights=True,
verbose=1
)Мы также можем настроить автоматическое сохранение параметров модели во время тренировки с помощью колбека tf.keras.callbacks.ModelCheckpoint. Это позволит нам в будущем восстановить модель из сохраненных контрольных точек без ее тренировки.
# Create a checkpoints directory.
checkpoint_dir = 'tmp/checkpoints'
os.makedirs(checkpoint_dir, exist_ok=True)
checkpoint_prefix = os.path.join(checkpoint_dir, 'ckpt_{epoch}')
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True
)Будем тренировать модель в течение 500 эпох с 1500 шагами на каждую эпоху. На каждом шагу, модель будет обучаться на группе из 64 рецептов. Градиентный спуск на каждом также будет выполнен для группы из 64 рецептов (каждый из которых состоит из 2000 символов).
Если вы экспериментируете с тренировочными параметрами, то, возможно, имеет смысл уменьшить количество эпох до, скажем, 20 вместе с количеством шагов на эпоху, а затем посмотреть, как модель работает в этих условиях. Если модель улучшит свою производительность, вы можете добавить больше данных (шагов и эпох) в тренировочный процесс. Это может сэкономить время на настройку параметров модели.
EPOCHS = 500
INITIAL_EPOCH = 1
STEPS_PER_EPOCH = 1500
print('EPOCHS: ', EPOCHS)
print('INITIAL_EPOCH: ', INITIAL_EPOCH)
print('STEPS_PER_EPOCH: ', STEPS_PER_EPOCH)➔ вывод:
EPOCHS: 500 INITIAL_EPOCH: 1 STEPS_PER_EPOCH: 1500
Запускаем тренировку:
history = model.fit(
x=dataset_train,
epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
initial_epoch=INITIAL_EPOCH,
callbacks=[
checkpoint_callback,
early_stopping_callback
]
)
# Saving the trained model to file (to be able to re-use it later).
model_name = 'recipe_generation_rnn_raw.h5'
model.save(model_name, save_format='h5')def render_training_history(training_history):
loss = training_history.history['loss']
plt.title('Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(loss, label='Training set')
plt.legend()
plt.grid(linestyle='--', linewidth=1, alpha=0.5)
plt.show()
render_training_history(history)➔ вывод:

На графике сверху представлены только первые 10 шагов тренировки.
Из диаграммы видно, что погрешность модели уменьшается во время обучения. Это означает, что модель учится предсказывать следующие символы таким образом, чтобы окончательная последовательность выглядит более и более похожей на реальные тексты рецептов.
Для упрощения генерации рецептов, мы создадим нашу модель заново, но на этот раз с batch_size равным 1. Это будет значит, что вместо группы из 64 последовательностей на входе мы будем ожидать всего одну последовательность. Эта последовательность представляет собой начало нового рецепта. Продолжение рецепта будет сгенерировано нейронной сетью.
tf.train.latest_checkpoint(checkpoint_dir)➔ вывод:
'tmp/checkpoints/ckpt_1'
Перестроим нашу модель с batch_size равным 1 и загрузим сохраненные в контрольных точках параметры модели, чтобы нам не пришлось тренировать ее заново:
simplified_batch_size = 1
model_simplified = build_model(vocab_size, embedding_dim, rnn_units, simplified_batch_size)
model_simplified.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model_simplified.build(tf.TensorShape([simplified_batch_size, None]))
model_simplified.summary()➔ вывод:
Model: "sequential_6" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_6 (Embedding) (1, None, 256) 45056 _________________________________________________________________ lstm_5 (LSTM) (1, None, 1024) 5246976 _________________________________________________________________ dense_5 (Dense) (1, None, 176) 180400 ================================================================= Total params: 5,472,432 Trainable params: 5,472,432 Non-trainable params: 0 _________________________________________________________________
Проверим, что на вход ожидается группа из одной последовательности (вместо 64-х):
model_simplified.input_shape➔ вывод:
(1, None)
Чтобы использовать нашу обученную модель для генерации рецептов, нам необходимо реализовать так называемый цикл прогнозирования. Следующий блок кода генерирует текст с помощью цикла:

Источник изображения Text generation with an RNN .
Параметр temperature здесь определяет, насколько нечетким или насколько неожиданным будет сгенерированный рецепт. Низкие значения temperature приводят к более предсказуемому тексту. Более высокие значения temperature приводят к более неожиданному тексту. Мы проведем некоторые эксперименты с различными значениями temperature ниже.
def generate_text(model, start_string, num_generate = 1000, temperature=1.0):
# Evaluation step (generating text using the learned model)
padded_start_string = STOP_WORD_TITLE + start_string
# Converting our start string to numbers (vectorizing).
input_indices = np.array(tokenizer.texts_to_sequences([padded_start_string]))
# Empty string to store our results.
text_generated = []
# Here batch size == 1.
model.reset_states()
for char_index in range(num_generate):
predictions = model(input_indices)
# remove the batch dimension
predictions = tf.squeeze(predictions, 0)
# Using a categorical distribution to predict the character returned by the model.
predictions = predictions / temperature
predicted_id = tf.random.categorical(
predictions,
num_samples=1
)[-1, 0].numpy()
# We pass the predicted character as the next input to the model
# along with the previous hidden state.
input_indices = tf.expand_dims([predicted_id], 0)
next_character = tokenizer.sequences_to_texts(input_indices.numpy())[0]
text_generated.append(next_character)
return (padded_start_string + ''.join(text_generated))temperatureВоспользуемся функцией generate_text() для генерации рецептов. Функция generate_combinations() генерирует 56 различных комбинаций входящего текста и параметра temperature. Это должно помочь нам определиться с подходящим значением для temperature.
def generate_combinations(model):
recipe_length = 1000
try_letters = ['', '\n', 'A', 'B', 'C', 'O', 'L', 'Mushroom', 'Apple', 'Slow', 'Christmass', 'The', 'Banana', 'Homemade']
try_temperature = [1.0, 0.8, 0.4, 0.2]
for letter in try_letters:
for temperature in try_temperature:
generated_text = generate_text(
model,
start_string=letter,
num_generate = recipe_length,
temperature=temperature
)
print(f'Attempt: "{letter}" + {temperature}')
print('-----------------------------------')
print(generated_text)
print('\n\n')
Чтобы не делать эту статью слишком длинной, ниже будут напечатаны только некоторые из этих 56 комбинаций.
generate_combinations(model_simplified)➔ вывод:
Attempt: "A" + 1.0 ----------------------------------- ◘ Azzeric Sweet Potato Puree ❖ • 24 large baking potatoes, such as Carn or Marinara or 1 (14-ounce) can pot wine • 1/4 pound unsalted butter, cut into small pieces • 1/2 cup coarsely chopped scallions ✼ ︎ Bring a large pot of water to a boil, place a large nonstick skillet over medium-high heat, add All Naucocal Volves. Reduce heat to medium and cook the potatoes until just cooked through, bubbles before adding the next layer, about 10 to 12 minutes. Remove ground beans and reserve. Reserve the crumb mixture for about 6 greased. Let cool 2 minutes. Strain soak into a glass pitcher. Let cool in ice. Add short-goodfish to the batter and stir to dissolve. Pour in the cheese mixture and whisk until smooth. Set aside for 20 seconds more. Remove dumplings and cheese curds. Spread 1/3 cup of the mixture on each circle for seal ballo. Transfer mixture into a greased 9-by-11-inch baking dish and chill for 20 minutes. ︎ Bake, covered, for 30 minutes. Serve warm. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣ Attempt: "A" + 0.4 ----------------------------------- ◘ Apricot "Cookie" Cakes ❖ • 1 cup all-purpose flour • 1 cup corn flour • 1 cup sugar • 1 tablespoon baking powder • 1 teaspoon salt • 1 teaspoon ground cinnamon • 1 cup grated Parmesan • 1 cup pecans, chopped • 1/2 cup chopped pecans • 1/2 cup raisins ✼ ︎ Preheat oven to 350 degrees F. ︎ Butter and flour a 9 by 13-inch baking dish. In a medium bowl, whisk together the flour, sugar, baking powder, baking soda and salt. In a small bowl, whisk together the eggs, sugar, and eggs. Add the flour mixture to the butter mixture and mix until just combined. Stir in the raisins and pecans and transfer to the prepared pan. Spread the batter over the top of the crust. Bake for 15 minutes. Reduce the oven temperature to 350 degrees F, and bake until the cupcakes are set and the top is golden brown, about 20 minutes more. Transfer the cake to a wire rack to cool to room temperature. Refrigerate until ready to serve. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣ Attempt: "A" + 0.2 ----------------------------------- ◘ Alternative to the Fondant ❖ • 1 cup sugar • 1 cup water • 1 cup heavy cream • 1 teaspoon vanilla extract • 1/2 cup heavy cream • 1/2 cup heavy cream • 1 teaspoon vanilla extract • 1/2 cup chopped pecans ✼ ︎ In a saucepan over medium heat, combine the sugar, sugar, and corn syrup. Cook over medium heat until the sugar is dissolved. Remove from the heat and stir in the vanilla. Refrigerate until cold. Stir in the chocolate chips and the chocolate chips. Serve immediately. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣ Attempt: "B" + 0.4 ----------------------------------- ◘ Battered French Toast with Bacon, Bacon, and Caramelized Onions and Pecorino ❖ • 1/2 pound squid (shredded carrots) • 1 small onion, diced • 1 small green pepper, seeded and cut into strips • 1 red bell pepper, stemmed, seeded and cut into 1/4-inch dice • 1 small onion, chopped • 1 green bell pepper, chopped • 1 cup chicken stock • 1 cup heavy cream • 1/2 cup shredded sharp Cheddar • 1 teaspoon ground cumin • 1 teaspoon salt • 1 teaspoon freshly ground black pepper ✼ ︎ Preheat the oven to 350 degrees F. ︎ For the bacon mixture: In a large bowl, combine the cheese, sour cream, mustard, salt, pepper, and hot sauce. Stir together and mix well. Fold in the milk and set aside. ︎ For the filling: In a large bowl, mix the flour and salt and pepper, to taste. Add the beaten eggs and mix to combine. Set aside. ︎ For the topping: Mix the cream cheese with the mayonnaise, salt and pepper in a medium bowl. Add the chicken and toss to coat the other side. Transfer the mixture to the prepared Attempt: "C" + 1.0 ----------------------------------- ◘ Crema battered Salmon ❖ • 1 cup fresh cranberries (from 4 tablespoons left of 4 egg whites) • 3 teaspoons sugar • 1 tablespoon unsalted butter • 2 tablespoons truffle oil • Coarse salt • Freshly ground black pepper ✼ ︎ Place cornmeal in a small serving bowl, and combine it. Drizzle milk over the plums and season with salt and pepper. Let stand for about 5 minutes, until firm. Serve immediately. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣ Attempt: "C" + 0.8 ----------------------------------- ◘ Classic Iseasteroles ❖ • 3 cups milk • 3/4 cup coconut milk • 1/2 cup malted maple syrup • 1/2 teaspoon salt • 3 cups sugar • 4 1-inch strawberries, sliced into 1/4-inch pieces • 1/2 teaspoon ground cinnamon ✼ ︎ Place the cherries in a small saucepan; sprinkle with the sugar. Bring to a simmer over medium-low heat, then remove from the heat. Let stand until the coconut fluffy, about 15 to 20 minutes. Drain the coconut oil in a stream, whisking until combined. Add the cream, espresso and cocoa powder and stir to combine. Cover and refrigerate until ready to serve. Makes 10 to 12 small springs in the same fat from the surface of the bowl, which using paper colors, and freeze overnight. ︎ Meanwhile, combine the cream, sugar, vanilla and salt in a medium saucepan. Cook over medium heat until the sugar dissolves and the sugar melts and begins to boil, about 5 minutes. Remove from the heat and stir in the vanilla. ︎ To serve, carefully remove the pops from the casserole and put them in Attempt: "C" + 0.4 ----------------------------------- ◘ Cinnamon Corn Cakes with Coconut Flour and Saffron Sauce ❖ • 3 cups shredded sharp Cheddar • 1 cup grated Parmesan • 2 cups shredded sharp Cheddar • 1 cup grated Parmesan • 1 cup shredded part-skim mozzarella cheese • 1 cup grated Parmesan • 1 cup grated Parmesan • 1 cup grated Parmesan • 1 teaspoon kosher salt • 1/2 teaspoon freshly ground black pepper ✼ ︎ Preheat the oven to 400 degrees F. Line a baking sheet with a silpat and preheat the oven to 350 degrees F. ︎ In a large bowl, combine the masa harina, cumin, cayenne, and salt and pepper. Dredge the pasta in the flour and then dip in the egg mixture, then dip in the eggs, then dip in the egg mixture and then dredge in the breadcrumbs. Place the breaded cheese on a sheet tray. Bake until the crust is golden brown and the filling is bubbling, about 25 to 30 minutes. Remove from the oven and serve hot. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣ Attempt: "L" + 0.4 ----------------------------------- ◘ Lighted Flan with Chocolate and Pecans ❖ • 2 cups milk • 1 cup sugar • 1 teaspoon vanilla extract • 1 cup heavy cream • 1/2 cup heavy cream • 1 tablespoon powdered sugar • 1 teaspoon vanilla extract • 1/2 cup heavy cream • 1/2 teaspoon ground cinnamon • 1/2 teaspoon ground nutmeg • 1/2 cup chopped pecans ✼ ︎ Watch how to make this recipe. ︎ In a small saucepan, combine the sugar, salt, and a pinch of salt. Cook over medium heat, stirring occasionally, until the sugar has dissolved. Remove from the heat and set aside to cool. Remove the cherries from the refrigerator and place in the freezer for 1 hour. ︎ In a blender, combine the milk, sugar, vanilla, salt and water. Blend until smooth. Pour the mixture into a 9-by-13-inch glass baking dish and set aside. ︎ In a small saucepan, combine the remaining 2 cups sugar, the vanilla, and 2 cups water. Bring the mixture to a boil, and then reduce the heat to low. Cook until the sugar is dissolved, about 5 minutes. Remove from the heat an Attempt: "L" + 0.2 ----------------------------------- ◘ Lighted Fondanta with Chocolate and Cream Cheese Frosting ❖ • 1 cup heavy cream • 1 tablespoon sugar • 1 tablespoon vanilla extract • 1 teaspoon vanilla extract • 1 cup heavy cream • 1 cup heavy cream • 1/2 cup sugar • 1 teaspoon vanilla extract • 1 teaspoon vanilla extract • 1/2 cup chopped pistachios ✼ ︎ Preheat the oven to 350 degrees F. ︎ In a large bowl, combine the cream cheese, sugar, eggs, vanilla, and salt. Stir until smooth. Pour the mixture into the prepared baking dish. Sprinkle with the remaining 1/2 cup sugar and bake for 15 minutes. Reduce the heat to 350 degrees F and bake until the crust is golden brown, about 15 minutes more. Remove from the oven and let cool completely. Spread the chocolate chips on the parchment paper and bake until the chocolate is melted and the top is golden brown, about 10 minutes. Set aside to cool. ︎ In a medium bowl, whisk together the egg yolks, sugar, and vanilla until smooth. Stir in the cream and continue to beat until the chocolate Attempt: "Mushroom" + 1.0 ----------------------------------- ◘ Mushroom and Bacon Soup with Jumbo Sugar Coating ❖ • 2 tablespoons vegetable oil • 1 2/3 pounds red cabbage, shredded, about 4 cups of excess pasted dark ends of fat, and pocked or firm • 2 red bell peppers, cored, seeded and diced • 1 poblano pepper, chopped • 3 medium carrots, finely chopped • 1/2 medium pinch saffron • 4 cups water • 2 cups mushrooms or 1/2 cup frozen Sojo Bean red • Salt and freshly ground black pepper • 1 pound andouille sausage • 1 gallon vegetable broth • Chopped fresh parsley, cilantro leaves, for garnish ✼ ︎ In a large Dutch oven for gas burner, heat oil over moderate heat. Add the leeks to the pot, scraping the bottom of the skillet. Add the beans and sausage and sprinkle the reserved potatoes with some orange juice cooked sausage (such as The Sauce.) Add roasted vegetables and pinto beans, mozzarella, basil and bamboo shoots. Simmer rice until soup is absorbed, 15 to 20 minutes. ︎ Bring another pan of water to a boil and cook shrimp for 5 minutes. While onions Attempt: "Mushroom" + 0.8 ----------------------------------- ◘ Mushrooms with Lentil Stewed Shallots and Tomatoes ❖ • 1 tablespoon olive oil • 3 cloves garlic, smashed • Kosher salt • 1 1/2 pounds lean ground turkey • 1 cup coarsely peeled tart apples • 2 tablespoons chopped garlic • 1 teaspoon ground cumin • 1/2 teaspoon cayenne pepper • 1 teaspoon chopped fresh thyme • 3/4 cup chopped fresh basil • 1/2 small carrot, halved lengthwise and cut into 1/2-inch pieces • 1 roasted red pepper, halved and sliced vertically diced and separated into rough chops • 3 tablespoons unsalted butter • 2 cups shredded mozzarella • 1/4 cup grated parmesan cheese • 1/4 cup prepared basil pesto ✼ ︎ Stir the olive oil, garlic, thyme and 1 teaspoon salt in a saucepan; bring to a simmer over medium heat. Remove from the heat. Add the basil and toast the soup for 2 minutes. ︎ Meanwhile, heat 4 to 4 inches vegetable oil in the skillet over medium-high heat. Add the olive oil, garlic, 1/2 teaspoon salt and 1/2 teaspoon pepper and cook, stirring often, until cooked through, a Attempt: "Mushroom" + 0.4 ----------------------------------- ◘ Mushroom Ravioli with Chickpeas and Shiitake Mushrooms and Sun-Dried Tomatoes ❖ • 1 pound zucchini • 1 cup chicken broth • 1 cup fresh basil leaves • 1/2 cup chopped fresh basil leaves • 1/2 cup grated Parmesan • 1 teaspoon salt • 1/2 teaspoon freshly ground black pepper • 1 teaspoon chopped fresh thyme • 1 teaspoon fresh lemon juice • 2 cups chicken broth • 1/2 cup grated Parmesan • 1/2 cup grated Parmigiano-Reggiano ✼ ︎ Preheat oven to 450 degrees F. ︎ Place the bread cubes in a large bowl. Add the basil, parsley, olive oil, parsley, thyme, basil, salt and pepper and toss to coat. Spread the mixture out on a baking sheet and bake until the sausages are cooked through, about 20 minutes. Serve immediately. ︎ In a small saucepan, bring the chicken stock to a boil. Reduce the heat to low and cook the soup until the liquid is absorbed. Remove from the heat and stir in the parsley, shallots and season with salt and pepper. Serve immediately. ␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣␣ Attempt: "Mushroom" + 0.2 ----------------------------------- ◘ Mushroom and Spicy Sausage Stuffing ❖ • 1 tablespoon olive oil • 1 medium onion, chopped • 2 cloves garlic, minced • 1 cup frozen peas • 1 cup frozen peas • 1/2 cup chopped fresh parsley • 1/2 cup grated Parmesan • 1/2 cup grated Parmesan • 1 teaspoon salt • 1/2 teaspoon freshly ground black pepper • 1 cup shredded mozzarella • 1/2 cup grated Parmesan • 1 cup shredded mozzarella • 1 cup shredded mozzarella cheese ✼ ︎ Preheat the oven to 350 degrees F. ︎ Bring a large pot of salted water to a boil. Add the pasta and cook until al dente, about 6 minutes. Drain and reserve. ︎ Meanwhile, heat the olive oil in a large skillet over medium-high heat. Add the shallots and saute until tender, about 3 minutes. Add the garlic and cook for 1 minute. Add the sausage and cook until the shallots are tender, about 3 minutes. Add the sausage and cook until tender, about 2 minutes. Add the garlic and cook, stirring, until the garlic is lightly browned, about 1 minute. Add the sausage and cook until the s
Вы можете воспользоваться Генератором рецептов прямо в браузере и поэкспериментировать с входным текстом и температурой.
Это выходит за рамки данной статьи, но модель все еще имеет следующие нюансы, которые необходимо улучшить/решить:
mushrooms в разделе ингредиентов, но они не упоминаются ни в названии рецепта, ни на этапах приготовления.