https://habrahabr.ru/company/npl/blog/334756/- Python
- Data Mining
- Big Data
- Блог компании New Professions Lab
Процесс разработки образовательной программы очень похож на процесс разработки нового продукта. И там, и там ты пытаешься вначале понять, а есть ли спрос на то, что ты собираешься производить? Существует ли в реальности та проблема, которую ты хочешь решить?
Предыстория
В этот раз для нас всё было довольно просто. Несколько выпускников нашей программы «Специалист по большим данным» в течение, наверное, года просили:
Сделайте для нас еще одну программу, где мы бы могли научиться работать с Kafka, Elasticsearch и разными инструментами экосистемы Hadoop, чтобы собирать пайплайны данных.
Потом со стороны работодателей стали «прилетать» запросы, которые собирательно можно описать так:
Data Engineer'ы – это очень горячие вакансии!
Реально их уже на протяжении полугода никак не можем закрыть.
Очень здорово, что вы обратили внимание именно на эту специальность. Сейчас на рынке очень большой перекос в сторону Data Scientist'ов, а больше половины работы по проектам – это именно инженерия.
С этого момента стало понятно, что спрос есть, и проблема существует. Надо бросаться в разработку программы!
Интересный момент в разработке образовательной программы, что ты её валидируешь не у непосредственного потенциального клиента. Ну представьте, мы подходим к человеку, который хотел бы у нас учиться, и спрашиваем: «Вот это — то, что тебе нужно?» А он вообще без понятия, потому что пока не разбирается в этом.
Поэтому программу нужно валидировать, во-первых, у тех, кто в этом разбирается — реальных data engineer'ов; во-вторых, у работодателей — ведь, это они в конечном счёте потребители нашего продукта.
Пообщавшись с шестью дата инженерами, часть из которых участвуют в найме сотрудников в команду, стало очень быстро понятно, в чем состоит основная суть работы такого человека, и какие задачи такой человек должен уметь решать.
Программа
Суть работы дата инженера заключается в том, чтобы уметь создавать пайплайны из данных, мониторить их и траблшутить, а также решать разовые ad-hoc задачи по выгрузке и трансформации данных.
Конкретизируя, получилось, что он должен уметь:
- Собирать сырые данные
- Работать с очередями и их конфигурировать
- Запускать джобы с обработкой данных (в т.ч. ML) по расписанию
- Конфигурировать BI
- Работать с реляционными БД
- Работать с noSQL
- Работать с инструментами для real-time обработки
- Пользоваться command-line tools
- Работать грамотно с окружением
В каждом из этих пунктов можно записать целый ряд различных инструментов. Есть даже
прекрасная визуализация на эту тему. Их все охватить в программе не представлялось возможным, да и нужным, поэтому мы решили, что человеку достаточно получить опыт создания одного batch- и одного real-time пайплайна. Остальное, при необходимости, он самостоятельно в будущем освоит.
Но важно, чтобы он научился делать пайплайн «от и до», чтобы не было ни одного белого пятна в этом процессе. И тут возникла проблема для нас, как организаторов.
Генератор кликов
Мы остановились на том, что наши участники будут анализировать кликстрим. Причем мы должны придумать, как мы будем его генерировать прямо им на сайты. Предпосылки такого решения следующие:
- Поскольку один из пайплайнов должен быть real-time, то статические готовые датасеты нам не подходят, нам нужно как-то генерировать данные тоже в real-time,
- Поскольку мы решили, что участники должны строить пайплайн «от и до», то это значит, что они должны собирать данные прямо с сайта, как это они бы делали в реальной жизни.
Отлично, осталось придумать как. Часть дата инженеров подсказала, что можно смотреть в сторону инструментов для тестирования сайта — например,
Selenium. Часть даже сделала уточнение, что лучше использовать
PhantomJS внутри него, поскольку он «headless», а значит, будет быстрее.
Мы воспользовались их советом, и написали свой эмулятор пользователей для сайтов наших участников. Сам не-ахти-какой-код ниже (важно: мы выдадим один и тот же сайт всем, поэтому можем в коде использовать конкретные параметры поиска, зная структуру этого сайта):
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from numpy.random import choice
import time
import numpy as np
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 YaBrowser/17.6.1.745 Yowser/2.5 Safari/537.36")
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_window_size(1024, 768)
hosts = ["35.190.***.***"]
keywords = {"music": "песн", "grammar": "англ"}
conformity = 0.9
condition = 1
def user_journey(host, journey_length, keywords, user_type, conformity):
driver.get("http://" + host)
el = driver.find_element_by_link_text("Статьи") # начинаем наш journey со статей
el.click()
print driver.current_url
for i in xrange(journey_length):
try:
links = []
the_links = []
p = 0
P = []
links = driver.find_elements_by_class_name("b-ff-articles-shortlist__a") # собираем список всех url на странице
if len(links) == 0:
links = driver.find_elements_by_class_name("b-ff-mobile-shortlist__a") # если так не удалось, то другим способом
if len(links) == 0:
links = driver.find_elements_by_class_name("b-ff-articles-tags__a") # если и так не удалось, то другим способом
links[0].click
driver.current_url
the_links = driver.find_elements_by_partial_link_text(keywords.get(user_type)) # собираем все url, содержащие ключевик
the_link = choice(the_links, 1)[0] # рандомно выбираем один из нужных url
links.append(the_link) # добавляем к списку всех ссылок на странице
p = (1-conformity)/float(len(links)-1) # рассчитываем равную вероятность для всех url, но учитывая, что у одной из них будет вероятность conformity
P = [p]*len(links) # присваиваем всему списку одну и ту же вероятность
P[-1] = conformity # у последнего элемента 'the link' меняем вероятность на conformity
l = choice(links, 1, p=P) # делаем рандомный выбор ссылки с заданным списком вероятностей
time.sleep(np.random.poisson(5)) # случайное время ожидания на странице
l[0].click()
print driver.current_url
except:
driver.close # закрыть драйвер, если что-то пошло не так
while condition == 1:
for host in hosts:
journey_length = np.random.poisson(5)
user_type = choice(keywords.keys(), 1)[0]
print user_type
user_journey(host, journey_length, keywords, user_type, conformity)
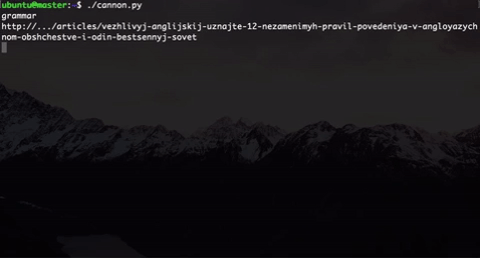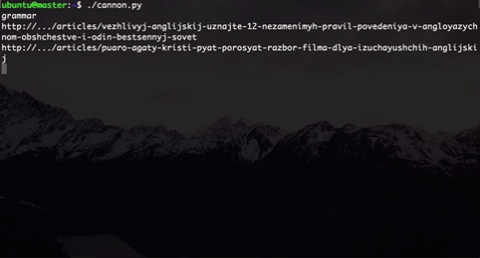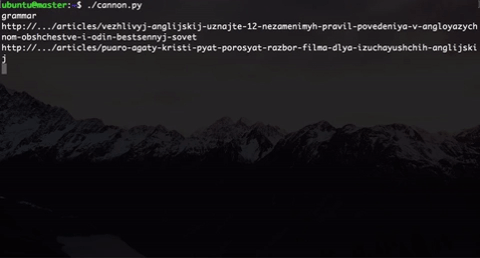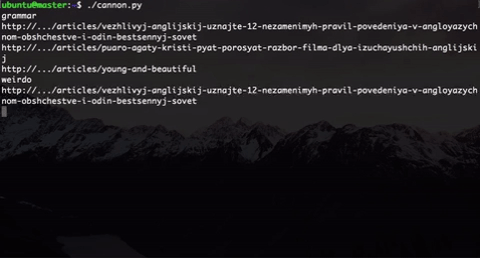
Что мы сделали? Мы генерируем пользователей разного типа. Здесь указаны два (на самом деле их больше): меломан и человек, желающий разобраться в грамматике. Выбор типа выбирается рандомно.
Внутри типа мы тоже внедрили элемент случайности: пользователь одного типа не будет ходить по одним и тем же ссылками, которые бы мы прямо захардкодили, а ссылка будет выбираться рандомно из подмножества «правильных» ссылок + есть еще элемент случайности, когда пользователь будет попадать на «неправильные» ссылки. Это было сделано, потому что в будущем участники будут анализировать эти данные и пробовать как-то сегментировать этих пользователей.
Помимо этого, чтобы прям вообще было похоже на реальное пользовательское поведение, мы внедрили рандомное время ожидания на странице. И эта пушка стреляет пока мы её не остановим.
Единственное, что группу в 20-30 человек с такой пушкой быстро не обработаешь, поэтому мы решили запускать этот скрипт через
gnu parallel. Такая строчка позволяет запустить наш скрипт параллельно на всех доступных ядрах:
$ parallel -j0 python ::: cannon.py
Итог
- Каждый участник поднимает у себя выданный нами сайт при помощи nginx.
- Присылает нам ip-адрес своего сервера.
- Внедряет на все страницы своего сайта javascript для сбора кликов.
- Собирирает данные, прилетающие из нашей пушки на его сайт.
- Передает в Kafka.
- Ну и дальше по пайплайну...
Так начинается проект, над которым он будет работать в течение 6 недель на
программе Data Engineer.