Формат таблиц в pandas
- воскресенье, 4 октября 2020 г. в 00:27:15
Если вы пока ещё не знаете как транслировать данные напрямую заказчику в подсознание или, на худой конец, текст сообщения в slack, вам пригодится информация о том, как сделать процесс интерпретации таблиц более быстрым и комфортным.
Например, в excel для этого используется условное форматирование и спарклайны. А в этой статье мы посмотрим как визуализировать данные с помощью Python и библиотеки pandas: будем использовать свойства DataFrame.style и Options and settings.
Импортируем библиотеки: pandas для работы с данными и seaborn для загрузки классического набора данных penguins:
import pandas as pd
import seaborn as snsС помощью pd.set_option настроим вывод так чтобы:
pd.set_option('max_rows', 5)
pd.set_option('display.max_colwidth', None)
pd.set_option('display.float_format', '{:.2f}'.format)Прочитаем и посмотрим датафрейм.
penguins = sns.load_dataset(‘penguins’)
penguins
Если нужно вернуть настройки к дефолтным, используем pd.reset_option. Например, так, если хотим обновить все настройки разом:
pd.reset_option('all')Полный список свойств set_option.
Формат чисел, пропуски и регистр
У датафреймов в pandas есть свойство DataFrame.style, которое меняет отображение содержимого ячеек по условию для строк или столбцов.
Например, мы можем задать количество знаков после запятой, значение для отображения пропусков и регистр для строковых столбцов.
(penguins
.head(5)
.style
.format('{:.1f}', na_rep='-')
.format({'species': lambda x:x.lower(),
'island': lambda x:x.lower(),
'sex': lambda x: '-' if pd.isna(x) else x.lower()
})
)
У нас тут всё про пингвинов, но в данные о ценах, можно добавить знак ₽ перед числом таким образом:
(df
.style
.format({'price': '₽{:.2f}'})
)Дальше — больше!
Выделение цветом (минимум, максимум, пропуски)
Функции для поиска минимального и максимального значений не работают с текстовыми полями, поэтому заранее выделим столбцы, для которых они будут применяться, в отдельный список. Этот список будем передавать в параметр subset.
numeric_columns = ['bill_length_mm',
'bill_depth_mm',
'flipper_length_mm',
'body_mass_g']Подсветим минимум, максимум и пустые ячейки и выведем первые 5 строк датафрейма.
(penguins
.head(5)
.style
.format('{:.1f}', na_rep='-')
.format({'species': lambda x:x.lower(),
'island': lambda x:x.lower(),
'sex': lambda x: '-' if pd.isna(x) else x.lower()
})
.highlight_null(null_color='lightgrey')
.highlight_max(color='yellowgreen', subset=numeric_columns)
.highlight_min(color='coral', subset=numeric_columns)
)
Наглядно видно, что в этих 5ти строках самый длинный клюв у пингвина в строке с индексом 2 и у него (неё!) же самые длинные плавники и самый маленький вес.
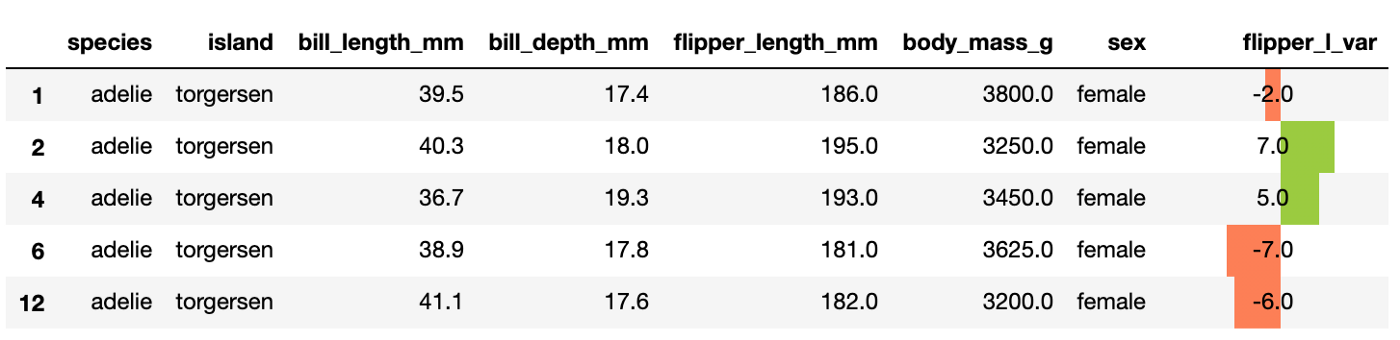
Усложним ещё немного: посмотрим на разброс длины плавников пингвинов-девочек вида Adelie.
Bar chart в таблице
Для начала, выделяем в отдельный датафрейм пингвинов женского пола и вида Adelie и считаем для них разброс длин плавников.
adelie_female = (penguins[(penguins['species'] == 'Adelie') &
(penguins['sex'] == 'FEMALE')]
.copy()
)
adelie_female['flipper_l_var'] = ((adelie_female['flipper_length_mm']-
adelie_female['flipper_length_mm'].mean()).round())К форматированию числовых значений, пропусков и регистра добавляем формат для столбца 'flipper_l_var'. Задаём:
subset), для которых будем строить график;align): mid — так как мы ожидаем, что значения будут как положительные, так и отрицательные. Подробнее про другие параметры выравнивания можно посмотреть тут;color). В нашем случае 2 цвета: для отрицательных и положительных значений;vmin, vmax).Отдельно с помощью set_properties пропишем, что значения в столбце 'flipper_l_var' должны стоять в центре ячейки.
(adelie_female
.head(5)
.style
.format('{:.1f}', na_rep='-')
.format({'species': lambda x:x.lower(),
'island': lambda x:x.lower(),
'sex': lambda x: '-' if pd.isna(x) else x.lower()
})
.bar(subset=['flipper_l_var'],
align='mid',
color=['coral', 'yellowgreen'],
vmin=adelie_female['flipper_l_var'].min(),
vmax=adelie_female['flipper_l_var'].max()
)
.set_properties(**{'text-align': 'center'}, subset='flipper_l_var')
)
Heatmap в таблице
Иногда очень удобно подсветить все значения в таблице с помощью градиента. Например, когда нужно сравнить сгруппированные данные.
Посчитаем количество пингвинов разных видов и средние значения массы, длин плавников и клюва в зависимости от вида.
species_stat=(penguins
.groupby('species')
.agg(penguins_count=('species','count'),
mean_bill_length=('bill_length_mm', 'mean'),
mean_bill_depth=('bill_depth_mm', 'mean'),
mean_flipper_length=('flipper_length_mm', 'mean'),
mean_body_mass=('body_mass_g', 'mean'),
)
)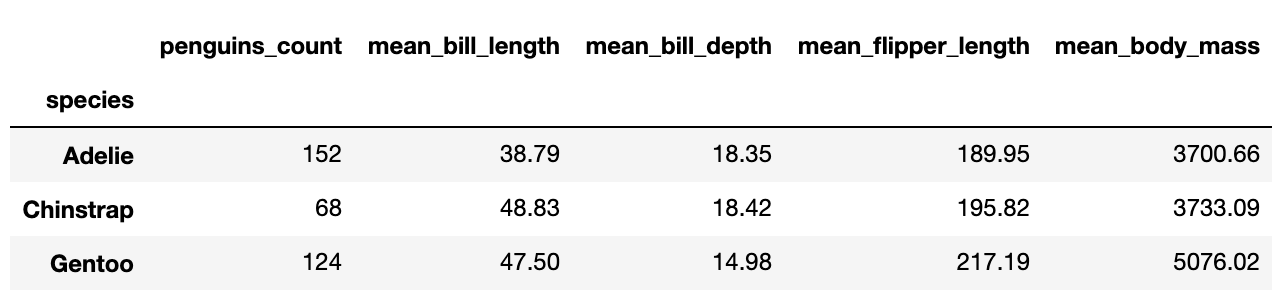
О трех видах пингвинов можно сделать выводы и по этой таблице, но если значений становится чуть больше, хочется сразу заняться чем-то более полезным, чем разглядывать ряды чисел.
Исправим это. Потому что, ну что может быть полезнее и веселее разглядывания чисел?! И если вы думаете по-другому, я не знаю, зачем вы дочитали до этого момента.
(species_stat
.T
.style
.format("{:.1f}")
.background_gradient(cmap='Blues', axis=1)
)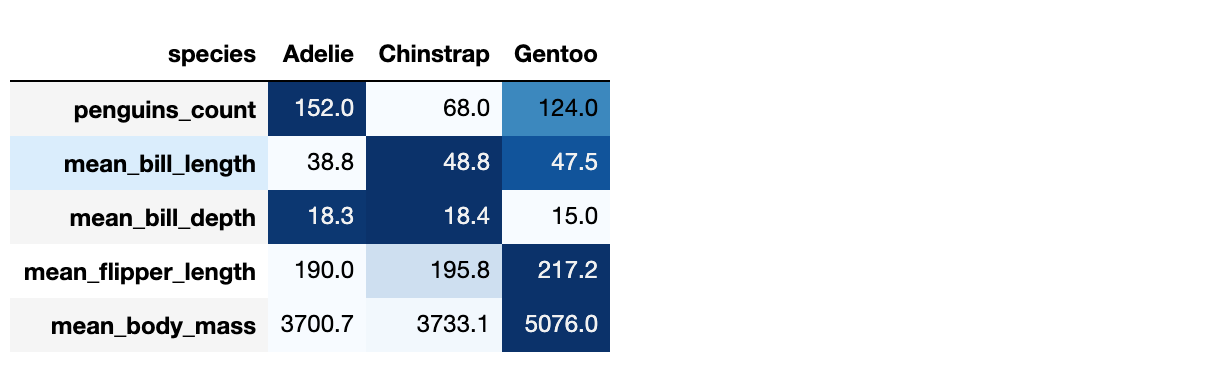
Транспонируем таблицу — так нагляднее сравнение между видами и применяем метод background_gradient со следующими параметрами:
cmap): Blues. Это одна из дефолтных карт;axis=1).Форматирование таблиц в pandas с помощью DataFrame.style и Options and settings упрощает жизнь, ну или как минимум улучшает читабельность кода и отчетов. Но обработку типов данных, пропусков и регистра лучше, конечно, проводить осознанно ещё до этапа визуализации.
highlight_max, highlight_min и highlight_null, но для более изощрённых условий можно написать свою;sparklines и PrettyPandas.