http://habrahabr.ru/post/250239/
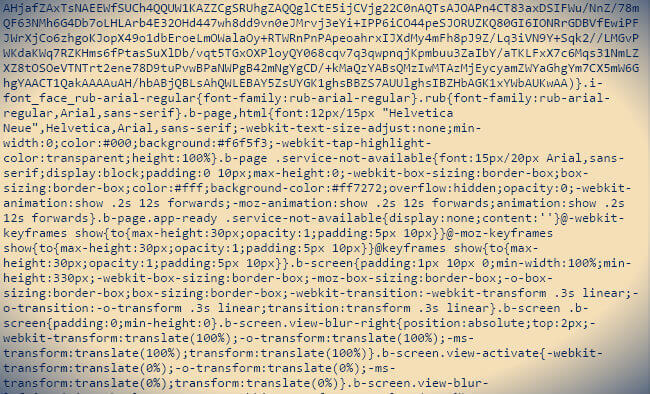
На изображении выше многие увидят известную картину. Так выглядит большинство CSS файлов на продакшене. Мы все стараемся, чтобы наши веб-страницы загружались быстро; для достижения этой цели используем различные инструменты и техники оптимизации загрузки и рендеринга страниц. Об одном, но редко используемом методе, я бы хотел поговорить и рассказать, как мне удалось сократить размер CSS файла почты
mail.ru на 180Кб.
Казалось бы, в файле, изображенном выше, уже нечего оптимизировать, все пробелы и переносы строк удаленны, файл обработан каким-нибудь умным оптимизатором типа CSSO со структурным изменением и кажется, что такой файл поймет только браузер или пьяный сантехник. Но, как мы знаем, нет предела
извращенству совершенству, а тем более оптимизации.
Далее мы попробуем выжать все соки из этого файла.
Если приглядеться, то мы заметим в этом файле кое что интересное.

Прошу обратить внимание на имена классов. Наверное, вы уже догадались, о чем пойдет речь — о сокращении длины этих имен. Потому что с приходом БЭМ и других техник написания CSS названия классов стали весьма длинными, а порой неприлично длинными.
Примеры из жизни
Я провел анализ CSS файлов, некоторых популярных ресурсов и подтвердил свое предположение:
 На изображение указаны классы, встречающиеся в продакшан версиях CSS файлов указанных сайтов
На изображение указаны классы, встречающиеся в продакшан версиях CSS файлов указанных сайтов
Наверное, никому не надо объяснять значимость скорости первоначальной загрузки страницы и ее влияние на удовлетворенность пользователей, конверсию, посещаемость сайтов. С приходом мобильных девайсов и мобильного интернета эта проблема стоит очень остро. Например, загрузка 40Кб на 4G интернете в среднем займет 700мс, а если рассмотреть 3G, EDGE, GPRS, WiFi в час пик в кафе или метро, то время загрузки значительно увеличится. Каждые сэкономленные килобайты на вес золота.
Если мы боремся за каждый пробел и перенос строки в CSS файлах, беспощадно вырезая их, то почему бы не сжимать названия классов и идентификаторов до двух или трех символов? Ведь вашим пользователям абсолютно не важно, как будет называться класс блока на странице, но им будет очень важна скорость загрузки страницы. Возможно, именно поэтому ребята из Google используют эту технику (на сайте google.com):
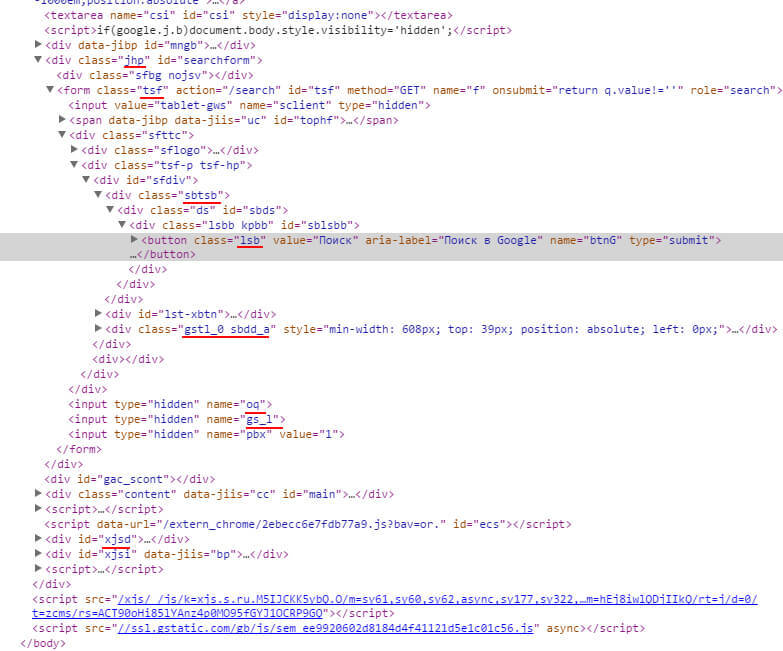
От слов к делу
Итак, с тем, зачем это нужно, надеюсь, разобрались. Приступим к делу. Первая проблема в том, что мы не можем просто так взять и сократить классы и идентификаторы в CSS файлах, потому что они используются в верстке, шаблонах и JS файлах. Заменив только в одном месте — все поломается. Становится очевидно, что надо заменить названия во всей связке файлов. В своих проектах для минификации, склеивания и прочих таких задач я использую Grunt.js. Эта система сборки является одной из самых популярных мире фронтенд-разработки. Занимаясь беглым поиском плагинов, реализующих такую задачу, я ничего не обнаружил и решил написать свой
велосипед плагин.
grunt-revizor
Так родился
grunt-revizor. При его написании я столкнулся с несколькими проблемами. В CSS файлах все просто, синтаксис заранее известен, .name или #name, но в других файлах это может выглядеть иначе. Например, в HTML
<div class="name"></div>
, т.е. name уже без точки или в JS файлах
document.getElementById('name') тоже без #, что усложняет проблему поиска и замены имен. Что наиболее страшно — можно поломать что-нибудь, например, если имя CSS класса будет ".success" и в JS файле у нас будет переменная «success», заменив ее мы поломаем JS код. А этого мы допустить не можем, поэтому пришлось ввести требования к написанию имен, а именно — имя должно оканчиваться на уникальный префикс, который однозначно даст возможность отличить класс от чего либо другого JS, HTML и других файлах. Например, .b-tabs__title-block--, в данном случае префикс '--'.
Пример таска:
grunt.initConfig({
revizor: {
options: {
namePrefix: '__',
compressFilePrefix: '-min'
},
// Найдет файлы: test/css/style1.css, test/css/style2.css, 'test/js/main.js и др...
src: ['test/css/*.css', 'test/html/*.html', 'test/js/*.js'],
dest: 'build/'
},
});
После запуска этого таска grunt найдет все CSS, HTML и JS файлы, которые соответствуют путям из src, найдет в CSS файлах все имена классов и идентификаторов, оканчивающихся на префикс __, сожмет найденные имена до двух и трех символьных, например .b-tabs--notselected__ -> .zS, после чего сохранит новые файлы, в которых будут заменены все найденные совпадения, и сохранит их в папке build, с именами style1-min.css, index-min.html, main-min.js.
Пример CSS:
/* Original: style1.css */
.b-tabs__title-block-- {
color: red;
font-size: 16px;
}
.b-tabs__selected-- {
font-weight: bold;
}
/* ======================================= */
/* Result: style1-min.css */
.eD {
color: red;
font-size: 16px;
}
.rt {
font-weight: bold;
}
Пример JS:
/* Original: main.js */
var $tabmenu = $('#tabmenu--');
var tabmenu = document.getElementById('tabmenu--');
if ($tabmenu.hasClass('b-tabs__selected--')) {
$tabmenu.removeClass('b-tabs__title-block--');
};
/* ======================================= */
/* Result: main-min.js */
var $tabmenu = $('#j3');
var tabmenu = document.getElementById('j3');
if ($tabmenu.hasClass('rt')) {
$tabmenu.removeClass('eD');
};
Такой же принцип и для HTML, template и прочих фалов.
Некоторые особенности плагина:
- Сначала генерируются 2-х символьные имена. После того, как количество имен перевалит за 2500, начнутся генерироваться 3-х символьные имена;
- Для генерации имен используются строчные и заглавные буквы латинского алфавита, цифры, символы - и _;
- Есть проверка на коллизию, т.е. сжатое имя может соответствовать только одному полному имени.
Оптимизации на примерах
Попробуем выяснить потенциальную выгоду такой оптимизации на примере тех же популярных ресурсов. Расскажу, как я буду считать. Конечно же, не буду пропускать CSS файлы через grunt-revizor, потому что в них не используется уникальный префикс. С помощью нехитрого Node файла я буду считать общее количество классов, высчитывать их длину в байтах и из этого высчитывать потенциальный размер файлов. Упрощенная формула выглядит так:
names = ['b-block1','b-block2','b-block3', ....];
saveSize = allNamesSize - (names.length*3)
// allNamesSize - Общая длина всех символов всех найденных классов
// 3 - Итоговое количество символов в сжатом название
| Сайт |
Размер оригинального файла |
Сжато |
В процентах |
|---|
| Mail.ru почта (Desktop version) |
849 Кб |
182,5 Кб |
26,4% |
| hh.ru (Desktop version) два файла |
109,8 Кб |
30 Кб |
27,3% |
| vk.com (Mobile version) два файла |
184,1 Кб |
48,5 Кб |
26,4% |
| Яндекс.Такси (Mobile version) |
127 Кб |
13 Кб |
10,3% |
| 2gis.ru (Mobile version) |
1293 Кб |
172 Кб |
13,3% |
Использовались обычные файлы, не gzip. Данные оптимизации примерные, потому что по мимо CSS файлов стили иногда были в html странице, соответственно, здесь не учитывались. Использовалась простенькая регулярка для парсинга, которая искала только классы, притом не все возможные, и она не искала идентификаторы. Помимо сжатия CSS будет выигрыш на других файлах, html, шаблонах и т.д., которые здесь тоже не учтены. Отмечу сразу, что некоторые файлы мало подаются такой оптимизации, например, файлы где мало классов или используются короткие имена, или много изображений, вставленных через data:URL, что демонстрируется на файлах 2gis и Яндекс.Такси.
Заключение
Конечно же, я не придумал ничего нового. Этот способ знаком многим, но он используется редко, т.к. в нем есть как минусы, так и плюсы. Например, он вносит трудности в разработку, чистоту кода и т.д. По большому счету gzip частично решает проблему длинных имен и здорово сжимает файлы, но все же определенный выигрыш в размере и времени декомпрессии файлов можно получить и с использованием gzip. Например, оптимизированный сжатый файл mail.ru на 20Кб меньше того же не оптимизированного сжатого файла.
Так же хочу сказать, что мой плагин не является серебренной пулей в этом вопросе, а лишь пример реализации. Возможно, в будущем из плагина получится что нибудь действительно стоящее. Я буду плотно работать над этой идей, в идеале хотелось бы, чтобы плагин работал с абсолютно не подготовленными файлами, т.е без использования префикса, а делал все автоматически и безошибочно.
Смысл всей моей статьи в том, чтобы поднять интерес разработчиков к этому вопросу, послушать мнение других. Может быть, у кого-то уже был негативный или положительный опыт в данном вопросе. Пожалуйста, поделитесь им. К тому же, тот же Google, я думаю, не зря использует этот метод.
В общем, есть о чем поговорить и над чем задуматься.