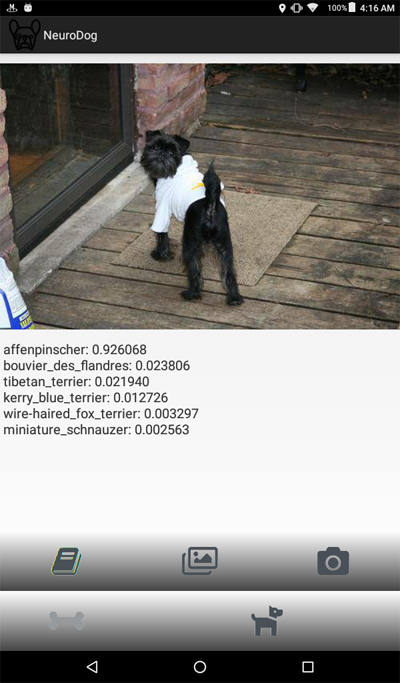
Dog Breed Identifier: Full Cycle Development from Keras Program to Android App. on Play Market
- пятница, 12 апреля 2019 г. в 00:13:07
from google.colab import drive
drive.mount('/content/drive/')
>>> Go to this URL in a browser: ...
>>> Enter your authorization code:
>>> ··········
>>> Mounted at /content/drive/
import datetime as dt
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm import tqdm
import cv2
import numpy as np
import os
import sys
import random
import warnings
from sklearn.model_selection import train_test_split
import keras
from keras import backend as K
from keras import regularizers
from keras.models import Sequential
from keras.models import Model
from keras.layers import Dense, Dropout, Activation
from keras.layers import Flatten, Conv2D
from keras.layers import MaxPooling2D
from keras.layers import BatchNormalization, Input
from keras.layers import Dropout, GlobalAveragePooling2D
from keras.callbacks import Callback, EarlyStopping
from keras.callbacks import ReduceLROnPlateau
from keras.callbacks import ModelCheckpoint
import shutil
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.models import load_model
from keras.applications.resnet50 import ResNet50
from keras.applications.resnet50 import preprocess_input
from keras.applications.resnet50 import decode_predictions
from keras.applications import inception_v3
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3
import preprocess_input as inception_v3_preprocessor
from keras.applications.mobilenetv2 import MobileNetV2
from keras.applications.nasnet import NASNetMobile
working_path = "/content/drive/My Drive/DeepDogBreed/data/"
!ls "/content/drive/My Drive/DeepDogBreed/data"
>>> all_images labels.csv models test train valid
# Is GPU Working?
import tensorflow as tf
tf.test.gpu_device_name()
>>> '/device:GPU:0'
warnings.filterwarnings("ignore")
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
np.random.seed(7)
start = dt.datetime.now()
BATCH_SIZE = 16
EPOCHS = 15
TESTING_SPLIT=0.3 # 70/30 %
NUM_CLASSES = 120
IMAGE_SIZE = 256
#strModelFileName = "models/ResNet50.h5"
# strModelFileName = "models/InceptionV3.h5"
strModelFileName = "models/InceptionV3_Sgd.h5"
#IMAGE_SIZE = 224
#strModelFileName = "models/MobileNetV2.h5"
#IMAGE_SIZE = 224
#strModelFileName = "models/NASNetMobileSgd.h5"
labels = pd.read_csv(working_path + 'labels.csv')
print(labels.head())
train_ids, valid_ids = train_test_split(labels,
test_size = TESTING_SPLIT)
print(len(train_ids), 'train ids', len(valid_ids),
'validation ids')
print('Total', len(labels), 'testing images')
>>> id breed
>>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull
>>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo
>>> 2 001cdf01b096e06d78e9e5112d419397 pekinese
>>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick
>>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever
>>> 7155 train ids 3067 validation ids
>>> Total 10222 testing images
def copyFileSet(strDirFrom, strDirTo, arrFileNames):
arrBreeds = np.asarray(arrFileNames['breed'])
arrFileNames = np.asarray(arrFileNames['id'])
if not os.path.exists(strDirTo):
os.makedirs(strDirTo)
for i in tqdm(range(len(arrFileNames))):
strFileNameFrom = strDirFrom +
arrFileNames[i] + ".jpg"
strFileNameTo = strDirTo + arrBreeds[i]
+ "/" + arrFileNames[i] + ".jpg"
if not os.path.exists(strDirTo + arrBreeds[i] + "/"):
os.makedirs(strDirTo + arrBreeds[i] + "/")
# As a new breed dir is created, copy 1st file
# to "test" under name of that breed
if not os.path.exists(working_path + "test/"):
os.makedirs(working_path + "test/")
strFileNameTo = working_path + "test/" + arrBreeds[i] + ".jpg"
shutil.copy(strFileNameFrom, strFileNameTo)
shutil.copy(strFileNameFrom, strFileNameTo)
# Move the data in subfolders so we can
# use the Keras ImageDataGenerator.
# This way we can also later use Keras
# Data augmentation features.
# --- Uncomment once, to copy files ---
#copyFileSet(working_path + "all_images/",
# working_path + "train/", train_ids)
#copyFileSet(working_path + "all_images/",
# working_path + "valid/", valid_ids)
breeds = np.unique(labels['breed'])
map_characters = {} #{0:'none'}
for i in range(len(breeds)):
map_characters[i] = breeds[i]
print("<item>" + breeds[i] + "</item>")
>>> <item>affenpinscher</item>
>>> <item>afghan_hound</item>
>>> <item>african_hunting_dog</item>
>>> <item>airedale</item>
>>> <item>american_staffordshire_terrier</item>
>>> <item>appenzeller</item>
def preprocess(img):
img = cv2.resize(img,
(IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
# or use ImageDataGenerator( rescale=1./255...
img_1 = image.img_to_array(img)
img_1 = cv2.resize(img_1, (IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
img_1 = np.expand_dims(img_1, axis=0) / 255.
#img = cv2.blur(img,(5,5))
return img_1[0]
# or use ImageDataGenerator( rescale=1./255...
train_datagen = ImageDataGenerator(
preprocessing_function=preprocess,
#rescale=1./255, # done in preprocess()
# randomly rotate images (degrees, 0 to 30)
rotation_range=30,
# randomly shift images horizontally
# (fraction of total width)
width_shift_range=0.3,
height_shift_range=0.3,
# randomly flip images
horizontal_flip=True,
,vertical_flip=False,
zoom_range=0.3)
val_datagen = ImageDataGenerator(
preprocessing_function=preprocess)
train_gen = train_datagen.flow_from_directory(
working_path + "train/",
batch_size=BATCH_SIZE,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
shuffle=True,
class_mode="categorical")
val_gen = val_datagen.flow_from_directory(
working_path + "valid/",
batch_size=BATCH_SIZE,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
shuffle=True,
class_mode="categorical")
def createModelVanilla():
model = Sequential()
# Note the (7, 7) here. This is one of technics
# used to reduce memory use by the NN: we scan
# the image in a larger steps.
# Also note regularizers.l2: this technic is
# used to prevent overfitting. The "0.001" here
# is an empirical value and can be optimized.
model.add(Conv2D(16, (7, 7), padding='same',
use_bias=False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3),
kernel_regularizer=regularizers.l2(0.001)))
# Note the use of a standard CNN building blocks:
# Conv2D - BatchNormalization - Activation
# MaxPooling2D - Dropout
# The last two are used to avoid overfitting, also,
# MaxPooling2D reduces memory use.
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(2, 2), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(16, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(32, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(32, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(64, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(64, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(128, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(128, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
model.add(Conv2D(256, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Conv2D(256, (3, 3), padding='same',
use_bias=False,
kernel_regularizer=regularizers.l2(0.01)))
model.add(BatchNormalization(axis=3, scale=False))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2),
strides=(1, 1), padding='same'))
model.add(Dropout(0.5))
# This is the end on "convolutional" part of CNN.
# Now we need to transform multidementional
# data into one-dim. array for a fully-connected
# classifier:
model.add(Flatten())
# And two layers of classifier itself (plus an
# Activation layer in between):
model.add(Dense(NUM_CLASSES, activation='softmax',
kernel_regularizer=regularizers.l2(0.01)))
model.add(Activation("relu"))
model.add(Dense(NUM_CLASSES, activation='softmax',
kernel_regularizer=regularizers.l2(0.01)))
# We need to compile the resulting network.
# Note that there are few parameters we can
# try here: the best performing one is uncommented,
# the rest is commented out for your reference.
#model.compile(optimizer='rmsprop',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
#model.compile(
# optimizer=keras.optimizers.RMSprop(lr=0.0005),
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.compile(optimizer='adadelta',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
#opt = keras.optimizers.Adadelta(lr=1.0,
# rho=0.95, epsilon=0.01, decay=0.01)
#model.compile(optimizer=opt,
# loss='categorical_crossentropy',
# metrics=['accuracy'])
#opt = keras.optimizers.RMSprop(lr=0.0005,
# rho=0.9, epsilon=None, decay=0.0001)
#model.compile(optimizer=opt,
# loss='categorical_crossentropy',
# metrics=['accuracy'])
# model.summary()
return(model)
def createModelMobileNetV2():
# First, create the NN and load pre-trained
# weights for it ('imagenet')
# Note that we are not loading last layers of
# the network (include_top=False), as we are
# going to add layers of our own:
base_model = MobileNetV2(weights='imagenet',
include_top=False, pooling='avg',
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
# Then attach our layers at the end. These are
# to build "classifier" that makes sense of
# the patterns previous layers provide:
x = base_model.output
x = Dense(512)(x)
x = Activation('relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
# Create a model
model = Model(inputs=base_model.input,
outputs=predictions)
# We need to make sure that pre-trained
# layers are not changed when we train
# our classifier:
# Either this:
#model.layers[0].trainable = False
# or that:
for layer in base_model.layers:
layer.trainable = False
# As always, there are different possible
# settings, I tried few and chose the best:
# model.compile(optimizer='adam',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
def createModelResNet50():
base_model = ResNet50(weights='imagenet',
include_top=False, pooling='avg',
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = base_model.output
x = Dense(512)(x)
x = Activation('relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
model = Model(inputs=base_model.input,
outputs=predictions)
#model.layers[0].trainable = False
# model.compile(loss='categorical_crossentropy',
# optimizer='adam', metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
def createModelInceptionV3():
# model.layers[0].trainable = False
# model.compile(optimizer='sgd',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
base_model = InceptionV3(weights = 'imagenet',
include_top = False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
model = Model(inputs = base_model.input,
outputs = predictions)
for layer in base_model.layers:
layer.trainable = False
# model.compile(optimizer='adam',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
def createModelNASNetMobile():
# model.layers[0].trainable = False
# model.compile(optimizer='sgd',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
base_model = NASNetMobile(weights = 'imagenet',
include_top = False,
input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3))
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
predictions = Dense(NUM_CLASSES,
activation='softmax')(x)
model = Model(inputs = base_model.input,
outputs = predictions)
for layer in base_model.layers:
layer.trainable = False
# model.compile(optimizer='adam',
# loss='categorical_crossentropy',
# metrics=['accuracy'])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
#model.summary()
return(model)
# Make sure that previous "best network" is deleted.
def deleteSavedNet(best_weights_filepath):
if(os.path.isfile(best_weights_filepath)):
os.remove(best_weights_filepath)
print("deleteSavedNet():File removed")
else:
print("deleteSavedNet():No file to remove")
deleteSavedNet(working_path + strModelFileName)
#if not os.path.exists(working_path + "models"):
# os.makedirs(working_path + "models")
#
#if not os.path.exists(working_path +
# strModelFileName):
# model = createModelResNet50()
model = createModelInceptionV3()
# model = createModelMobileNetV2()
# model = createModelNASNetMobile()
#else:
# model = load_model(working_path + strModelFileName)
checkpoint = ModelCheckpoint(working_path +
strModelFileName, monitor='val_acc',
verbose=1, save_best_only=True,
mode='auto', save_weights_only=False)
callbacks_list = [ checkpoint ]
# Calculate sizes of training and validation sets
STEP_SIZE_TRAIN=train_gen.n//train_gen.batch_size
STEP_SIZE_VALID=val_gen.n//val_gen.batch_size
# Set to False if we are experimenting with
# some other part of code, use history that
# was calculated before (and is still in
# memory
bDoTraining = True
if bDoTraining == True:
# model.fit_generator does the actual training
# Note the use of generators and callbacks
# that were defined earlier
history = model.fit_generator(generator=train_gen,
steps_per_epoch=STEP_SIZE_TRAIN,
validation_data=val_gen,
validation_steps=STEP_SIZE_VALID,
epochs=EPOCHS,
callbacks=callbacks_list)
# --- After fitting, load the best model
# This is important as otherwise we'll
# have the LAST model loaded, not necessarily
# the best one.
model.load_weights(working_path + strModelFileName)
# --- Presentation part
# summarize history for accuracy
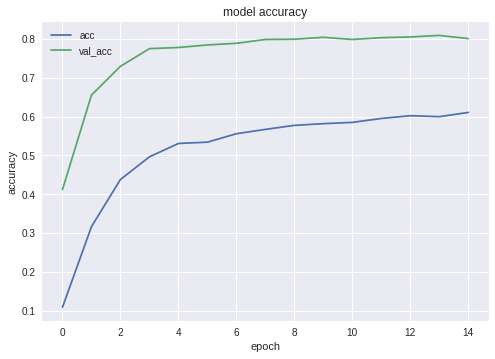
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['acc', 'val_acc'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['loss', 'val_loss'], loc='upper left')
plt.show()
# As grid optimization of NN would take too long,
# I did just few tests with different parameters.
# Below I keep results, commented out, in the same
# code. As you can see, Inception shows the best
# results:
# Inception:
# adam: val_acc 0.79393
# sgd: val_acc 0.80892
# Mobile:
# adam: val_acc 0.65290
# sgd: Epoch 00015: val_acc improved from 0.67584 to 0.68469
# sgd-30 epochs: 0.68
# NASNetMobile, adam: val_acc did not improve from 0.78335
# NASNetMobile, sgd: 0.8

# --- Test
j = 0
# Final cycle performs testing on the entire
# testing set.
for file_name in os.listdir(
working_path + "test/"):
img = image.load_img(working_path + "test/"
+ file_name);
img_1 = image.img_to_array(img)
img_1 = cv2.resize(img_1, (IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
img_1 = np.expand_dims(img_1, axis=0) / 255.
y_pred = model.predict_on_batch(img_1)
# get 5 best predictions
y_pred_ids = y_pred[0].argsort()[-5:][::-1]
print(file_name)
for i in range(len(y_pred_ids)):
print("\n\t" + map_characters[y_pred_ids[i]]
+ " ("
+ str(y_pred[0][y_pred_ids[i]]) + ")")
print("--------------------\n")
j = j + 1
# Test: load and run
model = load_model(working_path + strModelFileName)
from keras.models import Model
from keras.models import load_model
from keras.layers import *
import os
import sys
import tensorflow as tf
img = image.load_img(working_path
+ "test/affenpinscher.jpg") #basset.jpg")
img_1 = image.img_to_array(img)
img_1 = cv2.resize(img_1,
(IMAGE_SIZE, IMAGE_SIZE),
interpolation = cv2.INTER_AREA)
img_1 = np.expand_dims(img_1, axis=0) / 255.
y_pred = model.predict(img_1)
Y_pred_classes = np.argmax(y_pred,axis = 1)
# print(y_pred)
fig, ax = plt.subplots()
ax.imshow(img)
ax.axis('off')
ax.set_title(map_characters[Y_pred_classes[0]])
plt.show()

model.summary()
>>> Layer (type)
>>> ======================
>>> input_7 (InputLayer)
>>> ______________________
>>> conv2d_283 (Conv2D)
>>> ______________________
>>> ...
>>> dense_14 (Dense)
>>> ======================
>>> Total params: 22,913,432
>>> Trainable params: 1,110,648
>>> Non-trainable params: 21,802,784
def print_graph_nodes(filename):
g = tf.GraphDef()
g.ParseFromString(open(filename, 'rb').read())
print()
print(filename)
print("=======================INPUT===================")
print([n for n in g.node if n.name.find('input') != -1])
print("=======================OUTPUT==================")
print([n for n in g.node if n.name.find('output') != -1])
print("===================KERAS_LEARNING==============")
print([n for n in g.node if n.name.find('keras_learning_phase') != -1])
print("===============================================")
print()
#def get_script_path():
# return os.path.dirname(os.path.realpath(sys.argv[0]))
def keras_to_tensorflow(keras_model, output_dir,
model_name,out_prefix="output_",
log_tensorboard=True):
if os.path.exists(output_dir) == False:
os.mkdir(output_dir)
out_nodes = []
for i in range(len(keras_model.outputs)):
out_nodes.append(out_prefix + str(i + 1))
tf.identity(keras_model.output[i],
out_prefix + str(i + 1))
sess = K.get_session()
from tensorflow.python.framework import graph_util
from tensorflow.python.framework graph_io
init_graph = sess.graph.as_graph_def()
main_graph =
graph_util.convert_variables_to_constants(
sess, init_graph, out_nodes)
graph_io.write_graph(main_graph, output_dir,
name=model_name, as_text=False)
if log_tensorboard:
from tensorflow.python.tools
import import_pb_to_tensorboard
import_pb_to_tensorboard.import_to_tensorboard(
os.path.join(output_dir, model_name),
output_dir)
Let's use these functions to create an exportes NN:
model = load_model(working_path
+ strModelFileName)
keras_to_tensorflow(model,
output_dir=working_path + strModelFileName,
model_name=working_path + "models/dogs.pb")
print_graph_nodes(working_path + "models/dogs.pb")

<activity android:name=".MainActivity"
android:launchMode="singleTask">
<intent-filter>
<!-- Send action required to display
activity in share list -->
<action android:name="android.intent.action.SEND" />
<!-- Make activity default to launch -->
<category android:name="android.intent.category.DEFAULT" />
<!-- Mime type i.e. what can be shared with
this activity only image and text -->
<data android:mimeType="image/*" />
</intent-filter>
<uses-feature
android:name="android.hardware.camera"
android:required="true" />
<uses-permission android:name=
"android.permission.WRITE_EXTERNAL_STORAGE" />
<uses-permission
android:name="android.permission.READ_PHONE_STATE"
tools:node="remove" />
public class MainActivity extends Activity
static Bitmap m_bitmap = null;
static Bitmap m_bitmapForNn = null;
private int m_nImageSize = 256;
private String INPUT_NAME = "input_7_1";
private String OUTPUT_NAME = "output_1";
private TensorFlowInferenceInterface tf; private String MODEL_PATH = "file:///android_asset/dogs.pb";
private String[] m_arrBreedsArray;
private float[] m_arrPrediction = new float[120];
private float[] m_arrInput = null;
static
{
System.loadLibrary("tensorflow_inference");
}
class PredictionTask extends
AsyncTask<Void, Void, Void>
{
@Override
protected void onPreExecute()
{
super.onPreExecute();
}
// ---
@Override
protected Void doInBackground(Void... params)
{
try
{
# We get RGB values packed in integers
# from the Bitmap, then break those
# integers into individual triplets
m_arrInput = new float[
m_nImageSize * m_nImageSize * 3];
int[] intValues = new int[
m_nImageSize * m_nImageSize];
m_bitmapForNn.getPixels(intValues, 0,
m_nImageSize, 0, 0, m_nImageSize,
m_nImageSize);
for (int i = 0; i < intValues.length; i++)
{
int val = intValues[i];
m_arrInput[i * 3 + 0] =
((val >> 16) & 0xFF) / 255f;
m_arrInput[i * 3 + 1] =
((val >> 8) & 0xFF) / 255f;
m_arrInput[i * 3 + 2] =
(val & 0xFF) / 255f;
}
// ---
tf = new TensorFlowInferenceInterface(
getAssets(), MODEL_PATH);
//Pass input into the tensorflow
tf.feed(INPUT_NAME, m_arrInput, 1,
m_nImageSize, m_nImageSize, 3);
//compute predictions
tf.run(new String[]{OUTPUT_NAME}, false);
//copy output into PREDICTIONS array
tf.fetch(OUTPUT_NAME, m_arrPrediction);
}
catch (Exception e)
{
e.getMessage();
}
return null;
}
// ---
@Override
protected void onPostExecute(Void result)
{
super.onPostExecute(result);
// ---
enableControls(true);
// ---
tf = null;
m_arrInput = null;
# strResult contains 5 lines of text
# with most probable dog breeds and
# their probabilities
m_strResult = "";
# What we do below is sorting the array
# by probabilities (using map)
# and getting in reverse order) the
# first five entries
TreeMap<Float, Integer> map =
new TreeMap<Float, Integer>(
Collections.reverseOrder());
for(int i = 0; i < m_arrPrediction.length;
i++)
map.put(m_arrPrediction[i], i);
int i = 0;
for (TreeMap.Entry<Float, Integer>
pair : map.entrySet())
{
float key = pair.getKey();
int idx = pair.getValue();
String strBreed = m_arrBreedsArray[idx];
m_strResult += strBreed + ": " +
String.format("%.6f", key) + "\n";
i++;
if (i > 5)
break;
}
m_txtViewBreed.setVisibility(View.VISIBLE);
m_txtViewBreed.setText(m_strResult);
}
}
m_btn_process.setOnClickListener(new View.OnClickListener()
{
@Override
public void onClick(View v)
{
processImage();
}
});
private void processImage()
{
try
{
enableControls(false);
// ---
PredictionTask prediction_task
= new PredictionTask();
prediction_task.execute();
}
catch (Exception e)
{
e.printStackTrace();
}
}
protected void onCreate(
Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
....
onSharedIntent();
....
@Override
protected void onNewIntent(Intent intent)
{
super.onNewIntent(intent);
setIntent(intent);
onSharedIntent();
}
private void onSharedIntent()
{
Intent receivedIntent = getIntent();
String receivedAction =
receivedIntent.getAction();
String receivedType = receivedIntent.getType();
if (receivedAction.equals(Intent.ACTION_SEND))
{
// If mime type is equal to image
if (receivedType.startsWith("image/"))
{
m_txtViewBreed.setText("");
m_strResult = "";
Uri receivedUri =
receivedIntent.getParcelableExtra(
Intent.EXTRA_STREAM);
if (receivedUri != null)
{
try
{
Bitmap bitmap =
MediaStore.Images.Media.getBitmap(
this.getContentResolver(),
receivedUri);
if(bitmap != null)
{
m_bitmap = bitmap;
m_picView.setImageBitmap(m_bitmap);
storeBitmap();
enableControls(true);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
}
}