https://habr.com/ru/post/501362/- Python
- Обработка изображений
- Машинное обучение
- Разработка на Raspberry Pi
- TensorFlow
В эпоху заточения хорошо заниматься физкультурой, но вот беда — не все домашние с этим согласны, так что приходилось прикладывать некоторые усилия. Работать надзирателем однако хотелось не очень, потому как надо было собственно работать, а пущеный на самотек спортивный процесс, наблюдаемый в лучшем случае одним глазом, заимел тенденцию скатываться в халяву.
Профессионально деформированный мозг беспокоился, что надо эти процессы как-то мониторить, собирать метрики, и делать это конечно не вручную, а чтобы оно все само себя посчитало.
Начать было решено с приседаний. Фундаментальное движение, с явными состояниями, большой амплитудой, в общем, идеальный выбор.
В техническом плане — у меня есть Raspberry Pi да камера, вполне достаточно для прототипа.
Сбор данных
Тут все просто: включаем камеру через OpenCV и пишем картинки в файлы, соблюдая последовательность.
Детектор движений
Было несколько вариантов — например с помощью сегментации выделить человека на картинке и с ним уже что-то делать. Но сегментация в разумное время на Raspberry — нереальное сочетание слов, плюс к этому, сегментировать пришлось бы каждый кадр, упуская из виду важный факт, что у нас их целая последовательность.
Таким образом, я остановился на выделении движущихся элементов в клипе. В OpenCV есть
замечательные функции удаления фона, из которых, с помощью некоторых манипуляций, можно получить сегментированный объект.
Итак, создаем background subtractor:
backSub = cv.createBackgroundSubtractorMOG2()
И начинаем кормить его кадрами:
mask = backSub.apply(frame)
На выходе получается примерно такая картинка:

Дальше добавим белого, чтобы контур стал более четким.
mask = cv.dilate(mask, None, 3)
Идея в том, чтобы из каждого кадра вырезать подобную маску и классифицировать ее как стойка, присед или ничего.
Интересный вопрос, как вырезать всю фигуру из этого кадра.
Для начала поищем контуры:
cnts, _ = cv.findContours(img, cv.RETR_CCOMP, cv.CHAIN_APPROX_SIMPLE)
С мыслью, что самый большой контур с достаточной точностью будет соотвествовать фигуре.
Увы, это не всегда так.
Тем не менее, от большого контура можно оттолкнуться, используя детали решаемой задачи.
Особенность приседа в том, что он делается на одном месте — значит мы можем опираться то, что фигура сохраняет свою позицию и размеры от кадра к кадру.
Тогда мы можем итеративно строить bounding rect, увеличивая, если главный контур оказывается за его пределами.
Например, на этой картинке красным обозначен самый большой контур, синим — bounding rect для этого контура, зеленым — bounding rect для все фигуры.
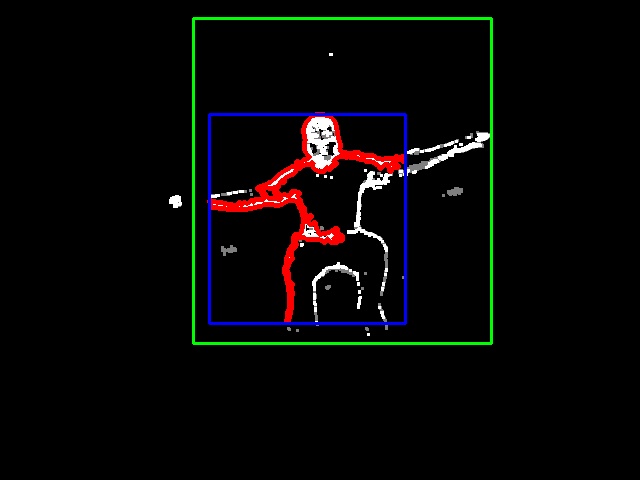
В итоге, с большой достоверностью удается получить прямоугольник, в котором происходит движение. Теперь надо бы понять, что это мы получили.
Классификация поз
Полученный прямоугольник вырезаем, помещаем в квадрат, приводим к одному размеру, классифицируем вручную и получаем какие-то такие маски:
Для приседа:

Для стойки:

Этим уже можно кормить нейросеть.
Для классификации будем использовать Keras + Tensorflow на черно-белых картинках.
Размер картинок — интересный вопрос, я проводил эксперименты с двумя вариантами:
64x64 vs 128x128.
Есть три класса — стойка, присед и ничего.
Собираем простейшую сверточную сеть:
model = Sequential([
Convolution2D(8,(5,5), activation='relu', input_shape=input_shape),
MaxPooling2D(),
Flatten(),
Dense(512, activation='relu'),
Dense(3, activation='softmax')
])
model.compile(loss="categorical_crossentropy", optimizer=SGD(lr=0.01), metrics=["accuracy"])
Есть мнение, что минимум для классификации — это
Lenet-подобная модель с двумя сверточными слоями, но на практике работает и эта односверточная.
И 128x128 на 8ми фильтрах и 10ти эпохах получаем 92.66%. Выглядит многообещающе. С увеличением времени обучения до 20ти эпох, точность вырастает до 99.34%.
64x64 на 10-ти эпоха выдает лишь 86% точности. На 20 дотягиваем до 94х и на 30 до 96.
Зато модель в 4 раза меньше и работает в 4 раза быстрее.
На собранных данных модель-64 выдавала похожие результаты, так что я остановился на ней.
Запуск на Raspberry Pi
OpenCV
Я большой поклонник модуля OpenCV-DNN и рассчитывал крутить модель с его помощью, не прибегая к тяжеловесному Tensorflow.
Однако, сконвертив модель из Keras в TF и запустив тест, получил такое нерадостное сообщение:
cv2.error: OpenCV(4.2.0) C:\projects\opencv-python\opencv\modules\dnn\src\dnn.cpp:562: error: (-2:Unspecified error) Can't create layer "flatten_1/Shape" of type "Shape" in function 'cv::dnn::dnn4_v20191202::LayerData::getLayerInstance'
На
Stack Overflow есть тема полугодовой давности, где советуют:
- обновиться до последней версии
- поколдовать с заменой Flatten на Reshape
Вариант
1 не помог, вариант
2 — не совсем то, чем хотелось бы заняться вместо решаемой задачи.
Tensorflow
Таким образом, не осталось других альтернатив, кроме как использовать TF. Гугл уже достаточно давно поддерживает Raspberry официально, так что одной головной болью меньше.
TF содержит адаптеры к Keras, так что ничего конвертировать не надо.
Загружаем модель:
with open(MODEL_JSON, 'r') as f:
model_data = f.read()
model = tf.keras.models.model_from_json(model_data)
model.load_weights(MODEL_H5)
graph = tf.get_default_graph()
И скармливаем ей картинки масок из файлов:
img = cv.imread(path + f, cv.IMREAD_GRAYSCALE)
img = np.reshape(img,[1,64,64,1])
with graph.as_default():
c = model.predict_classes(img)
return c[0] if c else None
Классификация (на Raspberry) занимает четверть секунды для картинок 128x128 и 60-70 миллисекунд для 64x64, это почти реалтайм.
Программа
Собираем из этих кусочков
программу для Raspberry.
Сервис будет на Flask с таким интерфейсом:
- GET / — управляющая страничка, о ней ниже
- GET /status — получить текущее состояние, количество приседов, кадров
- POST /start — начать упражнение
- POST /stop — закончить упражненеи
- GET /stream — видеопоток с камеры
В том же процессе подключается Tensorflow.
Это очень плохая идея, особенно на Raspberry — TF будет жрать память и ресурсы, и сервис будет не только тормозить с ответами, но и запросто вырубится, когда TF исчерпает ресурсы малинки (а это обязательно случится).
Но для первой версии налаживать межпроцессный обмен мне было лень, пусть прототип будет таким.
Для конечного пользователя заводим простой
веб-апп (который опять раздается все тем же фласк-сервисом), который умеет:
- показывать видео с камеры
- начинать/заканчивать упражнение
- показывает счетчик приседаний
В режиме упражнения сервис пишет картинки в файловую систему.
По-хорошему их надо бы удалять автоматически, а пока можно забирать для обучения нейросети.
Как только упражнение начинается, программа начинает обрабатывать картинки в поисках движущегося объекта, вырезает маску этого объекта, передает эту маску классификатору и если удалось встретить последовательность стойка — присед — стойка, то приседание можно засчитать.
 Инструмент для разметки
Инструмент для разметки представляет собой python + opencv + GUI приложение.
На картинке ищется контур, рамка для фигуры, и нажатием кнопок S (Stand), Q (sQuat), N (Nothing) можно классифицировать картинку, и ее маска автоматически будет записана в нужный каталог.
После этого каталог с новыми классифицированными масками надо перенести в данные для
нейросети и переобучить ее.
Я запускал детектор на Raspberry, но ничего не мешает запускать его на любой машине с питоном, opencv и камерой — с малинкой это проще, чем таскать лаптоп.
Проблемы
В существующем виде это можно признать MVP, но до стабильного решения еще работать и работать.
- Улучшить качество при удалении фона. Тень и блики оставляют неприятные артифакты, от которых потом рвет крышу у классификатора
- Собрать больше данных для классификатора
- Улучшить классификатор. Существующий быстр и прост, но надежность его результатов под вопросом. Древний Lenet-5 заметно навороченнее и за ним стоит логика, в которую стоит вникнуть.
Ссылки