Чем заменить ELK для просмотра логов?
- пятница, 6 мая 2016 г. в 03:13:40
Что обычно делает python-программист, когда его отправляют воевать с ошибкой?
Сначала он лезет в sentry. Здесь можно найти время, сервер, подробности сообщения об ошибке, traceback и, может быть, какой-нибудь полезный контекст. Затем, если этих данных недостаточно, программист идет c бутылкой к админам. Те залезают на сервер, ищут это сообщение в файловых логах, и, может быть, находят его и некоторые предшествующие ошибке записи, которые в редких случаях могут помочь в расследовании.
А что делать, если в логах только loglevel=ERROR, а ошибка настолько крута, что ее локализация требует сопоставления логики поведения нескольких различных демонов, которые запущены на десятке серверов?
Решение — централизованное хранилище логов. В самом простом случае — syslog (за 5 лет, что был развернут в rutube, не использовался ни разу), для более сложных целей — ELK. Скажу честно, "ластик" — крут, и позволяет быстро крутить разнообразную аналитику, но вы интерфейс Kibana видели? Этой штуке так же далеко до консольных less/grep, как винде до линукса. Поэтому мы решили сделать свой велосипед, без Java и Node.js, зато с sphinxsearch и Python.
В общем-то, основные претензии к ELK заключаются в том, что Kibana — это совсем не инструмент навигации по логам. Не то, чтобы совсем пользоваться невозможно, но как замена grep/less — не годится.

Так что чуть ли не основным требованием к "велосипеду" была минималистичная верстка, избавиться от вечно зависающего построенного на "вражеских" технологиях Logstash, ну и ElasticSearch тоже заодно выкинуть.
Чтобы логи хранить, их надо куда-то отправлять. В тот же ElasticSearch можно писать напрямую, но гораздо веселее через RabbitMQ — на то он и брокер сообщений. Взяв за основу python-logstash, мы "докрутили" к нему корректную обработку недоступности RabbitMQ и несколько "загрузчиков". В пакете logcollect поддерживается автонастройка для Celery, Django и "родного" python logging. При этом к корневому логгеру добавляется обработчик, отправляющий все логи в формате JSON в RabbitMQ.
Да, чуть не забыл. Пример:
from logcollect.boot import default_config
default_config(
# RabbitMQ URI
'amqp://guest:guest@127.0.0.1/',
# идентификаторы для подсистем или еще чего-нибудь похожего
# по-сути добавляется в каждое сообщение отдельным ключем
activity_identity={'subsystem': 'backend'},
# префикс для RabbitMQ routing key.
routing_key='site')Для предварительной фильтрации логов мы воспользовались функционалом RabbitMQ: используется topic-exchange, который отправляет в очередь на обработку только сообщения, соответствующие определенному шаблону. К примеру, sql-запросы Django проекта "site" будут обрабатываться, только если для соответствующей очереди задан routing key site.django.db.backends, а "поймать" все логи от django можно с помощью routing key site.django.#. Это позволяет балансировать между объемом хранимых данных и полнотой охвата логируемых сообщений.
Первоначально, буква "A" в ALCO означала "асинхронный", однако быстро выяснилось, что использование asyncio-based решений тут ни к чему: всё упиралось в скорость фильтрации сообщений питоновским процессом. Оно и понятно: librabbitmq позволяет получать из "кролика" сразу пачку сообщений, каждое из которых надо разобрать, вырезать ненужные поля, переименовать недопустимые, для некоторых полей сохранить новые значения в Redis, сгенерировать на основе метки времени id для sphinxsearch, а еще сформировать INSERT-запрос.
В последствии, правда, оказалось, что "асинхронный" — это всё-таки про нас: для того, чтобы эффективнее расходовать процессорное время, round-trip INSERT-запроса между питоном и sphinxsearch выполняется в отдельном потоке, с синхронизацией через родные очереди питона.
Новые колонки сохраняются в БД, после чего становится доступным ряд настроек их отображения и хранения:
С технической точки зрения рассказывать особо нечего (bootstrap + backbone.js + django + rest_framework), поэтому приведу лишь пару скриншотов.

Логи можно фильтровать по датам, значениям определенных колонок из списка, по произвольным значениям, а также выполнять полнотекстовый поиск по самим сообщениям. Кроме того, опционально можно посмотреть записи, соседствующие с найденными полнотекстовым поиском (привет, less).
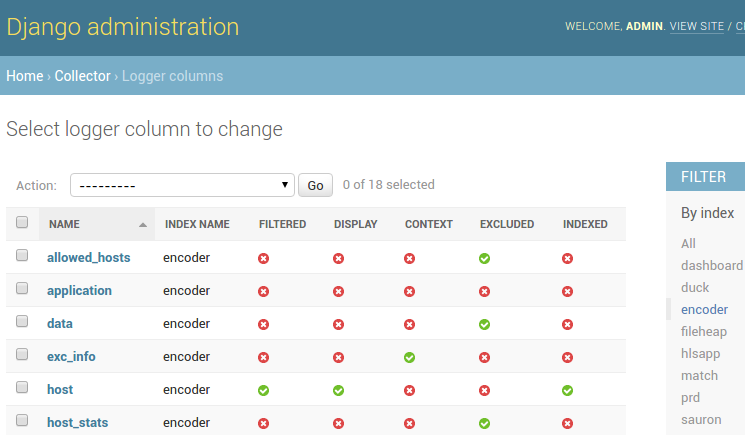
Отображение колонок настраивается через админку, как и настройки индексов routing_key или период хранения данных.
К сожалению, похвастаться молниеносной загрузкой страницы мы пока не можем: sphinxsearch так устроен, что любая фильтрация по атрибутам требует fullscan всего индекса, поэтому быстро работает только полнотекстовый поиск (считай, grep). Зато он — мегабыстр! Но мы не сдаемся, и упорно пытаемся производительность фильтрации.
К примеру, первичные ключи специально генерируются на основе метки времени, т.к. sphinxsearch умеет "быстро" выгребать данные по диапазону id. Начиная с некоторого объема индекса, выигрыш по производительности дает индексация отдельных колонок: несмотря на низкую мощность (cardinality), за счет того, что используется полнотекстовый индекс, обработка запроса занимает условно 20 секунд против минуты в случае фильтрации по json-атрибутам. Также в запросе указывается распределенный индекс, соответствующий диапазону запрашиваемых дат: таким образом, данные за весь месяц не читаются, если требуются логи за "вчера".
Скорость вставки в RT-индекс со времен вот этой статьи в блоге sphinxsearch значительно возросла: на персоналке удалось достичь (как бы не соврать...) 8000 row/s на инсертах по 1000 записей, при одновременном получении записей из очереди RabbitMQ и обработке в python-процессах. А еще alco умеет вставлять записи в каждый индекс в несколько потоков, хотя до полноценного шардирования sphinxsearch по машинам мы не доросли: интересных логов в продакшне не настолько много, чтобы это стало критичным.
Внимательный читатель заметит (с), что конфигурация sphinxsearch у нас явно не статическая ;-) В общем-то это не секрет, и в документации написано, что sphinx.conf вполне может быть исполняемым файлом, если в его начале стоит "shebang". Так что наш скрипт конфига написан на питоне, он ходит по http к админке alco и печатает в stdout конфиг сфинкса, сгенерированный с помощью шаблонизатора django, попутно создавая отсутствующие директории и удаляя уже не используемые индексы.
Если кого-нибудь заинтересовал наш "велосипед", подробнее про alco можно почитать на github. Чтобы попробовать, достаточно sphinxsearch, RabbitMQ, MySQL и Redis. Ну и, конечно, будем рады баг-репортам и пулл-реквестам.