http://habrahabr.ru/company/mailru/blog/266017/

В сентябре прошлого года была
опубликована последняя статья о Центрифуге — сервере с открытым исходным кодом для обмена сообщениями в режиме реального времени. Теперь в списке хабов, в которые публикуется этот пост, присутствует Go. И неспроста, как можно понять уже из заголовка, Центрифуга была портирована с Python на Go — так появилась
Centrifugo. О причинах миграции, о плюсах и минусах Go, а также о том, как эволюционировал проект с момента предыдущей публикации – читайте под катом.
В посте (и, видимо, дальше по жизни) я буду называть сервер в общем Центрифугой, а если нужно подчеркнуть разницу между имплементациями на разных языках, буду использовать английское название — Centrifuge для Python-версии, Centrifugo — для Go-версии.
Очень кратко о том, что такое Центрифуга. Это сервер, который работает рядом с бекендом вашего приложения. Пользователи приложения подключаются к Центрифуге, используя протокол Websocket или полифил-библиотеку
SockJS. Подключившись и авторизовавшись, они подписываются на интересующие их каналы. Как только бекенд приложения узнает о новом событии он отправляет его в нужный канал в Центрифугу (используя очередь в Redis или HTTP API), которая, в свою очередь, рассылает сообщение всем подключенным заинтересованным пользователям.
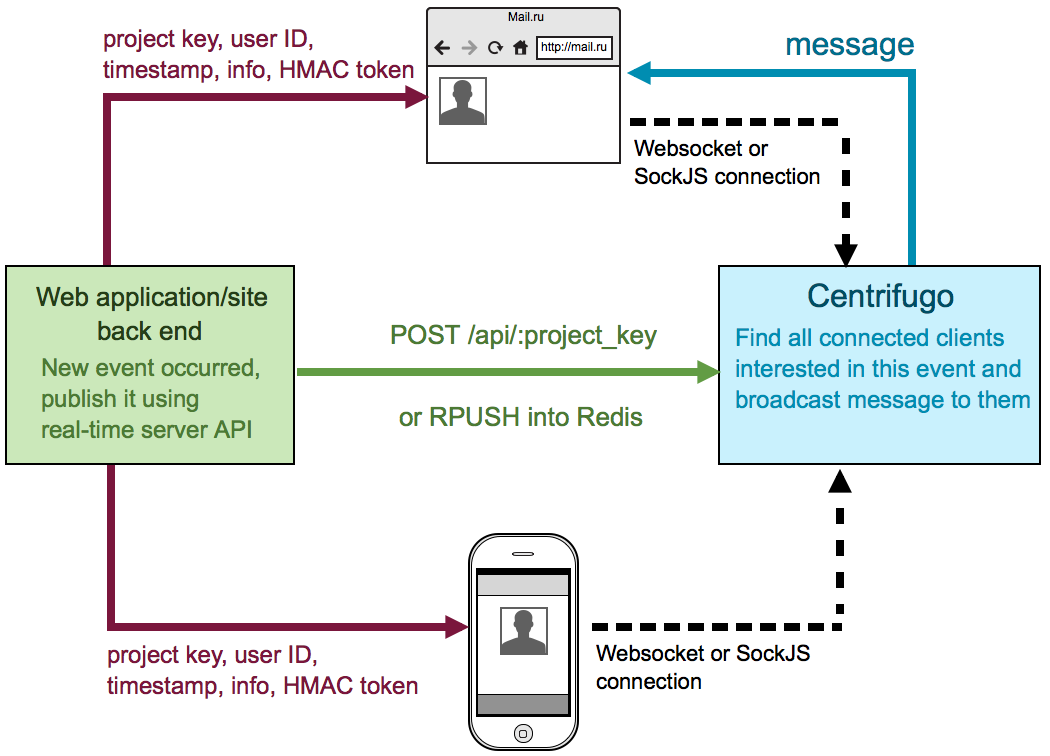
Тем самым Центрифуга решает проблемы множества современных распространенных фреймворков (таких как Django, Ruby on Rails, Laravel и т.д.), с применением которых написан бекенд многих веб-приложений. Когда бекенд не умеет работать асинхронно, a пул воркеров, обрабатывающих запросы, ограничен, то обработка постоянных соединений от клиентов моментально приводит к исчерпанию этого пула. Конечно, ничто не мешает использовать Центрифугу и в паре с вашим асинхронным бекендом, чтобы просто уменьшить количество работы, которую нужно проделать для разработки.
Решений, подобных Центрифуге, существует немало, и я упоминал о некоторых из них в предыдущих статьях. Основными отличительными особенностями являются несколько вещей:
- независимость от языка, на котором написан бекенд приложения;
- использование SockJS: позволяет всем пользователям, чьи браузеры по тем или иным причинам не могут установить Websocket соединение, получать новые сообщения через fallback-транспорт (eventsource, xhr-streaming, xhr-polling и т.д.);
- авторизация пользователей, основанная на использовании подписанного токена (HMAC SHA-256);
- возможность запустить несколько процессов, связанных Редисом;
- информация о текущих пользователях в канале, история сообщений в каналах, сообщения о подписке на канал пользователем или отписке от канала; большинство PUB/SUB решений умеют только рассылать новые сообщения;
- полная готовность к деплою: rpm, Dockerfile, конфиг Nginx; а теперь еще и релизы в виде бинарного файла под все платформы.
Раньше я делал акцент на том, что основное предназначение Центрифуги — мгновенные сообщения в веб-приложениях. Пожалуй, приставка «веб» немного скрывает возможный потенциал проекта: подключаться к Центрифуге можно и из мобильных приложений, используя Websocket-протокол. Это было подтверждено некоторыми пользователями из opensource-сообщества. Но к сожалению, клиентов для мобильных устройств, то есть на Java или Objective-C/Swift, пока нет. Миграция на Go — это еще один небольшой шаг на пути к адаптации сервера под использование из разных сред. Но обо всем по порядку. Итак, почему Go? На это было несколько причин.

Плюсы миграции на Go
Производительность
Не секрет, что Go значительно быстрее CPython. И Центрифуга на Go стала значительно шустрее. Приведу примеры. Центрифуга позволяет отправлять в одном HTTP-запросе к API множество команд. Я отправил запрос, содержащий 1000 новых сообщений, которые должны быть опубликованы в канал. Давайте посмотрим на результаты.
Centrifuge: 2.0 секунды на обработку запроса, когда в канале нет пользователей
Centrifuge: 17.2 секунд, когда в канале 100 пользователей
Centrifugo: 30 миллисекунд, когда нет пользователей (x15)
Centrifugo: 350 миллисекунд, когда в канале 100 пользователей (x49)
Все-таки 1000 сообщений — это нестандартная ситуация, вот результаты отправки одного нового сообщения в канал, в котором 1000 активных клиентов:
Centrifuge: 3 миллисекунды, когда 0 пользователей в канале
Centrifuge: 160 миллисекунд с 1000 пользователями в канале
Centrifugo: 200 микросекунд, когда 0 пользователей в канале (x15)
Centrifugo: 2.0 миллисекунд с 1000 пользователями в канале (x80)
Цифры получены на Macbook Air 2011. Стоит также отметить, что клиентские соединения были искусственно созданы с той же самой машины, и завершенный ответ не говорит о том, что сообщения уже прилетели клиентам. Кстати, вот код, который использовался для публикации сообщений:
from cent.core import generate_api_sign
import requests
import json
command = {
"method": "publish",
"params": {"channel": "test", "data": {"json": True}}
}
n = 1000
url = "http://localhost:8000/api/development"
commands = []
for i in range(n):
commands.append(command)
encoded_data = json.dumps(commands)
sign = generate_api_sign("secret", "development", encoded_data)
r = requests.post(url, data={"sign": sign, "data": encoded_data})
Конечно, такой прирост производительности наблюдается не во всех компонентах сервера, но абсолютно все стало быстрее. В репозитории Centrifuge также есть бенчмарк-скрипт, создающий большое количество соединений, подписанных на один канал. После подписки в канал отправляется сообщение и высчитывается время до момента, когда все клиенты получат сообщение. Если взять верхнюю границу такого времени за 200 мс, то количество одновременных соединений, которые способен нормально обслужить сервер при таком распределении каналов/клиентов, выросло в ~4 раза (на моем ноутбуке с 4000 до 14000). Опять же, так как все клиенты создаются внутри одного скрипта с той же машины, есть возможность необъективности этой оценки.
Многоядерность
Go позволяет запустить один процесс, который будет использовать несколько ядер одновременно. В случае с Торнадо нам приходилось запускать несколько процессов Центрифуги и использовать Nginx в качестве балансера перед ними. Это работает, но Go позволяет сделать гораздо проще: написать программу, которая сама позаботится о том, чтобы утилизировать доступную мощь машины. Но волшебства не бывает, код программы должен быть таким, чтобы Go runtime мог распределить работу между ядрами процессора (
https://golang.org/doc/faq#Why_GOMAXPROCS).
Распространение
Приложение на Go проще распространять, так как на выходе Go позволяет получить для программы один статически слинкованный исполняемый файл. Cкачал, запустил — работает! Без каких-либо зависимостей и перетягивания питоновского virtualenv на боевую машину. В Mail.Ru Group мы, конечно, файлики просто так в бой не копируем, а создаем для каждого из наших приложений rpm. Но создание rpm также гораздо прозрачнее, проще и быстрее. Дополнительно к вышеозвученному Go позволяет кросс-компилировать код под различные платформы — это потрясающая и удобная возможность. Все, что нужно в большинстве случаев, — указать для какой платформы и архитектуры вам нужен бинарный файлик.
Встроенная в язык concurrency-модель
Встроенная по умолчанию в язык Go concurrency позволяет писать неблокирующий код, используя все доступные библиотеки и инструменты языка, нет необходимости искать неблокирующие библиотеки, как это происходит в случае с Торнадо. Одной из головных болей, например, был асинхронный клиент для Редиса. Про официальный redis-py можно сразу забыть. Из более-менее живых и приспособленных для Торнадо нашлось два:
tornado-redis и
toredis. Изначально я планировал использовать tornado-redis, но выяснилось, что он совершенно не подходит для меня из-за наличия
бага. В итоге в Python-версии используется toredis. Он очень даже хорош, но путь к нему был тернист.
В Go асинхронная работа с сетевыми и системными вызовами заложена в основу языка. Runtime scheduler переключает контекст между горутинами на блокирующих вызовах или после определенного максимального времени, отведенного на работу горутины. В общем и целом, все это похоже на работу Gevent, да и Tornado в какой-то мере, но иметь это из коробки — большое счастье.
Статическая типизация
Прошу заметить, что в этом пункте я не утверждаю, что статическая типизация лучше динамической. Но! Благодаря статической типизации существенно проще вносить изменения в код. Для меня это, надо признать, стало одним из самых ярких открытий после Python — рефакторинг очень сильно упрощается. Есть дополнительная уверенность, что если код компилируется после внесения правок, то он будет работать правильно.
Мне кажется, перечисленных пунктов достаточно, чтобы убедиться в разумности миграции. Были и другие плюсы, обнаружившиеся в процессе. Go-код легко тестировать, версия 1.5 открывает дорогу к созданию shared library для использования из Java или Objective-C, встроенные утилиты позволяют отследить утечки горутин.

Минусы миграции на Go
Нужно было, конечно, оценить и минусы такой миграции. Например, что делать с Python-версией: написать полностью совместимую Go-версию и подменить код в репозитории или сделать отдельным проектом? Подменить было заманчиво, все-таки ссылки в интернете на проект и название значили достаточно много. Здравый смысл подсказал, что нужно делать отдельно. В итоге сейчас есть Centrifuge и Centrifugo. И я не сказал бы, что это очень хорошо, вносит путаницу.
Второй момент: гораздо проще найти разработчиков-пользователей opensource-решения, если они сами используют тот же язык программирования, на котором написано это opensource-приложение. Все-таки, как ни крути, а Python-сообщество покрупней, чем сообщество Go. Пришлось этим пожертвовать.
Далее, язык для меня новый, так что была вероятность (и даже все еще есть) наступить на старые грабли повторно или найти новые. Но разве это когда-либо останавливало программистов? Наоборот!
Есть минусы и в самом языке Go. Давайте пройдемся по основным, на которые обычно жалуются:
- Отсутствие generics. Да, их нет. В итоге у меня в репозитории лежат 2 структуры данных, которые теоретически, будь в Go поддержка generics, я мог бы переиспользовать в других проектах (а, возможно, даже взять уже готовые из другого репозитория). Это in-memory fifo очередь и priority heap очередь, умеющие работать только со строками. Пожалуй, были бы generics — было бы лучше. Но в то же время, я бы не сказал, что меня это очень смущает. Как я понял, авторы языка Go считают этот вопрос открытым. Возможно, в будущем они смогут найти правильный способ, как добавить generics в язык.
- Обработка ошибок. В Go отсутствуют исключения, и принято явно возвращать ошибку из функций/методов. На мой взгляд, это очень субъективный минус. Мне, например, нравится. Я по каким-то личным причинам делал так и в Торнадо, как результат выполнения корутин вместо того, чтобы вызывать исключение. Для меня это удобно! Но если в Python это кажется неестественным по отношению к практикам языка, то тут без этого просто не обойтись.
Миграция
Центрифуга на Python строится на основе нескольких основных библиотек:
Tornado,
Toredis,
Sockjs-Tornado. Соответственно, нужно было найти аналоги в Go. Вместо Tornado выступает непосредственно сам язык, для работы с Redis-ом используется
Redigo, а также нашлась замечательная
реализация SockJS-сервера. В общем, решение о миграции c Python на Go было принято, и на переписывание основной базы кода ушло около 3 месяцев работы по вечерам после работы. Так уж вышло, что процесс миграции совпал с моим желанием избавиться от бекендов хранения настроек проектов и неймспейсов. Если вы читали предыдущие статьи про проект, то, возможно, знаете: раньше эти настройки хранились на выбор в JSON-файле, SQLite, MongoDB или PostgreSQL с возможностью написать и использовать свой бекенд. При этом SQLite был выбором по умолчанию. Это, пожалуй, было ошибкой. Настройки меняются настолько редко, что держать ради них базу данных ну совсем бессмысленно. В итоге я переработал все на использование только конфигурационного файла, избавившись от всевозможных бекендов.
Конфигурационный файл теперь можно создавать в форматах JSON, YAML или TOML — спасибо чудесной Go библиотеке
Viper. Вообще Viper хорош не только поддержкой нескольких форматов, его основная задача — собирать конфигурационные опции из различных мест с правильным приоритетом:
- значения по умолчанию;
- значения из конфигурационного файла;
- из переменных окружения;
- из удаленных источников конфигурации (Etcd, Consul);
- из аргументов командной строки;
- заданные явно в процессе работы самого приложения.
Таким образом, библиотека позволяет очень гибко конфигурировать приложение.
Среди сложностей миграции, которые возникли, я бы отметил следующие:
- Частое использование interface{} и map[string]interface{}, которые я применял и тут, и там. Не сразу, но постепенно от этого удалось избавиться, применив вместо них строго типизированные структуры. Кстати, это помогло привести внутренний протокол общения между нодами и протокол общения с клиентом в порядок. Понятно, что и какого типа придет или должно быть отправлено.
- Возможные race conditions при доступе к данным из разных горутин. Большинство из них удалось найти с помощью race-детектора Go, который печатает в консоль все замеченные случаи незащищенного каким-либо средством синхронизации доступа к данным из различных горутин. Из средств синхронизации в Go доступны каналы, а также примитивы из пакета sync и atomic.
Огромную помощь оказал
Mr Klaus Post, который нашел несколько race conditions, указал на некоторые стилевые недочеты в коде, а также сделал несколько чрезвычайно полезных pull request-ов.
Есть еще одна интересная возможность Go, открывшаяся уже по ходу переписывания. Это появившаяся в версии Go 1.5 поддержка создания shared library для работы c публичным API библиотеки из Java и Objective-C. Возможно, это дорога к созданию клиентов под iOS и Android? В процессе миграции была полностью переписана
документация. Она теперь охватывает и связывает воедино все проекты, связанные с Centrifugo. Это сам сервер, javascript-клиент, HTTP API-клиенты, веб-интерфейс. Кстати, веб-интерфейс, ранее написанный на Торнадо и находившийся непосредственно в репозитории вместе с кодом сервера, теперь отделен и представляет собой одностраничное приложение на ReactJS (
https://github.com/centrifugal/web). Внимание, гифка:

Python-версия Центрифуги на данный момент практически полностью совместима с Go-версией. Различия совсем незначительные, но в дальнейшем расхождение будет все сильнее, новых возможностей в Centrifuge я добавлять не планирую, только фиксы найденных багов.
Мы уже почти 2 месяца используем Centrifugo в интранете Mail.Ru Group, и проблем пока не возникало. Нагрузка у нас небольшая: 550 одновременно подключенных пользователей в среднем за сутки, около 50 активных каналов в среднем и порядка 30 сообщений в минуту. Чтобы запустить и попробовать Centrifugo, можно скачать бинарный релиз для вашей системы (
https://github.com/centrifugal/centrifugo/releases), есть спека для сборки RPM и Docker image.
Мне часто задают два вопроса. Первый — почему я должен использовать Центрифугу, если есть Редис? Второй — сколько пользователей способен выдержать один инстанс Центрифуги? Первый вопрос странный, и ответ на него: конечно, можно не использовать Центрифугу, но тогда с нуля придется реализовать массу вещей, которые из коробки доступны в проекте. На первый взгляд, это может показаться несложным, но ведь дьявол в мелочах. А этих мелочей прилично, начиная с кода браузерного клиента и заканчивая деплоем. В Центрифуге многие проблемы реального использования уже решены. Она уже с успехом протестирована в бою. Так, например, она позволила нам в Mail.Ru Group провести интерактивную игру для сотрудников: около 50 участников пришли со своими мобильными устройствами — ноутбуками, планшетами и телефонами. Абсолютно все смогли подключиться к игре и в реальном времени получали на экраны вопросы, результаты раунда и статистику игры. При этом ведущий видел, кто реально находился онлайн, что помогало организовать людей в начале игры. Ответ на второй вопрос: я не знаю. Не знаю, потому что можно подключить десятки тысяч одновременных соединений, и все будет замечательно работать. Но в то же время на общую производительность и пропускную способность влияют масса факторов: железо, количество подключений, количество каналов, количество сообщений в каналах. Ответ на данный вопрос может дать только здравая оценка и мониторинг.
Дальнейшие цели такие:
- Клиенты для использования на Android и iOS — по большому счету надежда тут на opensource-сообщество или на shared library на Go, так как ни Objective-C/Swift, ни Java я не знаю.
- Метрики.
- Шардирование? Redis Cluster? Tarantool?
И несколько ссылок в заключение:
P.S. Картинки с гоферами в статье из репозитория на Github:
github.com/hackraft/gophericons
P.S.S. Также хотелось бы поблагодарить хабрапользователей
merc и
sl4mmer, которые внесли значительный вклад в развитие проекта.