http://habrahabr.ru/post/224383/
 Или как я перестал бояться и полюбил ассемблер
Или как я перестал бояться и полюбил ассемблер
Однажды летом, я устроился в родном университете программистом микроконтроллеров. В процессе общения с нашим главным инженером (здравствуйте, Алексей!), я узнал, что чипы спиливают, проекты воруют, заказчики кидают и появление китайского клона наших программаторов для автомобильной электроники — лишь вопрос времени, задавить их можно только высоким качеством. При всем этом, в паранойю впадать нельзя, пользователи вряд ли захотят работать с нашими железками в ошейниках со взрывчаткой.
Хорошая мера защиты — обновления программного обеспечения. Китайские клоны автоматически отмирают после каждой новой прошивки, а лояльные пользователи получают нашу любовь, заботу и новые возможности. Робин Гуды при таком раскладе, естественно, достанут свои логические анализаторы, HEX-редакторы и начнут ковырять процесс прошивки с целью ублажения русско-китайского сообщества.
Хоть у нас и не было проектов, которые требуют подобных мер защиты, было понятно: заняться этим надо, когда-то это пригодится. Погуглено — не найдено, придумано — сделано. В этой статье, я расскажу, как уместить полноценное шифрование в 1 килобайт и почему ассемблер — это прекрасно. Много текста, кода и небольшой сюрприз для любителей старого железа.
Платформа и язык
Все проекты мы делали на ATmega просто потому что в СНГ их проще и дешевле всего купить. Как я понял из разговоров со старшими, это весьма глючное семейство и нужно выполнять много странных действий, чтобы оно безотказно работало. На ассемблере мы писали, потому что задачи крайне чувствительны к скорости работы. Полагаться на компилятор было нельзя и многие участки кода были просчитаны по тактам. К тому же, только на ассемблере можно делать невозможное.
Скажу честно, поначалу я боялся изучать ассемблер, думая, что он вызывает необратимые повреждения мозга и программистскую инвалидность. Да и не просто так люди изобрели С — ассемблер, должно быть, очень сложная штука. Как оказалось, ассемблер — самый простой язык в мире. Ничего проще ассемблера не существует. Моргать светодиодиками, входить в прерывания и пользоваться стеком я научился за один день и приступил к работе. Через пару месяцев, опыта было достаточно для написания проекта, о котором пойдет речь в этой статье.
В ассемблере нет никаких сложных абстракций, что и обеспечивает эту тупоголовую простоту. Конкретно в AVR-версии нет даже циклов. Чтобы организовать цикл, нужно взять регистр, поместить в него количество итераций, уменьшить регистр на единичку в конце тела и, если там еще не 0 — прыгнуть (каким-то из братьев goto) на начало тела. К таким странным конструкциям очень быстро привыкаешь и перестаешь бояться.
Что такое бутлоадер
Бутлоадер — программа, которая запускается сразу же после оживления микроконтроллера. Что бутлоадер делает — решает программист. Как правило, бутлоадеры ответственны за некоторые очень системные функции, вроде обновления ПО, загрузку ОС или настройку окружения для работы следующих программ. Наш бутлоадер будет выполнять одну-единственную функцию — обновлять прошивку микроконтроллера.
В архитектуре AVR, бутлоадер может вызываться двумя способами — натравливанием на него reset-вектора или установкой фьюза BOOTRST, который заставит микроконтроллер начать работу не с 0 адреса, а с адреса начала бутлоадера, размер которого задается, опять же, в фьюзах.
Какие проблемы могут возникнуть на этом этапе? Фьюзы можно редактировать. Сильно умный «пользователь» может, к примеру, перепрограммировать BOOTRST и работа начнется с reset-вектора, а не нашего бута. Он может изменить размер бутлоадера, микроконтроллер начнет выполнять какую-то ересь из середины бута и это может скомпрометировать систему.
Значит, мы должны перенаправить сам reset-вектор на наш бутлоадер, а в его теле расставить безусловные переходы на начало, в тех местах, которые соответствуют разным размерам бутовой области. Без проблем.
Бутлоадер будет определять, выполнять ему пользовательскую программу, или перейти в режим прошивки, по наличию или отсутствию уровня на определенном выводе.
Криптография
Перед началом работы, я закончил 1 часть
курса по криптографии от Дэна Боне на Coursera. Профессор Дэн постоянно говорил о том, что ни в коем случае нельзя писать криптографические системы самостоятельно, этим должны заниматься профессионалы, а не студенты-первокурсники в свои каникулы. Безусловно. В оправдание могу сказать, что этот бутлоадер и не позиционируется как неуязвимая ко всем атакам штука. Его существование — не основная, а дополнительная мера защиты интеллектуальной собственности. Короче говоря, человек должен поковыряться в файле обновления, потыкаться осциллографом, помучиться недельку, подумать «а ну его к черту, заплачу 2000$ китайцам, они его спилят» и сделать именно это. Стоимость программного взлома должна превышать стоимость физического взлома, не более.
Микроконтроллер — открытая система, все инженеры знают, как с ним работать. Микроконтроллеры могут пропрыгивать команды при оверклоке, могут «забывать» про защиту при определенном пониженном напряжении, могут иметь очень глупые дыры, вроде возможности записи и выполнения кода в Flash из RAM, при невозможности чтения (пример — ST92F). Если есть возможность изменить буквально пару байт прошивки — она будет слита полностью. В прошивке, как правило, имеются области с ожидаемой структурой — к примеру, неиспользуемые вектора прерываний, что облегчает изменение пары байт методом тыка. Значит, простым блочным шифром в режиме CBC/CTR не обойтись.
Если никак нельзя допустить возможность изменения прошивки — придется использовать код аутентичности сообщений. Примеры таких кодов — CCM, GCM, EAX. Честно говоря, я уже плохо помню, почему выбрал именно EAX. Скорее всего, его будущая реализация на ассемблере показалась мне наиболее простой.
Каждая прошивка будет иметь свой, случайно-сгенерированный ключ, подключаемый в виде отдельного файла. Этим же файлом шифруются обновления. Защита заключается в том, что мы просто не будем выпускать новые прошивки для скомпрометированных ключей. Придется знать каждого пользователя в лицо, но безопасность требует жертв. Также, во время генерации ключа, будут вычисляться некоторые константы, чтобы микроконтроллеру не пришлось это делать самостоятельно.
EAX
Сколько документации нужно инженеру, чтобы написать шифрование? Две картинки, взятые из
научной работы.

Вспомогательные алгоритмы
Мы гарантируем кратность объема данных размеру блока на этапе шифрования прошивки, что сводит функцию pad к M^B (31) и переменная P (32) не будет использована никогда.
На этапе генерации ключа, мы можем вычислить константу L (40) и, как следствие, B.
«Исключающее или со стрелочкой» (31) означает, что B будет в-xor-ено только в конец строки M.

Процесс шифрования
Где M – незашифрованный текст, CT – шифрованный текст, K – ключ, N – вектор инициализации, H – заголовок.
На ассемблере необходимо будет написать только функцию дешифрования.
Пусть заголовок сообщения H будет задан, неизменен и известен только нам. Это не влияет на криптостойкость, так как подразумевается, что заголовок — публичная информация. Теперь можно вычислить H' (23) на этапе генерации ключа.
Если посмотреть на строки 22, 24, вкупе с 50 и 10, можно осознать, что циферка в верхнем индексе при OMAC перейдет в последний символ строки с длиной, равной длине блока и будет использована в качестве первого блока в CBC т. е. зашифрована. Шифрование этих строк можно провести на этапе генерации ключа. Причем, в файл ключа будут включены только зашифрованные строки с числами 0 (L0) и 2 (L2) — для вычисления N' и C' соответственно.
Имея на руках L0, B и N, вычисление N' сводится к E(L0^B^N).
Итак, на этапе генерации ключа будут вычислены B, L0, L2, H'.
Вместе они займут 64 байта.
AES-128
AES – гениальный в своей простоте алгоритм. К тому же, он обладает большой гибкостью, в зависимости от того, нужна нам производительность или занимаемый объем. В нашем случае, критически важен занимаемый объем и простота. Про AES написано много хороших статей, не буду вдаваться в подробности его устройства.
Особенностью AES является то, что дешифровка алгоритмически сложнее самого шифрования. В процессе дешифровки, нужно умножать на 14 в конечном поле. Поскольку зашитых таблиц умножения в этом ужасе у нас нет, будем пользоваться AES нестандартно — для шифрования обновления на мощном компьютере, будем «дешифровать» его, а при дешифровке на слабеньком микроконтроллере — «шифровать». Разницы в криптостойкости нет.
Я не придумал никакого эффективного (и безопасного) способа расширения ключей. Подготовка всех 11 экземпляров выполняется на этапе генерации ключа. В принципе, по этой причине можно сделать весь блок ключей полностью случайным — это немного увеличит защиту от брутфорса, если какой-то бобер-извращенец решит им заняться.
Расширенный ключ займет 176 байт. Вместе с подсчитанными константами, он образовывает файл ключей, который займет навечно 240 байт Flash. Осталось 784 т. е. 392 ассемблерные команды.
Жизненно важной и огромной частью AES является таблица подстановки — байты, на которые заменяются байты текста. В байте аж 256 возможных комбинаций и таблица займет столько же Flash-памяти. Недопустимо! Значит, будем ее вычислять.
Таблица подстановки вычисляется следующим образом: сначала находится число, обратное номеру элемента таблицы, потом, это обратное, подвергается следующему аффинному преобразованию:

x0...x7 – обратное число в виде вектора. Это нужно написать на ассемблере и уложиться в меньше чем 256 байт, чтобы была выгода. Мы уложимся в 88 байт. Приступим.
Hello, world!
Программист на ассемблере всегда начинает программу с упрощения собственной жизни. Оно заключается в переименовании регистров, чтобы, к примеру, вместо r16 можно было писать temp_0. Я, по традиции, называю 0 и 1 регистры OP0 и OP1, 2 и 3 — NULL и OxFF (заполняя их соответствующими значениями), а остальные — как придется.
Регистры.def OP0 = r0
.def OP1 = r1
.def NULL = r2
.def OxFF = r3
.def b0 = r4
.def b1 = r5
.def b2 = r6
.def b3 = r7
.def b4 = r8
.def b5 = r9
.def b6 = r10
.def b7 = r11
.def b8 = r12
.def b9 = r13
.def bA = r14
.def bB = r15
.def bC = r16
.def bD = r17
.def bE = r18
.def bF = r19
.def temp_0 = r20
.def temp_1 = r21
.def temp_2 = r22
.def temp_3 = r23
.def temp_4 = r24
.def temp_5 = r25
В нашем случае, пришлось использовать почти все регистры, с 4-го по 19-й, для хранения расшифровываемого блока данных. Я вынес его в регистры потому что работать с ними намного проще и быстрее. Любая деятельность с оперативной памятью в микроконтроллерах все равно приводит к работе с регистрами, зачем платить больше.
Регистры с 20 по 25 используются для временного хранения вычисляемых данных и названы соответствующе.
С 26 до 32 идут специальные 16-битные регистры — X, Y, Z, используемые для адресации памяти. Причем, только Z может использоваться для адресации Flash. Как я слышал, они физически имеют технические приспособления для инкремента, декремента и вычисления смещения, поэтому, применение их в других целях, хоть и возможно, считается плохой практикой и может приводить к недопустимым глюкам в ответственных приложениях.
Помимо переименования регистров, посчитаем некоторые полезные константы — количество байт в странице Flash-памяти, размер всего бутлоадера, размер блока шифра, количество страниц памяти, количество блоков данных на страницу и адрес, по которому нужно расположить файл ключей:
Константы.equ PAGE_BYTES = PAGESIZE*2
.equ BOOT_SIZE = 1024
.equ BLOCK_SIZE = 16
.equ PAGES = (FLASHEND+1)/PAGESIZE - BOOT_SIZE/PAGE_BYTES
.equ BLOCKS_PER_PAGE = PAGE_BYTES / BLOCK_SIZE
.equ KEY_ADDR = (FLASHEND + 1) — (BLOCK_SIZE*(11+4))/2
Добавим будущему чуду гибкости — разрешим выбирать скорость связи по UART, порт, вывод и уровень, по которому мы будем решать, оставаться в бутлоадере или продолжить загрузку. Помимо таких утилитарных настроек, можно задать адрес метки, на которую будет совершен прыжок, в случае, если прошивка не требуется, а также, решить, должен ли бутлоадер перешивать нулевую страницу памяти — там расположен вектор прерываний и его перезапись злоумышленником может скомпрометировать систему.
Настройки;Reset address (Where to jump to if not asked to load boot)
.equ RESET_VECT = 0
;Is 0th flash page used?
.equ USE_0th_PAGE = 1
;////////////////////////PORT SETUP
// use port letter...
// A / B / C / D / E
.equ port_used = 'C'
// check status of pin number...
.equ pin = 6
// load boot only if port is...
// (S)ET (1) / (C)LEAR (0)
.equ level = 'C'
;////////////////////////BAUD RATE SETUP
.equ Fosc = 16000000 ;clock frequency
.equ baud = 19200 ;baud rate
.equ UBRR = Fosc / ( BLOCK_SIZE * baud ) - 1
.if high( UBRR ) != 0
.error "Unsupported baud rate setting - high byte of UBRR is not 0!"
.endif
Теперь, разберемся с оперативной памятью. AES требует 256 байт под таблицу замены. Блок данных состоит из вектора инициализации (16 байт), непосредственно данных (размер страницы), метки для проверки целостности (16 байт). Для расшифрования данных, нам нужно сгенерировать дешифрующую последовательность на основе вектора инициализации — еще один размер страницы.
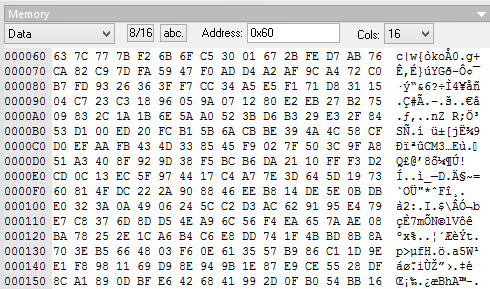
Застолбим место в памяти.dseg
.org 0x60
SBOX: .byte 256 ;rijndael substitution box
;these three SHOULD be consecutive
SAVED_IV: .byte BLOCK_SIZE ;E(L0^N^B)
RCVD_PAGE: .byte PAGE_BYTES ;page to be written
TAG: .byte BLOCK_SIZE ;initially - precomputed header value
ENC_IV: .byte PAGE_BYTES ;IV's to xor with page to decrypt
.cseg
На ATmega16, с размером страницы 64 байта, объем использованной оперативной памяти — 544 байта из 1024. На ATmega8 – 416. Многовато. Существуют микроконтроллеры с большими страницами Flash-памяти при малом объеме оперативной. Возможно, можно что-то придумать, но совместимость со всем семейством мало кому понадобится.
С директивами препроцессора познакомились, перейдем к ассемблеру. Программа традиционно начинается с инициализации указателя стека, выключения прерываний, установки регистров NULL и OxFF, установки настроек UART.
ИнициализацияBOOT_START:
ldi temp_0, low( RAMEND)
out SPL, temp_0
ldi temp_0, high(RAMEND)
out SPH, temp_0
cli
clr NULL
mov OxFF, NULL
com OxFF
ldi temp_0, low( UBRR )
out UBRRH, NULL
out UBRRL, temp_0
ldi temp_0, ( 1 << RXEN ) | ( 1 << TXEN )
out UCSRB, temp_0
ldi temp_0, ( 1 << URSEL ) | ( 1 << UCSZ1 ) | ( 1 << UCSZ0 )
out UCSRC, temp_0
На все это нам хватило аж 6 разных ассемблерных команд, являющихся аббревиатурами или сокращениями. ldi – load into, mov – move, out – output to I\O register, com – complement, cli – clear interrupt flag. Как я уже говорил, ассемблер прост до невозможности. «Сложные» части, со всякими непонятными UBRRH (UART Baud Rate Register High-byte), детально описаны в даташитах и являются настройкой оборудования.
Решим, оставаться в буте, или нет. Выбор регистра порта, согласно настройкам пользователя, выполняется на этапе сборки:
Все еще ничего интересного, можно не смотреть.if port_used == 'A'
cbi DDRA, pin
sbi PORTA, pin
nop
.if level == 'S'
sbis PINA, pin
.elif level == 'C'
sbic PINA, pin
.endif
.elif port_used == 'B'
cbi DDRB, pin
sbi PORTB, pin
nop
.if level == 'S'
sbis PINB, pin
.elif level == 'C'
sbic PINB, pin
.endif
.elif port_used == 'C'
cbi DDRC, pin
sbi PORTC, pin
nop
.if level == 'S'
sbis PINC, pin
.elif level == 'C'
sbic PINC, pin
.endif
.elif port_used == 'D'
cbi DDRD, pin
sbi PORTD, pin
nop
.if level == 'S'
sbis PIND, pin
.elif level == 'C'
sbic PIND, pin
.endif
.elif port_used == 'E'
cbi DDRE, pin
sbi PORTE, pin
nop
.if level == 'S'
sbis PINE, pin
.elif level == 'C'
sbic PINE, pin
.endif
.endif
;if user asked to load boot - this will be skipped
jmp RESET_VECT
Немного оригинальной будет процедура чтения\записи в последовательный порт. Так как у нас мало места и небольшие скорости, я решил совместить подтверждение готовности к работе с получением данных и разбить процедуру на несколько, имеющих разные возможности. На ассемблере, это очень просто сделать, вызывая подпрограмму по разным меткам:
Готовность и получение за 8 команд;UART <- 0xC0
;temp_0 <- UART
confirm_and_read:
ldi temp_0, 0xC0
;UART <- temp_0
;temp_0 <- UART
UART_send:
sbis UCSRA, UDRE ;skip next command if readiness bit is set
rjmp UART_send
out UDR, temp_0
;temp_0 <- UART
UART_read:
sbis UCSRA, RXC
rjmp UART_read
in temp_0, UDR
ret
Унылая часть завершена, мир для будущей работы построен. Начнем работать.
Таблица подстановки за 88 байт
Для начала, нужно найти число, обратное данному, в конечном поле. Такое, чтобы при умножении этого числа на данное, получилась 1. Алгоритм умножения описан в статье на
вики , не буду приводить его.
Нахождение обратного в конечном поле — сложная задача. Тут нужно применить расширенный алгоритм Эвклида… но мы инженеры. Уберите выпускников computer science от экранов. Мы ищем обратный элемент полным перебором, с помощью умножения.
Поиск обратного элемента ldi XH, high(SBOX) ;point X to SBOX memory location
ldi XL, low( SBOX)
ser bF ;first inc will overflow to 0
next_box:
inc bF
mov temp_1, bF ;save input in temp_1
cp temp_1, NULL ;if it's null - return
breq sbox_byte_done ;return here
mov OP0, OxFF ;so it overflows
look_more:
inc OP0 ;try next candidate
;temp_0 <- OP0 * temp_1 (in a Galois field)
;branching is fine, function used in precomputation only
finite_multiplication:
mov b0, OP0 ;operand 0 (candidate)
mov b1, temp_1 ;operand 1 (current byte)
ldi temp_2, 0x1B ;0x1B holder
clr temp_0 ;multiplication result
next_bit:
lsr b0 ;operand 0 >> 1
brcc PC+2 ;if lsb of operand 0 was 1
eor temp_0, b1 ;xor operand 1 into result
lsl b1 ;operand 1 << 1
brcc PC+2 ;if msb of operand 1 was 1
eor b1, temp_2 ;xor 0x1B into operand 1
cp b0, NULL ;while there are bits in operand0
brne next_bit ;work on it
cpi temp_0, 1 ;if multiplication result was not 1
brne look_more ;inverse is in OP0
После чего, проводим аффинное преобразование и сохраняем результат в память. Оно собрано из простейших кубиков. Программирование на ассемблере — замечательное упражнение для мозгов. Всегда можно найти более элегантное решение, сохранить еще пару команд, выжать еще пару тактов, причем, эта экономия на спичках порой — вопрос жизни и смерти. Это параллельный волшебный мир программирования, в котором процесс кодинга превращен в сборку конструктора.
Аффинное преобразование на ассемблере clr temp_1 ;affine transform result
ldi temp_5, 0b11110001 ;matrix producer
ldi temp_3, 0b00000001 ;current bit mask
process_bit:
mov temp_4, OP0 ;multiplicative inverse
and temp_4, temp_5 ;and with matrix producer
pop_next_bit:
lsl temp_4 ;inv&matrix << 1
brcc PC+2 ;if it had msb
eor temp_1, temp_3 ;sum bit into result
cp temp_4, NULL ;while operand has bits
brne pop_next_bit ;work on it
lsl temp_3 ;move to next bit
lsl temp_5 ;cyclically shift matrix producer
brcc PC+2 ;if it had msb
ori temp_5, 1 ;move msb to lsb
cp temp_3, NULL ;while there are bits left
brne process_bit ;process next bit
sbox_byte_done:
ldi temp_2, 0b01100011 ;0x63
eor temp_1, temp_2 ;xor it into result
st X+, temp_1 ;save to memory
cpse bF, OxFF ;if we're at last byte
rjmp next_box ;we're done
Миссия выполнена.
Как быстро все это работает? В симуляторе — 2203268 такта. 0.27 секунды на частоте 8 МГц. Я считаю, это замечательная скорость.
Мы потеряли 256 байт оперативной памяти и 0.27 секунд на старте, сохранив 168 байт Flash-памяти и решив замечательную головоломку.
Таблица подмены готова, экспансия ключей проведена на компьютере — есть все необходимое для реализации AES.
Assembled Encryption Standard
Начнем с элементарных операций. На каждом этапе дешифрования, ключ суммируется с данными. Данные находятся в файле регистров, с 4-го, их таких 16 штук, а на текущий ключ пусть всегда указывает регистр Z. Регистры-указатели могут указывать не только на области SRAM или Flash, но и на файл регистров, что очень сильно упрощает нам жизнь и ускоряет работу системы.
Add round keyadd_round_key:
clr YH ;point to register file
ldi YL, 4
xor_Z_to_Y:
lpm temp_0, Z+ ;load key byte
ld temp_1, Y ;load data byte
eor temp_1, temp_0 ;xor them
st Y+, temp_1 ;store back to data
cpi YL, low( 4 + 16 ) ;check if it was the last byte
brne xor_Z_to_Y ;if not - process next data byte
ret
Еще одна простая операция — перемешивание рядков. Каждый рядок данных циклически сдвигается влево на свой порядковый номер. Нужно просто подумать, какой байт с каким поменять и, наконец, применить эти полезные навыки обмена двух переменных местами без использования дополнительной переменной. Плюс решения — можно перемешать все эти операции между собой для дополнительной защиты от атак сторонними каналами.
Shift rows;cyclical shift: 0_row << 0; 1_row << 1; 2_row << 2; 3_row << 3
shift_rows:
;1st row
eor b1, bD
eor bD, b1
eor b1, bD
eor b1, b5
eor b5, b1
eor b1, b5
eor b5, b9
eor b9, b5
eor b5, b9
;2nd row
eor b2, bA
eor bA, b2
eor b2, bA
eor b6, bE
eor bE, b6
eor b6, bE
;3rd row
eor b3, bF
eor bF, b3
eor b3, bF
eor b7, bF
eor bF, b7
eor b7, bF
eor bB, bF
eor bF, bB
eor bB, bF
;done
ret
Замена всех данных на соответствующие им подмены из таблицы — казалось бы, тривиальная задача. Простой подход, в лоб, имеет фатальный недостаток: он слишком линеен. Линейность, неизменность и понятность — потенциальные уязвимости для атаки сторонними каналами. Грубо говоря, нам нечего менять в реализации от случая к случаю, без неизменности результата, для дополнительного уровня защиты. Поступим иначе. Будем обрабатывать один столбец за раз. Меняем порядок обхода — и атакующий будет мучиться еще неделю.
За подстановкой всегда следует смещение строк, поэтому, не будем разделять эти процедуры.
Sub bytessubstitute_shift_rows:
ldi XH, high(SBOX)
ldi XL, low( SBOX)
movw OP0, X
;one column at a time
clr YH
ldi YL, 4
sub_next:
movw X, OP0
ldd temp_0, Y+0x08
add XL, temp_0
adc XH, NULL
ld temp_0, X
std Y+0x08, temp_0
movw X, OP0
ldd temp_0, Y+0x0C
add XL, temp_0
adc XH, NULL
ld temp_0, X
std Y+0x0C, temp_0
movw X, OP0
ldd temp_0, Y+0x04
add XL, temp_0
adc XH, NULL
ld temp_0, X
std Y+0x04, temp_0
movw X, OP0
ldd temp_0, Y+0x00
add XL, temp_0
adc XH, NULL
ld temp_0, X
st Y+, temp_0
sbrs YL, 3 ;XL == 8
rjmp sub_next
Приближаемся к порталу в ад. Перед входом туда, нам нужно изобрести умножение на 2. С инженерной точки зрения, умножение на 2 в конечном поле отличается от простого тем, что после сдвига влево, к результату нужно прибавить 0x1B, если старший бит множителя был единичкой. Если бит был единичкой, то… нельзя использовать переходы и условия в ответственных участках криптографических систем. Без проблем! Перед сдвигом влево, мы сохраним старший бит и потом будем записывать его в нужные места пустого регистра, пока не соберем там 0x1B, если бит был единичкой, или 0, если он был нулем.
Сюрприз. В моей реализации, процедура умножения на 2 разместилась на одном из размеров бутлоадера. В точку попадания этого размера, поместим безусловный переход на начало бута и, чтобы он не мешал жить при каждом умножении на 2, перепрыгнем его.
Sub bytes;temp_0 <- temp_0 * 2 (in a finite field)
;temp_0 = (temp_0 << 1) ^ (0x1B & MSB(temp_0))
;NO BRANCHING HERE
;uses NULL in a dirty way
mul_by_2:
bst temp_0, 7 ;store 7th bit in T
bld NULL, 0 ;we form 0x1B in NULL if T is set
rjmp cont_mul
rjmp BOOT_START ;0x1F80. BOOTSZ can be here
cont_mul:
bld NULL, 4
lsl temp_0
bld NULL, 3
bld NULL, 1
eor temp_0, NULL
clr NULL
ret
Остался последний этап — смешение столбцов. Элементы каждого столбца подвергаются следующему преобразованию:
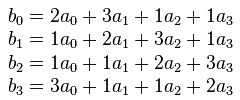
Умножение на 2 мы написали выше. Сложение в конечном поле — исключающее или. Для умножения на 3, нужно просто еще раз прибавить число к результату умножения на 2. Сложность в том, что мы, внезапно, пишем на ассемблере, ограничены в объеме кода и придется много считать. Оптимизации придется выполнять в уме и комментариях. Нужно очень аккуратно продумать ход вычислений и использовать регистры с умом.
Mix columnsmix_columns:
;point to register file
clr YH
ldi YL, 4
next_column:
ldd temp_2, Y+0x00 ;result0
ldd temp_3, Y+0x01 ;r1
ldd temp_4, Y+0x02 ;r2
ldd temp_5, Y+0x03 ;r3
mov temp_0, temp_3 ;r1 to operand
rcall mul_by_2 ;r1 * 2
mov temp_1, temp_0 ;save r1 * 2
eor temp_0, temp_2 ;r0 + r1 * 2
eor temp_0, temp_5 ;r0 + r1 * 2 + r3 (lacks r2 * 3)
std Y+0x01, temp_0 ;to r1
mov temp_0, temp_2 ;r0 to operand
rcall mul_by_2 ;r0 * 2
mov OP0, temp_0 ;OP0 <- r0 * 2
eor temp_0, temp_1 ;r0 * 2 + r1 * 2
eor temp_0, temp_3 ;r0 * 2 + r1 * 3
eor temp_0, temp_4 ;r0 * 2 + r1 * 3 + r2
eor temp_0, temp_5 ;r0 * 2 + r1 * 3 + r2 + r3 (done)
std Y+0x00, temp_0 ;to r0
mov temp_1, OP0 ;OP0 -> r0 * 2
mov temp_0, temp_5 ;r3 to operand
rcall mul_by_2 ;r3 * 2
mov OP0, temp_0 ;OP0 <- r3 * 2
eor temp_0, temp_1 ;r3 * 2 + r0 * 2
eor temp_0, temp_2 ;r0 * 3 + r3 * 2
eor temp_0, temp_3 ;r0 * 3 + r1 + r3 * 2
eor temp_0, temp_4 ;r0 * 3 + r1 + r2 + r3 * 2 (done)
std Y+0x03, temp_0 ;to r3
mov temp_1, OP0 ;OP0 -> r3 * 2
mov temp_0, temp_4 ;r2 to operand
rcall mul_by_2 ;r2 * 2
mov OP0, temp_0 ;OP0 <- r2 * 2
eor temp_0, temp_1 ;r2 * 2 + r3 * 2
eor temp_0, temp_5 ;r2 * 2 + r3 * 3
eor temp_0, temp_2 ;r0 + r2 * 2 + r3 * 3
eor temp_0, temp_3 ;r0 + r1 + r2 * 2 + r3 * 3 (done)
std Y+0x02, temp_0 ;to r2
mov temp_1, OP0 ;OP0 -> r2 * 2
ldd temp_0, Y+0x01 ;r0 + r1 * 2 + r3
eor temp_0, temp_1 ;r0 + r1 * 2 + r2 * 2 + r3
eor temp_0, temp_4 ;r0 + r1 * 2 + r2 * 3 + r3 (done)
std Y+0x01, temp_0 ;to r1
adiw Y, 4 ;pointer to next column
cpi YL, 20 ;if not done
brne next_column ;process next
ret
Просто много арифметики. В процессе вычисления, происходит 6 обращений к памяти вместо ожидаемых 4, но, как мне кажется, максимально возможная пространственная оптимизация достигнута.
Итак, все необходимые для AES этапы шифрования написаны. Соберем их воедино. Сохранять указатели в стек перед началом работы и восстанавливать их позже — хорошая практика. Почти всегда они используются где-то еще и основная программа не ожидает такой подставы, как изменение указателей на память в одной из процедур. То же самое относится и к статус-регистру. Если вы не ограничены в пространстве — всегда сохраняйте статус-регистр в начале процедуры и восстанавливайте его перед возвратом!
Само шифрование;performs a round of encryption
;using given expanded keys and s-box
Rijndael_encrypt:
push ZH
push ZL
push YH
push YL
push XH
push XL
ldi ZH, high(KEYS*2)
ldi ZL, low( KEYS*2)
rcall add_round_key
ldi temp_0, 9
encryption_cycle:
push temp_0 ;store cycle counter
rcall substitute_shift_rows
rcall mix_columns
rcall add_round_key
rjmp continue_enc
rjmp BOOT_START ;0x1F00. BOOTSZ can be here
continue_enc:
pop temp_0 ;restore cycle counter
dec temp_0
brne encryption_cycle
rcall substitute_shift_rows
rcall add_round_key
pop XL
pop XH
pop YL
pop YH
pop ZL
pop ZH
ret
Посчитаем, во сколько байт мы уложились. Сложение с ключом — 18 байт. Умножение на 2 — 22 байта. Сдвиг рядков — 50 байт. Подстановка — 62 байта. Перемешивание столбцов — 94 байта. Связать все это — 56 байт. Суммарно — 302 байта. Понять, что ты это сделал — бесценно. Чуть больше среднего размера заголовка исполняемого файла Windows.
Блочный шифр — хорошо, но без специального режима шифрования, он практически бесполезен. Если блочному шифру нечего делать — он тоже бесполезен, поэтому, займемся приемом данных.
Протокол обмена информацией
Блок зашифрованных данных в EAX, как и в практически любой другой схеме аутентифицированного шифрования, состоит из вектора инициализации, самих данных и подписи. Вектор инициализации и подпись имеют длину блока нижележащего шифра, сами данные произвольной длины, в нашем случае — размер страницы Flash. Вспомните этап выделения памяти — элементы блока данных расположены в SRAM последовательно, для облегчения процедуры принятия данных от компьютера.
С целью упрощения конструкции, не будем задумываться о каком-либо вычурном формате данных — мы принимаем прошивку, которая должна заполнить собой весь объем Flash. Все области памяти, которые непосредственно в прошивке не задействованы, обязаны быть заполнены случайными байтами. Таким образом, нельзя выпустить маленький патч, исправляющий буквально пару команд — бутлоадер будет перешивать все. Это может быть долго, но безопасность превыше всего.
Протокол обмена данными следующий: сразу после генерации таблицы подмены, бутлоадер выдает в порт байт 0xC0 (COnfirm) и ждет байт 0x60 (GO). После сигнала готовности от компьютера, бут выставляет указатель Z на начало записываемой области памяти, записывает в temp_0 количество страниц, которые нужно будет принять, расшифровать и записать, и переходит к приему страницы. Выглядит это следующим образом:
Начало работыwait_for_start:
rcall confirm_and_read
cpi temp_0, 0x60
brne wait_for_start
;/////////////////////////////PAGE ADDR INIT
.if USE_0th_PAGE == 0
ldi ZH, high(PAGE_BYTES)
ldi ZL, low( PAGE_BYTES)
ldi temp_0, PAGES - 1
.else
clr ZH
clr ZL
ldi temp_0, PAGES
.endif
next_page:
;save page counter and address
push temp_0
push ZH
push ZL
;/////////////////////////////BLOCK RECEPTION
;receive whole block
ldi XH, high(SAVED_IV)
ldi XL, low( SAVED_IV)
ldi temp_1,( BLOCK_SIZE /*nonce*/ + PAGE_BYTES /*page*/ + BLOCK_SIZE /*expected tag*/ )
get_more_block:
rcall confirm_and_read
st X+, temp_0
dec temp_1
brne get_more_block
Как мы помним из листинга функции confirm_and_read, она сначала отправляет 0xC0, потом ждет ответа. Это обеспечивает синхронизацию с компьютером в ее простейшем виде — программное обеспечение должно отправлять следующий байт только при полной готовности принимающей стороны. Это, конечно, медленно — на прием-передачу данных уходит больше времени, чем на расшифрование, которым мы сейчас займемся.
EAX Assembled
Если мы будем реализовывать EAX именно так, как показано на Двух Документирующих Картинках — мы не уложимся в объем. Поэтому, подкорректируем ход событий.
Подпись — сумма зашифрованного вектора инициализации (N, от Nonce), заголовка данных (его обработка выполняется на этапе генерации ключа) и кода аутентификации самих данных, вычисленного с помощью алгоритма CMAC\OMAC. Вычисленная на месте подпись должна сойтись с той, которую нам прислали. Исключающее или двух одинаковых чисел равно 0. Значит, будем суммировать все вычисляемые значения прямо в полученную подпись, а потом проверим, все ли ее значения обратились в 0.
Нам уже известен H' – заданный и обработанный заголовок, находящийся в файле ключей. Сразу же сложим его с полученной подписью:
Начало работы;/////////////////////////////TAG INITIALIZATION
;initialize precomputed header with tag
;tag <- H ^ tag
header_to_tag:
ldi ZH, high(PRECOMP_HEADER_TAG*2)
ldi ZL, low( PRECOMP_HEADER_TAG*2)
ldi YH, high(TAG)
ldi YL, low( TAG)
next_header_byte:
lpm temp_0, Z+
ld temp_1, Y
eor temp_0, temp_1
st Y+, temp_0
cpi YL, low( TAG + BLOCK_SIZE )
brne next_header_byte
Следующий простой этап — вычисление N'. Все необходимые данные для этого у нас есть. Облегчим себе жизнь, выделив все манипуляции с блоками памяти в отдельные процедуры. Нам может понадобиться перемещение блока данных в файл регистров, сложение двух блоков данных по указателю и.т.п. В двух процедурах, в зависимости от метки вызова, разместилось аж 9. Не слышал, чтобы такая оптимизация была возможна на языке более высокого уровня.
Вспомогательные функции;block <- block ^ Z
xor_Z_to_block_RAM:
ldi YH, 0
ldi YL, 4
;Y <- Y ^ Z
xor_Z_to_Y_RAM:
ldi temp_2, BLOCK_SIZE
;Y <- Y ^ Z ( temp_2 times )
ram_xor_cycle:
ld temp_3, Z+
ld temp_1, Y
eor temp_1, temp_3
st Y+, temp_1
dec temp_2
brne ram_xor_cycle
ret
;block -> SAVED_IV
save_IV:
ldi YH, high(SAVED_IV)
ldi YL, low( SAVED_IV)
;block -> Y
from_regs_to_Y:
ldi XH, 0
ldi XL, 4
rjmp move_from_X_to_Y
;SAVED_IV -> block
rest_IV:
ldi XH, high(SAVED_IV)
ldi XL, low( SAVED_IV)
;X -> block
from_X_to_regs:
ldi YH, 0
ldi YL, 4
;X -> Y
move_from_X_to_Y:
ldi temp_0, 0x10
;X -> Y ( temp_0 times )
ram_save_cycle:
ld temp_1, X+
st Y+, temp_1
dec temp_0
brne ram_save_cycle
ret
Теперь, приступим к вычислению N' согласно Документирующим Картинкам. Тут используется подготовленное на этапе генерации ключа B и L0. Все происходящее, традиционно, описывается в комментариях. В конце вычисления, полученное N' суммируется с подписью.
Обработка вектора инициализации;/////////////////////////////NONCE
;block <- N
ldi XH, high(SAVED_IV)
ldi XL, low( SAVED_IV)
rcall from_X_to_regs
;block <- N ^ B
ldi ZH, high(PRECOMP_B*2)
ldi ZL, low( PRECOMP_B*2)
rcall add_round_key
;block <- N ^ B ^ L0
ldi ZH, high(PRECOMP_L0*2)
ldi ZL, low( PRECOMP_L0*2)
rcall add_round_key
;block <- E( N^B^L0 ) (nonce)
rcall Rijndael_encrypt
;save calculated nonce
rcall save_IV
;tag <- H ^ N ^ expected
ldi YH, high(TAG)
ldi YL, low( TAG)
ldi ZH, high(SAVED_IV)
ldi ZL, low( SAVED_IV)
rcall xor_Z_to_Y_RAM
Для шифрования данных, EAX использует AES в режиме CTR – счетчика. Этот режим превращает блочный AES в потоковый шифр, которым можно без особых проблем шифровать данные произвольной длины. Вектором инициализации выступает только что подготовленный N', который, каждый блок, увеличивается на единичку и шифруется.
Увеличение на единичку — проблема, когда у нас число из 16 случайных байт, придется обработать все переносы до одного, мало ли. Ничего сложного.
Инкремент 16-ти регистров одновременно;block++
;all carrying is done properly
increment_regs:
ldi YH, 0
ldi YL, 20
clr temp_0
carry_next:
ld temp_0, Y
cpi temp_0, 1
ld temp_0, -Y
adc temp_0, NULL
st Y, temp_0
cpi YL, 5
brsh carry_next
ret
Складываем зашифрованный вектор инициализации с данными — получаем расшифрованные данные. Расшифровывать до проверки подписи мы их не будем, они будут расшифрованы непосредственно перед записью в память. Но N' уже готово, память под код расшифровки выделена — почему бы его не сгенерировать?
Режим CTR;/////////////////////////////DECRYPTION IVs
ldi YH, high(ENC_IV)
ldi YL, low( ENC_IV)
IV_calc_cycle:
;block <- E(IV)
rcall Rijndael_encrypt
;ENC_IV <- E(IV)
rcall from_regs_to_Y
push YH
push YL
;IV++
rcall rest_IV
rcall increment_regs
rcall save_IV
pop YL
pop YH
cpi YL, low( ENC_IV + PAGE_BYTES )
brne IV_calc_cycle
Самая сложная часть — код аутентификации сообщения. Он основан на CBC – не самом удобном для реализации в ассемблере режим шифрования. Честно говоря, не знаю, почему люди все еще используют CBC вместо CTR в обычной жизни. Он требует выравнивания до размера блока, не параллелизируется, имеет несколько забавных уязвимостей при неправильной реализации и, в целом, сложнее. К счастью, о выравнивании мы позаботились на этапе шифрования прошивки.
Обратите внимание, что B, согласно Картинкам, суммируется только с последним блоком — в конец шифруемой строки. Как и в случае с вектором инициализации, полученный код аутентификации сразу же суммируется с подписью.
Вычисление CMAC/OMAC подписи;/////////////////////////////CMAC / OMAC TAG CALCULATION ( block <- C )
;X contains 20 after last save_IV command
clear_registers:
st -X, NULL
cpi XL, 4
brne clear_registers
;block <- L2
ldi ZH, high(PRECOMP_L2*2)
ldi ZL, low( PRECOMP_L2*2)
rcall add_round_key
;last block is processed individually
ldi temp_0, BLOCKS_PER_PAGE
ldi ZH, high(RCVD_PAGE)
ldi ZL, low( RCVD_PAGE)
CBC_TAG:
;block <- block ^ m(i)
;temp_0 is fine
rcall xor_Z_to_block_RAM
push temp_0
cpi temp_0, 1
brne dont_add_B
ldi ZH, high(PRECOMP_B*2)
ldi ZL, low( PRECOMP_B*2)
rcall add_round_key
dont_add_B:
;Z is saved properly
rcall Rijndael_encrypt
pop temp_0
dec temp_0
brne CBC_TAG
;block <- H ^ N ^ C ^ expected
ldi ZH, high(TAG)
ldi ZL, low( TAG)
rcall xor_Z_to_block_RAM
Мы только что установили последнюю деталь в пазл и можем проверить, сошлась подпись, или нет. Условие правильности подписи — все ее байты должны обратиться в 0. Традиционная криптографическая проверка — объединить все значения с помощью ИЛИ в отдельный регистр, никаких условий. После цикла решается, записывать данные во Flash, или сообщить об ошибке подписи и помереть.
Традиционная безопасная проверка подписи;/////////////////////////////TAG CHECK
clr temp_0
check_more:
ld temp_1, -Y
or temp_0, temp_1
cpi YL, 4
brne check_more
cp temp_0, NULL
breq do_write
rjmp die
Метка die отправляет нас в бесконечный цикл, отправляющий 0xFF на любой запрос. Прошивающая программа должна заметить неправильные байты подтверждения и оповестить пользователя о том, что файл не подходит.
Вечный цикл ошибки;/////////////////////////////TAG FAILURE AND EXIT
die:
ldi temp_0, 0xFF
rcall UART_send
rjmp die
В случае, если подпись верна — мы восстанавливаем указатель Z на текущую страницу Flash и переходим в процедуру записи. Если эта страница была последней — переходим на метку upload_done, которая отправляет прошивающему байт успеха — 0x0C и уходит в цикл смерти.
Все хорошо — переходим к записи;/////////////////////////////TAG SUCCESS - CTR AND WRITE
do_write:
;restore page pointers
pop ZL
pop ZH
;decrypt and write page
rcall store_page
;restore page counter
pop temp_0
dec temp_0
;continue if not done, else - die
breq upload_done
rjmp next_page
Процедура расшифровки и записи в Flash ничем не примечательна, я просто следовал документации по самопрограммированию. Единственное интересное место — попытка испортить записываемый в Flash байт содержимым регистра temp_0, в котором должен быть результат упаковывания подписи. Если подпись была правильной — в temp_0 находится 0 и с данными ничего не случится. Если по какой-то причине микроконтроллер успешно «перелетел» всю проверку и начал писать во Flash – по крайней мере, он будет писать туда мусор.
Процедура самопрограммирования железо-зависима, при портировании на другие микроконтроллеры, может быть необходимо подкорректировать вызов команды store program memory.
Расшифровка данных и запись во Flash;D( RCVD_PAGE ) -> flash
store_page:
;erase current page
ldi temp_1, 0b00000011
rcall spm_it
ldi YH, high(RCVD_PAGE)
ldi YL, low( RCVD_PAGE)
ldi XH, high(ENC_IV)
ldi XL, low( ENC_IV)
write_next:
ld r0, Y+
ld temp_2, X+
eor r0, temp_2
ld r1, Y+
ld temp_2, X+
eor r1, temp_2
;last countermeasure - if we jumped through tag check
eor r0, temp_0
eor r1, temp_0
;store word to page buffer
ldi temp_1, 0b00000001
rcall spm_it
adiw Z, 2
cpi YL, low( RCVD_PAGE + PAGE_BYTES )
brne write_next
;write page
;back to page start
subi ZL, low( PAGE_BYTES)
sbci ZH, high(PAGE_BYTES)
;write page
ldi temp_1, 0b00000101
rcall spm_it
;to next page start
subi ZL, low( -PAGE_BYTES)
sbci ZH, high(-PAGE_BYTES)
;re-enable flash
ldi temp_1, 0b00010001
rcall spm_it
ret
spm_it:
in temp_2, SPMCSR
sbrc temp_2, SPMEN
rjmp spm_it
out SPMCSR, temp_1
spm
ret
Собираем все воедино. Ровно 1024 байта. Осталось прошить микроконтроллер, выставить фьюзы и написать клиентское ПО.

Тестирование
Не будем мучиться с клиентским ПО, напишем генератор ключей и шифровальщик прошивок на Qt, с использованием Crypto++. Статический заголовок для шифрования вписан туда же, намертво. Все неиспользуемые области памяти заполняются случайными байтами.
Прошивальщик элементарен — ждем 0xC0, отправляем 0x60 и, пока файл не закончится, отправляем байт в ответ на каждый 0xC0. Получили 0x0C – все готово, получили 0xFF – произошла ошибка. Напишем его на чистом С для Linux. COM-порта у меня на ноутбуке нет, поэтому… используем Psion 5MX, который младше меня всего на 5 лет.

Достанем из закромов родины какую-то плату с ATmega8A, прошьем ее бутом, соединим с куском платы с MAX233, соберем на Псионе прошивальщик, перемотаем все это случайными проводочками, укажем прошивальщику порт и файл прошивки, перезапустим блок питания… Процесс пошел.
Прошу прощения за состояние стола и тестовый стенд — радиоэлектронщик из меня не очень.
Вся задача тестовой программы — потушить светодиод и повиснуть навсегда. После прошивки, ей это удается. Успех!
Старательный Псион передал 10КБ в порт и ждет указаний
Таким нехитрым образом, можно сделать невозможное и оставить много места для пользовательского кода. Теперь есть способ выкатывать патчи, совершенно не беспокоясь о том, что исходники украдет какой-то китайский шпион.
Буду рад, если кто-то найдет критические ошибки безопасности в моей реализации.
Все исходные коды и эта статья распространяются под лицензией CreativeCommons Attribution-NonCommercial-ShareAlike.

Репозиторий на GitHub:
github.com/sirgal/AVR-EAX-AES-bootloader
(весь код для ПК написан впопыхах и, местами, год назад, буду рад, если кто-то пожелает этот ужас исправить, у меня пока нет времени)



