https://habrahabr.ru/company/ods/blog/330118/- Обработка изображений
- Машинное обучение
- Алгоритмы
- Python
- Блог компании Open Data Science

Сразу оговорюсь, что данный пост не несет большой технической нагрузки и должен восприниматься исключительно в режиме «пятничной истории». Кроме того, текст насыщен английскими словами, какие-то из них я не знаю как перевести, а какие-то переводить просто не хочется.
Краткое содержание
первой части:
1.
DSTL (научно-техническая лаборатория при министерстве обороны Великобритании) провела
открытое соревнование на Kaggle.
2. Соревнование закончилось 7 марта, результаты объявлены 14 марта.
3. Пять из десяти лучших команд — русскоговорящие, причем все они являются членами
сообщества Open Data Science.
4. Призовой фонд в $100,000 разделили брутальный малазиец
Kyle, команда
Романа Соловьева и
Артура Кузина, а также
я и
Сергей Мушинский.
5. По итогам были написаны блог-посты (
мой пост на хабре,
пост Артура на хабре,
наш с Серегой пост на Kaggle), проведены выступления на митапах (
мое выступление в Adroll,
мое выстпление в H20.ai,
выступление Артура в Yandex, выступление
Евгения Некрасова в Mail.Ru Group), написан
tech report на arxiv.
Организаторам понравилось качество предложенных решений, но не понравилось, сколько они отстегнули за это соревнование. В Каggle ушло $500k, в то время как призовые всего $100k.
Был сделан логичный вывод — создать свой британский Kaggle с преферансом и гимназистками. Знаний и умений у двигателей науки при министерстве обороны UK и MI6, на серьезный AI Research не хватит, поэтому вместо того, чтобы сделать закрытый междусобойчик для своих, они устроили открытое соревнование, но с мутными правилами, а именно: участвовать могут все, а вот на призовые претендовать только те, кто является гражданами и проживает в странах, которые выше некой отсечки в
очередном коррупционном рейтинге 2014 года. Почему 2014, а не чего-то более свежего? Это до сих пор непонятно. Существует конспирологическое мнение, что 2014 год был выбран именно для того, чтобы оставить за бортом китайцев и не оставить индусов. А вот в 2016 году Индия и Китай имеют одинаковый рейтинг, так что фокус бы не прошел.
Написать сайт, имитирующий Kaggle, у двигателей науки навыка тоже не хватило, поэтому они наняли подрядчика, а именно,
британского коррупционера BAE Systems.
Для получения денег за то соревнование, про которое рассказано в
первой части, было необходимо провести skype-конференцию с представителями DSTL и в двух словах описать решение. Мы презентовали, описали. Они откровенно плыли и, собственно, отчасти на этом основывается мое самоуверенное предположение о том, что специалистов высокого полета у них нет. Но сами по себе эти британские ученые достаточно адекватные, и в конце нашей речи их главный, в качестве рекламы, упомянул, что они тоже не пальцем деланы, и что у них есть
своя площадка для проведения соревнований, и что вот только что стартовали две задачи, одна —
под Computer Vision, другая —
под Natural Language Processing и у каждой призовой фонд 40 тысяч фунтов (20k, 12k, 8k). Мы ответили, что в курсе и, в свою очередь, вежливо поинтересовались: «А почему у вас правила дискриминационные”? Мужик ответил, что это все ерунда, что это не они, а подрядчик, который проводит соревнование так начудил, и что DSTL тоже против дискриминации, что всё поменяют и вообще, счастья всем и каждому.
Позже мы уточнили по email, насколько серьезно они намереваются придерживаться правильной линии партии и получили в ответ:
— There is likely to be a change to the terms and conditions relating to the datasciencechallenge.org. The original conditions were set by the company who are running the challenge for us (based on legal grounds) but following feedback they have/will be changed. Please don't let it put you off participating.
Но на самом деле, это все было не важно. Идея в том, что с одной стороны я сильно проседал на знаниях в Object Detection и под это дело лихо пролетал на интервью. Например, в Nvidia на self driving car, я влетел на том, что Image Classification я умею, Image Segmentation умею, а вот Object Detection, который очень важен для многих бизнесовых задач, которые используют компьютерное зрение — нет. А как известно, учиться лучше в бою, так что это надо либо свой проект в свободное время пилить, либо поработать над каким-нибудь соревнованием.
Стоит добавить, что задача
про классификацию рыбок, в которой нужен был object detection прошла для меня по нулям как раз из-за нехватки знаний, ну и другие задачи, которые к тому моменту уже начались, но не закончились, то есть
про рак шейки матки,
про подсчет морских котиков, да и ImageNet 2017, тоже угнетали, заставляя комплексовать на тему собственной беспомощности.
Суммируя:
1. О том, что денежный приз гражданам России не светит, было известно заранее. Когда позже вся эта история прошла по новостям этот кусок опускался, так как работать в режиме „наших бьют“ гораздо выгоднее для рейтинга. Да, была надежда, что правила поменяют, но „обещать — не значит жениться“, так что сильно на это никто не рассчитывал.
2. Соревнования — это 10-100x по специфичным знаниям в единицу времени в машинном обучении, по сравнению с академической средой или работой. Очень было нужно разобраться в Object Detection, плюс, хотелось, чтобы появился pipeline под этот тип задач, так как pipeline'ы имеют привычку кочевать из проблемы в проблему, трансформируя многие задачи из „что-то как-то понятно, но не очень — влечу на пару месяцев“ в „задача сложная, значит на написание pipeline уйдет не один вечер, а целых два“.
Постановка задачи
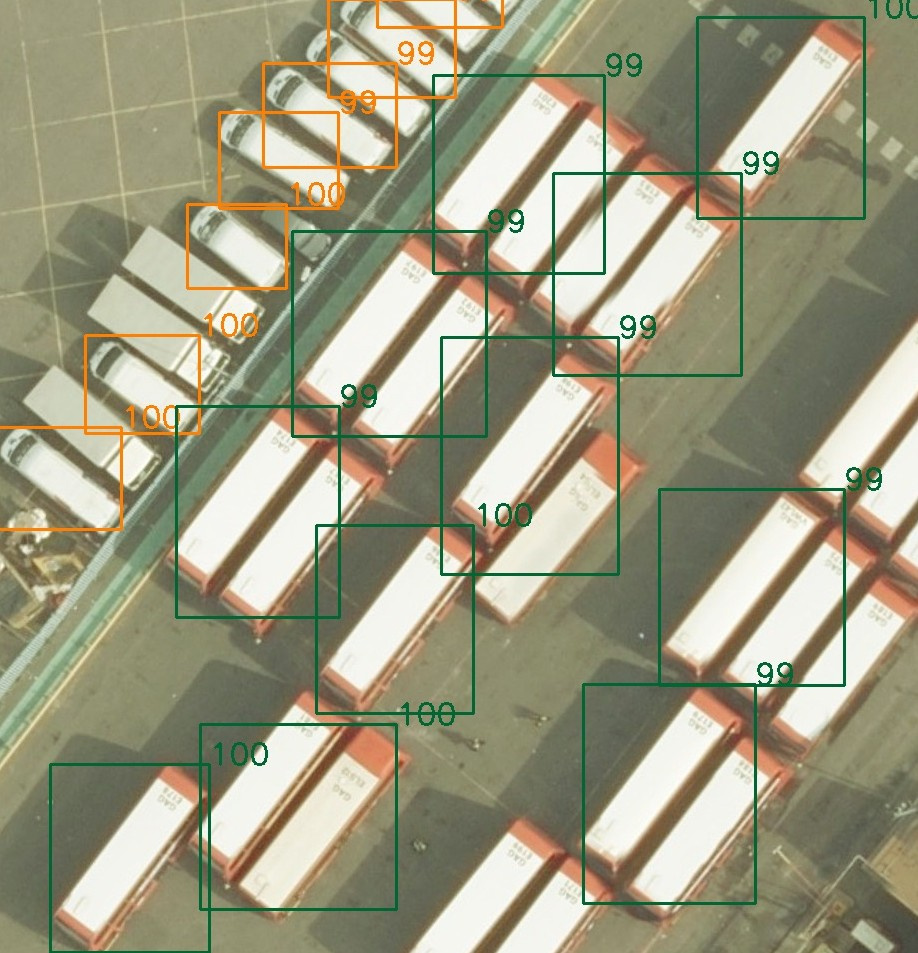
Что, собственно, требуется? Надо создать алгоритм, который будет брать спутниковые снимки, неизвестного города в Великобритании и на них находить мотоциклы, машины и автобусы определенного вида. По тени от колеса обозрения было сделано предположение, что этот неизвестный город — Лондон.
В задаче, про
спутники, про которую рассказывалось в первой части, с данными все было сложно:
1. Снимки представлены в куче различных спектральных диапазонов, разрешениях, каналы сдвинуты как во времени, так и в пространстве.
2. Данных мало. Train, public test и private test соответствуют различным распределениям.
3. Классы сильно разбалансированы. Например, в train set одному пикселю класса машинок соответствовало 60000 пикселей класса ферм. Собственно, в нашем с Серегой решении мы полностью положили болт на машинки и не заморачивались c их нахождением в Нигерийских джунглях в которых все действо и происходило как раз из-за проблем с данными этого класса.
Там было увлекательно и очень интересно, но все умаялись. Задача была с исподвыподвертом и больше времени проводилось не над научными изысканиями, а над борьбой с инженерной мутью, часть из которой была обусловлена спецификой данных, а часть нездоровым креативом со стороны организаторов.
В этой же задаче все было наоборот:
1. Данные представлены в обычном RGB, сделаны с одной высоты, и чуть не в одно время.
2. Train и test представлены 1200 картинками (600 и 600), каждая размером 2000x2000, в разрешении 5 см / pixel. То есть достаточно для решения задачи, но при этом не требует кластера из GPU и нескольких недель обучения.
В стандартных benchmark-датасетах, отмаркированных под Object Detection, на которых ученые мужи занимаютcя выяснением, чей алгоритм лучше, объекты отмечены через bounding boxes (боксы), то есть каждому объекту из train соответствуют координаты прямоугольника и метка класса, а модель, в свою очередь, предсказывает координаты прямоугольников, метку класса и то, насколько модель уверена в предсказании.
Проблема в подготовке таких датасетов в том, что эти прямоугольники достаточно долго обводить, а датасеты нужны большие, так что даже если нанять маркировщиков задешево, получится долго и дорого. Альтернативный вариант — это так называемое weak labeling, где вместо бокса ставится точка в центр объекта.
Британцы пошли именно по альтернативному пути, и маркировали точками, причем, в отличие от стандартного подхода, в котором есть объект — есть метка, они добавили воображения и проводили маркировку в режиме — вот этот объект алгоритмы участников, наверно, найдут — мы его отметим, а вот тут машина наполовину скрыта кроной дерева, так что мы ее отмечать не будем. Так делать не надо, сильно затрудняет тренировку моделей. Но спишем эти перекосы на их неопытность.
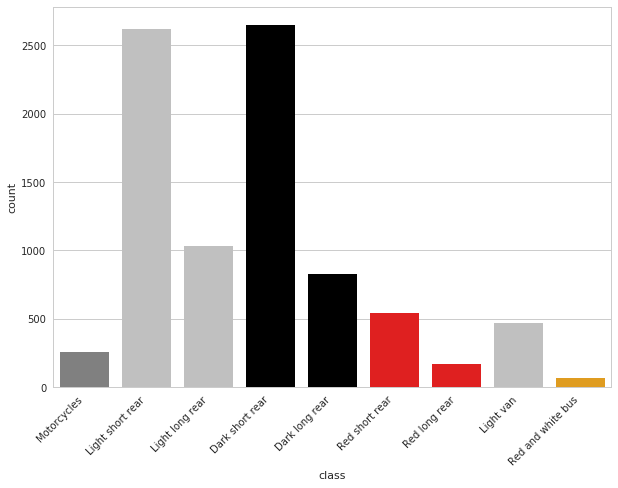
Классов было 9, а именно:
- A — любые мотоциклы и скутеры
- B — короткие светлые машины
- C — длинные светлые машины
- D — короткие темные машины
- E — длинные темные машины
- F — короткие красные машины
- G — длинные красные машины
- H — белые фургоны
- I — красно-белые автобусы

То есть мало найти машинку, надо еще правильно классифицировать, плюс, искать надо не всё. Синие, зеленые, желтые транспортные средства и прочее британцев не интересовали.
Классы несбалансированы, но наименее представленные классы, то есть мотоциклы, автобусы и красные машинки обладали ярко выраженными признаками, так что сеть это не сильно напрягало.
(Картинку предоставил Владислав Кассым)
Метрика
В качестве оценки точности модели использовался jaccard similarity, где True Positive засчитывался, если предсказанная точка рядом с британской меткой, а так как размеры объектов различались, то и расстояние зависело от класса.
Что мы имеем? Задача, которая с одной стороны — стандартная, а с другой — черт его знает, как к ней подступиться. Как вариант, можно попытаться выехать на плечах коллектива, все-таки ребята, которые подобрались в слаке Open Data Science, обладают зашкаливающе высокой квалификаций в машинном обучении. Но факт, что организаторы считают граждан России, Украины и Беларуси людьми второго сорта и что параллельно идет море других задач, где и дискриминации в правилах нет, и денежные призы посимпатичнее, не добавляло мотивации начать работать над задачей. Кроме того, интенсивная рубка, которая шла в задаче про спутники, привела к тому, что многие выгорели, взяли перерыв от соревнований и занялись тем, что важнее, то есть спортом и личной жизнью.
Коллективом решать задачи интереснее и эффективнее, поэтому стояла задача разобраться самому и подбить остальных на участие. Времени оставалось мало, что-то в районе месяца.
Окунувшись в литературу по Object Detection стало понятно, что статей про детекцию через боксы много, а через точки в центрах масс — мало. Ну и реализаций кода, которые выкладывают авторы для случая с боксами под каждый фреймворк тоже хватает, а под точки при беглом просмотре я ничего не нашел.
Как следствие, первый шаг, который был сделан — сведение неизвестной задачи к стандартной, а именно, я угробил пару дней на работе и обвел все боксы в train. Использовал я для этого
sloth, хотя позже, уже после того, как все разметил, догадался спросить, и коллектив подсказал, что существуют альтернативные инструменты, и для других задач, которые были после, я использовал
labelimg.
На разметку ушло порядка десяти часов, что, в принципе, немало, но эта инвестиция в дальнейшем помогла легко уйти в топ, да и вообще, занять призовое место. Дополнительной маркировкой решились сразу две задачи, во-первых, стало понятно на чем именно сфокусироваться в литературе и какой чужой код перебивать под эту задачу, а во-вторых, что не менее важно, сразу добавило мотивации ребятам в чатике, чтобы присоединиться к работе над задачей. Много народу не подключилось, потому что, как я упомянул выше, параллельно шли не менее интересные задачи про рак шейки матки и про подсчет морских котиков. Например,
Константин Лопухин сразу сказал, что на задачу про британские машинки времени мало, а вот на котиков самое оно и не прогадал, финишировав на той задаче вторым (
выступление в Yandex с его решением). Желание набить руку на задаче детектирования британских машинок изъявили
Сергей Мушинский и
Владислав Кассым. Собственно, все трое и закончили в топ-10.
Итак, месяц до конца, обведены боксы, с этим надо что-то делать. Существуют две основные вариации на архитектуры сети для задачи детекции:
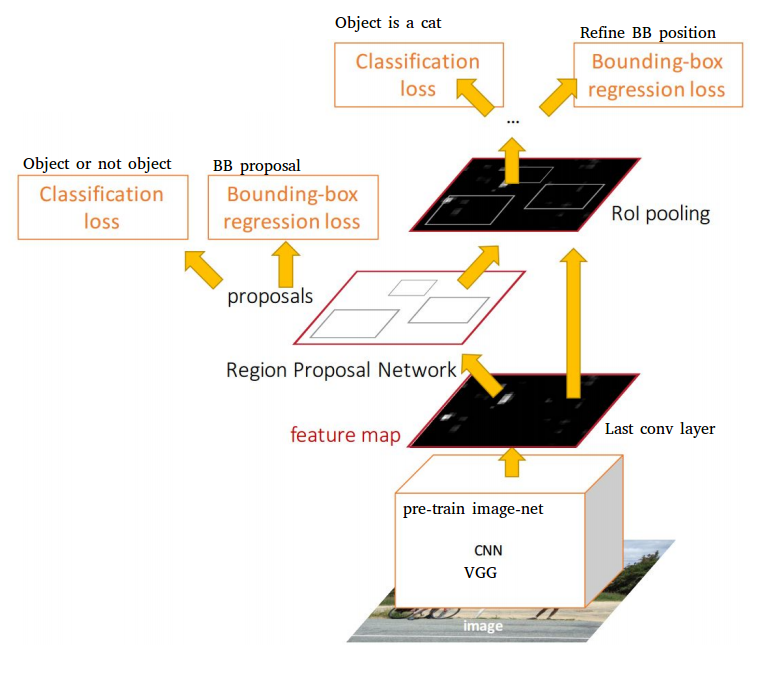
1. Семейство RCNN: Fast RCNN, Faster RNN — то есть сети, у которых pipeline можно разделить на две части: первая — найти области на картинке, которые соответствуют объектам, а вторая — провести классификацию для каждой области, чтобы определить какой именно объект там содержится.
2. Семество YOLO: YOLO, YOLO9000, SSD — в этих архитектурах поиск областей и классификация происходит в один заход.
Встает резонный вопрос, что лучше и когда. В каждой статье авторы утверждают, что вот именно они рвут конкурентов на британский флаг. Такой подход понятен, не будешь заниматься агрессивным академическим cherry picking, оверфитить на стандартные бенчмарки и трындеть про State Of The Art — не получишь грант, твои аспиранты не выпустятся и все прочие радости, которые мы сейчас имеем в академической среде. (На эту тему недавно была очень приятная статья в которой приводилась историческая справка о том, как мы дошли до такой жизни:
Is the staggeringly profitable business of scientific publishing bad for science?).
Но это проблемы академической среды и их локальные заморочки. Тут у нас есть четко поставленная задача, есть метрика, есть leaderboard, на котором участники показывают серьезные результаты, а у меня, кроме обведенных боксов, нет ни черта. При наличии большого количества времени и вычислительных ресурсов, можно было бы прогнать все архитектуры через наши данные и посмотреть на то, что получилось, но ни времени, ни желания этого делать конечно не было. Но! Вопрос о том, когда и какие сети хороши, терзал не меня одного. Пару лет назад Object Detection занимались исключительно ученые, но к бизнесу, несмотря на мощь подхода, это не имело отношения. Все упиралось в то, что в отличие от задач классификации и сегментации, задачи детекции работали со скоростью эстонской черепахи, то есть ни о каком real time detection речи не было. Но это все было пару лет назад, то есть по меркам Deep Learning достаточно давно. С тех пор сделано много улучшений и сейчас компании активно применяют Object Detection для зарабатывания своих триллиардов.
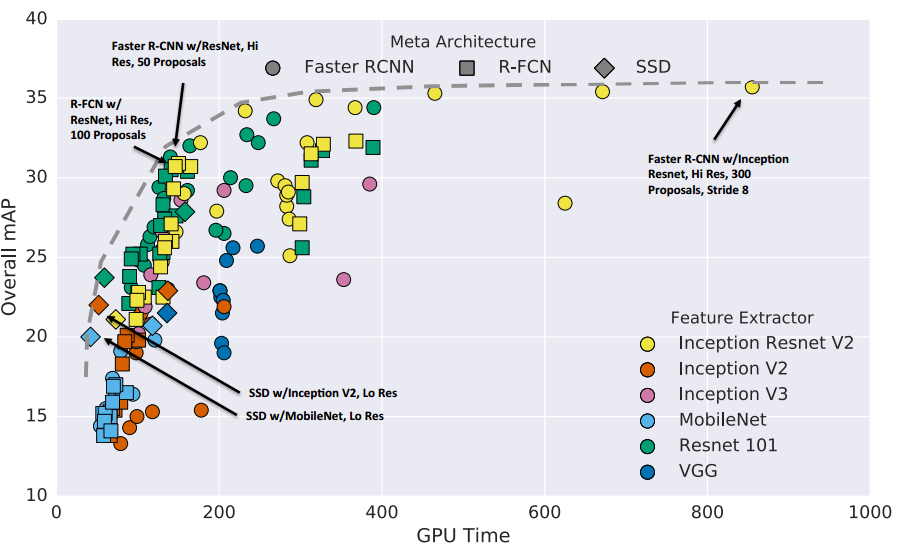
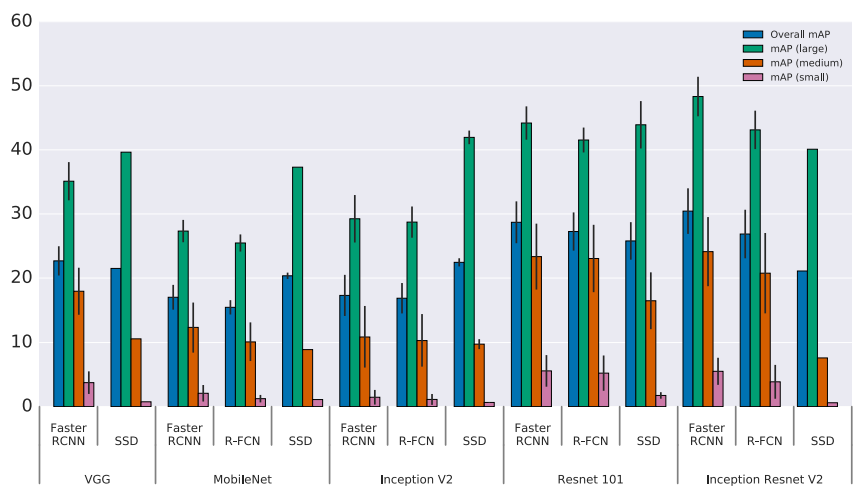
Так вот, в свое время ученые мужи, которые работают в Google воспользовались тем, что с вычислительными ресурсами у них все нормально и написали
обзорную статью в 11 авторов в которой с одной стороны ни одной новой идеи, а с другой она обладает огромной ценностью, во всяком случае среди меня. В этой статье авторы прогнали Faster RCNN и SSD с различными base feature extractions и провели анализ результатов по скорости и точности.
В статье говорится о том, что Faster RCNN поточнее, особенно на небольших объектах, а SSD предсказывает пошустрее. Причем разница по скорости предсказаний между ними, на мой взгляд, проходит как раз между „нельзя пихать в production“ и „можно пихать в production“. С дивана я не очень представляю под какие задачи можно пихать Faster RCNN в прод, но с удовольствием послушаю про success story в комментариях.
Этой статье я поверил на слово, не потому что я люблю верить на слово и не потому что Google при написании статей больше печется о своем имени и, как следствие, больше говорит по делу, а просто потому что выбора большого не было. Времени до конца соревнования оставалось совсем немного.
По указанной выше причине, а именно — большая точность при детекции мелких объектов, мотоциклы на картинках были крайне небольшого размера, выбор пал на Faster RCNN.
Круто. Я обчитался литературы, что-то начало проясняться, но чтения было мало. От того, что в голове стали прорисовываться какие-то контуры и мозаика начала постепенно складываться в большую картину, на лидерборде ты не появишься. Надо писать код. Нет кода — нет разговора.
Детекция — это не классификация, с нуля писать тяжело, куча нюансов, море мистических параметров, которые авторы подбирали месяцами, так что обычно берется чужой код и адаптируется под свои данные. Существует много различных фреймворков для работы с нейронными сетями, у каждого свои плюсы и минусы. В начале работы над этой задачей наиболее комфортно я себя чувствовал с Keras, на котором мы с Серегой и затащили предыдущее соревнование. Сказано — сделано, берется
реализация Faster RCNN на Keras и перебивается под наши данные. Запускается тренировка, что-то сходится, но это таааааак медленно. Как-то привыкаешь, что в других задачах через сеть летят десятки картинок в секунду, но тут все совсем не так. Сказывается и то, что Faster RCNN медленный и то, что Tensorflow не зашкаливает по производительности, плюс overhead, который идет от Keras, как от wrapper'a.
Что-то куда-то потренировалось, сошлось, предсказание, лидерборд и я десятый c результатом 0.49. То, что я в десятке — это хорошо, а вот то, что у ребят в первой тройке 0.8+, то есть разрыв достаточно большой — это не очень.
Keras — это хорошо и приятно, чистый код, понятная кодовая база, но он медленный и data parallelization осуществляется с большей болью, чем хочется. Всю зиму я работал над прошлой задачей, используя один GPU, а уже ближе к концу докупил второй. Два GPU — это очень удобно, как минимум, это позволяет проверять две идеи одновременно, да и если идей нет, не обязательно железу простаивать — на этих GPU всегда можно майнить криптовалюты, чем, скорее всего, и занимаются многие, кто решает задачки на Deep Learning, в свободное от тренировки моделей время.
В данном же случае идея одна — натренировать Faster RCNN. Тренируется сеть медленно, у меня два GPU, реализация на Keras небыстрая и мудреная, параллелить можно, но с болезненно. Сейчас ведется много работы над тем, чтобы можно было делать Data Parallelization на несколько GPU мизинцем левой ноги. Как я понимаю, на данный момент с этой задачей успешно справились разработчики mxnet и pytorch.
В этой задаче карты легли так, что выбор пал на mxnet. Он действительно быстрый сам по себе, он действительно легко параллелится мизинцем левой ноги. Это были плюсы, из минусов — такое ощущение, что его писали инопланетяне. Наверно, сказывается то, что и сам mxnet и реализация Faster RCNN для меня были в диковинку, но тем не менее, проблемы с тем, что делаешь шаг в сторону — сразу темный лес, документации не хватает, не покидали с начала и до конца. Спасло то, что Сергей и Владислав занимались ровно тем же самым и через дебри mxnet я продирался в составе группы, а не один.
На этом техническую часть можно было бы и закончить. По сути, применение реализации Faster RCNN на mxnet моментально вывело в регион 0.8+. Тренировка производилась на crops размером 1000x1000, которые аугментировались поворотами на углы кратные 90 градусам + отражения (преобразования из D4 group). При предсказании, исходные картинки 2000x2000 резались на пересекающиеся куски размером 1000x1000. После этого применялся Non Maximum Supression для борьбы с эффектом, когда один и тот же бокс предсказан в различных тайлах. После этого у каждого бокса находился центр масс и это и шло в итоговое предсказание.
В определенный момент, несмотря на то, что везде в литературе утверждается, что Resnet 152 как feature extractor работает лучше, чем VGG 16, выяснилось, что общепринятая точка зрения на этой задаче не работает. Кто-то, на дурака, попробовал использовать VGG 16 и это заметно улучшило результат. Позже, в другом разговоре,
bobutis, который в составле команды выиграл задачи
по классификации рыбок и
рака шейки матки, используя Faster RCNN, подтвердил, что на практике, VGG как feature extractor работает лучше.
В этой задаче были такие чистые данные и их количество было подобрано так хорошо, что сеть работала за гранью моих ожиданий. Особенно радовали случаи, когда из-под дерева или из-под моста торчали одни фары.
Где у сети были проблемы? Как и ожидалось, плотно упакованные объекты предсказывались плохо. На эту тему тоже много литературы, но в целом, детекция плотно упакованных объектов — это другая задача.
На
задаче про подсчет морских котиков подход через детекцию не зашел, как раз именно из-за плотной упаковки и народ решал через сегментацию, сопоставляя каждому котику гауссиану и сегментируя получившийся heatmap.
Иногда, но крайне редко, сеть пыталась выдать всякий хлам за интересующие нас объекты.
При этом, точность моей модели jaccard = 0.85, у
ironabar, который на первом месте 0.87, но никак не 0.98-0.99. Навскидку, мы ошиблись примерно с 1200 машинками — а это очень много, особенно учитывая, что у меня сложилось стойкое впечатление, что на этой задаче и на этих данных сеть работает точнее, чем ручная разметка (первый раз с таким сталкиваюсь на практике).
Я думаю, что получилось вот что:
1. Многие классы тяжело отличать визуально, серая машина в тени может выглядеть как темная, а на солнце — как светлая. Синие и синеватые машинки тоже, совершенно запросто, могли упасть не в тот класс. И это сказывалось и при тренировке, и при предсказании.
2. Организаторы определили классы в достаточно странной манере — не, скажем, белый седан или хэтчбек, а белая длинная или короткая машина. При визуальной оценке, даже если отложить вопрос цвета в сторону, много пограничных случаев, которые не очевидно, к какому классу относить. Даже белые фургоны не всегда можно отличить от коротких белых машин.
3. Кабриолеты, несмотря на то, что сверху выглядят темными относятся к тому классу, которому соответствует основная расцветка, то есть, что бы сказал прохожий, если бы его спросили цвет машины. Это не проблема если бы таких кабриолетов в train было много, но число кабриолетов в Лондоне, скажем прямо, не зашкаливает.
4. Организаторы проявили креатив и решили упростить задачу для участников, то есть разбили случаи на простые и сложные, и ввели для этого какие-то свои внутренние правила, то есть если машина на краю и часть багажника выходит за край картинки они ее не учитывали ни в train, ни в test, что-то похожее можно сказать и про машины, которые наполовину скрыты деревьями. Как следствие, это добавило шума разметке, то есть сеть при тренировке щелкало за False Positive не по делу, уменьшая ее предсказательную силу и какие-то предсказанные машинки классифицировались как False Positive при вычислении jaccard на сайте соревнования.
Середина мая. Соревнование закончилось, на Public LB я третий, на Private — второй, организаторы пишут письмо в котором просят предоставить:
Please send the following information to general@datasciencechallenge.org:
Full name
Nationality
Telephone contact details
Whether you would be happy to provide an interview for the winner announcements
Passport details (scan/photo of details page with photo)
Proof of address (eg. scan/photo of a utility bill)
Bank account details (IBAN, Account Number and Sort Code)
В правилах написано, что если ты гражданин России — то денег дадут. Но уточнить с меня не убудет, я написал письмо, в котором английским по белому написал, что я гражданин России, живу в Сан Франциско, США, банк у меня американский и задаю логичный вопрос: „Призовые платить будем“? В ответ получаю email, который сводится к ожидаемому: „Нет, призовых не будет, ибо, несмотря на результат, по правилам, цветом паспорта ты не вышел“.
...I'm sorry to say that due to your Russian citizenship you do not meet Clause 2.3b because Russia has a score below 37. As a result the company running the challenges is unable to award you any prize money as you do not meet the criteria that they need to follow due to their legal obligations in the UK.
…
Ответ был ожидаемым, так что обидно не было. Но! Сам факт наличия всех этих ограничений по месту жительства и по гражданству выбешивал с самого начала. Понятно, что в этом соревновании так уж получилось, но раз уж они позиционируют себя как очередную копию Kaggle, то очень бы хотелось щелкнуть по носу, чтобы увеличить шансы на то, что в будущем они будут думать, прежде чем запускать соревнования с нездоровыми правилами. Как щелкнуть — непонятно. Я написал что-то у них на форуме, добавил пару строчек к
блог-посту на Kaggle про спутниковые снимки, хоть этот блог никто и не читает, но так, для очистки совести. Написал свой первый и единственный
пост в twitter и
гневный пост на facebook. Каюсь. Еще когда писал, я осознавал, что те, кто не в курсе деталей будут воспринимать текст как: „Подлые британцы в последний момент поменяли правила и кинули меня на деньги“.
Также я скинул ссылку на пост на facebook и twitter в слак ODS. На этом долг перед мировым научным сообществом был закончен, ибо непонятно, что еще сделать, чтобы уж точно по носу щелкнуть, и с этими мыслями я пошел спать. Скажем честно, cилу ODS я недооценил, кто-то репостнул, кто-то лайкнул, слово за слово, на следующий день эта история появилась где-то в телеграмме, на каких то мелких новостных сайтах, а потом все это окончательно вышло из под контроля.
Я уже не помню хронологию событий, помню лишь, как в определенный момент я сижу на работе, и, вместо тренировки очередной модели, читаю канал #_random_flood и это воспринимается как фронтовые сводки.
Народ мониторил различные средства массовой информации и скидывал, что и где в новостях пролетело.
Со мной пытались связаться:
1. Russia Today — я отказался давать интервью на камеру, но ответил на пару вопросов по email. И этого им хватило на
заметку.
2. Первый канал — атаковали всех моих русскоговорящих знакомых на Facebook и VK с просьбой помочь связаться со мной.
3. Пятый канал — пытались связаться со мной, не получилось; пытались связаться с моими родителями, не получилось; поехали в школу и взяли интервью у учителей. Я сильно надеюсь, что учителя не прощелкали клювами и выбили под это доп. финансирование.
4. Рен ТВ — хотели что-то из серии их стандартных программ про инопланетян и прочую экзотику, а именно, чтобы я стал центральным персонажем выпуска передачи „Осторожно: русские!“.
5. Комсомольская правда — выпустили не только электронную, но и бумажную версию.
6. Я попал на главную
lenta.ru. Ненадолго, но тем не менее.
7. Какие-то совсем неизвестные мне каналы вроде „Царьград ТВ“ тоже попытались общаться, но они все пропадали в лавине всех, кто пытался со мной связаться.
Я сам не смотрел, но народ рассказывал, что тот факт, что я отказался работать на камеру не остановил телевизионщиков. Они все равно выпустили сюжеты, добавив мое фото в фон. Ну и, как водится, пригласили каких-то непонятных персонажей высказать их экспертную оценку на происходящее.
Общаться со всеми этими людьми большого желания не было. Цель моего поста на Facebook щелкнуть британцев, чтобы у них мозги пошустрее зашевелились и чтобы в будущем они создавали меньше дискриминационных соревнований, а не стать центральным персонажем новостных сюжетов вида: „Скандалы. Интриги. Расследования“. Я никогда не работал на камеру, плюс, у меня есть грешок — говорить то, что думаю, а на камеру так делать, наверное, не стоит. Да и то, что я скажу и то, что может получиться после монтажа — это две большие разницы, так что несмотря на свойственный мне природный авантюризм, вписываться в это я не стал.
На фоне всего этого, я не побоюсь слова, стада, очень приятно выделился Mail.Ru Group. Они мне прямым текстом написали: „Мы готовы выплатить деньги вместо британцев. Как с вами связаться?“. Как я уже писал, я не рассчитывал получить денег с этого соревнования, но сам подход мне понравился. Понятно, что для них это PR, причем достаточно дешевый, но при этом, на мой взгляд, это красивый ход. Этим подходом они высказали свое уважение, что очень хорошо смотрелось на контрасте со всеми остальными, для которых „дать нам интервью — большая честь“. Мы пообщались. Текст press release у них был готов и в течение 30 секунд после того, как я дал добро, он был опубликован. Аккуратно, без истерик, без „наших бьют“, все по делу, как и положено серьезной компании.
Разведка донесла, что в самом Mail.Ru Group это решение было встречено неоднозначно, что, в общем, ожидаемо. По факту мы имеем:
1. Какой то левый парень, который в Mail.Ru Group не работает.
2. В России не живет.
3. Участвовал в соревновании, которое проводила британская разведка.
4. По правилам денег получить не должен.
5. Вместо того, чтобы потратить эти деньги и послать работников, которые пашут как негры на плантациях с утра до вечера, на какую-нибудь конференцию, этому левому перцу выделяются несколько месячных зарплат типичного Data Scientist'a.
Логика безусловно есть. И перед ребятами, которых все это огорчило я извиняюсь. В свое оправдание хочу сказать, что за выделение денег на конференции и на PR, отвечают различные департаменты и, что все-таки для здорового PR, деньги небольшие, так что и на конференции должно остаться.
Деньги выделили, это приятно. Но брать их нельзя, они токсичные. Хотя опять же, скажем честно, если бы речь шла не о 12 тысячах фунтов, а о 120, я бы, наверное, взял. Или нет? Черт его знает. Но 1,200,000 точно бы взял.
С деньгами надо было что-то делать. Кто-то в канале #_random_flood предложил их пожертвовать. Эта идея мне понравилась. Очень сильно напрягает отсутствие финансирования в фундаментальной науке. С одной стороны, это логично, ведь по большому счету людям платят за сам факт своего существования, надеясь, что в один прекрасный момент будет какой-то прорыв, что-то большое. И примеров таких прорывов в истории более, чем достаточно, но финансирование, что в России, что за рубежом фундаментальной науки, прямо скажем, не фонтан. Так и созрела идея пожертвовать эти деньги на российскую науку. Куда жертвовать? Черт его знает. Я, когда в России учился, на гранты не подавал, да и давно это было, все десять раз поменялось. Кто больше поддерживает? Кто меньше пилит? Не знаю. Погуглил какие-то фонды, выбрал на дурака РФФИ. Попытки с ними связаться не увенчались успехом. Может у них и правда с деньгами все нормально и пожертвований они не принимают. А вот Российский Научный Фонд согласился деньги взять, правда уточнил, кто был организатором соревнований. Как ни странно, ответ “британская разведка” их вполне устроил.
Как только по новостям прошло, что я жертвую призовые двенадцать тысяч фунтов на науку, народ одобрил, но не все. Например, сестра, которая тоже физик, правда экспериментатор и у которой финансирование зависит от грантов, написала мне гневное письмо о том, что я все сделал не так и что все распилят и вообще, что она в гневе.
Вообще вся эта история прошла на грани фола. Меня прокатили по новостям как обиженного русского гения, а могли точно так же прокатить как предателя родины. Живет за границей, разрабатывал алгоритмы на данных британской разведки — этого уже за глаза. При желании много можно было бы на эту тему накрутить и то, что это было открытое международное соревнование никого бы уже не волновало.
Перевели ли деньги? Насколько я знаю да. Это заняло больше месяца, но недавно мне пришло подтверждение, что деньги уже в фонде. Опять же, хочется надеяться, что хоть что-то из них дойдет до самих двигателей науки.
Приходили сообщения от тех, кто негативно отнесся к тому, что я живу и работаю за рубежём. Я эти сообщения игнорировал, но пусть будет, отвечу им тут и отвечу я вот так: после дембеля, когда я пришел в военкомат, военком выдал мне удостоверение ветерана боевых действий, медаль за воинскую доблесть, пожал руку и сказал, что Родина мной гордится. Даже если это и не так, с того момента я считаю, что все долги за два года срочной службы я отдал. И на этом вопрос с тем, кто, кому и что должен, считаю закрытым. Другой вопрос, почему двигать науку за границей зачастую проще, чем в России, но это отдельная проблема и детальный анализ, наверное, надо делать в другом посте и будем надеяться, до этого руки у меня дойдут.
Из забавного. Достаточно много девушек захотели добавиться в друзья на facebook или VK. Многие — очень симпатичные. Но при этом просто приходило извещение, о том, что кто-то захотел добавиться, без сообщения. Так скучно. А вот если бы какая-нибудь девушка написала вариацию на тему: „Владимир, вам, наверное, сейчас тяжело, такой стресс, приходите в гости на бокал вина, я и подружку приглашу“ — это было бы любопытнее, и, как минимум, я бы это интерпретировал, что девушка уверена в себе, умеет добиваться чего хочет, в общем не такая как все в хорошем смысле этого слова. Но максимум, что было: „Вы выглядите “cлегка» нетипично для программиста". Как-то даже без огонька.
На этой ноте данный пост можно и закончить, но есть еще пара событий, которые хочется добавить. Один парень, который живет в Лондоне и который сам испытал британский национализм на своей шкуре, связал меня с журналистом, который работает в каком-то небольшом британском новостном издании и пообщавшись со мной, этот журналист выпустил про эти события
заметку у себя на сайте.
Организаторы соревнований, несмотря на то, что приз платить не собирались попросили за свой счет поднять на амазоне EC2 instance, воспроизвести решение, написать документацию и сделать презентацию, и за это они обещали у себя на сайте упомянуть мое имя. Я вежливо отказался. Но во время обмена email'ами на эту тему, выяснилось, что журналисты, что наши, что британец, пытались с DSTL связаться и задавали вопросы, на которые у тех не было красивых ответов. Я не знаю, удался ли антидискриминационный щелчок по носу или нет, но хочется надеяться, что да.
Ближе к середине июня они написали email и сказали, что несмотря ни на что, мое второе место у меня никто не отнимает, и попросили мое фото.
Меня очень сильно подмывало отправить фото с медвежонком со словами: «А в свободное от машинного обучения время, я выращиваю медведя, будете еще раз дискриминировать — он вас съест».
Фото с мишкой я им отправил, правда формулировку смягчил и убрал из нее эмоции. В итоговом
press release они меня упоминули, но косолапого показывать почему-то не стали.
Параллельно со всей этой историей на Kaggle стартовало
соревнование с призом в $1,200,000 где по каким то соображениям обрезали китайцев, коллектив не одобрил, правила поменяли, и все вроде нормально.
Примерно месяц назад стартовало еще
одно соревнование на Kaggle и тоже дискриминационное. Приз $1,500,000, но претендовать на него могут только граждане США и обладатели Green Card, то есть на этот раз за бортом остались не только Китай и Россия, а Евросоюз, Великобритания, Канада, Австралия, Израиль и все остальные, кого за бортом США обычно не оставляет. Серега на эту тему написал
гневный текст на форуме, и судя по числу upvotes, коллектив с ним в большинстве своем солидарен. Я тоже отметился и тут же со мной связался какой-то американский журналист и даже опубликовал
текст на эту тему.
Когда я связался с администратором этого нового соревнования и вежливо уточнил: «Как так получилось? Вы же всегда были за меритократию”. Он что-то витиевато ответил, но по сути ответ свелся к двум словам: „Мы продались“.
В этом соревновании я планирую участвовать. Заканчивается оно через несколько месяцев, поглядим как оно пойдет. Задача достаточно злая, но если что-то склеится, не исключено, что будет вторая часть Марлезонского балета. В конце концов, когда ты топишь против дискриминации, из призовых мест тебя слышат лучше, чем когда у тебя ни черта на задаче не получилось.
А что по знаниям? Знаний в Deep Learning в различных областях у меня сейчас много, как минимум их хватило вот на такую историю:
В начале мая, через Kaggle со мной связался рекрутер Tesla, который искал специалистов на позицию AI Researcher. Я согласился проинтервьюироваться на эту вакансию. Лихо прошел take home test, оба tech screen, onsite interview, хорошо пообщался с своим потенциальным непосредственным начальником Andrej Karpathy, оставалось пройти background check и чтобы Элон Маск одобрил мою заявку. И вот как раз на стадии background check я и срезался. Рекрутер сказал мне, что я нарушил Non Disclosure Agreement, и что где-то разболтал о процессе интервью, и что офера не будет. Это было неожиданно, но в более развернутом виде эту байку, я, наверное, расскажу, когда буду писать третью часть эпопеи про офисный планктон.
Отдельное спасибо Сергею Мушинскому и Владиславу Кассыму за помощь в работе над этой задачей, Сергею Белоусову, за то, что отвечал на мои глупые вопросы по Object Detection, без его помощи вряд ли я бы успел за месяц так хорошо разобраться в теме, а также Юлию Семенову за помощь в подготовке этого текста.