Зачем писать свой React Data Grid в 2019
- среда, 26 июня 2019 г. в 00:18:11
Привет, Хабр! Я участвую в разработке ECM системы. И в небольшом цикле статей хочу поделится нашим опытом и историей разработки своего React Data Grid (далее просто грид), а именно:
У нашей системы есть веб-приложение, в котором пользователи работают со списками документов, результатами поисков, справочниками. Причем, списки могут быть как маленькие (10 сотрудников), так и очень большие (50 000 контрагентов). Для отображения этих списков мы разработали свой грид:
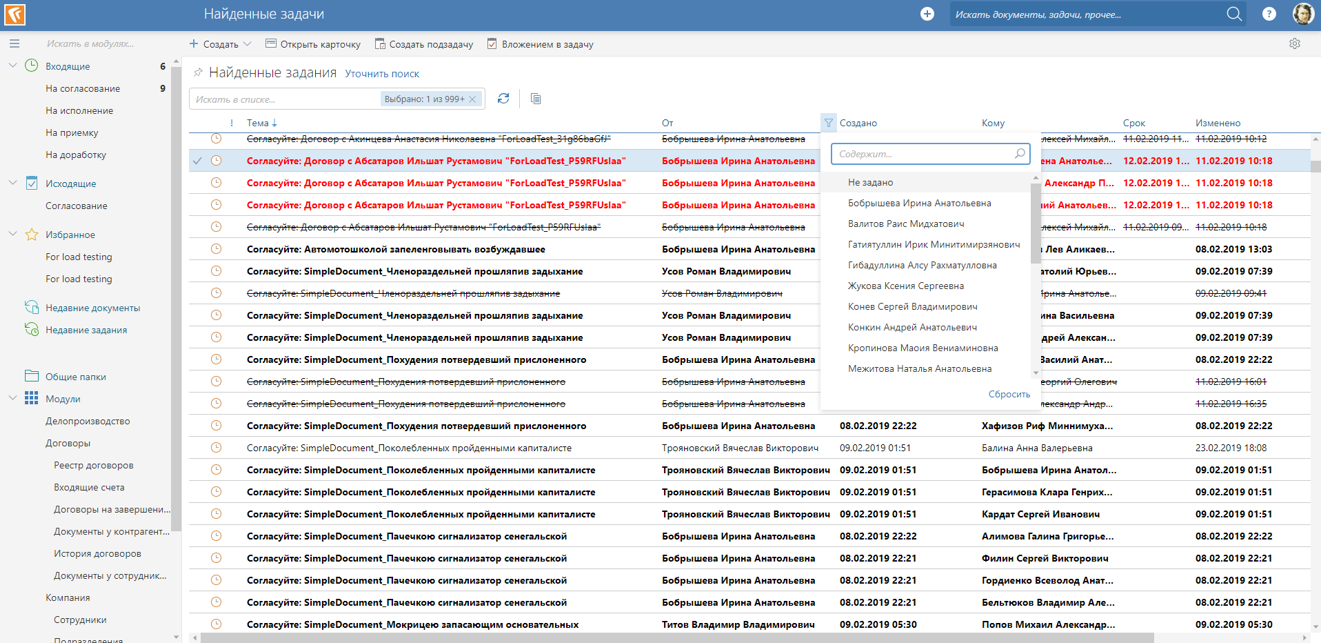
Когда мы только приступили к разработке веб-приложения, захотелось найти готовую библиотеку для отображения грида, которая умеет делать все, что нам надо: сортировать и группировать записи, перетаскивать и растягивать колонки, работать с множественным выделением, фильтровать и подсчитывать итоги по колонкам, порционно загружать данные с сервера и отображать десятки тысяч записей.
Поясню последнее требование «отображать десятки тысяч записей». В гридах это требование реализуется несколькими способами: paging, infinity scrolling, virtual scrolling.
Подходы paging и infinity scrolling распространены на веб сайтах, вы ими пользуетесь каждый день. Например, paging в Гугле:

Или infinity scrolling в том же Гугле по картинкам, где следующая порция картинок загружается, когда пролистаешь до конца первую порцию:

А вот virtual scrolling (далее буду называть виртуальный скроллинг) используется в вебе редко, его основное отличие от infinity scrolling — это возможность быстро проскролить в любое место очень больших списков. При этом будут загружены и отображены только видимые пользователю данные.
Для нашего веб-приложения хотелось использовать виртуальный скроллинг. Соглашусь, что скроллинг в любое место списка из 10.000 записей — кейс скорее выдуманный. Однако, произвольный скроллинг в пределах 500–1000 записей — кейс живой.
Когда реализуют виртуальный скроллинг, часто реализуют и программное API управления этим скроллингом. Это очень важная фича. Программный скроллинг используют, например, для позиционирования выделенной записи по середине экрана при открытии справочника:
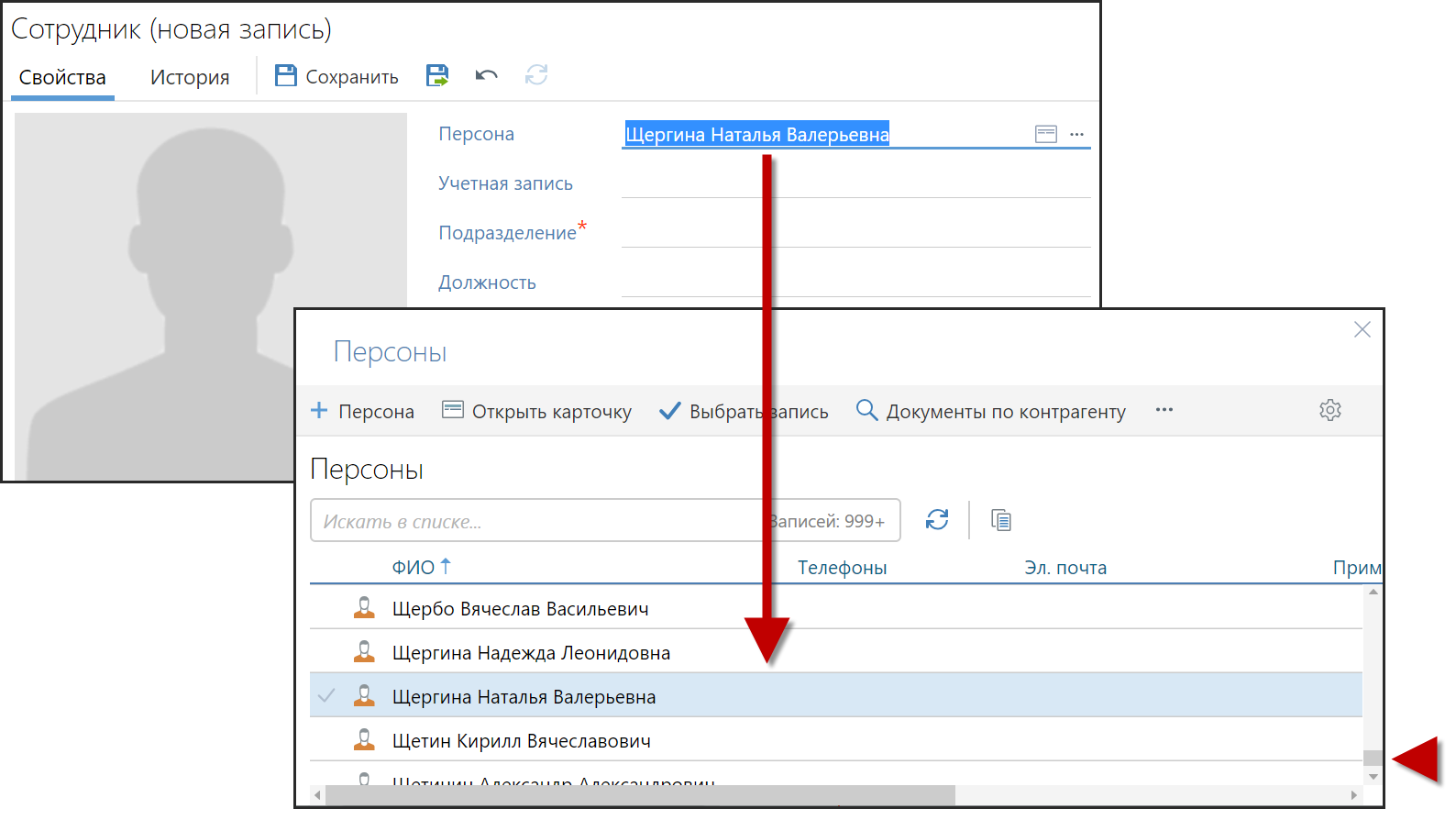
Вернемся к требованиям. Что еще нам было нужно:
В общем, требований было много.
Не долго исследуя существующие библиотеки, мы наткнулись на DevExtreme JavaScript Data Grid. По функциональным требованиям этот грид закрывал все наши потребности и имел очень презентабельный внешний вид. Однако по технологическим требованиям не подходил (не react, не redux, не flexbox). На тот момент у DevExtreme не было react грида.
Ну и пусть не react, решили мы, за то грид красивый и функциональный, будем использовать его. И добавили библиотеку себе в проект. Оказалось, мы добавили 3 Мб скриптов.
За пару недель мы интегрировали грид в наше веб-приложение и подняли основной функционал:
По ходу прикручивания грида выяснились две серьезные проблемы и целый ворох менее серьезных.
Подружить DevExtreme JavaScript Data Grid с redux очень сложно. У нас получилось управлять настройками колонок и выделением записей через redux, но хранить порционно загружаемые данные в redux, и выполнять над ними CRUD операции через redux — это нереально. Пришлось делать костыль, который в обход redux манипулировал данными грида. Костыль получился сложным и хрупким. Это был первый тревожный звоночек, что грид нам не подходит, но мы продолжили его вкручивать.
Нет API управления виртуальным скроллингом. От программного управления скроллингом мы не могли отказаться, пришлось перешерстить исходники DevExtreme и найти внутреннее API управления скроллингом. Конечно, у этого API была гора ограничений, ведь оно было рассчитано на внутреннее использование. В итоге мы добились, чтобы внутреннее API более-менее работало на наших кейсах, но, опять в обход redux, и опять куча костылей.
Менее серьезные проблемы всплывали постоянно, потому что стандартный функционал DevExtreme JavaScript Data Grid нам подходил не полностью, и мы пытались его корректировать:
Хотя DevExtreme грид по функциональности содержал все что нам надо, но почти весь стандартный функционал хотелось переписать. За время его использования были добавлены сотни строк сложного для понимания кода, который пытался решить проблемы взаимодействия с redux и react, было сложно использовать не react грид в react приложении.
Спустя некоторое время использования DevExtreme было решено отказаться от него. Выкинуть все хаки, сложный код, а также 3 Мб скриптов DevExtreme. И найти или написать новый грид.
На этот раз, мы внимательнее отнеслись к исследованию существующих гридов. Были изучены MS Fabric DetailsList, ReactVirtualized Grid, DevExtreme React Grid, Telerik Grid, KendoUI Grid.
Требования остались те же, но уже оформились в понятный нам список.
Требования к технологиям:
Требования к функционалу:
К этому моменту уже появился первая версия DevExtreme React Grid, но мы сразу же отбросили его по следующим причинам:
Анализ существующих решений показал, что «серебряной пули» нет. Грид, который закрыл бы все наши требования, не существует. Было решено писать свой грид, который по функциональности будем развивать в нужную нам сторону, и дружить с технологиями нужными нашему продукту.
Разработку грида начали с прототипов, где опробовали самые сложных для нас темы:
Самым сложным оказалась сделать виртуальный скроллинг. По-крупному, его делают одним из 3-х способов:
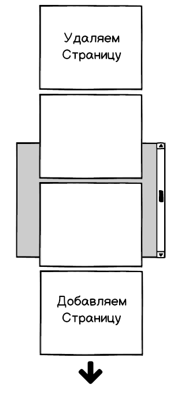
1. Постраничная виртуализация
Данные рисуются порциями — страницами. При скроллинге видимые страницы добавляются, невидимые удаляются. Страница состоит из 20-60 строк (обычно размер настраивается). Таким путем пошли продукты: DevExtreme JavaScript Data Grid, MS Fabric DetailsList.
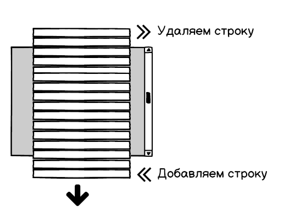
2. Построчная виртуализация
Рисуются только видимые строки. Как только строка уходит за экран, она сразу же удаляется. Этим путем пошли продукты: ReactVirtualized Grid, DevExtreme React Grid, Telerik Grid.
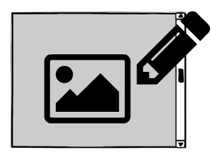
3. Canvas
Все строки и их содержимое рисуют с помощью Canvas. Так сделали в Google Docs.
При разработке грида мы сделали прототипы для всех трех вариантов виртуализации (даже для Canvas). И выбрали постраничную виртуализацию.
У построчной виртуализации были проблемы со скоростью отрисовки в прототипе. Как только усложнялось содержимое строк (много текста, подсветка, тримминг, иконки, большое число колонок, и везде flexbox), то дорого становилось добавлять/удалять строки по несколько раз за секунду. Конечно, результаты зависят и от браузера (мы делали поддержку в том числе для ie11, edge):

Вариант с Canvas был очень соблазнительный по скорости отрисовки, но трудоемкий. Предлагалось нарисовать все: текст, перенос текста, тримминг текста, подсветка, иконки, разделительные линии, выделение, отступы. Сделать реакцию на нажатие кнопок мышки на Canvas, подсветку строк при наведении курсора. При этом, поверх Canvas следовало наложить некоторые Dom-элементы (показ хинтов, «высплывающие действия» над строкой). Еще требовалось решить проблему размытости текста и иконок в Canvas. Все это долго делать и сложно. Хотя прототип мы осилили. При этом любая кастомизация строк и ячеек в будущем нам бы вылилась в большую трудоемкость.
У выбранной постраничной виртуализации были плюсы по сравнению с построчной, которые определили ее выбор:
Отдельный вопрос – это выбор размера страницы. Выше я писал, что размер настраивается и обычно составляет 20-60 строк. Большая страница долго рисуется, маленькая приводит к частому показу «белого экрана» при скроллинге. Экспериментальным путем был выбран размер страницы 25 строк. Однако для ie11 размер был уменьшен до 5 строк. По ощущениям, интерфейс в IE отзывчивее, если рисовать с небольшими задержками много мелких страниц, чем одну крупную с большой задержкой.
Постраничную виртуализацию нужно было реализовать с использованием react. Для этого следовало решить несколько задач:
Задача 1. Как добавлять/удалять страницы через react при скроллинге?
Для решения этой задачи ввели понятия:
Модель – это информация, по которой можно построить представление. Представление – это React-компонента.

По сути, задача виртуализации после этого сводилась к манипулированию моделями страниц: хранить список моделей страниц, добавлять и удалять модели при скроллинге. И уже по списку моделей через react строить/перестраивать отображение:

По ходу реализации сформировались правила работы с моделями страниц:
Задача 2. Как отобразить scollbar?
Виртуальный скроллинг предполагает, что доступен scrollbar, который учитывает размеры списка и позволяет выполнить скроллинг в любое место:

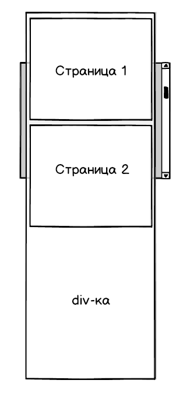
Как отобразить такой scollbar? Самое простое решение — вместо реальных данных рисуем невидимую div-ку нужного размера. И уже поверх этой div-ки отображаем видимые страницы:
Задача 3. Как следить за размером viewport?
Viewport – это видимая область данных грида. Зачем следить за ее размером? Чтобы вычислить число страниц, которые нужно отобразить пользователю. Предположим, у нас маленький размер страницы (5 строк) и большое разрешение экрана (1920x1080). Сколько страниц надо отобразить пользователю, чтоб закрыть весь viewport?
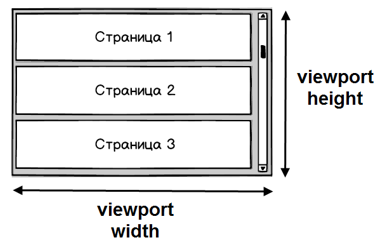
Решить эту задачу можно, если знать высоту viewport и высоту одной страницы. Теперь усложним задачу, предположим пользователь резко меняет масштаб в браузере – задает 50%:
Ситуация с масштабом показывает, что мало один раз узнать размер viewport, за размером надо следить. И теперь совсем усложним задачу: у html-элементов нет события resize, на которое можно подписаться и следить за размером. Resize есть только у объекта window.
Первое, что приходит в голову – использовать таймер и постоянно опрашивать высоту html-элемента. Но есть решение еще лучше, которое мы увидели у DevExtreme JavaScript Data Grid: создать невидимый iframe, растянуть его на размер грида и подписаться на событие resize у iframe.contentWindow:


P.S. Это еще не конец. В следующей статье я расскажу как мы подружили наш грид с redux.
Чтобы получить полноценный виртуальный скроллинг пришлось решить еще множество других задач. Но те, что описаны выше были самими интересными. Вот на вскидку еще несколько задач, которые тоже всплывали:
Если есть вопросы по реализации, можете писать их в комментариях.