https://habrahabr.ru/post/329782/Здравствуйте, в этой статье описан механизм работы Angular 2. Сегодня мы заглянем под капот популярного фреймворка.
Эта статья является вольным переводом доклада Тобиаса Боша (Tobias Bosch) — The Angular 2 Compiler. Ссылку на оригинал доклада Вы можете найти в конце статьи.
Овервью
Тобиас Бош – сотрудник компании Google и член рабочей группы разработчиков Angular, который создал большинство составляющих частей компилятора. Сегодня он рассказывает о том, как работает Angular изнутри. И это не что-то заоблачно сложное.
Надеюсь, что вы используете некоторые полученные знания в своих приложениях. Возможно, вы, как и наша команда, создадите свой собственный компилятор или небольшой фреймворк. Я расскажу о том, как работает компилятор и как мы достигли своей цели.
Что такое компилятор?
Это все, что происходит между входными данными приложения (ими могут быть ваши команды, шаблоны и т.д.) и вашим запущенным приложением.
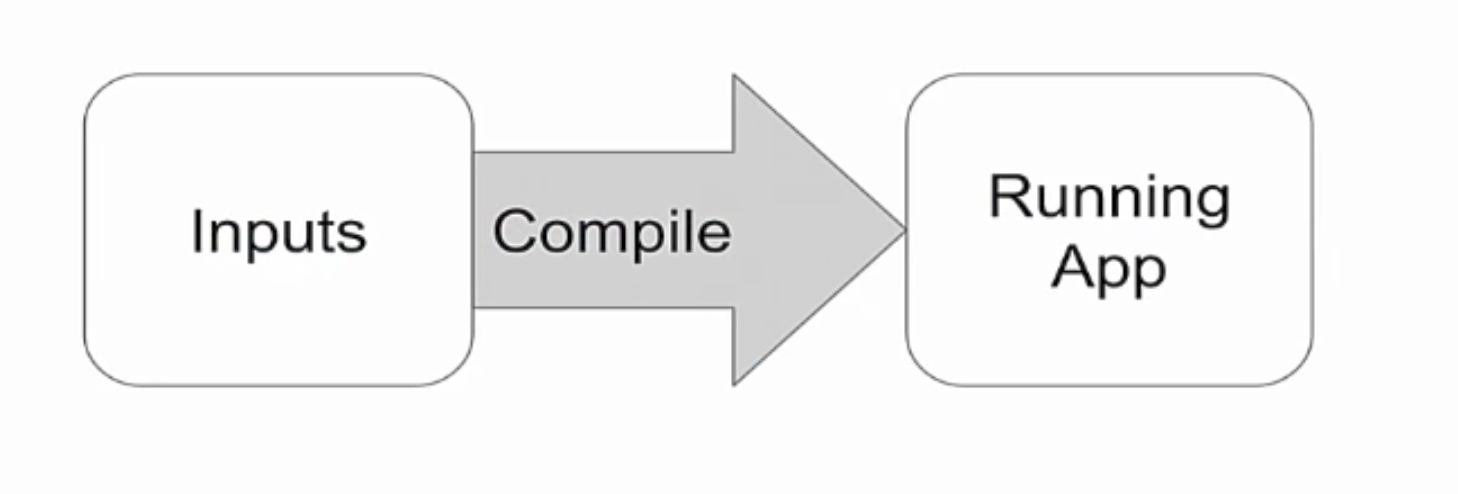
Все то, что происходит между ними – это сфера деятельности компилятора. С виду может показаться, что это чистой воды магия. Но это не так.
Что мы сегодня рассмотрим?

Сначала мы немного поговорим о производительности: что имеется в виду под быстрой работой? Мы поговорим о том, какие виды входных данных у нас есть.
Также мы поговорим о лексическом анализе, о том, что это такое, и что компилятор Angular 2 делает с анализом. Мы поговорим о том, как Angular 2 берет проанализированные данные и обрабатывает их. В целом, реализация этого процесса происходила у нас в три попытки, сначала была простая реализация, потом улучшенная и еще более улучшенная. Так сделали это Мы. Это те этапы, благодаря которым нам удалось достичь ускоренной работы нашего компилятора.
Также мы обсудим разные среды, достоинства и недостатки динамической (Just In Time) и статической (Ahead Of Time) компиляции.
Производительность: что означает быстрая работа?
Представим ситуацию: я написал приложение и утверждаю, что оно быстро работает. Что я имею в виду? Первое, что можно подумать, это то, что приложение очень быстро загружается. Возможно, вы видели AMP-страницы Google? Они загружаются нереально быстро. Это можно отнести к понятию «быстрый».
Возможно, я использую большое приложение. Я переключаюсь от одной рубрики к другой. Например, от краткого обзора к развернутой странице, и такой переход происходит очень шустро. Это тоже может характеризовать быстроту.
Или, скажем, у меня есть большая таблица и сейчас я просто изменю все ее значения. Я создаю новые значения без изменения структуры. Это реально быстро. Все это – разные аспекты одного и того же понятия, разные вещи, на которые нужно обращать внимание в приложении.
Переход по путям
Я хотел бы остановиться детальней на этапе перехода по путям (switching a route).
Важный момент, — при переходе по путям, фреймворк разрушает и воссоздает все заново. Он не придерживается структуры: все разрушается и все воссоздается заново.
Как можно сделать этот процесс быстрым?
Чтобы сделать что-то быстро, нужно измерить эту быстроту. Для этого нужен тест. Один из тестов на производительность, которые мы используем – это тест производительности по методу deep-tree. Возможно, вы слышали о таком. Это компонент, который используется дважды. Это рекурсия компонента до тех пор, пока не будет достигнута определенная глубина.
У нас есть 512 компонентов и кнопки, которые могут разрушать или создавать эти компоненты. Далее мы замеряем, сколько времени уходит на разрушение и создание компонентов. Так и происходит переход по путям. Переход от одного view к другому. Разрушение всего – создание всего.
Какие у нас есть входные данные?Компоненты
У нас есть компоненты, и я думаю, что их все знают.
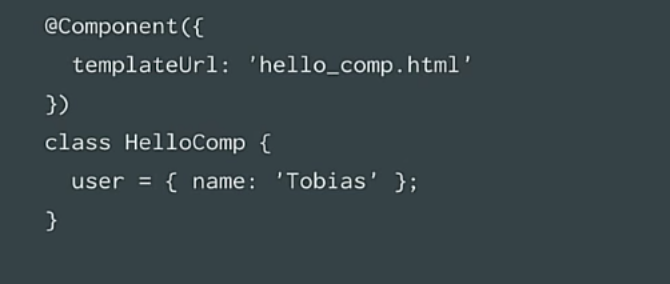
У них есть шаблон (template). Вы можете сделать шаблоны встроенными или поместить их в отдельный файл, стоит помнить что у них есть контекст.
Экземпляры компонентов по своей сути – это контекст, данные, которые используются для постройки шаблона (template). В нашем случае, у нас есть пользователь, у пользователя есть имя (в нашем случае это мое имя).
Шаблон
Далее у нас есть шаблон. Это простой HTML, сюда можно вставить что-то вроде формы ввода, можно применить вообще все, что предлагает HTML.
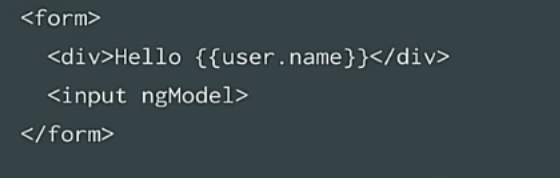
Здесь мы имеем некоторый новый синтаксис: помните двойные фигурные скобки, квадратные и круглые скобки? Это привязка Angular к свойствам или событиям. Сегодня мы будем говорить только о фигурных скобках и о том, что они означают. С точки зрения семантики это значит «взять данные из компонента и поместить их в определенное место». При изменении данных должно происходить обновление текста.
Директивы
Директивы содержат селектор – это селектор CSS. Суть в том, что когда Angular проходит разметку, если он находит директиву, которая соответствует какому-то элементу, то выполняет ее.
Допустим, у нас есть селектор для форм, и этим мы как бы говорим, — каждый раз когда мы создаем элемент формы, пожалуйста создай эту директиву.
Точно так же и с ngModel. Когда вы создаете атрибут ngModel, вы должны создать и директиву.
У этих директив могут быть зависимости. Это наше выражение зависимости.

Зависимость имеет иерархическую структуру, таким образом, чтобы ngModel запрашивала ngForm.
И что же делает Angular?
Он просматривает все дерево в поисках ближайшей ngForm, которая на один уровень выше в структуре дерева. Он не будет просматривать одноуровневые элементы, только родительские.
Есть и другие входные данные, но мы не будем останавливаться на них подробно.
Все, что делается в Angular, проходит через компилятор.
Хорошо, у нас есть входные данные. Следующее, что нам необходимо – это понять их.
Это просто набор бреда, или, все-таки, это имеет какой-то смысл?
Процесс лексического анализа
Первая стадия
Допустим, у нас есть какой-то шаблон, к примеру, HTML.
Представление шаблона
Как мы его можем представить таким образом, чтоб компилятор его понял?
Этим занимается анализатор. Он прочитывает каждый символ, а затем анализирует смысл. То есть, он создает дерево. У каждого элемента есть только один объект. Допустим, есть какое-то имя – имя элемента, есть дочерние элементы. Скажем так, текстовый узел представляет собой JSON объект с текстовыми свойствами. Также у нас есть атрибуты элемента. Скажем так, мы кодируем это все как вложенные списки. Первое значение – это ключ, второе – это значение атрибута. И так далее, здесь нет ничего сложного. Такая репрезентация называется абстрактным синтаксическим деревом (АСД, english — AST). Вы будете часто слышать это понятие. Это все – HTML.
Как мы можем изобразить связь элемента с данными?
Мы можем отобразить это следующим образом. Это – текстовый узел, то есть у нас есть JSON объект с текстовыми характеристиками. Текст пустой, потому что изначально нет никакого текста для отображения. Текст зависит от входящих данных. Входящие данные представлены в этом выражении. Любые выражение также анализируются на предмет того, что же они означают. Они выглядят как JavaScript, их может быть больше или меньше. Здесь вы не можете применить функцию или цикл for, но у нас есть такая штука как потоки, как нечто особое, что можно применить в этом случае. Мы можем изобразить этот user.name как propPath (путь к характеристике), который можно прочитать.
Это, скажем, особый путь, который представляет данное выражение, а также мы может уловить, откуда именно из вашего шаблона это выражение пришло.
Определение места выражения
Так почему же это так важно? Почему нам важно знать, откуда именно из АСД пришло это выражение?
Все потому, что мы хотим показать вам сообщения об ошибках во время выполнения программы. Скажем так, чтобы ваш пользователь знал об этих ошибках.
И потом, бывают же и исключения? Например, невозможно прочитать имя из undefined. Если такое происходит, тогда вам нужно отправиться в отладчик ошибок и проверить, установить точку прерывания на первой ошибке. Тогда вы должны понять, где именно произошла ошибка.
Компилятор Angular предоставляет вам больше информации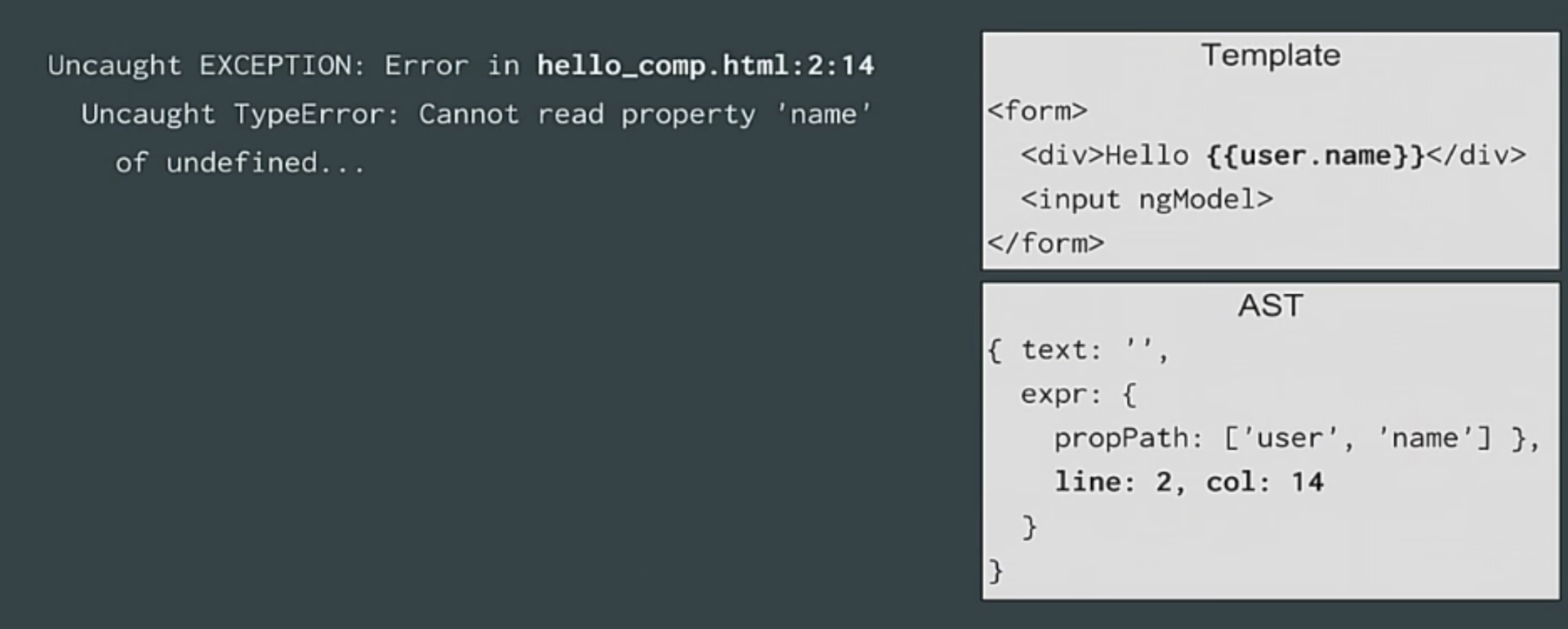
Он показывает, из какого именно места в шаблоне «растут ноги» этой ошибки. Цель – показать вам, что ошибка берет свои истоки, например, из конкретно этой интерполяции во второй строке, 14 столбце вашего шаблона. Для этого нам нужно, чтобы номера строк и столбцов были в АСД.
Далее, какие нам нужны анализаторы, чтобы построить это АСД?
Здесь существует множество возможностей. Например, мы можем использовать браузер.
Браузер – отличный анализатор HTML, верно? Он занимается этим каждый день. Такой подход у нас был при разработке Angular 1, этот же подход мы начинали использовать при разработке Angular 2.
Сейчас мы не используем браузер в таких целях по двум причинам:
- из браузера нельзя вытащить номера строк и столбцов. При анализе HTML браузер просто не использует их.
- мы хотим, чтобы Angular работал и на сервере.
Очевидно, что на сервере нет браузера. Мы могли бы сказать: в браузере мы используем браузер, а на сервере мы используем нечто другое. Так и было. Но потом мы попали в тупиковые ситуации, например, с SVG, или с размещением запятых, поэтому нам нужно было, чтобы везде была одинаковая семантика. Поэтому, проще вставить фрагмент JavaScript, и анализатор. Это как раз то, что делаем мы.
Итак, мы говорили об HTML и выражениях.
Как мы представляем директивы, которые мы находим?
Мы можем отобразить их через JSON объекты, которые представляют элементы, просто добавив другое свойство: директивы. И мы ссылаемся на функции конструктора этих директив.
В нашем примере с вводными данными с ngModel, мы можем изобразить этот элемент как JSON объект. У него есть имя input, атрибуты, ngModel и директивы. У нас есть указатель на конструкторы, а также мы улавливаем зависимости, потому что нам нужно указать, что если мы создаем ngModel, нам нужна и ngForm, и нам нужно подхватить эту информацию.
Учитывая АСД с информацией HTML, связями и директивами, — как мы воплощаем это все в жизнь? Как это можно сделать проще всего?
Сначала разберемся с HTML. Какой самый простой способ создать элемент DOM? Во-первых, вы можете использовать innerHTML. Во-вторых, вы можете взять уже существующий элемент и клонировать его. И в-третьих, вы можете вызвать document.createElement.
Давайте проголосуем. Кто считает, что способ innerHTML – самый быстрый? А кто считает, что element.cloneNode быстрее всего создаст элемент? Или может, самый быстрый способ – это element.createElement?
Очевидно, все меняется с течением времени. Но на данный момент:
- innerHTML – это самый медленный вариант. Это очевидно, потому что браузер должен вызвать свой анализатор, взять вашу строку, пройтись по каждому символу и построить элемент DOM. Очевидно, что это очень медленно.

- element.cloneNode – это самый быстрый способ, потому что у браузера уже есть построенная проекция, и он просто клонирует эту проекцию. Это просто добавление в память еще одного элемента. Это все, что требуется сделать.
- document.createElement – это нечто между двумя предыдущими способами. Этот способ очень близок к element.cloneNode. Чуть-чуть медленнее, но очень близок.

Вы скажете: «Хорошо, давайте будем использовать element.createElement для создания нового элемента DOM».
Так работал Angular 1, и так же мы начинали при разработке Angular 2. И по традиции, оказывается, что это не совсем честное сравнение, по крайней мере, не в случае с Angular. В случае использования Angular, нам нужно создать какие-то элементы, но, помимо этого, мы должны разместить эти элементы. В нашем случае мы хотим создать новые текстовые узлы, но также нам нужно найти именно тот, который отвечает за user.name, поскольку позже мы хотим обновить его.
Поэтому, если сравнивать, то мы должны сравнивать как создание, так и размещение. Если использовать innerHTML или cloneNode, то придется заново проходить весь путь построения DOM. При использовании createElement или createTextNode вы обходите эти действия стороной. Вы просто вызываете метод и сразу же получаете его исполнение. Никаких новых построений и прочего.
В этом отношении, если сравнивать createElement и createTextNode, они оба примерно одинаковы по скорости (зависимо от количества привязок).
Во-вторых, требуется гораздо меньше структур данных. Вам не требуется отслеживать все эти индексы и прочее, поэтому такие способы проще и почти одинаковы по скорости. Поэтому, мы используем эти способы, и другие фреймворки также переключаются на такой подход.
Итак, мы уже можем создавать элементы DOM.
Теперь нам нужно создать директивы
Нам нужно внедрение зависимостей от дочернего элемента к родительскому. Допустим, у нас есть структура данных под названием ngElement, которая включает элемент DOM и директивы для данного элемента. Также есть родительский элемент. Это простое дерево внутри дерева DOM.
 И как же мы можем создать элементы DOM из АСД?
И как же мы можем создать элементы DOM из АСД?
У нас есть шаблон, у нас есть элемент, из которого мы построили АСД. Что мы можем сделать со всем этим?
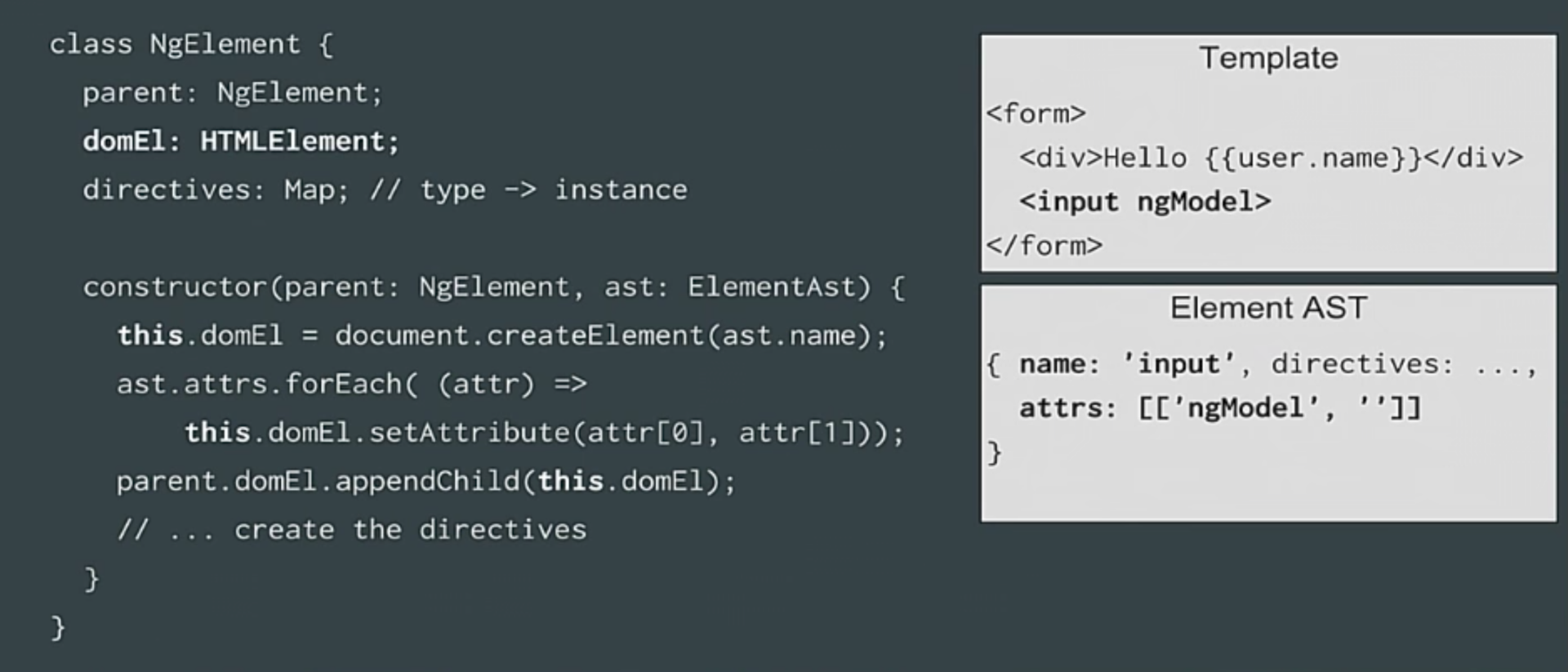
В нашем ngElement и конструкторе вызываем document.createElement, просматриваем атрибуты и присваиваем их элементам, и дальше добавляем элемент к нашему родительскому элементу. Как видите, никакой магии.
Дальше переходим к директивам. Как это работает?
Мы просматриваем привязки, каким-то образом получаем их (расскажу об этом чуть позже) и просто повторно вызываем new для конструктора, отдаем ему привязки и сохраняем Map. Map будет переходить от типа директив (ngModel) к экземплярам директив.
И весь этот поиск директив будет работать таким образом: у нас будет метод, который получает директиву, которая сначала проверяет сам элемент (если ли у него директива). Если нет, то возвращаемся к родителю и проверяем там.
Это самое простое, что можно сделать. Мы сами начинали в этом направлении. И это работает.
Важная деталь: привязки. Как отобразить привязки?
Вы просто создаете класс binding, у которого есть target – Node. Им будет текстовый узел.
У target есть свойство, в нашем случае это будет значение узла, это место, куда поместится значение. И выражение.
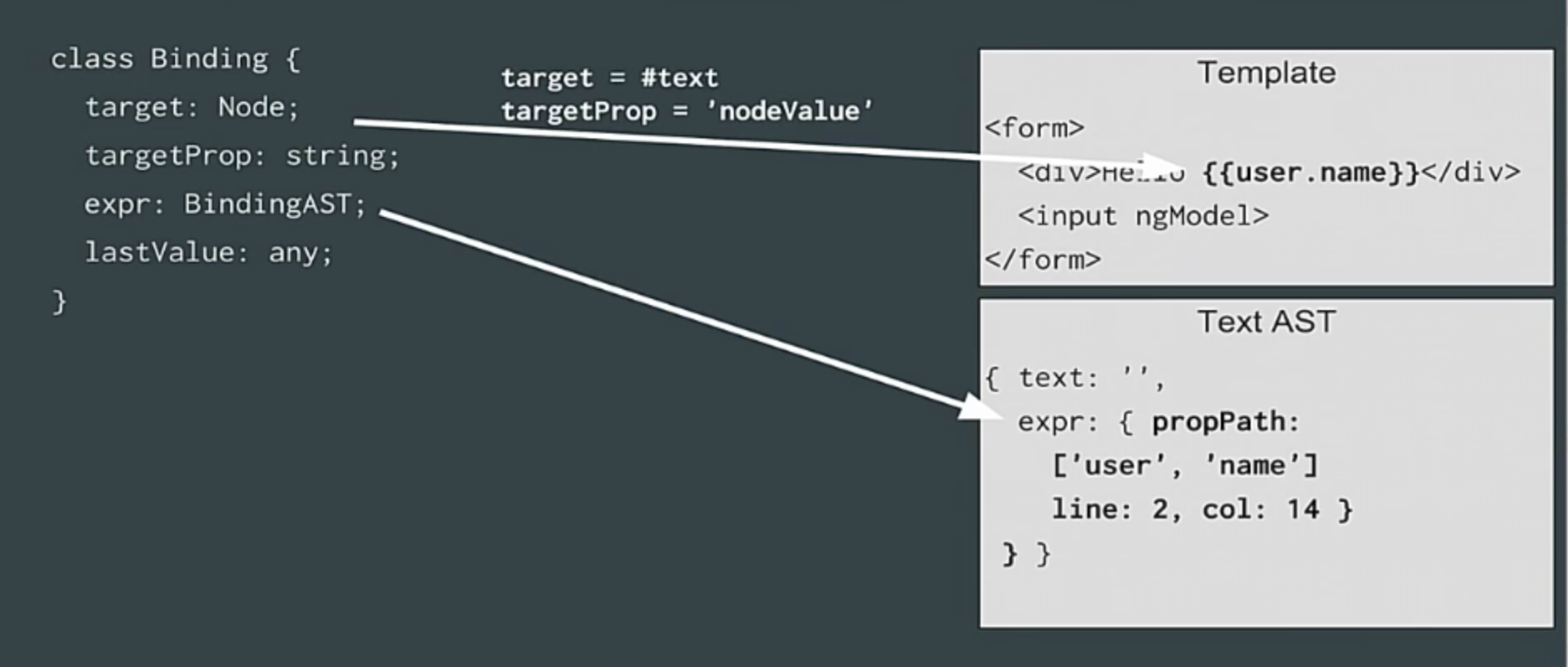
Привязка работает таким образом: каждый раз, когда вы оцениваете выражение или когда оно просто изменяется, вы сохраняете его в target.
То есть у вас может быть следующий метод: сначала вы оцениваете выражение, если оно изменилось – то обновляете target и другие сохраненные ранее значения.

Что касается тех исключений, о которых речь шла ранее – мы вызываем методы try catch для отслеживания пути оценивания. Когда срабатывает исключение, мы его повторно генерируем и создаем для него модель из номеров строк и столбцов.
Так мы и получаем номера строк и столбцов, в которых есть ошибки. Это все мы связываем в представление. Это последняя структура данных.
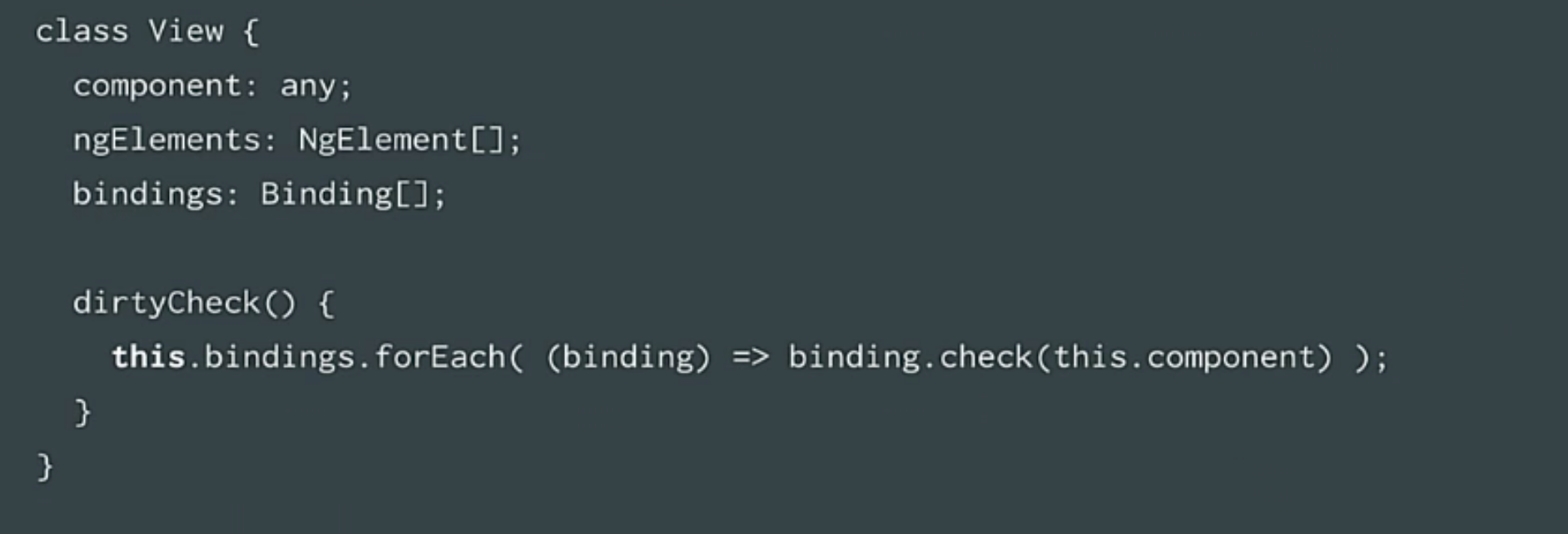
Представление – это элемент шаблона. То есть, когда мы просматриваем код ошибок – мы увидим много представлений. Это просто элементы шаблона. И их мы соединяем в представление. Представление ссылается на компонент, ng-элементы и привязки а также метод dirty-check, который просматривает привязки и проверяет их.
Вот мы и закончили первую стадию. У нас есть новый компилятор. Насколько мы быстры? Почти на таком же уровне, что и Angular 1. Уже неплохо. Используя подход проще, мы добились той же скорости. А ведь Angular 1 не медленный.
Вторая стадия

Как нам ускорить процесс? Какой следующий шаг? Что мы упустили? Давайте разбираться.
Нам нужно что-то, что имеет отношение к нашим структурам данных. Когда дело касается структуры данных, на самом деле, это очень сложный вопрос. Если сравнивать с прошлой написанной нами программой, где появляется try-catch, но если отбросить это, мы увидим, что многие функции тормозят процесс, и что многие моменты нужно оптимизировать. Если вы считаете причиной медленной работы своей программы структуры данных, то это очень сложный вопрос, потому что они разбросаны по всей вашей программе. Это всего лишь предположение, что дело в структурах данных.
Мы провели эксперименты и попробовали разобраться. Мы наблюдали за этими директивами: Map внутри ngElements.

Получается, что для каждого элемента в дереве DOM мы создаем новый map? Можно было бы сказать, что там нет директив, мы их не создавали. Но все-таки, мы всегда создаем map, наполняем его директивами и считываем с него информацию. Это может быть неэкономно, это может перегружать память, прочтение все-таки занимает тоже какое-то время.
Альтернативный подход: можно сказать: «Окей, мы разрешаем только 10 директив для одного элемента. Далее мы создаем класс inlinengElement, 10 свойств для элементов директив и типов директив, и для того, чтобы найти директиву мы создаем 10 условных операторов IF». Это быстрее? Возможно.
Это не потребляет много ресурсов памяти, да?
К примеру, установка: вы устанавливаете свойство, а не map. Чтение может быть немного медленным из-за 10 условий. Это как раз тот случай, для которого был оптимизирован JavaScript VM. JavaScript VM может создавать скрытые классы (можете погуглить о них на досуге). Это и делает JavaScript VM быстрее. Переключение на эту структуру данных – это то, что ускоряет процессы. Позже мы посмотрим на результаты тестов производительности. Еще одна штука, для которой нужно оптимизировать структуры данных – это повторное использование существующих экземпляров.
Можно задать логичный вопрос, — Если некоторые строки уничтожены, а другие восстанавливаются, то почему тогда не кешировать эти строки в кеше и изменять данные, как только строки появляются? Так мы и сделали. Мы создали так называемый view cache, который восстанавливает старые экземпляры представлений.
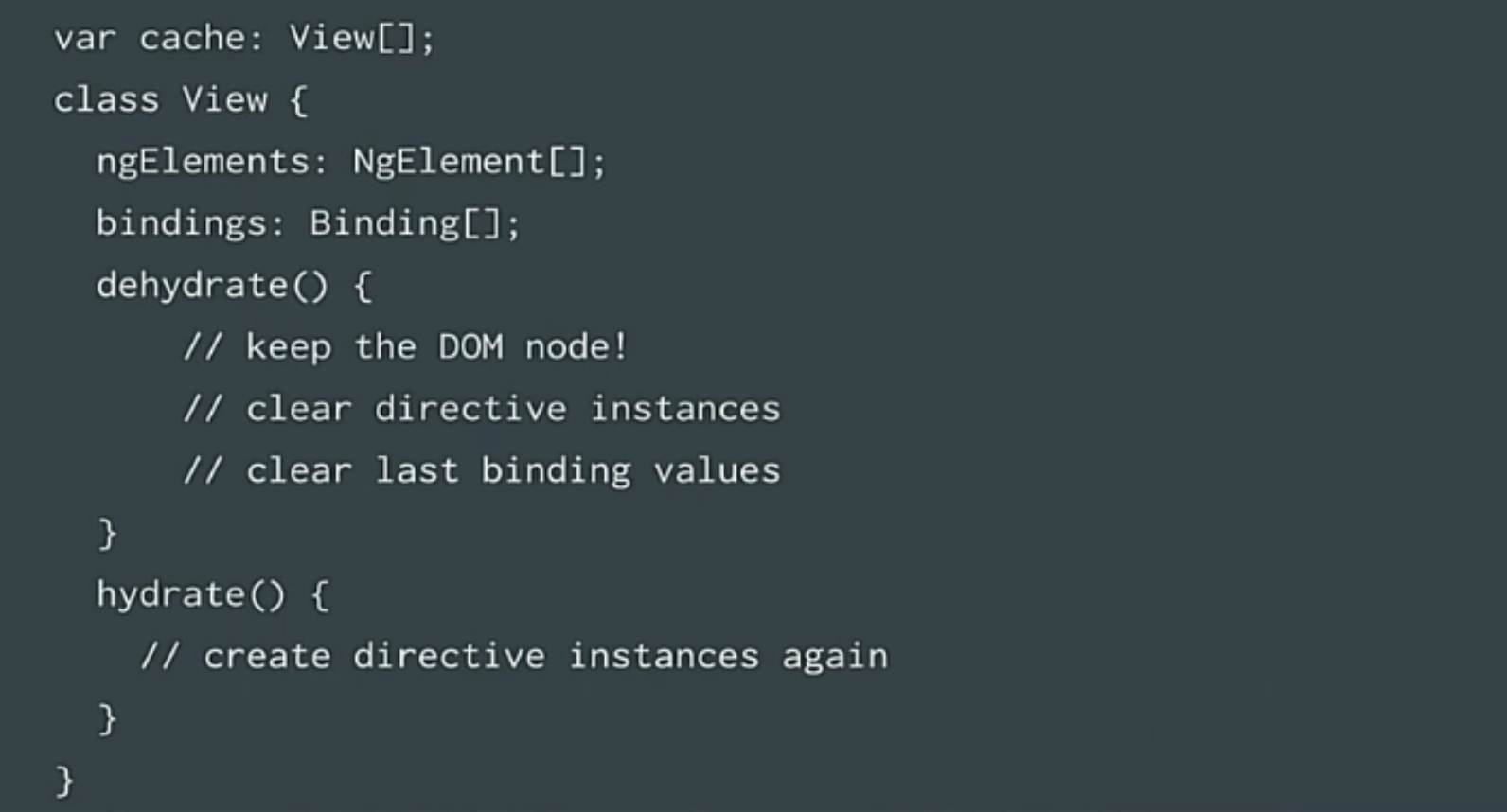
Перед тем, как перейти в новый пул, нужно уничтожить состояние. Состояние содержится в директиве. Так мы убиваем все директивы. Далее, когда происходит выход из пула, нужно заново создать эти директивы. Этим занимаются методы hydrate и dehydrate. Узлы DOM мы сохранили, поскольку все происходит из модели, весь статус – в модели. Поэтому мы ее и сохранили. И снова мы провели тест на производительность.
Среда тестирования
Чтобы вы поняли результаты этих тестов, стоит отметить, что Baseline – это программа с ручным JavaScript кодом и жесткой кодировкой. В такой программе не были использованы никакие фреймворки, программа была написана только для этого теста deep–tree. В программе производится dirtyChecking. Эту программу мы приняли за единицу. Все остальное сравнивается в соотношении. Angular 1 получил отметку 5,7.
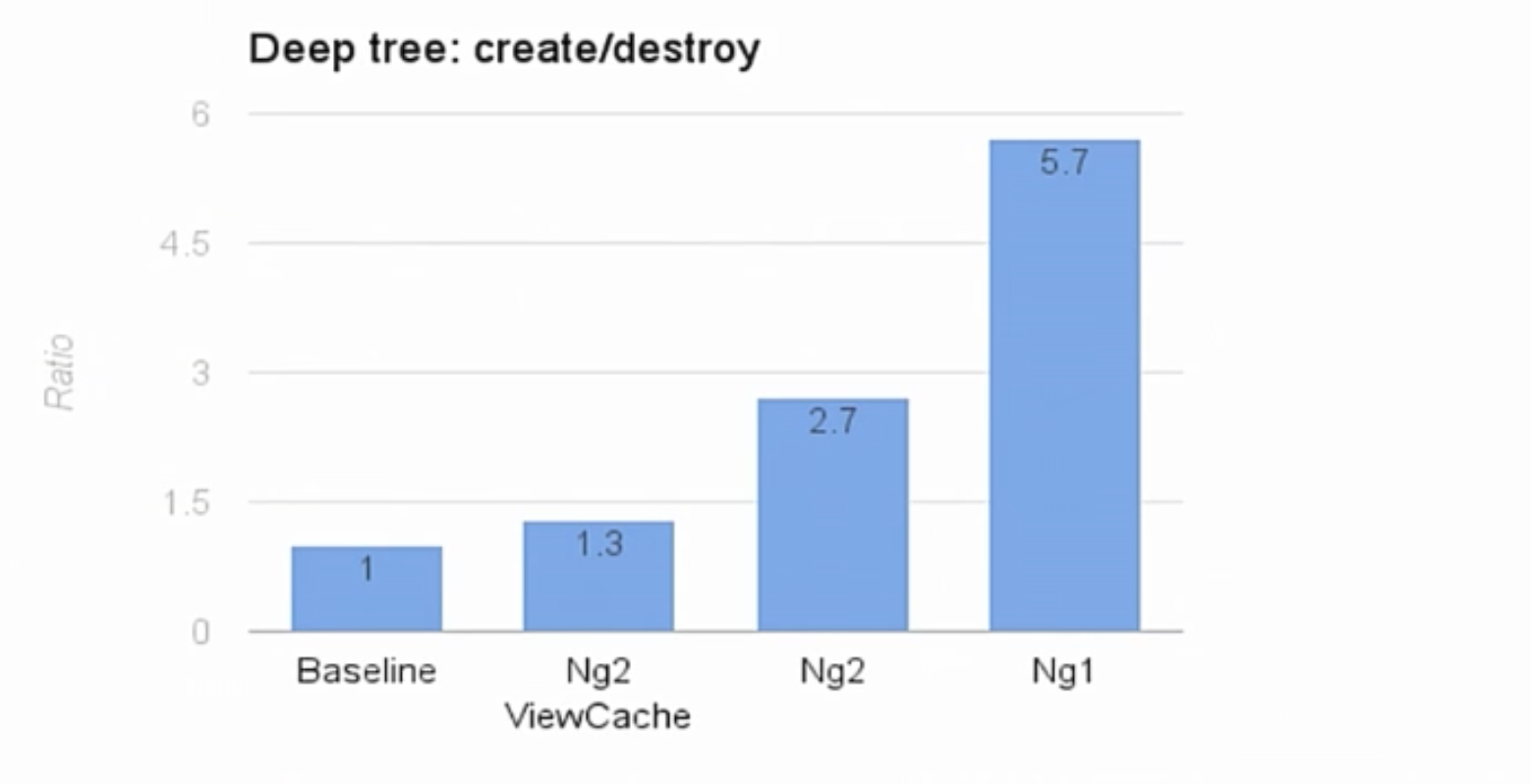
Раньше мы показывали такую же скорость с оптимизированными структурами данных и без view cache. Мы были на уровне 2,7. Так что, это неплохой показатель. Мы увеличили скорость в два раза за счет быстрого доступа к свойствам. Сначала мы подумали, что наша работа на этом заканчивается.
Недостатки второй стадии
Мы создали приложения на этой базе. Но потом мы увидели недостатки:
- ViewCache плохо дружит с памятью. Представьте, вы переключаете маршруты обработки запросов. Ваши старые запросы остаются в памяти, потому что они кешированы, не так ли? Вопрос в том, когда удалять запросы из кэша? На самом деле, это очень сложный вопрос. Можно было бы создать несколько простых элементов, которые бы позволяли пользователю выбирать, кэшировать что-то или нет. Но это было бы, как минимум, странно.
- Еще одна проблема: элементы DOM имеют скрытое состояние. Например, элемент помещен в фокус. Даже если у вас нет привязки к фокусу, и элемент может находиться как в фокусе, так и вне его, то его удаление или возвращение может изменять фокус этого или других элементов. Про это мы не подумали. Появились связанные с этим баги. Можно было пойти таким путем: мы могли полностью удалять элементы, чтобы удалить их состояние, и даже восстанавливать их. Но это бы свело на нет показатели ViewCache, если бы нам пришлось воссоздавать DOM. Ведь у нас был показатель 2,7. Как же мы бы достигли скорости в такой ситуации?
Третья стадия
Класс view
Дальше к нам пришла мысль: давайте еще раз посмотрим на наш класс view. Что там у нас?
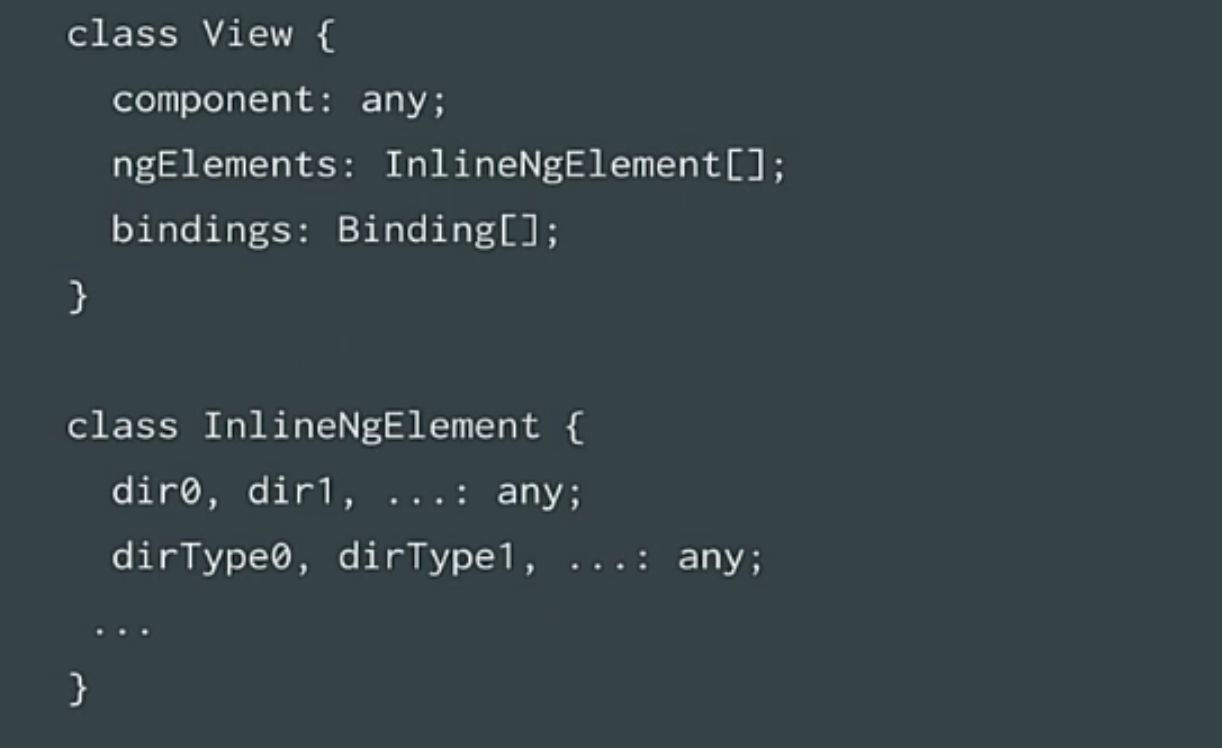
У нас есть компонент – эти уже оптимизированные ngelement, так? У нас есть привязки. Но класс view по-прежнему содержит эти массивы. Можем ли мы создать InlineView, который тоже использует только свойства? Никаких массивов. Это возможно? Оказалось, да.
Как это выглядит? Примерно так.
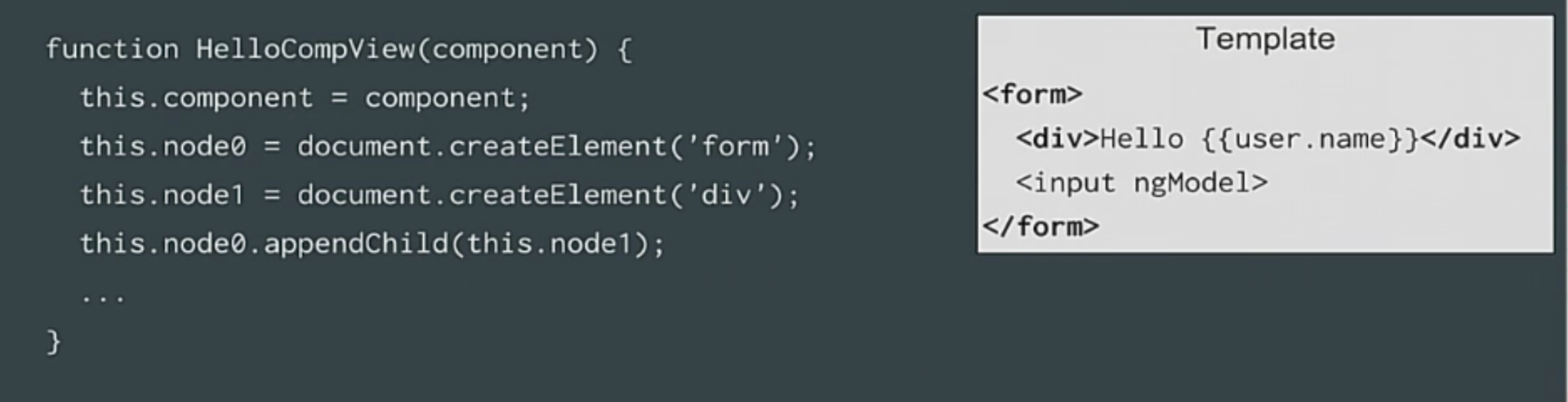
 Шаблон
Шаблон
Итак, у нас, как и ранее, будет шаблон, и для каждого элемента мы просто будем создавать код. Для этого шаблона мы будем создавать код, который отображает наш класс view. В конструкторе для каждого элемента мы вызовем document.createElement, который будет храниться в свойстве Node0 – для первого элемента, для второго мы опять вызовем document.createElement, который будет храниться в Node1. Дальше, когда нам понадобится присоединить элемент к своему родителю, у нас есть свойства, так ведь? Нам просто нужно сделать все в правильном порядке. Мы можем использовать свойство для обращения к предыдущему состоянию. Именно так мы поступим с DOM.
 Директивы
Директивы
С директивами мы поступаем точно так же. У нас есть свойства для каждого экземпляра. И опять-таки, нам просто нужно убедиться в правильности порядка выполнения действий: что сначала идут зависимости, а затем те компоненты, которые используют эти зависимости. Что сначала мы используем ngForm, а затем – ngModel.
Привязки
Далее, привязки. Мы просто создаем код, который выполняет dirty-check. Мы берем наши выражения, конвертируем их обратно в JavaScript. В этом случае это будет this.component user.name. Это значит, что мы вытаскиваем user.name из компонента, сравниваем его с предыдущим значением, которое так же является свойством. Если значение изменилось – мы обновляем текстовый узел. В конце мы сводим все к представлением со структурой данных. В ней только свойства. Нет никаких массивов, Map, везде используется быстрый доступ через свойства.
Это значительно ускоряет процесс. Скоро я покажу вам цифры, чтобы вы могли убедиться в этом.
Вопрос вот в чем: как мы это делаем?
Скажем, кому-нибудь нужно создать строку, которая оценивает этот новый класс. Как это делается? Мы просто применяем то, что мы делали в реализации 101 в нашей текущей реализации.
Суть вот в чем: Если раньше мы создавали DOM узлы, сейчас мы создаем код для создания DOM узлов. Если раньше мы сравнивали элементы, сейчас мы создаем код для сравнения элементов. И наконец, Если раньше мы обращались к экземплярам директив или узлам DOM, сейчас мы храним свойства там, где хранятся экземпляры директив и узлы DOM. В таком случае код выглядит вот как.
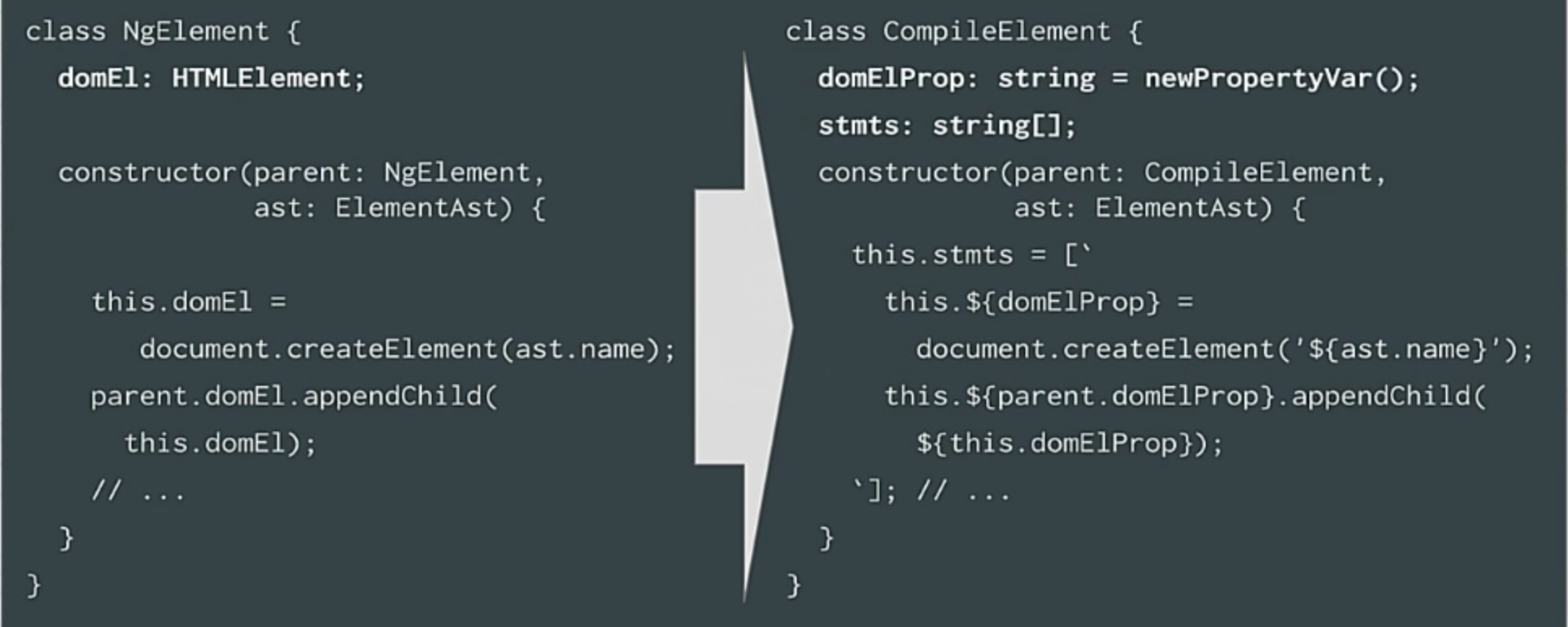
Раньше, у нас был наш ngelement, сейчас у нас есть compileElement. На самом деле эти классы сейчас существуют в компиляторе. Там есть compileElement, compileView и так далее.
Отображение будет таким: раньше у нас был элемент DOM, сейчас же у нас есть только свойство, в котором хранится элемент DOM. Раньше мы вызвали document.createElement, сейчас же мы создаем строку с этой новой строковой интерполяцией, которая отлично подходит для создания кода, в котором мы говорим, что this.document + название его свойства равнозначен document.createElement с названием АСД.
И наконец, если раньше мы вызывали appendChild, то сейчас мы создаем код для присоединения дочернего элемента к родительскому. То же самое происходит и с поиском директив-зависимостей. Все происходит по такому же алгоритму, только сейчас для этих целей мы создаем код.
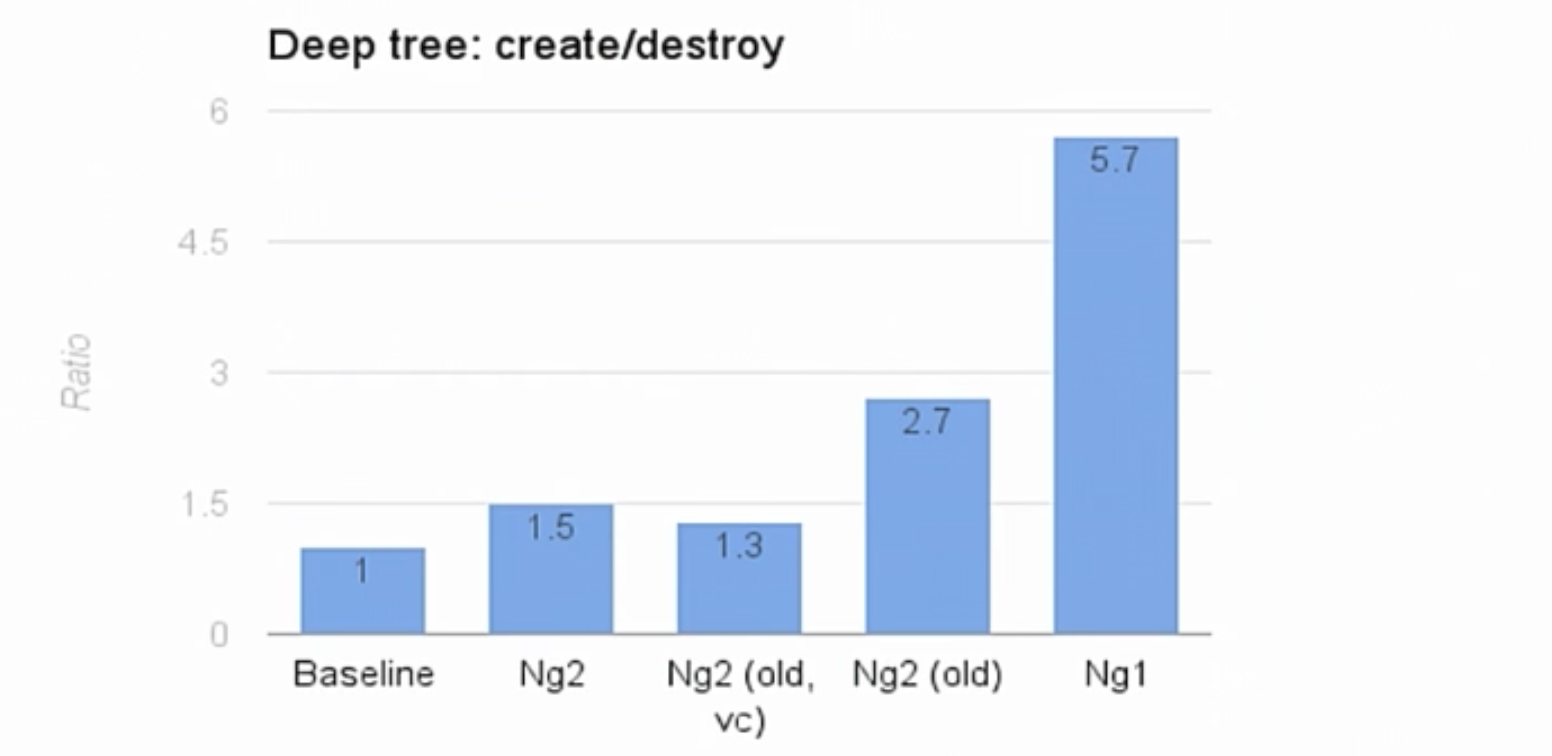
Если сейчас мы посмотрим на показатели, то увидим, что сейчас мы гораздо увеличили скорость. Если раньше наш показатель был 2,7, то сейчас он составляет 1,5. Это почти в два раза быстрее. ViewCache, по-прежнему, остается чуть быстрее. Но мы исключили вариант с его использованием, и вы уже знаете причины нашего решения. Мы отлично справились, и могли бы уже закончить. Но нет.
Динамическая (Just in Time) компиляция
Итак, вначале мы говорили про динамическую (Just in Time) компиляцию. Динамическая – это значит, что мы компилируем в браузере.
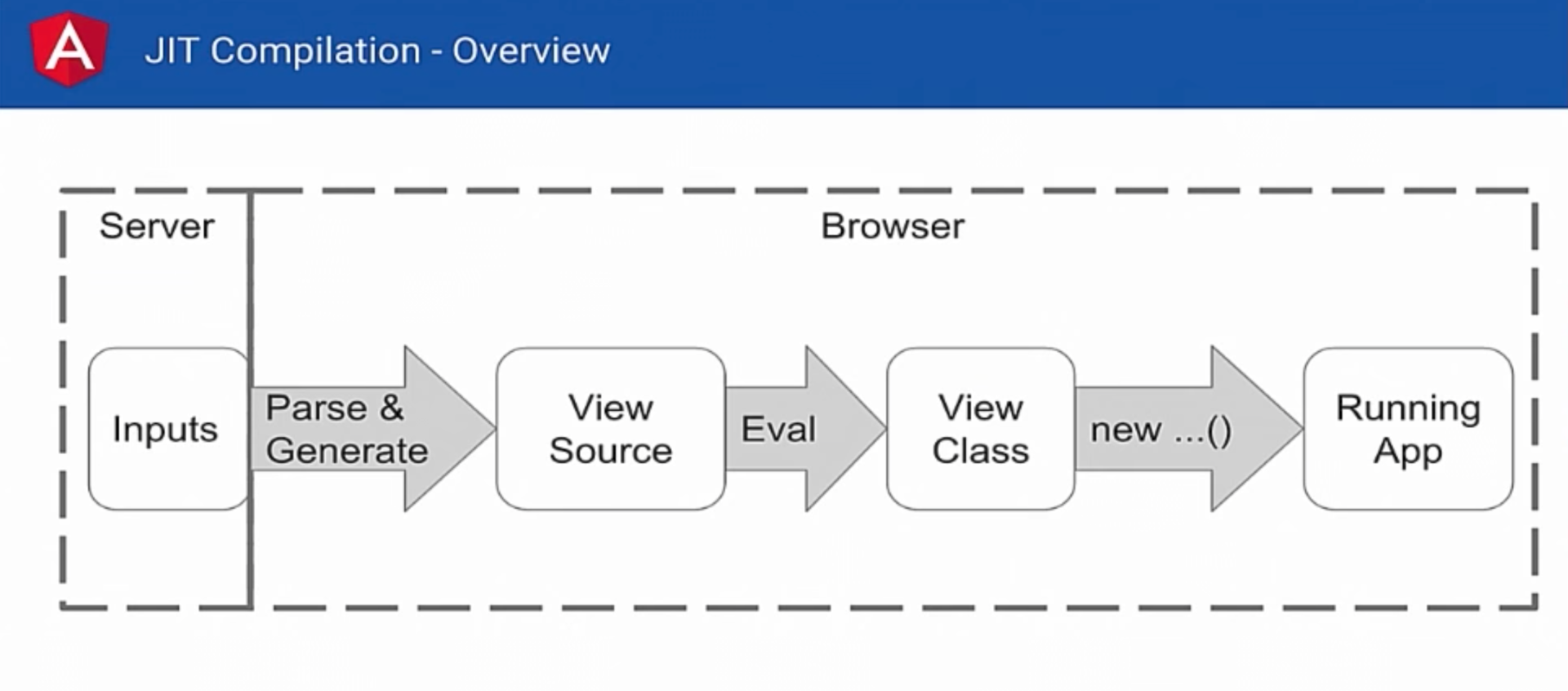
Напомним, это работает примерно так: у вас есть какие-то входящие данные, которые находятся на вашем сервере. Браузер их загружает и забирает, анализирует все, создает исходный класс view. Теперь нам нужно оценить этот исходный код для того, чтобы получить еще один класс. После этого мы можем создать этот класс, и далее мы получаем работающее приложение. С этой частью возникают определенные проблемы:
- Первая проблема в том, что нам нужно анализировать и создавать код внутри браузера. Это занимает какое-то время, в зависимости от того, сколько у нас компонентов. Мы должны пройти все символы. Конечно, это происходит достаточно быстро. И все же, на это тоже нужно время. Поэтому ваша страница будет загружаться не самым быстрым образом.
- Вторая проблема – это то, что анализатор должен находиться в браузере, поэтому нужно загрузить весь Angular компилятор в браузер. Поэтому, чем больше свойств мы добавляем и чем больше мы создаем кода, тем больше становиться размер.
- Следующая проблема – это оценка. В оценке кроется подвох. Главная проблема оценки – это то, что вы можете сделать ошибки, используя ее. Из-за одной такой ошибки кто-то может взломать ваш сайт. Поэтому вам не стоит использовать оценку, даже если вы думаете, что с вашим кодом все в порядке.
- Еще одной проблемой является то, что сейчас браузер добавляет политику защиты содержимого в качестве отличительной особенности (возможно, вы знаете об этом). С таким раскладом, сервер может дать указание браузеру, что не нужно вообще оценивать ту или иную страницу. Для браузера это может означать, что на этой странице не нужно запускать Angular вообще. Это не очень хорошо.
- Следующая проблема, с которой мы столкнулись, это минификация кода. Если вы хотите минифицировать код (а я надеюсь, что вы так и делаете, чтобы предоставлять клиенту как можно меньше кода), существуют кое-какие уловки, которые вы можете применить:
- Во-первых, вы можете переименовать переменные, обычно это безопасно, потому что вы можете определить, где используется та или другая переменная.
- Во-вторых, вы можете переименовать свойства объектов. Это сложнее, поскольку вы должны знать, где же именно используется тот или иной объект. Компилятор Clojure поддерживает такую функцию (она называется «улучшенная минификация»), мы его использовали в Google и использовали часто.
Итак, если мы используем улучшенную минификацию во время работы компилятора, происходит вот что.
Есть наши компоненты, наша разметка, загружаются в браузер, браузер анализирует шаблон и создает класс view. Пока все идет нормально. Браузер использует user.name, компонент также содержит user.name, просто этот user.name минифицирован с помощью технологии улучшенной минификации. Таким образом, компонент называется, скажем, С1, а мой пользователь внезапно оказывается просто U, а имя – N. Проблема в том, что минификатор не знает о моем шаблоне. Ведь в шаблоне по-прежнему остался user.name.
Итак, шаблон исполняется, по-прежнему создает user.name, которого просто не существует в компоненте. Есть определенные решения этой проблемы. Вы можете указать компоненту, что это свойство минифицировать не нужно. Но это не то, что нам нужно. Нам нужно, чтобы мы могли минифицировать это свойство, но с оперативной компиляцией и оценкой это работать не будет.
Статическая (Ahead of Time) компиляция
Именно по этой причине, следующим нашим шагом стало появление статической (Ahead of Time) компиляции. Она работает следующим образом.

Снова у нас есть входные данные, которые анализируются на сервере, и класс view также создается на сервере.
Тогда браузер просто подхватывает их, загружает как обычный текст сценария (как вы загружаете свой обычный код JavaScript), и затем просто создает нужные элементы.
Такой способ компиляции отлично подходит, потому что: Анализ происходит на сервере (а поэтому происходит быстро), компилятор не нужно переносить в браузер (и это тоже отлично). Также мы больше не используем оценку, ведь это скрипт. Поэтому такая компиляция подойдет для любого браузера.
Также статическая компиляция отлично подходит для улучшенной минификации, потому что теперь мы создаем класс view на сервере, и если мы запустим минификатор, то сможем также минифицировать и наши классы view. Теперь, когда минификатор исполнит свою работу, мы получим переименованные свойства в классах.
Отлично, теперь мы можем использовать улучшенную минификацию. Поэтому, наши показатели скорости упали еще ниже.
Недостатки статической компиляции
Итак, теперь у нас есть статическая компиляция. Теперь все отлично, да? Но как всегда, существуют и недостатки. Первая проблема состоит в том, что с использованием статической компиляции нам нужно создавать другой код.
Для оценки в браузере нужно создавать код по стандарту ES5. Вы создаете код, который использует локальные переменные, или который получает аргументы, переданные в функцию. Вы не используете require.js или что-либо в этом роде.
Поскольку код генерируется на сервере, то нужно было генерировать код TypeScript по двум причинам:
- Во-первых, мы хотели проверять типы ваших выражений (существуют ли они в компонентах).
- Во-вторых, мы хотели эффективно использовать систему модулей TypeScript. Мы хотели создать импорт, чтобы уже вы могли выбирать, какие системы модулей вы хотите использовать. Создание импорта — это гораздо удобнее со стороны возможностей генерации кода, чем думать о require.js, system.js, Google Clojure, системе модулей и так далее.
- В конце концов, мы также хотели применить код стандарта ES6 2016.
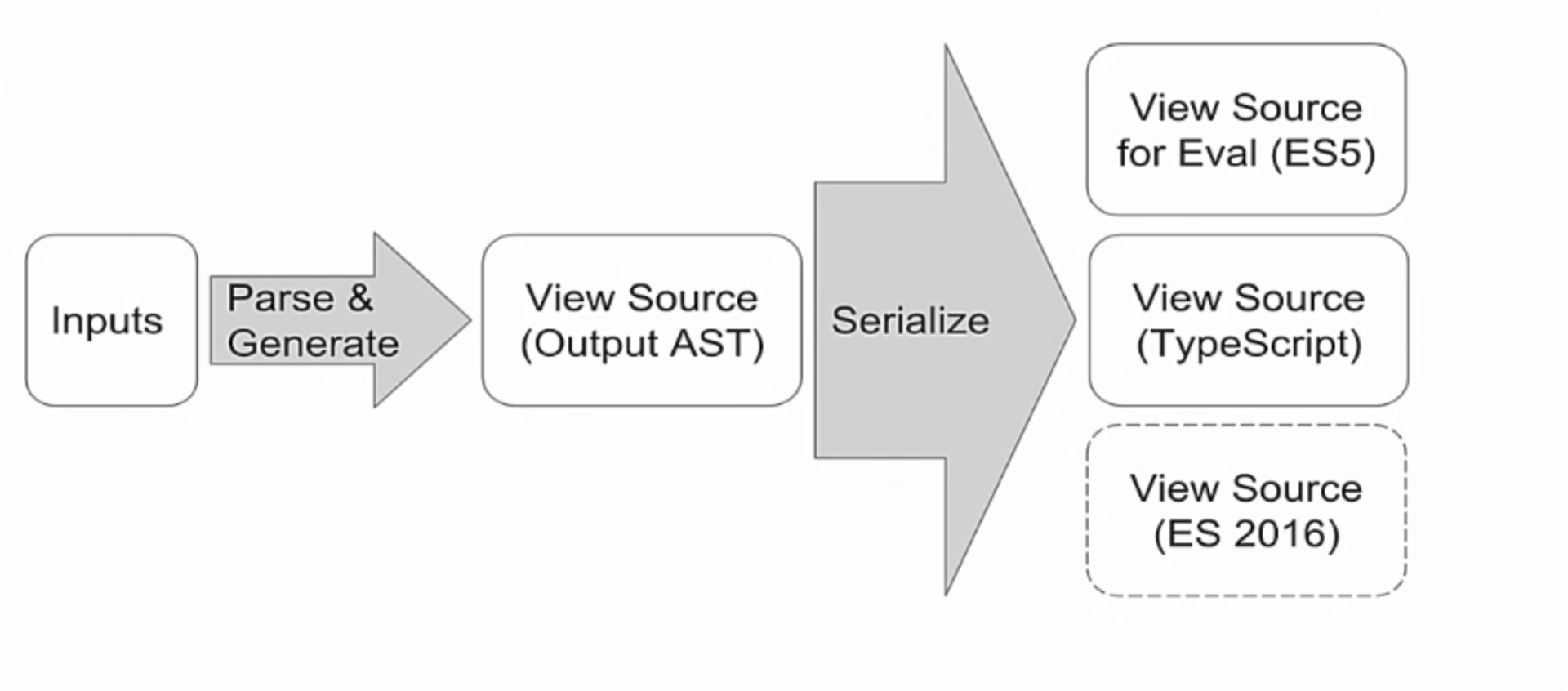 Как нам удалось обеспечить поддержку ES6 2016?
Как нам удалось обеспечить поддержку ES6 2016?
На самом деле, если вы знакомы с компиляторами, то существует общий шаблон. Вместо создания строк создается структура данных, похожая на выводимые данные, но эту структуру данных, эту АСД, можно сериализовать в разные выходные данные.
АСД содержит такие возможности, как объявление переменной, вызов методов и так далее, плюс типы. Потом для ES5 мы просто сериализуем это все без типов, а для TypeScript сериализуем с типами.
Это выглядит примерно так: наш сгенерированный АСД вывод, внутри объявленные переменные (мы указываем declare var name EL). Это создаст код var el в TypeScript и создаст тип. В ES5 тип будет опущен.
Далее мы можем вызвать метод. Сначала мы прочитаем переменную document (поскольку это глобальная переменная). И потом для нее мы сможем вызвать метод createElement с этими аргументами.
Мы разместили literal со значением «div», потому что, если вы анализируете строки, то должны правильно их экранировать. Значение может содержать кавычки, поэтому при чтении кода нужно их экранировать, пропускать. Поэтому, именно таким образом мы можем это сделать. Хорошей новостью можно назвать то, что теперь наш сгенерированный код одинаково выглядит как на сервере, так и в браузере. Никаких различных частей кода.
Вторая проблема, с которой мы столкнулись при разработке статического компилятора, это выделение метаданных. Взгляните на этот код.

В чем проблема этого кода? Скажем, у нас есть какая-то директива, которая имеет зависимость от cookies, и если у вас есть cookies, директива выполняет что-то другое. Это работает. Вы можете скомпилировать. Супер.
Но это не работает со статической компиляцией. Если подумать, почему так? Если это все спустить до уровня ES5, вы получите именно такой код.
Что, в конечном счете, делает декоратор? Он добавляет свойство вашему конструктору для метаданных. В конце он просто добавляет SomeDir с примечаниями.
Проблема в том, что если вы запустите это на сервере, оно не будет работать. Ведь на сервере нет document. Что же делать?
Можно предложить построить среду браузера на сервере, объявить переменную document, переменную window и так далее. В некоторых случаях это сработает, но в большинстве – нет. Второй способ (мы же теперь хорошо разбираемся в АСД, так?) – обработать АСД и вынуть из него метаданные без оценки кода. В АСД этого можно представить как-то так.
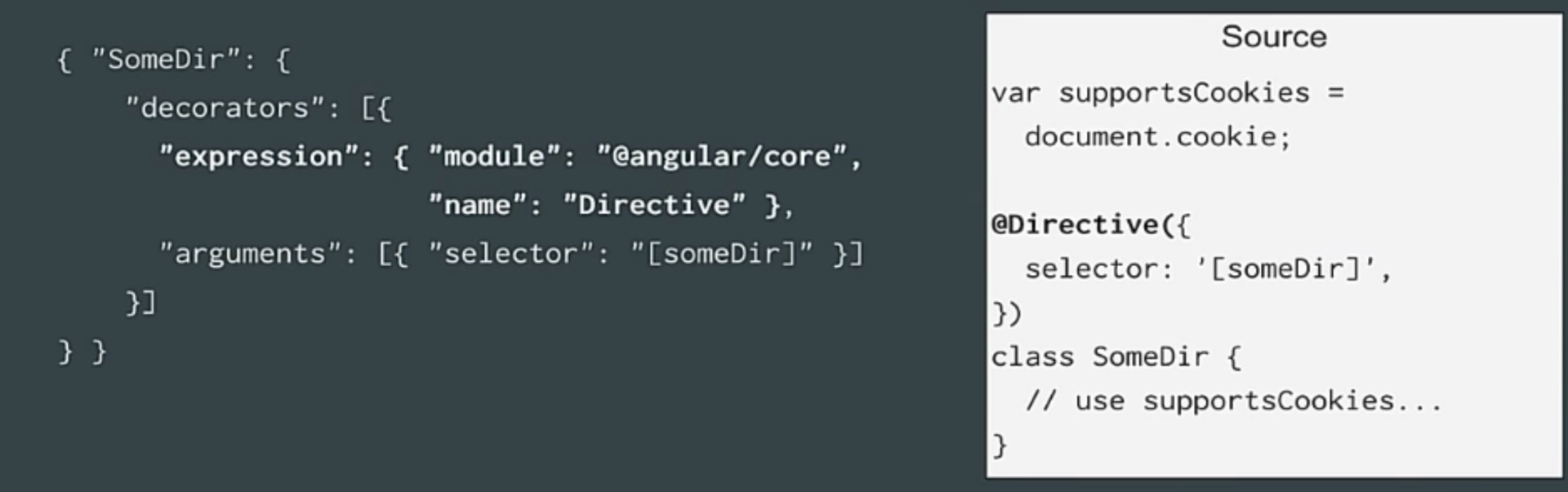
Таким образом, наш класс SomeDir в АСД может иметь свойство decorators, которое обращается к тому элементу, который вы вызываете (это выражение, где определена директива плюс аргументы). Происходит следующее. Мы вытаскиваем метаданные в JSON файлы, дальше наш статический компилятор берет эти файлы и из них создает шаблон. Очевидно, здесь есть ограничения. Мы не оцениваем JavaScript код напрямую, поэтому вы не можете делать все то, что вы привыкли делать в браузере.
Итак, наш статический компилятор ограничивает нас, но вы можете поместить примечание. Но если вы воспользуетесь приведенным выше методом, это сработает во всех случаях.
Хорошо, давайте снова остановимся на тестах производительности.
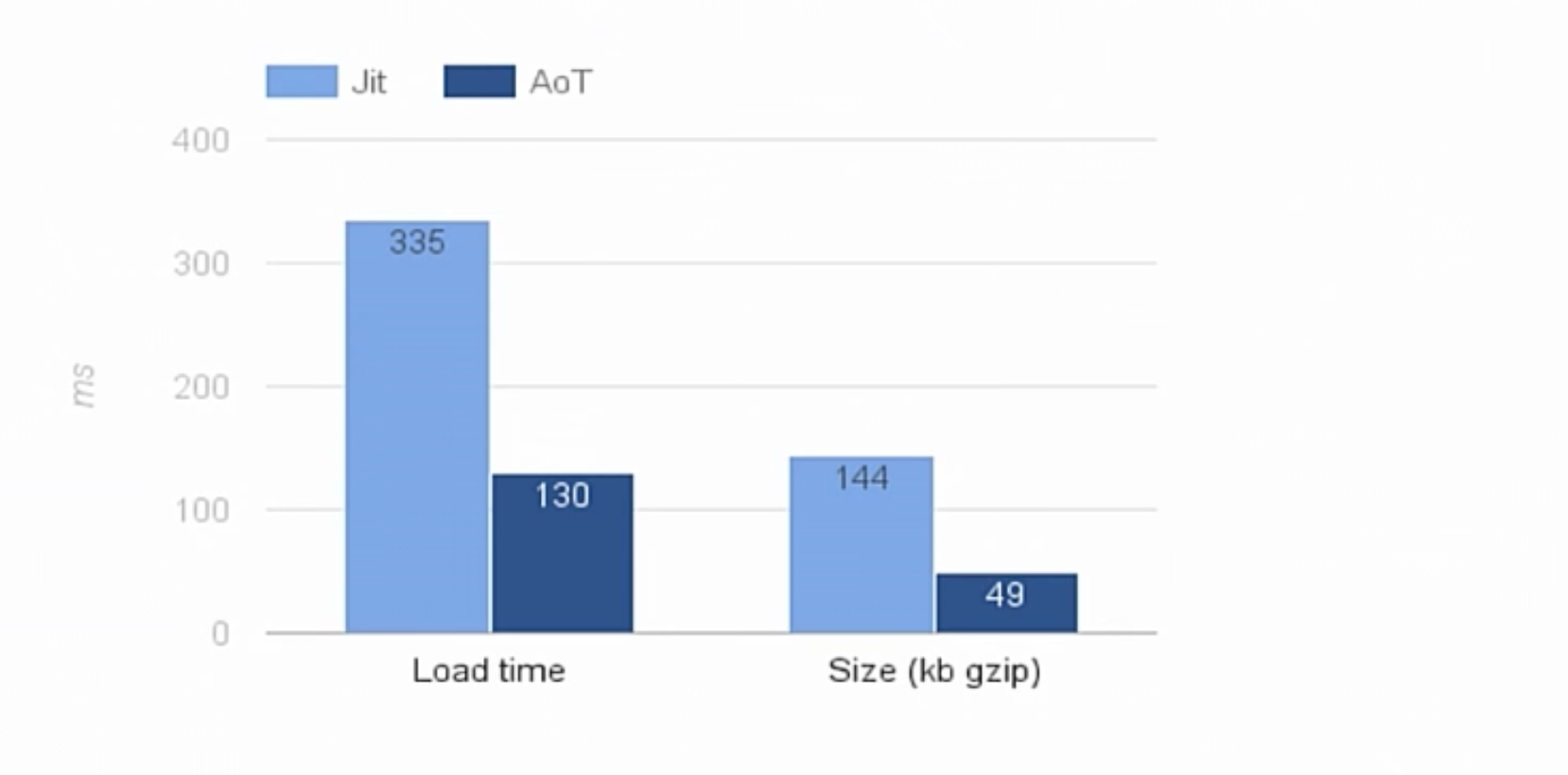
Это – простая написанная нами программа. И время ее загрузки сократилось очень значительно. Все потому, что мы больше не проводим анализ, а также потому, что компилятор Angular 2 больше не загружается. Это почти в три раза быстрее. Размер также сократился с уже минифицированных в формате gzip 144 килобайт до 49. Для сравнения, библиотека React с улучшенной минификацией сейчас весит 46кб.
А теперь немного наглядных примеров
Допустим, у нас есть компонент Angular, у нас есть ngForm и ngModel. ngModel в качестве зависимости имеет ngForm.
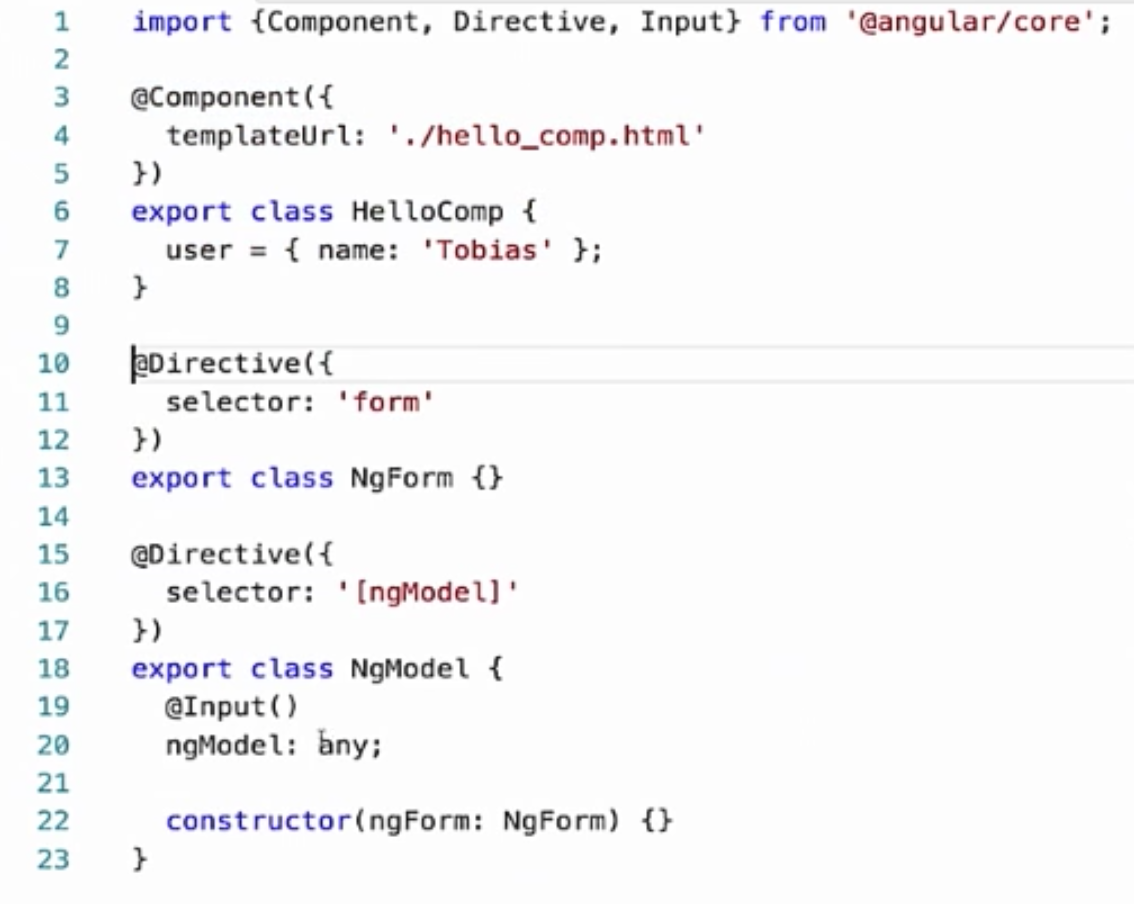
Добавим сюда NGC – это модули _node, которые охватывают компилятор TypeScript, поскольку при вытаскивании и поддержке метаданных эти модули зависят от TypeScript. И если мы посмотрим на сгенерированный код, то увидим, что он выглядит очень знакомо. У нас есть user.name. Если его значение меняется, мы обновляем входные данные директивы. Мы просто сравниваем с предыдущим значением и устанавливаем его.
В этом есть хорошая сторона. Допустим, в своем шаблоне я меняю user.name на wrongName. Наш шаблон обращается к user.name, а не к user. wrongName. Теперь, когда мы посмотрим на сгенерированный код, TypeScript выдаст ошибку.

Потому что эти представления имеют типы, основаны на типе компонента. И теперь при их компиляции вы будете обнаруживать ошибки своего кода, просто потому что мы использовали TypeScript. Ничего другого нам не понадобилось.
Мы хорошо справились, но мы стремимся стать еще лучше.
Наша цель – достичь размера 10 кб gzip. Размер некоторых наших прототипов составляет 25 кб и у меня есть несколько идей, как сделать компилятор еще меньше. Далее, мы хотим стать еще быстрее, чем наша отправная точка Baseline. Мы осознаем, что это еще не предел, и мы можем быть еще быстрее, чем Baseline.
Вы не заметите никаких изменений. Вы будете осуществлять изменения, генерировать разный код. Единственное – вы увидите разницу только в скорости.
В качестве заключения
Мы говорили про производительность, про разные аспекты производительности.
Мы обсуждали входные данные.
Мы узнали, что такое анализ, АСД (AST). Я рассказывал о том, как мы можем представить шаблон и как его реализовать.
Мы узнали, что document.createElement отлично подходит для фреймворка Angular.
Мы узнали, что быстрый доступ по свойствам и скрытые классы – это отличные инструменты для оптимизации вашего кода.
Мы узнали, что генерация кода (если сделать это правильно, то есть не только с помощью оценки, но и с поддержкой оффлайн, а также вывод АСД) – это отличная и мощная вещь. Это поможет вам в генерации скрытых классов.
Мы поговорили о статической (Ahead Of Time) и динамической (Just In Time) компиляции, а также о вещах, которые можно оптимизировать.
И наконец, мы посмотрели наглядный пример. На слайде есть ссылка на мою презентацию.
Огромное спасибо за внимание.