https://habrahabr.ru/company/oleg-bunin/blog/329798/- Разработка веб-сайтов
- JavaScript
- HTML
- CSS
- Блог компании Конференции Олега Бунина (Онтико)

Денис Паясь (Яндекс)
Меня зовут Денис, я работаю в Яндексе, а если точнее, то я занимаюсь разработкой фронтенда для страницы поисковой выдачи.
Дисклеймер: Денис рассказывал об этом в 2016 году, но мы посчитали, что как демонстрация архитектурного подхода сейчас этот доклад актуален даже больше, чем тогда.
Сегодня я расскажу про такую офигительную нашу внутреннюю штуку как Конструктор, про то как он получился, почему, и как мы вообще к этому всему пришли.Мне кажется, что те решения, которые мы приняли в процессе реализации этой замечательной фиготы, могут быть полезны не только нам в рамках нашей компании, нашей команды, но и целому множеству других команд, в ваших, например, компаниях. Я не знаю упомянул я или нет, но проект реально очень крутой. Почему – сейчас расскажу.
Теперь уже в эпоху до «конструктора», до того, как мы его внедрили, разработка какой-нибудь даже типовой продуктовой фичи, самой такой стандартной, занимала у нас офигительное количество времени: в районе двух недель, может, иногда больше, иногда меньше, я на этом остановлюсь подробнее. А сейчас, когда Конструктор внедрен, у нас есть прецеденты, когда фичи делаются за день – причем такой же сложности – а может и меньше. И, что круче всего, зачастую даже не нами, не фронтендерами. В общем, мне кажется, что это просто какой-то офигительный сказочный результат, но тем не менее это правда, и как мы до этого дошли, я сейчас и буду рассказывать.

Но обо всем по порядку.
Как я уже сказал, я работаю над страницей поисковой выдачи, если вы когда-нибудь вдруг почему-то пользовались Яндексом – кстати, советую, – то вы ее, скорее всего, уже видели. Если не видели, то вот – посмотрите, выглядит она следующим образом.
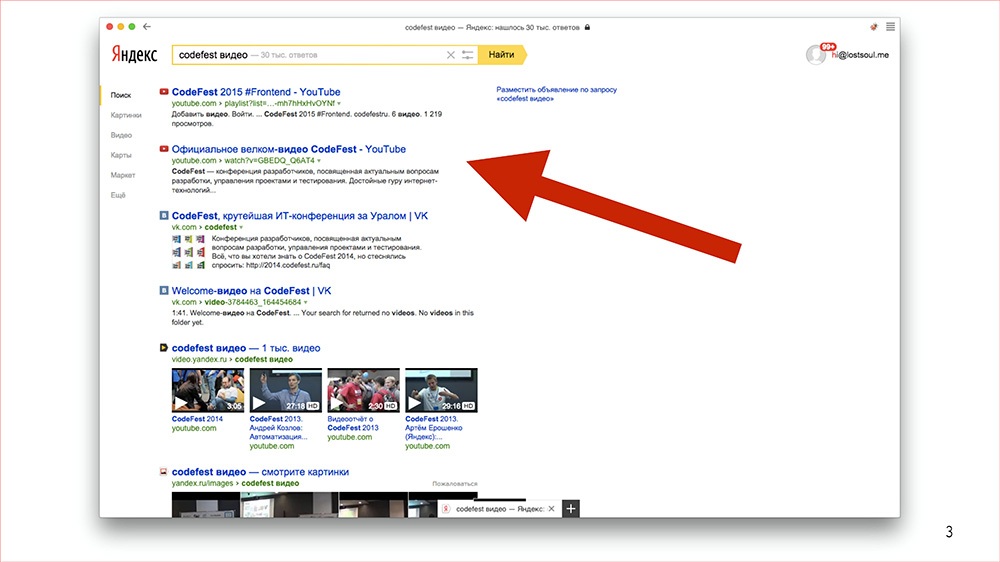
Можете вбить в своих ноутбуках, вживую она еще прикольнее.Над ней работают 35, а может быть даже 36 или уже 37 фронтендеров из 6 городов. Кроме фронтендеров есть еще менеджеры, дизайнеры, тестировщики, какое-то огромное число ребят из бекенда.
В общем, если всех сфоткать, получится примерно так.

Что мы все делаем?
Мы делаем целое множество фичей всяких разных, значительная часть из них – продуктовая.
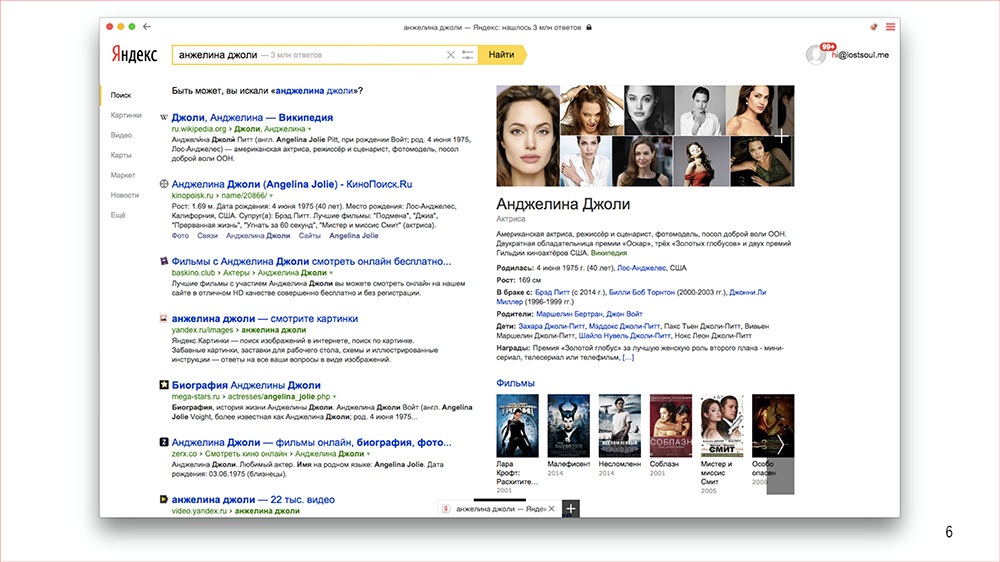
Например, вот эта вот красивая штука справа с фоточками Анджелины Джоли, какой-то структурированной информацией, фильмами, где она снималась, – в наших терминах это отдельная фича. Довольно крупная, она называется объектным ответом, если кому-то интересно.
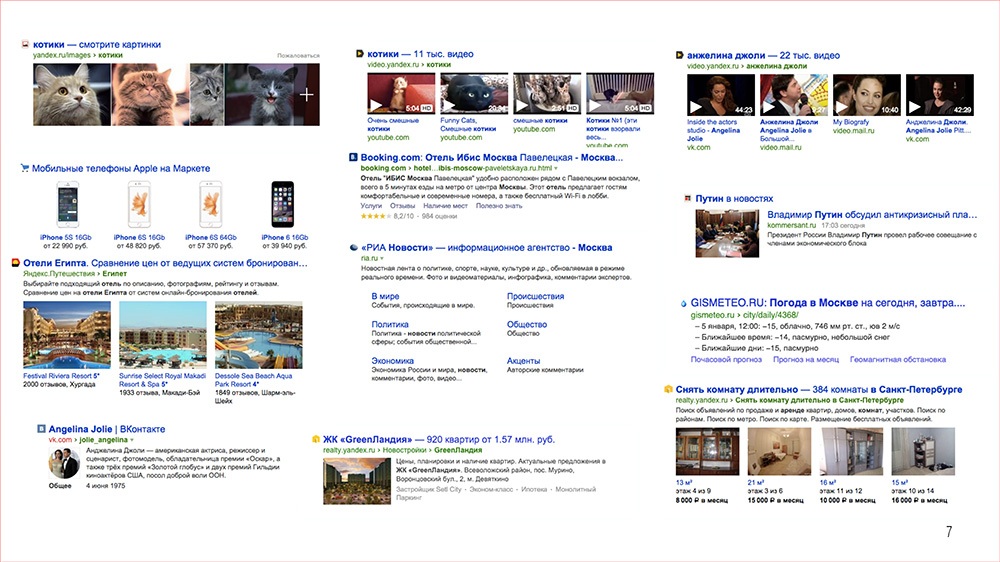
Кроме таких крупных фичей, есть значительная часть фичей поменьше. Для пользователя они выглядят просто как не вполне обычные результаты на выдаче. С картинками, структурированной информацией, видяшкам, в общем, что-то такое немного особенное. И таких фичей у нас выше крыши. В голове у меня почему-то цифра, что их в районе восьмидесяти, но откуда я ее взял, я не знаю, но, я думаю, она примерно похожа на правду.
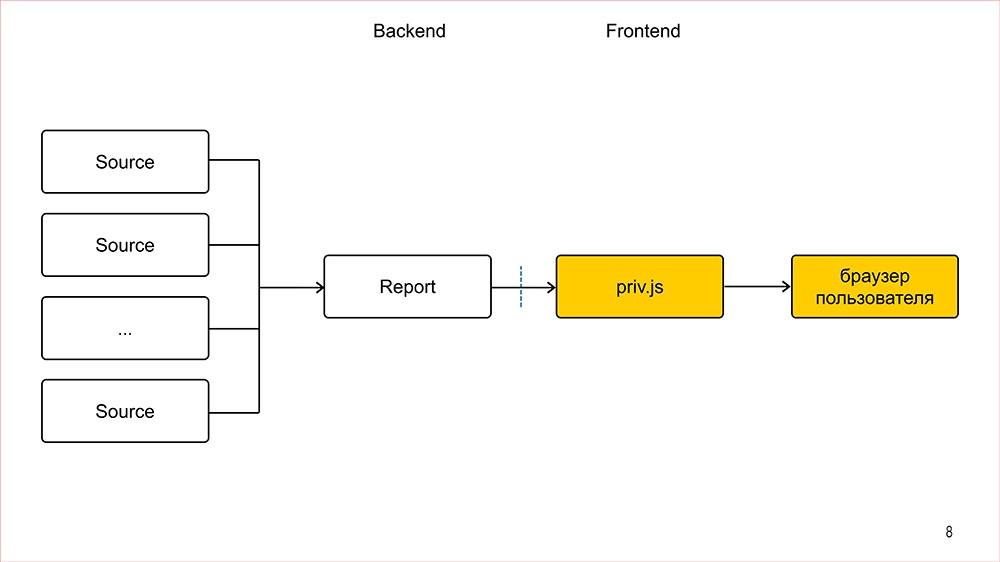
Как все это выглядит технологически, если по верхам? Для каждой такой фичи есть источник данных, то есть ребята из бекенда данные намайнили и, через еще один бекенд, который у нас называется репортом, передали уже нам во фронтенд. Во фронтенде у нас есть своя серверная часть, где на основе этих данных мы сгенерили разметку, которая уже отдается в браузер пользователя и представляет из себя для пользователя собственно фичу. Вроде все просто.Теперь давайте остановимся на какой-нибудь конкретной фиче, и на ее примере я покажу в чем же у нас была большая беда и проблема.

Итак, предположим, что нам нужно сделать фичу. Как это все начинается? Во-первых, ребята из бекенда должны намайнить данные. Например, если мы будем делать фичу про новые девайсы – фичи такого рода у нас в Яндексе часто называют «колдунщиками», если еще раз буду повторять это слово, не пугайтесь, – это просто «фича», почему так – это не важно. Итак, для фичей нужно намайнить данные.

До нас эти данные доходят в виде JSON-чика, причем JSON-чик очень специфичен под каждую фичу. То есть, если это колдунщик новых девайсов, то там будет информация о девайсе, ссылка на маркет, название производителя, может быть, – что-то такое. Если бы это была фича про социальные сети, там была бы имя-фамилия пользователя, что-нибудь еще, его семейное положение, в общем, какая-то такая фигота в предметной области фичи.

Параллельно с майнингом данных нужно нарисовать для всего этого дизайн.

Дизайн в то время у нас представлял их себя макеты, то есть по сути картинки, но с красивыми, возможно, спецификациями, где указаны все отступы, размеры и так далее. То есть нам было в целом достаточно удобно.
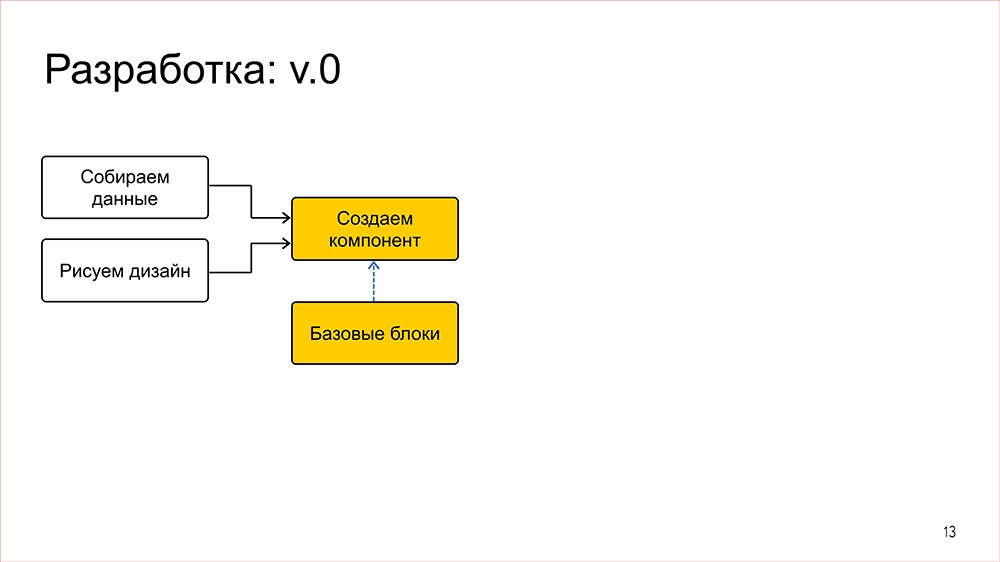
После того как у нас есть данные и дизайн, ставится задача уже на фронтенд, где мы на основе этой входной информации реализуем компонент непосредственно под фичу. В процессе реализации мы стараемся пользоваться какими-то общими штуками: кнопками, ссылками – из нашей небольшой библиотечки.
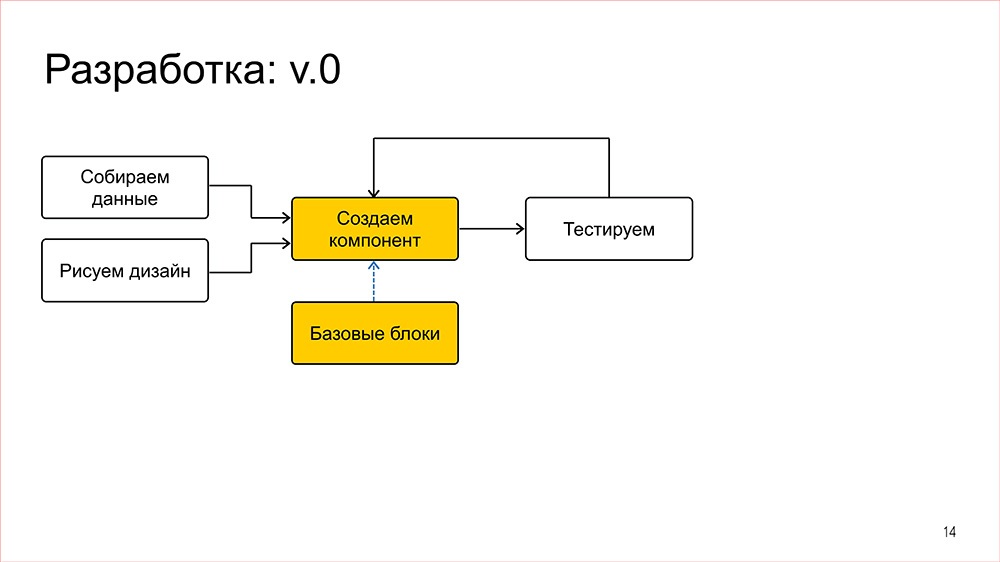
После того как фронтендеру кажется, что фичу он сделал, он отдает ее в тестирование, и тестировщик его убеждает, что скорее всего, фронтендер не прав.

Что проверяет тестировщик? Во-первых, что фича корректно работает под всеми платформами. Мы верстаем сразу под десктопы, планшеты, телефоны, под все браузеры, доля которых на SERP (search engine results page) больше чем, по-моему, пол-процента. В общем, это просто огромное количество штук, которое надо проверить. Кроме того у нас достаточно сложная система логирования, и тестировщик проверяет, что разработчик там в ней нигде не накосячил, что все хорошо.
А еще есть одна распространенная проблема, что дизайнеры на макетах всегда выбирают очень красивые данные, которые друг с другом хорошо сочетаются, и все выглядит замечательно. Но реальный мир зачастую бывает жесток и бывают названия на три строки, когда рассчитывали на одну, или часть данных просто не приходит, и все разъезжается просто – очень страшно выходит. И, в общем, тестировщик должен проверять, чтобы такой фигни не было.
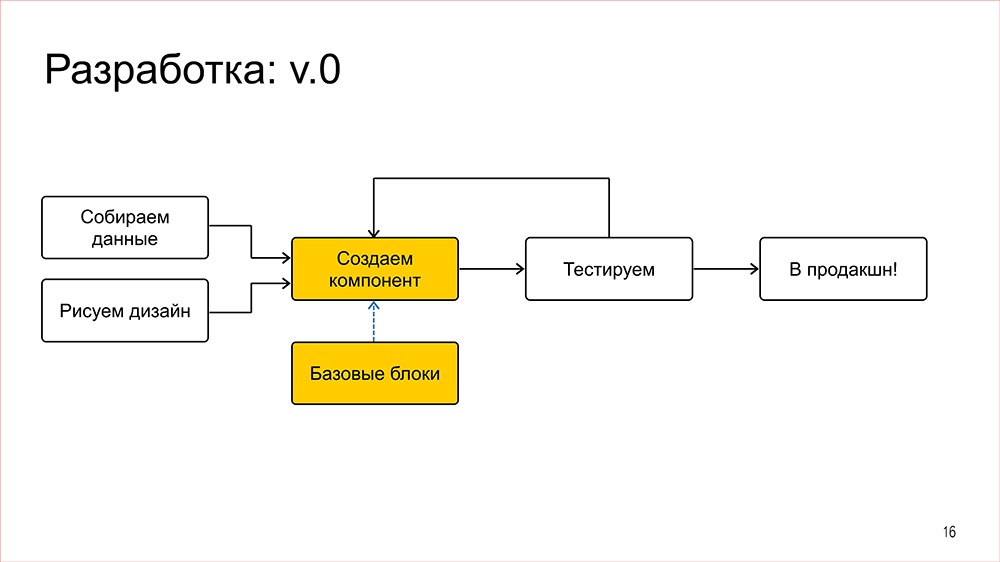
После того, как тестировщик все это проверил, он, скорее всего, возвращает задачу фронтендеру на доработку. Фронтендер это дорабатывает, отдает снова тестировщику, и так до победного. Как только тестировщик считает, что все выглядит замечательно, фича катится в production. Плюс-минус так.
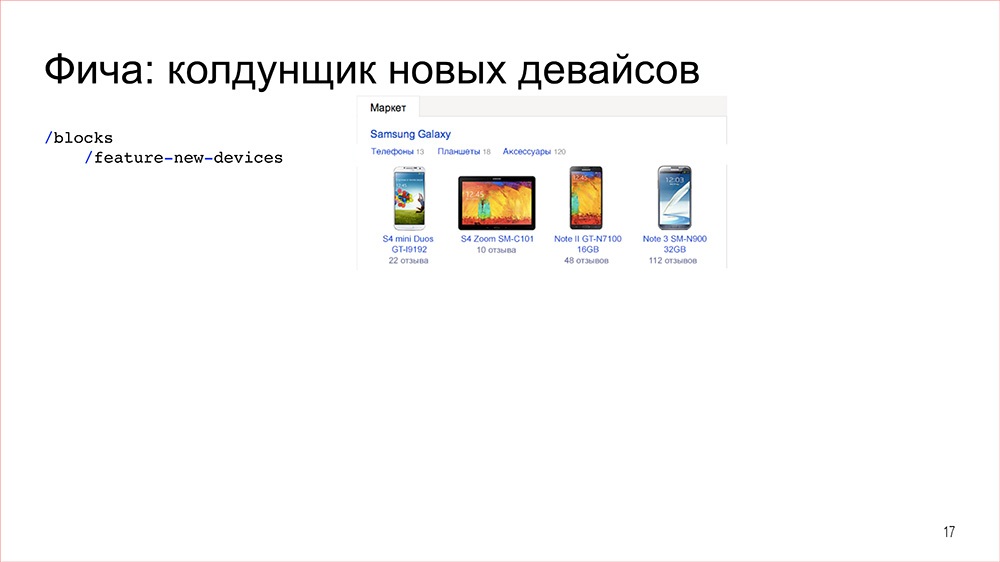
И вот мы прошли этот цикл, у нас в итоге появилась вот такая замечательная фича – колдунщик новых девайсов. Вроде все хорошо, но есть один нюанс: этот цикл, о котором я рассказываю, он достаточно длинный, он занимает порядка двух недель.Можно конечно сказать, что разработчики – раздолбаи, всех уволить. Что тут верстать две недели? Я за день сейчас нафигачу. Но на самом деле это, конечно, не так. На самом деле у нас просто очень серьезные требования к качеству, то есть ничего не должно ломаться: нигде, ни при каких обстоятельствах, на любых данных и так далее. И все это занимает довольно значительное время.
Фичу мы сделали. Что происходит дальше?

Дальше проходит месяц, может больше, и какому-нибудь другому фронтендеру от другого менеджера и дизайнера – не от того, что были в первой задаче, – приходит таска: «Сделай-ка мне фичу – колдунщик одежды. Вот тебе данные, вот тебе макет – вперед, фигач!»
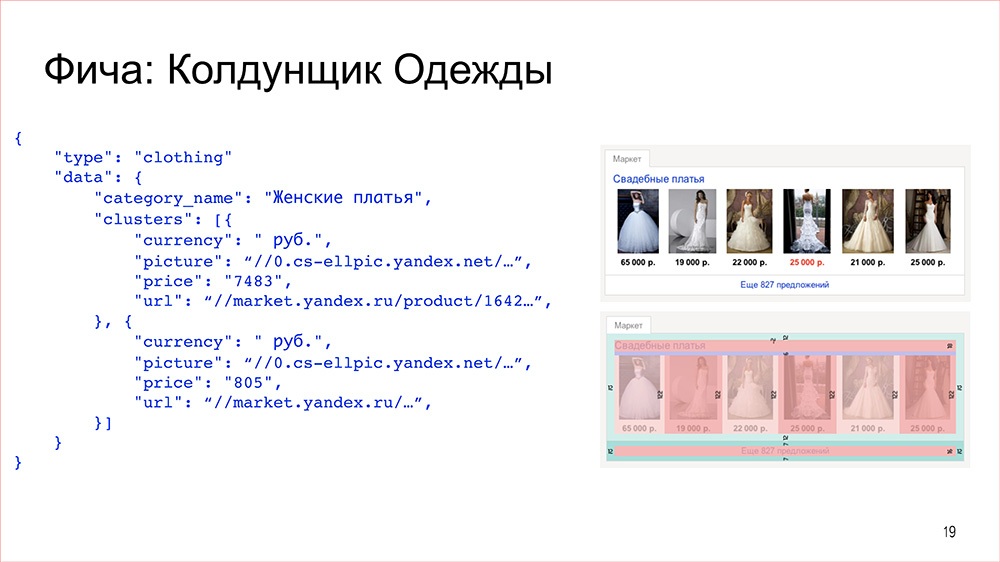
И фронтендер может либо сразу начать делать, либо подумать, что – хм-м – где-то я такую фичу уже видел. Давай-ка я найду исходники, может, найду другого чувака, который ее делал. Потрындим с ним, может, что-то можно вынести в общий компонент и не верстать с начала.
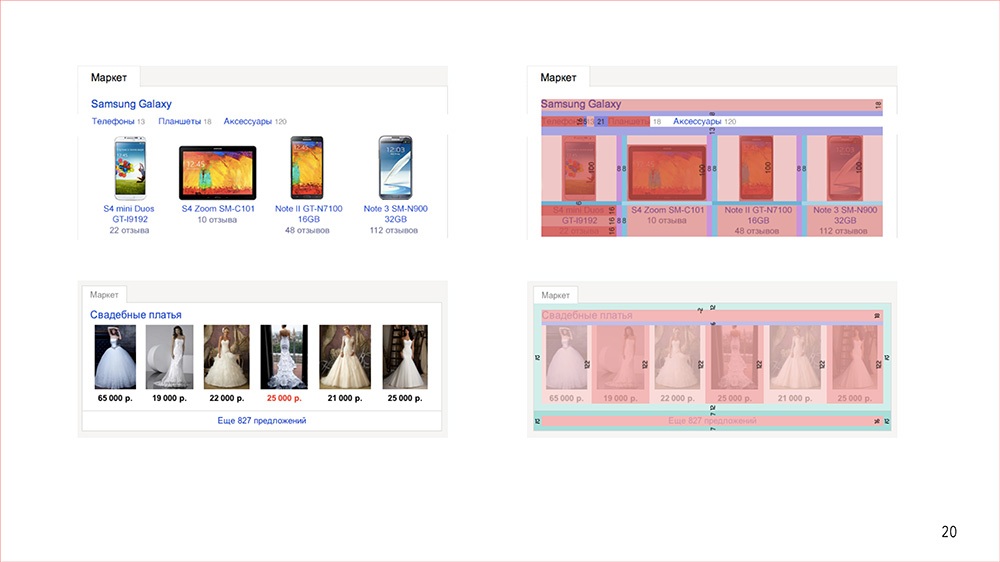
Он эту фичу находит и понимает страшное: не смотря на то, что визуально они, кажется, похожи – а что тут, одно и то же – у них на самом деле в деталях различия просто чудовищные. То есть у них полностью другие спеки, полностью разные. Они в принципе похожи только картинками, но даже подписи под этими картинками разного цвета, из разной информации: в одном случае – цена, в другом – какие-то отзывы светло-синие.Фронтендер на это все смотрит: если выносить это в общий компонент прямо так, то, хрен знает, может через неделю придет еще фича и мне API у этого компонента превращать в черт знает что. И вообще, если все это выносить, надо же и старую фичу перетестировать будет. В общем, как-то все это долго, и наверстаю-ка я лучше с нуля.
Ладно. Берет, верстает.

Я думаю, вы догадались, что происходит дальше.

Дальше приходит менеджер еще разочек.
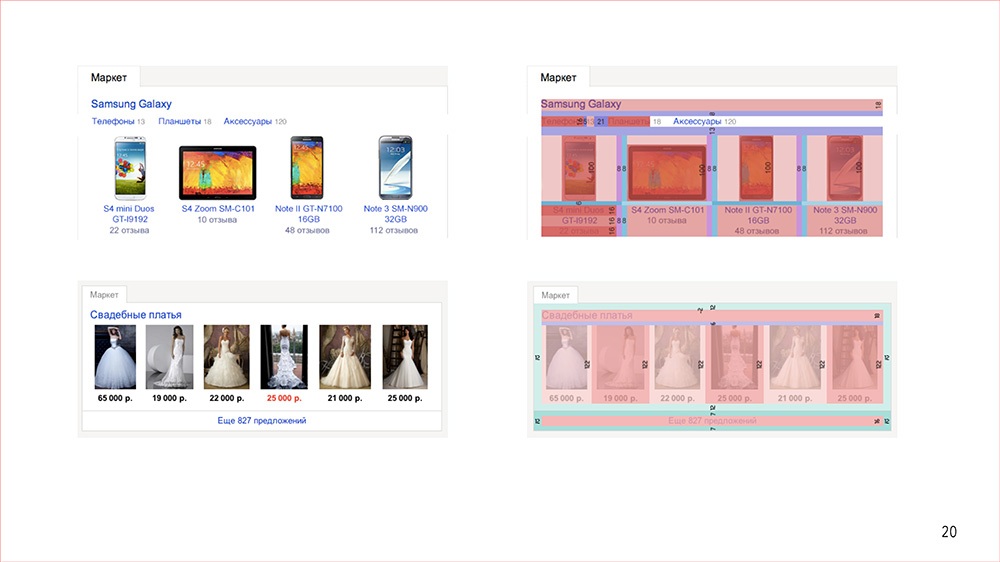
Какой-нибудь, тоже с какой-то фичей.


А потом еще один.

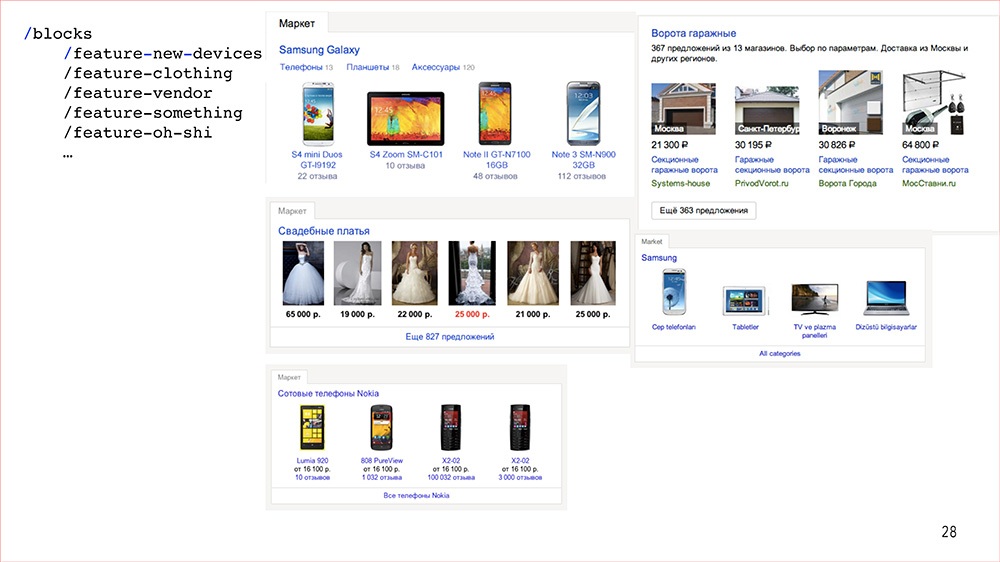
И еще разок.И на каждое из этого мы тратили по две недели.

И мы начинаем стоять примерно с таким выражением лица, типа: «Что за фигня происходит? Кажется тут что-то сильно не так!»

Если попытаться сформулировать проблему менее эмоционально и без ругани, то приходим к следующему.Во-первых, фичи делаются долго и это мягко сказано, хотелось бы побыстрее.
Во-вторых, когда кто-нибудь умный видит, что у нас есть N похожих фичей, ему может прийти в голову – не знаю обратили ли вы внимание или нет, но на тех картинках в пяти фичах цена была написана тремя разными способами, что кажется тоже не очень хорошо, – так вот, когда кто-нибудь это замечает, ему может прийти в голову, а давайте, сделаем тут как-то более-менее одинаково.
А, давайте! Давайте поправим пять версток так, чтобы нигде ничего не сломалось, и приведем их как-то к единому виду хотя бы в каком-то месте, потом все это протестируем. В общем, задачка тоже та еще, очень веселая, но никому такую не пожелаю.

А почему так происходит? Если спуститься на первый уровень этого вопроса, то ответ в следующем: так происходит потому, что не смотря на то, что у нас компонентный подход, все модные технологии, вот это все, – почему-то фичи, которые мы делаем невозможно реиспользовать. Почему-то они одноразовые (не фичи, а компоненты), они под фичу – и все, за каким-то редким исключением.
Если спуститься еще на уровень глубже, и спросить: а почему так происходит? – то можно найти два ответа.
Первый, что разработчики все очень странные, страдают фигней, всех уволить, нанять новых. Но это ответ неправильный.
Правильный ответ в следующем. Есть две проблемы: первая – и она на самом деле небольшая – первая проблема в том, что под каждую фичу данные приходят вообще разные, в смысле вообще совсем. Они приходят в предметной области бекенда, нам нужно их много преобразовывать, как-то ими пользоваться. Короче, это какая-то работа, которая должна делаться уникально под фичу. Ладно, это вроде решаемо.

Вторая проблема сложнее – это дизайн. Дело в том, что под каждую фичу, даже похожую дизайн приходит разный. Причем, зачастую складывается впечатление, что он отличается в деталях не потому что так надо, продуктово оправдано, а потому что «я – дизайнер, я так вижу, я нарисовал – все, верстай». И кажется, что это на самом деле тоже проблема и проблема куда более серьезная.

Примерно с такими мыслями мы пошли к дизайнерам и выяснили, что их такая ситуация тоже парит, но парит она их с дизайнерской точки зрения. Им не нравится, что вот у нас есть SERP, страничка у нас одна, а похожие штуки на ней решаются вообще по-разному, разными способами. То есть они на первый взгляд конечно выглядят одинаково, но если просто отрыть одну фичу и другую – примерно про одно и то же – они будут выглядеть по-разному. И дизайнеров это парит, они хотят консистентности.
В качестве первого шага в верном направлении сами же дизайнеры предлагают: а давайте мы будем начинать делать прототипы, потому что в прототипах сложнее накосячить чем в Фотошопе как-то неосознанно, что-то подвинуть куда-то и так далее.

Плюс, это позволяет нам сделать следующее: если дизайнеры начинают писать код – HTML, CSS – значит они у себя могут выносить какие-то общие штуки в компоненты. Например, если дизайнер понимает, что вот я сейчас делаю несколько картинок в ряд, это решает такую-то задачу и это сто пудов будет полезно другим дизайнерам – он может еще с ними посоветоваться при этом – то он может это вынести в общий компонент, описать что это, зачем это, описать какие штуки в этом компоненте настраиваются, чтобы другие дизайнеры тоже могли его использовать. У нас для таких вот компонент появляется хранилище, которое называется Depot.
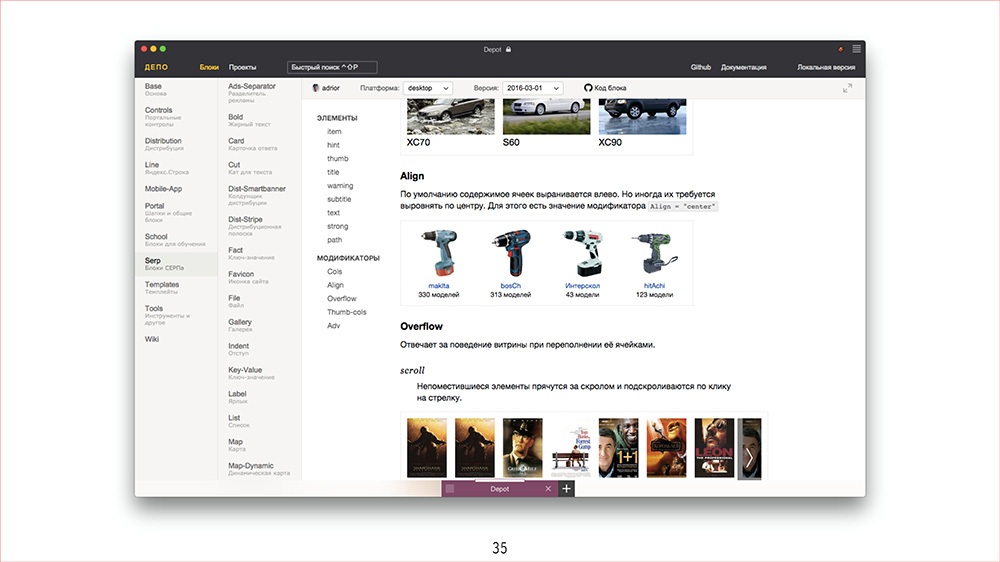
Выглядит оно вот так.Например, тот самый компонент с картинками в ряд, он называется витриной. Дизайнеры теперь уже знают, что у них есть компонент «витрина», и в фичах стараются его реиспользовать. Тут описано, какие поля в нем настраиваются, то есть какое у него API, как его использовать и так далее.

А если у дизайнеров появляются компоненты, то фронтендерам сам бог велел начать делать такую же библиотеку, но уже на production-технологиях: с корректным логированием, под все браузеры и так далее.
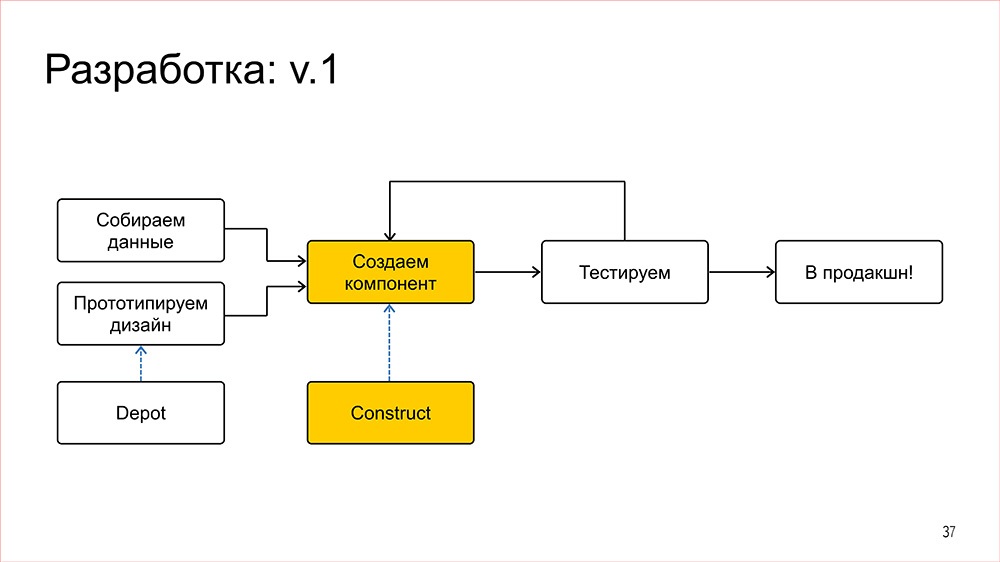
После того как у нас есть прототип и данные, ставится задача на фронтенд, где на основе прототипа мы смотрим, общие там компоненты используются или не общие, если используются общие компонент, то используем либо создаем такой компонент, и вроде как все хорошо. Остальные шаги с тестированием и выкаткой в production не меняются.
Вроде бы уже стало лучше, ну у такого подхода есть некоторая проблема. Давайте, мы на нее сейчас посмотрим.

Предположим, у нас есть такая простенькая фича – колдунщик туров. Где, по сути, голая «витрина» и заголовок. Так как «витрина» у нас уже была сделана в одной из предыдущих задач, как-то протестирована, вероятно неплохо, то мы эту фичу делаем на раз, просто используем «витрину», используем заголовок. Сдаем в тестирование. Тестировщик тоже уже не совсем глубоко смотрит, потому что он знает, что это общий компонент, и он был уже когда-то протестирован. И вроде все это катится в production – тоже быстро, это уже не неделя, это скорее дни, – и вроде все хорошо.

А через день может прийти другой менеджер и задать нам вот такую фичу – «маркет».

Вроде бы тоже «витрина», но есть нюанс. Вообще-то наша «витрина» такого не умеет и фронтендер, который на нее смотрит – на эту задачу – он думает: «Так, ладно. Мне нужно доработать существующий компонент витрины, сдать в тестирование – проверить, что все фичи, которые его используют, не отвалились, заиспользовать это в своей фиче». И… «Тот компонент тебе сделали за два дня,» – говорит он менеджеру, – «а этот я тебе буду делать две недели».

И менеджер начинает выглядеть примерно так: «Чуваки! И тут, и тут общий компонент – мы вроде договаривались о таком подходе, но в одном случае ты будешь его делать два дня, а в другом две недели? Что за фигня?»

И мы такие действительно думаем: «А что за фигня?»И, кажется, происходит это по следующей причине: дело в том, что дизайнерская «витрина» уже успела уйти вперед к тому времени, как на нас поставили эту задачу. Дизайнер конечно сделал фичу на своей версии витрины, мы об этом конечно не знали, и именно в этом наша проблема.

Поэтому мы вводим такой процесс как версионирование и синхронизация.Что это значит? Это значит, что дизайнер, когда прототипирует компонент, – в смысле, прототипирует фичу, используя какие-то компоненты, – возможно, эти компоненты как-то развивает, экспериментирует. Но когда он понимает, что компонент в таком виде хорошо бы попробовать в продакшене – всё, мы готовы им пользоваться, – он ставить этому компоненту версию. А кроме того он ставит задачу фронтендеру по реализации этой версии компонента. Если после этого ему нужно в компоненте что-то изменить – это будет следующая версия.
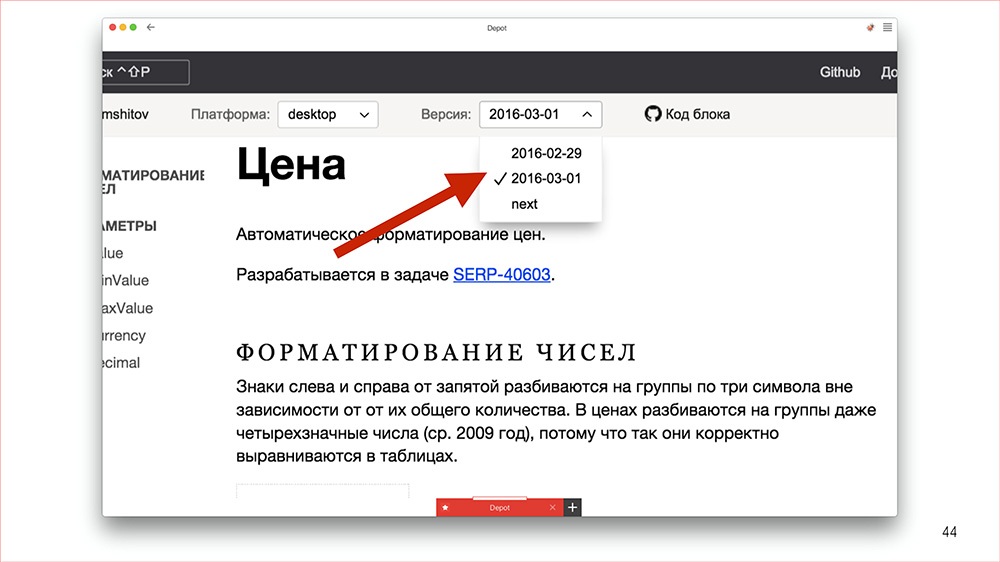
Выглядит это следующим образом.И что нам это дает?
Любой: и менеджер, и дизайнер, зайдя в Depot может увидеть, что компонент такой-то версии уже на верстке есть, и, значит, фронтендер сможет это сделать быстро. Компонента такой-то версии на верстке пока нет, но есть такая задача. Если какому-нибудь менеджеру этот компонент понадобится, то, менеджер, — будь готов ждать. Поэтому в процессе создания дизайна, прототипа для фичи менеджер с дизайнером могут договориться, как надо: быстро или совсем офигительно.
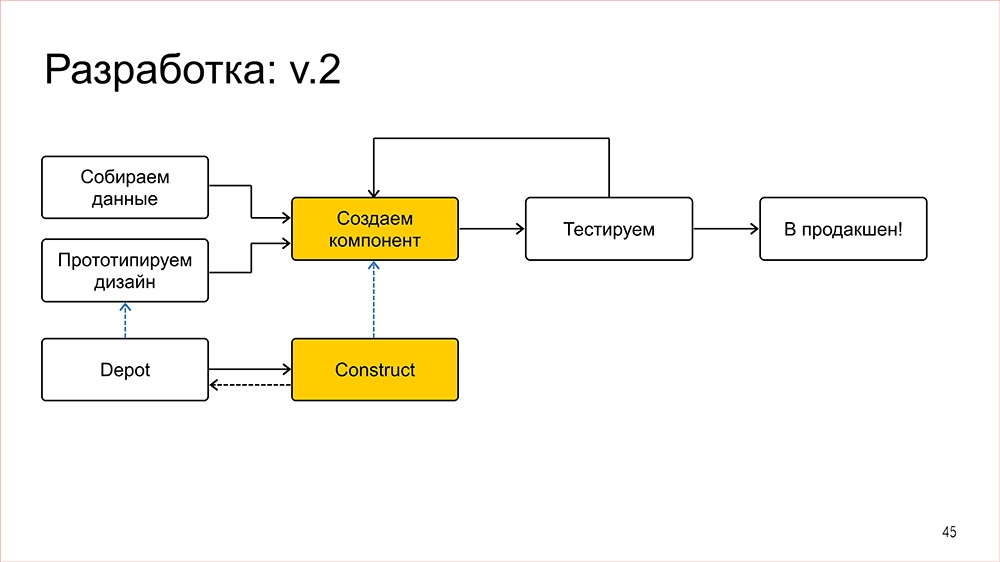
Схема разработки при этом меняется следующим образом. Что делают бекендеры – всем понятно, мы их тут не трогаем. Дизайнеры прототипируют дизайн, попутно вынося общие компоненты в Depot и дорабатывая существующие, проставляют этим компонентам версии, ставят задачи на фронтенд, и в этом месте происходит синхронизация с нашей библиотекой таких же общих компонент, но уже во фронтенде, которая называется «конструктором» собственно. После этого ставится задача на верстку, где мы из общих компонент собираем фичу, при этом и дизайнер, и менеджер на этом этапе уже знают, что все ли компоненты у фронтендеров есть, всем ли мы можем воспользоваться быстро, или придется подождать.
Кстати, мы выложили в открытый доступ видеозаписи последних двух лет конференции фронтенд-разработчиков Frontend Conf. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
Собираем фичу, сдаем в тестирование, катим в продакшн. Вроде все круто теперь уже, но мы были бы не мы, если бы не пошли еще дальше.

Я тут говорю, что дизайнеры выносят общие компоненты в Depot. А давайте подумаем, какие компоненты вообще могут быть не общими? Серьезно.
И мы для себя на этот вопрос ответили следующим образом: на самом деле все компоненты общие. Даже если у тебя какая-то штука сейчас используется один раз, всё равно хорошо бы тебе ее описать, – тебе как дизайнеру, – чтобы другие дизайнеры поняли, зачем ты ее вообще придумал, что она делает, и может быть, через каких-нибудь пол-года она кому-нибудь понадобится и он сможет ее либо так использовать, либо доработать и использовать. Это раз.
Кроме того у нас есть такие большие компоненты, как лейауты, которые говорят, что сверху у тебя заголовок, под ним тумба, справа от тумбы текст, под текстом у тебя «витрина» и так далее. Это тоже в большинстве своем какие-то устоявшиеся конструкции, которые тоже хорошо бы описать, описать как и когда их использовать и, собственно, использовать.
Что дает нам такой подход?

Дает он нам следующее. Если у нас все компоненты общие, то что у нас остается на реализацию непосредственно компоненты под фичу? Что она делает? Оказывается, что при таком подходе компонента под фичу должна делать ровно одно: преобразовывать данные, пришедшие в формате бекенда, в формат, который понимает API компонент «конструктора», зачастую лейаутов, как компонент самых крупных.

Раз так, то компоненты под фичу вырождаются в, по сути, адаптер. Что такое адаптер?

В нашем случае это чистая функция. Если у вас какой-то фреймворк, это может быть что угодно, но важно следующее: важно что адаптер никак не влияет на окружающее, то есть в нем нет ни CSS, ни JS клиентского – вся эта логика реализована в компонентах; адаптеры друг друга не реиспользуют, и адаптеры не зависят друг от друга тоже. Кроме того один адаптер пишется строго под одну фичу.
Ограничений, кажется, много, но они особо не мешают, а дают нам следующее потрясающее следствие, что если ты правишь какой-то существующий адаптер, самое худшее – если все совсем плохо, – что ты можешь сломать, – это одну конкретную эту фичу – все. Гарантированно ничего вокруг ты не сломаешь, потому что у тебя нет в нем ни клиентской логики, ни клиентских стилей. От этого адаптера гарантированно никто кроме этой фичи не зависит просто по постановке задачи, и так далее.
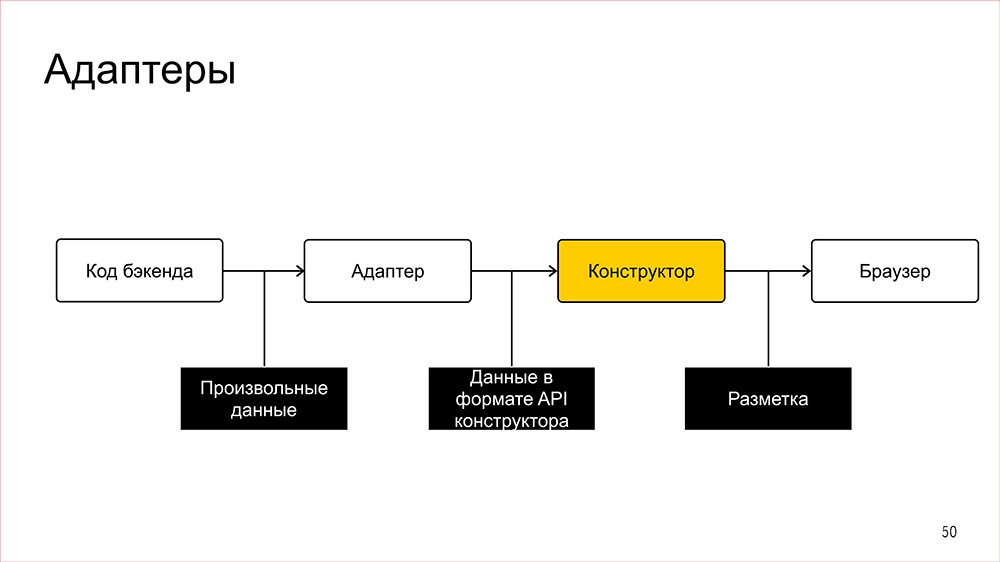
Если показать это на картинке, то вся схема выглядит следующим образом.У нас есть код от бекенда, который передает просто «что-то». На это «что-то» натравливается соответствующий адаптер, который на выходе говорит, каким компонентом эту фичу рендерить, и что подавать на вход в этот компонент. После этого это все попадает в «конструктор», который уже генерит разметку, и эта разметка уходит в браузер пользователя.

Это нам дает следующее, тоже как мне кажется офигительное, следствие: у нас есть компоненты в библиотеке и все компоненты у нас общие, а еще у нас есть адаптер. И при таком подходе получается, что разработка компонент и разработка фич на основе этих компонент – это на самом деле раздельные процессы.
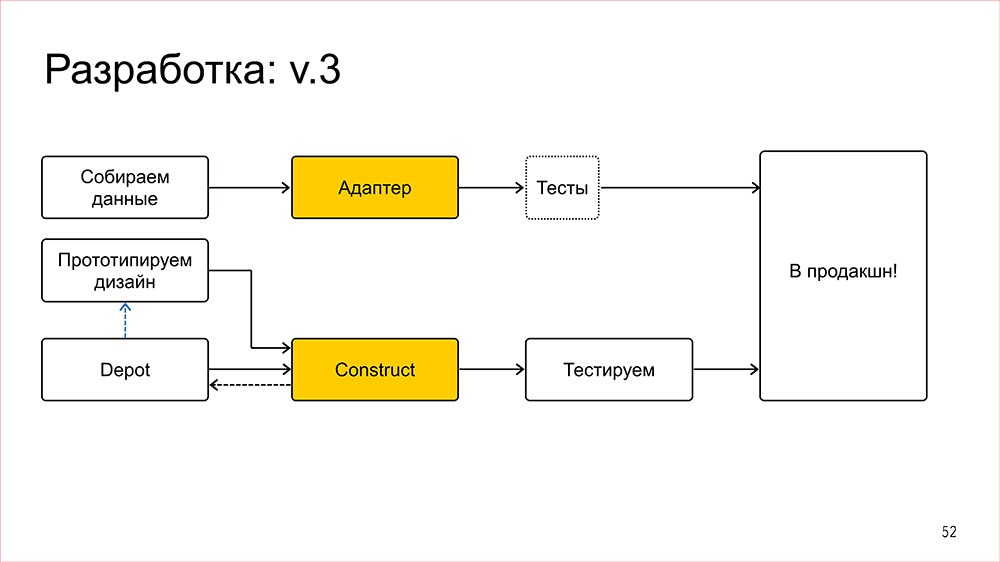
В некоторых точках они могут быть для некоторых фичей слабо связаны, но в целом выглядит это вот так. То есть дизайнеры развивают существующие компоненты и создают новые, развивают визуальный язык SERP и вот это вот всё. Когда дизайнер понимает, что эта компонента готова для использования в продакшне, он фиксирует ей версию. Мы по договоренности с менеджерами эту версию реализуем, тестируем на всех крайних случаях, в любой ситуации делаем так, чтобы компонента работала хорошо. И катим в продакшн, отдельно. А если нам нужно сделать фичу – мы просто берем и пишем адаптер. Так как адаптер гарантированно не влияет ни на что вокруг, ничего не может сломать и так далее, и использует те компоненты, которые уже хорошо протестированы, то тестирование адаптера – это задача по сути тривиальная. То есть нужно просто проверить, что на вот этих бекендовских данных всё продуктово выглядит плюс-минус хорошо – и все, и это тоже катится в продакшн. Причем вот эта верхняя ветка процесса, она действительно чертовски быстрая.

А теперь другой интересный вопрос: если адаптеры такая простая штука, занимаются только преобразованием данных, ничего не могут ломать, то на фига нужна фронтендерская квалификация, чтобы их писать?

И мы такие подумали, и подумали, что она действительно не нужна.Пусть адаптеры пишут те, кому это больше всех нужно, то есть менеджер, который ответственен за фичу, или аналитик, которому эта фича очень нужна.

Но как этого добиться? Есть одна маленькая проблемка: не все менеджеры, не все аналитики умеют в git, умеют в наш flow, умеют коммитить в репозиторий, делать pull-request и так далее. Но мы очень ленивые, поэтому нам хотелось все-таки, чтобы менеджеры это делали, поэтому мы себя пересилили и сделали следующее.

Во-первых, мы сделали для них веб-морду, через которую они могут этот адаптер написать, подключив туда реальные данные, которые ему намайнил бекендер.

Кроме того мы сделали для них сайт с документацией, потому что мы-то конечно можем залезть в исходники, посмотреть API нашего компонента, но менеджеры же ленивые и git не очень любят, поэтому им нужен отдельный сайт.

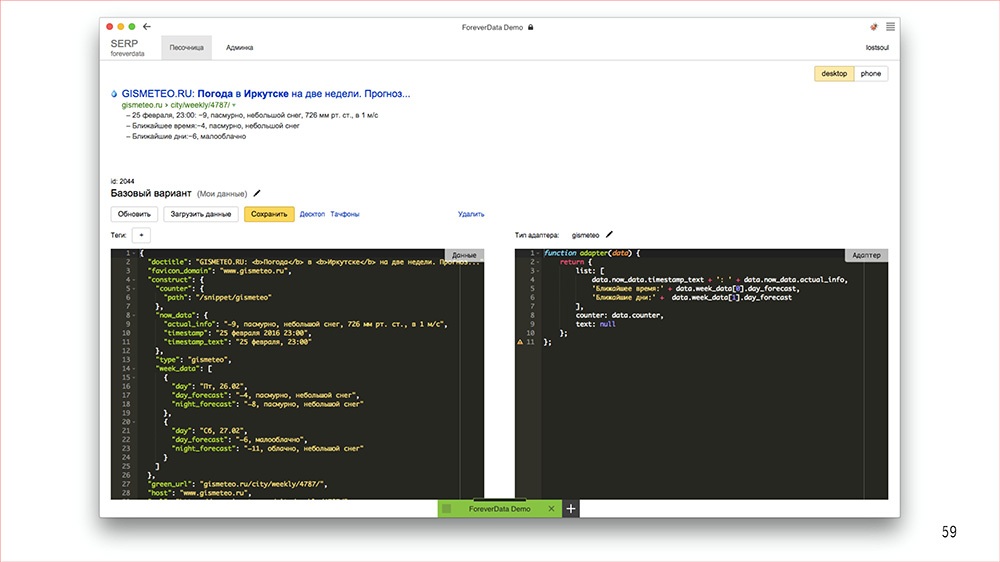
Выглядит это следующим образом. Веб-интерфейс выглядит вот так – просто для примера. Слева там плюс-минус реальные данные из бекенда, справа какой-то тривиальный адаптер, а вверху live-preview: как фича менеджера будет выглядеть в продакшне. Единственное, пожалуй, чего не хватает, это кнопочки «сдать в тестирование», но мы сейчас над этим работаем.

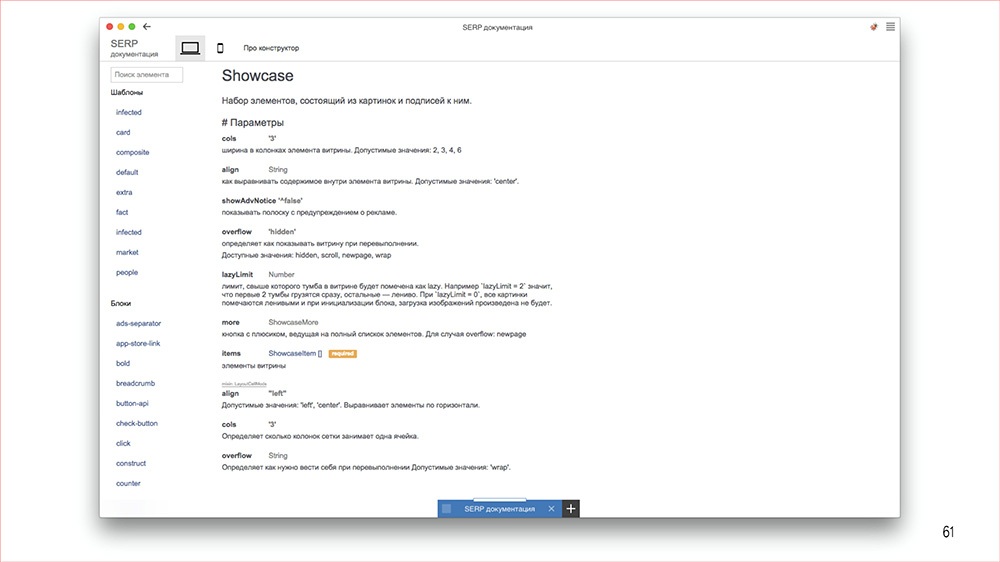
Кроме того у нас есть документация.Про нее я подробно рассказывал на каком-то из MoscowJS. Сейчас еще раз упомяну, что это все сделано на открытых технологиях. Есть JSDoc 3, который офигенно кастомизируется. Это уже, наверное, третья версия документации, но с каждым шагом мы все больше приближаемся к нашему идеалу. Даже сейчас ей уже можно вполне пользоваться, чем все и занимаются.

Собственно, к чему мы в итоге пришли?

Мы пришли к тому, что вместо недель, о которых я говорил в начале доклада, фичи делаются за часы или за дни – все-равно чертовски быстро. Кроме того они делаются зачастую даже не нами, а менеджерами или аналитиками. Например, у нас не так давно был кейс, когда нам пять новых колдунщиков-тире-фичей нафигачил аналитик. Раньше о таком можно было только мечтать.Кроме того мы «бесплатно» – ну как «бесплатно»… – мы получили полную синхронизацию с дизайном и полную консистентность в дизайне. Так как все фичи используют общие компоненты, причем все компоненты строго общие, когда ты одну компоненту обновляешь, процесс это конечно достаточно тяжелый, если компонента много где используется, зато гарантированно весь SERP будет консистентный. Просто по архитектуре, по постановке задачи. И это тоже очень круто.
И бонусом мы получили то, что теперь и менеджеры, и дизайнеры, и мы работаем в одних терминах: все знают, что у нас есть компоненты, из которых строятся фичи; а чтобы построить фичу, все знают, что нужно написать адаптер, который такая простая штука – преобразовывает данные.
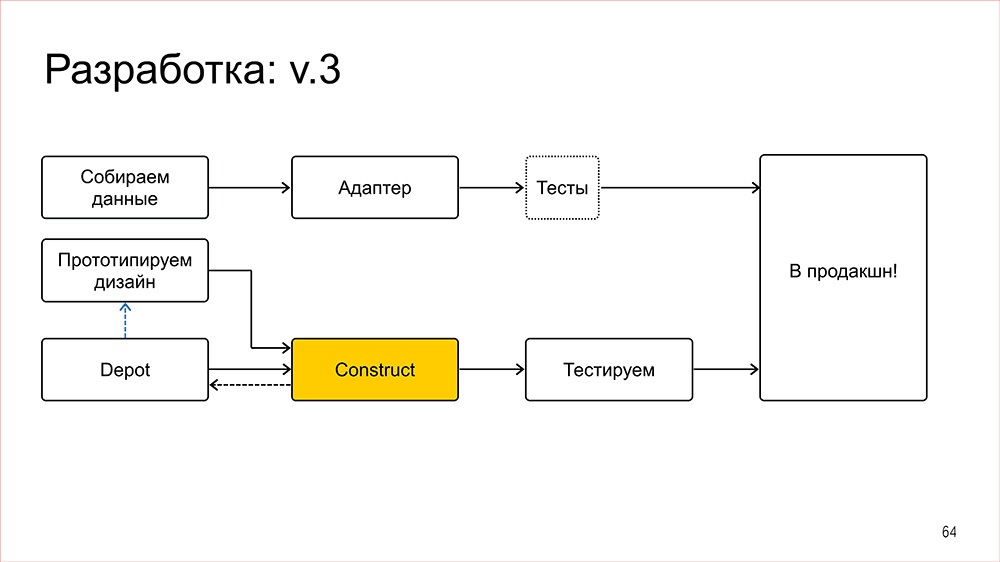
Собственно, схему подробно расписывать у меня уже нет времени, но она драматически отличается от того, что я показывал в начале. Основная фишка в ней следующая: что разработка компонентов и разработка фич на основе этих компонентов – это отдельные процессы. Причем разработка фич, если фича у тебя не какая-нибудь мега-требовательная, – процесс очень быстрый.

Решения, которые мы приняли по ходу.Во-первых, дизайнеры вместо макетов начинают делать прототипы.
А раз они делают прототипы – какие-то части этих прототипов они могут выносить в общие компоненты.
А раз у дизайнеров есть общие компоненты, то нам и подавно хочется сделать себе то же самое, то есть общие компоненты появляются и у нас.
Кроме того мы сделали версионирование компонент у дизайнеров и синхронизацию дизайнерских компонент с нами.
А еще мы поняли, что вообще-то все компоненты у нас общие, а раз так, то разработка фичи – это по сути написание простого адаптера по преобразованию данных, который на основе этих компонент и строит фичу.
А раз так, раз у нас есть разработка адаптеров и компонент, кажется, эти процессы на самом деле не всегда связаны, поэтому их можно вынести в раздельные процессы. То есть отдельно развивать компоненты – отдельно разрабатывать фичи.
И кроме того разработка адаптеров процесс простой, а мы ленивые, поэтому мы сделали так, что адаптеры разрабатываем не мы.
Собственно, к чему я всё это?

К тому, что вы можете использовать наш опыт. Начиная от каких-то тривиальных выводов в духе, что если для того, чтобы драматически ускориться, вам нужно полностью изменить весь процесс для кучи людей, а вы сейчас боитесь это сделать – не бойтесь. Даже в Яндексе получилось. При том, что у нас очень-очень много людей, очень большое число человек пришлось научить делать по-новому, но мы справились. А раз мы справились, значит и вы, скорее всего, тоже справитесь.Кроме того вы можете использовать какие-нибудь из наших абстракций – из наших фишек, которые мы придумали, – у себя в проекте. Например, как мне показалось, идея с адаптерами она достаточно крутая и может прижиться даже в тех системах, о которых я, придумывая это, даже и не думал. Подумайте на этот счет, возможно, она вам пригодится.
Кроме того вам может пригодиться отношение к проекту как к набору общих компонент, причем реально общих. Либо, возможно, вы сможете убедить дизайнеров начать делать прототипы, или даже сделать для них Depot. В общем – что угодно.
Скорее всего, каждый из этих шагов, будучи применённым в нужном месте, принесет вам профит.
Кроме того если у вас специфика работы такая, что вы делаете много фичей на основе разных данных, но у фичей визуально есть какое-то родство, – то есть они не полностью уникальные в каждом конкретном случае, – возможно, вы можете взять наш процесс целиком. Это конечно будет немного сложно, но профит принесет вам тоже, как это принесло профит нам.
В общем, на этом наверное – всё.
Можно хлопать, радоваться и задавать вопросы.
ВОПРОСЫ И ОТВЕТЫ
Вопрос:
Адаптеры, которые пишутся не фронтендерами, – они проходят какое-то code review? И как много говнокода появляется в адаптерах?
Ответ:
Смотри, сейчас они какое-то code review проходят, но мы хотим осознанно от этого отказаться.
Почему? Потому что, как я уже сказал, по условию адаптеры ни на что вокруг себя не влияют. А раз так, то скорее всего, тот человек, который адаптер создавал, или тот отдел, в общем, те люди к которым он относится, – скорее всего, они будут его изменять и впоследствии. Значит, им работать ровно с тем, что они написали. Им – не нам. И отсутствие такого code review – оно на самом деле позволит этот процесс ускорить. Сейчас он еще немного завязан на нас, потому что, как я уже показывал, нет кнопки «сдать в тесты». Но когда мы все это сделаем, мы хотим вообще дистанцироваться от всего этого, просто, типа: пишите, нам более-менее все-равно.
Но тестировщики это проверять конечно все-равно будут, просто just in case.
Вопрос:
У меня два вопроса. Первый: как долго у вас заняло сделать всю эту экосистему вокруг компонентов, адаптеров – до конца? Второй: используют ли ваши дизайнеры git?
Ответ:
Отвечу по порядку.
Заняло довольно до хрена времени, то есть у нас на это ушло года наверное полтора, может чуть больше. Но у нас очень много людей, поэтому изначально, например, вообще казалось, что этот процесс может и не сойтись. Но мы справились – все круто!
А во-вторых, дизайнеры у нас на самом деле люди офигительные. Я их безмерно уважаю, не только потому что они git используют. Я кому-то, по-моему, уже говорил – я знаю дизайнера нашего, который знает Haskell и на нем пишет, поэтому там серьезные ребята очень.
Вопрос:
У меня вопрос по поводу прототипов. Скажите пожалуйста поподробнее: что в них входит, что они из себя представляют и что вы заставили делать дизайнеров? Потому что, если я сейчас к дизайнеру подойду и скажу: «Тебе надо верстать код,» – то он истерически просто посмеется.
Ответ:
Смотри, нам в этом плане на самом деле очень повезло с дизайнерами, потому что ребята, которые у дизайнеров главные, – они технически подкованные люди, то есть их HTML-CSS не пугает, например.
Изначально была идея, чтобы хотя бы HTML и CSS писали, а что не могут сделать, описывали словами. Но в итоге в какой-то момент, когда мы пришли к дизайнерам, у них уже появился, вообще говоря, свой фреймворк реактоподобный – они написали и сделали на нем свои прототипы. В общем, они ребята какие-то чудовищные просто. Они просто взяли – ok – код так код, сделаем, всё.
На самом деле я понимаю, что не все дизайнеры такие, но прямо в базовом условии хватит, чтобы это была какая-то HTML-ка просто с CSS-ом. И если дизайнер какую-то фишку сделать не может – пусть словами опишет просто, но важно, что в централизованном месте. Чтобы другой дизайнер мог прийти посмотреть – ага, ведет себя так-то.
Примерно так.
Вопрос:
Предыдущий вопрос был близок, если я правильно понимаю, то в Depot у вас хранятся прямо уже готовые HTML-куски, которые можно использовать. То есть дизайнеры по сути их сами готовят?
Ответ:
По сути – да. У нас все немножко еще круче, – я как бы не стал в это вкладываться, – там на самом деле хранятся не HTML-куски, а прямо шаблоны, которые дизайнеры могут использовать, причем шаблоны дизайнерские: написанные дизайнерами для дизайнеров. Но HTML-куски в этом месте тоже бы подошли. Да, действительно, дизайнер может зайти в этот сервис – я сейчас попробую промотать туда, где он был, – в общем дизайнер может зайти в этот сервис и посмотреть, какие компоненты есть. Зайти, и информации, которая в этом сервисе есть, ему хватит, чтобы этот компонент заиспользовать, и чтобы понять как он себя ведет.
Тут у нас не видно конечно ни фига, но есть список компонентов. Дизайнер смотрит и так далее.
Вопрос:
Второй вопрос: если все, любые, даже самые мелкие сущности выносятся в общие элементы, то как происходит их структуризация? Потому что там от кнопок конкретных, значков, пикселей можно утонуть будет.
Ответ:
Согласен. Смотри, пока это все лежит плоским списком, но есть два «но» больших.
Первое – у нас есть БЭМ, благодаря которому у нас, например, нет двадцати вариантов кнопок – у нас есть одна кнопка с гибко настраиваемым поведением, то есть у нее есть темы, у нее есть какая-то кастомизация, и он нас в этом месте спасает. Хотя иногда действительно дублирование такое происходит, но мы стараемся от него избавляться.
И во-вторых, действительно, сейчас мы хотим разбить это на два списка, но правда, всего лишь на два. В первом будут хранится такие железобетонные компоненты, которые уже прошли проверку временем, их реально все используют, короче, штуки, которые сложно и дорого править, но они затронут очень много народу. А во втором – те самые компоненты, которые используются один-два раза и в перспективе могут вырасти в первую категорию.
Вопрос:
И, соответственно, с того момента, как вы перешли от макетов к прототипам, вы, получается, отказались от понятия pixel perfect, правильно я понимаю?
Ответ:
И да, и нет. С одной стороны, понятно, что мы не открываем две картинки в Фотошопе и не смотрим: так, что тут происходит? Но с другой – мы пока к этому не пришли, но активно идем, – так как все компоненты – они в любом должны быть очень близки, и и мы, и дизайнеры используем пусть разный код, но один и тот же набор компонент. Просто, тоже по условию, наши компоненты не могут сильно отличаться, и в этом месте, кажется, все хорошо, – то есть там не pixel perfect, но близко к этому.
Если же у нас в компонентах появятся драматические различия, мы в какой-то момент скорее всего огребем, поэтому мы стараемся от этого избавляться.
Вопрос:
То есть тестировщики в основном проводят такое больше функциональное тестирование?
Ответ:
Компонент на продакшне – да, а в дизайнерские компоненты смотрим только мы, и стараемся реализовывать похожим образом. То есть если, например, у дизайнера сверстана таблица каким-нибудь div c «display: table;», и если у нас нет каких-то возражений, мы делаем так же, чтобы впоследствии при развитии и нам, и им развиваться было примерно одинаково дорого или дешево.
Вопрос:
Вы советовали нам попробовать внедрить ваш опыт, а какой вы использовали для этого инструментарий? Вы там написали наверняка кучу «велосипедов» своих, да? Сколько это будет стоить, если я захочу внедрить это у себя в компании?
Ответ:
Тут смотри, в чем дело, тут дело не в конкретных технологиях, – что тебе нужно взять этот «велосипед» и поставить его у себя, – тут дело в подходе. Даже в тот момент, когда ты начнешь думать о проекте не как: вот у меня есть страница, и мы ее как-то верстаем, – и вот это вот всё; а как реально о наборе компонент, готовых для реиспользования – что бы вы там не использовали, я не знаю, табличку в Excel, например. Это уже скорее всего может вам принести какую-то выгоду.
Вопрос:
Нет, но вот ты рассказывал про то, что менеджер может зайти, там удобно, чуть-ли не сам написать адаптер. Эту систему разрабатывали – сколько получается? Если я подобную захочу внедрить?
Ответ:
Вот эта система на самом деле достаточно дешевая. Самым дорогим было движение в сторону этого подхода. Это сейчас после рассказа каждый шаг кажется очевидным и понятным – а что тут делать? На самом деле, когда мы про это все думали, было до фига вариантов и, в общем, то к чему мы пришли нам в принципе нравится – это самое ценное.
Вопрос:
Но каких-то готовых решений в Интернете нет, которые можно заюзать? И вы не выкладываете?
Ответ:
Я, боюсь, не могу вам их предложить, просто потому что у нас стек технологий свой. То есть даже если бы эти решения были, они были бы для БЭМ-стека, что скорее всего вас не устраивает. Поэтому тут, к сожалению, нет.
Вопрос:
Как вы заставили менеджера захотеть самому создавать эти компоненты, вернее их компоновать, писать эти дескрипторы?
Ответ:
Очень просто! Дело, смотри, в следующем. Дело в том, что работы у фронтендеров до фига, и когда к тебе приходит менеджер и говорит:
– Через сколько ты сможешь сделать эту задачу?
– Ну, у нас там еще какой-нибудь проект на две недели, и потом может быть еще что-нибудь, и может быть недельки через три я сяду-таки до твоей задачки и буду делать ее пол-дня. А можешь – вот у тебя есть веб-инструмент – возьми да сейчас сам сделай.
С точки зрения менеджера выбор понятен, мне кажется.
Вопрос:
Вопрос в том, что с адаптером – понятно. Этот компонент надо потом куда-то вывести, то есть нужно определить место и как он вызывается и так далее. Как это происходит? Кто это делает?
Ответ:
Смотри, в нашей специфике, именно нашего проекта, место у нас достаточно понятное. У нас есть обвес в виде шапки, левой колонки, футера – это все понятно. А внутри есть список, который просто проходится по тому, что прислали данные: они нам присылают массив с объектами, в которых по сути указан только тип, – по сути тип источника, – и кроме этого может быть вообще любая хренота. Собственно в этом месте у нас вызывается механизм адаптеров, которые эти данные преобразуют и скармливают на вход тоже механизм вот этого «конструктора» – он выбирает правильный компонент, вызывает его с нужным API, возвращает HTML, и элемент один под одним рендерится.
Вопрос:
А вот эти данные, которые определяют структуру, – они на чьей стороне хранятся, и кто их правит?
Ответ:
Смотри, данные, которые определяют, что этот результат выдачи будет под этим, а не наоборот – это на бекенде, потому что у нас есть понятие ранжирования. Все это машинное обучение, вся фигота. А в рамках одного компонента кто определяет, что типа текст по таблицей, а не наоборот, – это может определять либо компонент лейаут, если он достаточно жесткий, либо, если компонент лейаут достаточно гибкий, может определить сам менеджер в адаптере. В рамках одной фичи у него свобода.
Вопрос:
То есть появляются данные от бекенда, смотрится если есть адаптер, то это выводится. Если нет – то…
Ответ:
Если нет, то – упс! – ничего не выводится.
Вопрос:
Спасибо большое за доклад. Очень интересно, причем очень знакомо, потому что в компании мы несколько раз использовали практически идентичный подход к разработке. Но вопрос даже не про технологии, а существует такая насущная проблема: то что пока разрабатывается этот движок, генератор, и все чудесно работает, но возникает такой момент, когда технологии устаревают, и его нужно переписывать. Собственно, это иногда вообще ставит под сомнение со стороны менеджеров вообще в принципе этот подход. Вопрос в том, насколько много ресурсов у вас уходит на поддерживание актуальности технологий и их обновление.
Ответ:
Смотри, если я правильно тебя понял, это вопрос немножко про другую область. То есть на каких-бы технологиях это ни реализовать – оно скорее всего все-равно будет работать. Обновление технологий – это какой-то параллельный процесс. Он происходит параллельно с этим движением. Я не могу сейчас тебе даже сказать сколько ресурсов, но какие-то уходят: мы постоянно что-то меняем, постоянно развиваем шаблонизаторы, то – сё. Но, кажется, что в рамках этого проекта, это не драматически влияет. То есть я не могу понять, как это связано.
Ответ ведущего:
Мы с Денисом уже обсуждали эту штуку. И там конкретно в Яндексе, они использовали такую странную штуку, как BEM-JSON, и у них все шаблоны были, собственно, вот в этом джейсоне таком. Это сложно, не понятно зачем эта штука была нужна, она такая вся страшная.
Реплика докладчика:
Я тебе расскажу после доклада – хорошая штука.
Ответ ведущего:
А потом оказалось, что, знаете, можно технологический стек внутри поменять, а этот JSON полностью оставить. И то же самое, они могут на сайте взять и фреймворк поменять, который там view рендерит, – на React заменить или на еще что-то. А вот вся эта простыня, весь бекенд, – это все остается тем же самым. В данном случае, конкретно к проекту, – легко заменяется.
А переписывать вот эту вещь тоже наверное не сильно сложно, тут куча отдельных инструментов маленьких, – взял его и переписал под новый стек, допустим. С этим у них все хорошо, мне кажется.
Вопрос:
Вы говорите – 30 разработчиков на фронтенде, вы написали такую штуку крутую. Теперь вместо двух недель – часы и дни занимает. Но при этом вы говорите, что все-равно такая загрузка, что менеджеров даже заставили делать адаптеры. А чем тогда сейчас занимаются эти 30 разработчиков на фронтенде?
Ответ:
А! Легко! Легко! Самое важное забыл рассказать.
Сейчас, пока проект – его внедрили, он уже выкачен в production. Сейчас на самом деле я тоже прогнался только по верхам, это заняло у меня 35 минут. В каждом из мест есть какие-то нюансы, какие-то проблемы, которые стоит дорабатывать. Собственно, сейчас мы занимаемся этим. Плюс, сейчас есть какие-то уникальные штуки в уникальных местах и часть ребят занимается именно ими.
Но когда это все внедрится, в смысле, совсем в умы всех менеджеров, когда все менеджеры реально, типа, как сделать фичу: ну я сейчас пойду адаптер напишу – это сразу просто.
Тогда действительно не понятно, чем будет заниматься такая толпа людей, и это меня немножко беспокоит.
Вопрос:
Вот эта вся штука внедрена сейчас в SERP, правильно? То есть на одной странице, на одной поисковой выдаче? А планируется ли как-то масштабироваться, то есть на другие проекты, соседние, еще как-то?
Ответ:
Отчасти планируется, но вопрос такой на самом деле – очень по теме и достаточно сложный.
Хотелось бы отмасштабироваться, да, без вопросов – но… Этот подход с общей библиотекой – он очень хорошо работает именно, когда проект у тебя один и большой, потому что это по сути папка в проекте. Тебе нужно поправить компонент – ты правишь, все, тут все хорошо. Если это реально выносить в отдельный гитовый репозиторий, если у вас не какой-нибудь Perforce, который с этим хорошо справляется, – то очень просто огрести сложности именно в этом месте за счет очередей, за счет конфликтов, за счет того, что тебе банально нужно ревизию зафиксировать, а там разные люди фигачат, это все по-разному тестируется. В общем, тут могут начаться проблемы.
Мы в эту сторону смотрим. Пока не думали, как их решать. Возможно, решим, и, возможно, я про это тоже расскажу, но пока это живет в рамках одного проекта. Мы сейчас это активно дорабатываем, и вот это вот все.
Ответ ведущего:
Еще и стек технологический на разных проектах немного может отличаться.
Ответ:
Может, может, да. Но можно было бы хотя бы в схожих внедрить, но там тоже из-за – непонятно просто, как всем одновременно коммитить в одну библиотеку, – то есть у нас наших тридцать, а еще там со всех остальных проектов, при этом никому ничего не сломать, потому что экспертиза у каждого чувака есть только в рамках своего проекта.
В общем, это интересная задача, возможно, мы ее решим, возможно, я расскажу про это.
Ответ ведущего:
Через год увидимся, и нам расскажут как это получилось.
Ответ:
Это плохо работает, потому что если у тебя все компоненты общие, то это отдельная команда, это и будет «всеми разработчиками» или большей их частью. Потому что кроме компоненты и инфраструктуры пилить больше нечего.
Вопрос:
Давай два вопроса, первый: сколько всего людей работало над всеми этими штучками, чтобы дизайнеры понимали, менеджеры, кто там у вас – все-все? И чем-то это похоже на Ucoz, только без рекламы, мне кажется, нет?
Ответ:
Первое – сколько человек работало. В самом начале это был один фронтендер – это я, дизайнер и два менеджера. В какой-то момент команда разрослась до аж пяти или четырех фронтендеров, – в момент, когда это все прям активно-активно пилилось, прям все сразу. Сейчас в команде, которая занимается кором, три человека, именно три фронтендера, про дизайнеров и бекендеров, ну один дизайнер. Сколько бекендеров за всем этим стоит, я честно говоря не знаю.
И сейчас у нас активные работы – это всех научить все делать правильно. То есть ребята уже свыклись с мыслью, что да, так надо, но есть какие-то еще накладки за счет того, что тупо у нас там в сумме это повлияло на человек за сотню наверное, – очень много. Сейчас мы занимаемся примерно этим.
То что это похоже на Ucoz – да, примерно так. Это очень похоже на CMS, только я не думаю, что в разрезе такого проекта кто-то думал, что похожий подход вообще применим. А он применим так внезапно. Что круто.
Контакты
»
lostsoul@yandex-team.ruЭтот доклад — расшифровка одного из лучших выступлений на профессиональной конференции фронтенд-разработчиков Frontend Conf.
С этого года мы решили выделить секцию "Архитектура фронтенда" в отдельный трек на конференции разработчиков высоконагруженных систем HighLoad++. Мы приглашаем докладчиков и слушателей!