Как я учил змейку играть в себя с помощью Q-Network
- пятница, 30 августа 2019 г. в 00:33:28
Однажды, исследуя глубины интернета, я наткнулся на видео, где человек обучает змейку с помощью генетического алгоритма. И мне захотелось так же. Но просто взять все то же самое и написать на python было бы не интересно. И я решил использовать более современный подход для обучения агентных систем, а именно Q-network. Но начнем с начала.
В машинном обучении RL(Reinforcement Learning) достаточно сильно отличается от других направлений. Отличие состоит в том, что классический ML алгоритм обучается уже на готовых данных, в то время как RL, так сказать, сам создает себе эти данные. Идея RL состоит в том, что помимо самого алгоритма, который называют агентом, существует среда(environment), в которую этот агент и помещается. На каждом этапе агент должен совершать какое-то действие(action), а среда отвечает на это наградой(reward) и своим состоянием(state), на основе которого агент и совершает действие.
Здесь должно быть объяснение того, как алгоритм работает, но я оставлю ссылку на то, где это объясняют умные люди.
После того, как мы разобрались c rl, надо создать среду, в которую будем помещать агента. К счастью, изобретать велосипед не требуется, тк такая компания как open-ai уже написала библиотеку gym, с помощью которой можно писать свои энвайронменты. В библиотеке их уже имеется в большом количестве. От простых atari игр до сложных 3d моделей. Но среди всего этого нет змейки. Поэтому приступим к ее созданию.
Я не буду описывать все моменты создания энвайронмента в gym, а покажу только основной класс, в котором требуется реализовать несколько функций.
import gym
class Env(gym.Env):
def __init__(self):
pass
def step(self, action):
"""Функции подается выбранное агентом действие. Возвращает состояние после действия, награду и информацию об окончании эпизода"""
def reset(self):
"""Сбрасывает среду к стартовому состоянию и возвращает стартовое состояние"""
def render(self, mode='human'):
"""Рендерит среду"""Но для реализации этих функций надо придумать систему наград и в каком виде мы будем отдавать информацию о среде.
В видео человек подавал змейке расстояние до стены, змейки и яблока в 8 направлениях. Те 24 числа. Я же решил уменьшить количество данных, но немного усложнить их. Во первых, я совмещу расстояние до стен с расстоянием до змейки. Проще говоря будем говорить ей расстояние до ближайшего объекта, который может убить при столкновении. Во вторых, направлений будет всего 3 и они будут зависеть от направления движения змейки. Например при старте змейка смотрит вверх, значит мы сообщим ей расстояние до верхней, левой и правой стенки. Но когда голова змейки повернется направо, то мы уже будем сообщать расстояние до правой, верхней и нижней стенки. Для пущей простоты приведу картинку.

С яблоком я тоже решил поиграться. Информацию о нем мы будем представлять в виде (x,y) координаты в системе координат, которая берет начало у головы змейки. Система координат также будет менять свою ориентацию за головой змейки. После картинки, думаю, точно должно стать понятно.
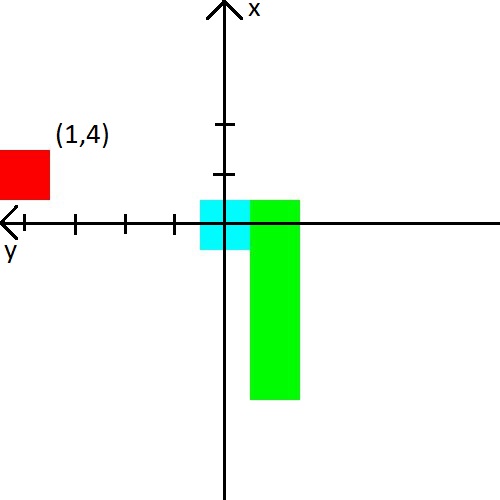
Если с состоянием можно придумать какие-то фичи и понадеяться, что нейросеть разберется, то с наградой все сложнее. От нее зависит будет ли агент учиться и будет ли он учиться тому, чего мы хотим.
Я сразу приведу систему награды, с которой я добился стабильного обучения.
А так же приведу примеры к чему приводит плохая система наград.

Основным интересом при написании змейки было увидеть, как змейка обучится зная так мало о своей среде. И обучилась она неплохо, тк средний показатель съеденных яблок достиг 23, что, мне кажется, очень не дурно. Поэтому эксперимент можно считать удачным.