Готовим чемоданчик serverless разработчика. (Часть 5 Заключительная)
- суббота, 30 апреля 2022 г. в 00:36:26

В предыдущих частях я сделал приложения, которое работает с БД, GitHub API. Все компоненты разворачиваются при помощи AWS SAM. Можно запускать реализованные функции локально. Все функции собраны воедино в одно API:
В этой, последней части, я рассмотрю вопросы, без ответов на которые опытная эксплуатация вряд ли будет похожа на прогулку в парке.
Уже изучено достаточно много, чтобы начинать собирать свой чемоданчик must have инструментов для serverless разработки. В этой части я соберу свой чемоданчик, а вы оставляйте в комментариях свои, будет интересно.
На основании предыдущих частей первым и одним из самых значимых инструментов в моем чемоданчике будет SAM framework. Этот инструмент позволил мне все вышеперечисленное построить, благодаря ему мое приложение успешно запускается как в облаке, так и локально.
Для развертывания приложения используются команды sam build и sam deploy. В каждом приложение должна быть возможность автоматически развернуть новый (по коммиту или по требованию).
Я хочу реализовать полноценный CI/CD pipeline для моего приложения на базе Jenkins CI. Не так давно компания AWS добавила в SAM framework ряд команд, призванных облегчить задачу организации полноценного CI/CD подхода - речь о командах:
sam pipeline bootstrap
sam pipeline initДанные команды упрощают создание CI/CD pipeline-файлов для ряда популярных CI/CD-инструментов.
Команда sam pipeline bootstrap используется, чтобы подготовить необходимые для работы CI/CD ресурсы в AWS, то есть это подготовительная команда, которая в интерактивном режиме запросит ряд данных(количество стадий, AWS-аккаунты и т.д.) и на их основе создаст необходимые ресурсы в AWS. В качестве результата работы данной команды в AWS-аккаунте будет развернут Cloud Formation стек, который создаст необходимые для полноценного pipeline ресурсы: IAM роли/политики, S3-бакет.
В свою очередь, команда sam pipeline init используется для создания непосредственно конфигурационного pipeline-файла в формате используемого вами CI/CD-сервиса, то есть данная команда - на основе уже созданных ресурсов для развертывания и в зависимости от выбранного из поддерживаемого списка CI/CD-сервиса - сгенерирует соответствующий pipeline-файл.
На данный момент поддерживаются следующие сервисы:
Jenkins
GitLab CI/CD
GitHub Actions
Bitbucket Pipelines
AWS CodePipeline
Результатом работы данной команды будет конфигурационный pipeline-файл для выбранного CI/CD-инструмента. Ниже фрагмент кода для Jenkins CI:
...
stage('deploy-prod') {
when {
branch env.MAIN_BRANCH
}
agent {
docker {
image 'public.ecr.aws/sam/build-provided'
}
}
steps {
withAWS(
credentials: env.PIPELINE_USER_CREDENTIAL_ID,
region: env.PROD_REGION,
role: env.PROD_PIPELINE_EXECUTION_ROLE,
roleSessionName: 'prod-deployment') {
sh '''
cd global-resources/
sam deploy --stack-name ${PROD_STACK_NAME} \
--template template.yaml \
--capabilities CAPABILITY_IAM \
--region ${PROD_REGION} \
--s3-bucket ${PROD_ARTIFACTS_BUCKET} \
--no-fail-on-empty-changeset \
--role-arn ${PROD_CLOUDFORMATION_EXECUTION_ROLE}
'''
}
}
}
...В данном случае можно заметить, что фактически в созданном pipeline-файле используются обычные shell-команды, доступные при установке утилит SAM cli, то есть ничего не мешает самостоятельно сделать конфигурационный pipeline-файл, используя команды sam build и sam deploy. Для того, чтобы вышеприведенный вариант корректно работал, нужен Jenkins плагин Pipeline: AWS Steps.
Запуск команды происходит в докер инстансе, который содержит все необходимые для сборки и развертывания приложения компоненты. Код в блоке withAWS выполняется в контексте указанного AWS профиля, с соответствующими правами. Переменная MAIN_BRANCH, как несложно догадаться, определяет основную ветку репозитория и в данном случае стадия deploy-prod будет запущена, только если используется основная ветка.
Таким образом, команда sam pipeline позволяет достаточно быстро развернуть первую версию CI/CD pipeline для serverless приложения. Этот инструмент пригодится для быстрого старта или для создания прототипов и отлично впишется в мой вышеупомянутый чемоданчик.
У меня уже есть 4 функции. Работая с лямбда функциями, я напрямую не работаю с инфраструктурой. Если бы это были EC2 инстансы, то я бы мог выбрать размер диска, тип инстанса (который бы влиял непосредственно на производительность виртуальных ядер и объем доступной оперативной памяти). А что есть у лямбда функций? Что делать, если моя лямбда умеет эффективно использовать потоки, как мне использовать более продвинутые виртуальные ядра?
В AWS есть только одна настройка, которая может влиять на производительность окружения лямбда функции - MemorySize (В прошлой части я добавил настройку выделять разное количество памяти для разных окружений). С одной стороны, все сильно упрощается, с другой стороны, существует прямая и неочевидная зависимость CPU от объема оперативной памяти.
На момент написания данной статьи максимальное количество памяти для функции - 10ГБ, минимальное - 128 МБ. За каждые 1769МБ AWS к окружению “добавляет” 1 vCPU. Таким образом, я могу иметь от 1 до 6 виртуальных ядер. Производительность ядра также зависит от объема памяти, так, 1 ядро окружения со 128 МБ памяти в 2 раза “слабее” 1 ядра окружения с 256 МБ памяти.
С увеличением памяти лямбда ускоряется, но увеличивается и плата за работу. Найти золотую середину поможет инструмент AWS Lambda Power Tuning. Эта утилита запускает лямбда функцию в разных конфигурациях, замеряет время и стоимость работы и показывает это на графике.
Если в приложении обрабатывается достаточно много запросов, то этот инструмент позволит определить оптимальную конфигурацию лямбда функции, которая бы выдавала приемлемую производительность при минимальной стоимости. Этот инструмент однозначно следует взять в свой чемоданчик.
Помимо оперативной памяти можно настраивать объем /tmp директории, которая доступна функции. Настройка осуществляется при помощи свойства EphemeralStorage. Минимальный размер (и по умолчанию) 512 МБ, максимальный размер - 10 ГБ.
Предположим, произойдет ошибка. Как о ней узнать? Где можно найти причины? В классическом приложении у меня есть логи. Логи отображаются в каком-то сервисе (например в kibana), где можно фильтровать результаты, искать по ключевым словам.
Пришло время разобраться с логами в моем приложении. У меня есть лямбда функции, которые содержат бизнес логику приложения, есть ApiGateway, принимающий запросы. Нужны способы работы с логами этих компонентов.
Начнем с функций. В AWS есть сервис Cloudwatch Logs, который используется для хранения и анализа логов приложений. Для каждой лямбда функции SAM создает отдельную лог группу в этом сервисе. Каждая лог группа состоит из нескольких log stream. Каждый такой поток относится к одному экземпляру лямбда функции. Все данные из stdout и stderr попадают туда. Если зайти в AWS Console в Cloudwatch сервис, то мои логи там выглядят так:
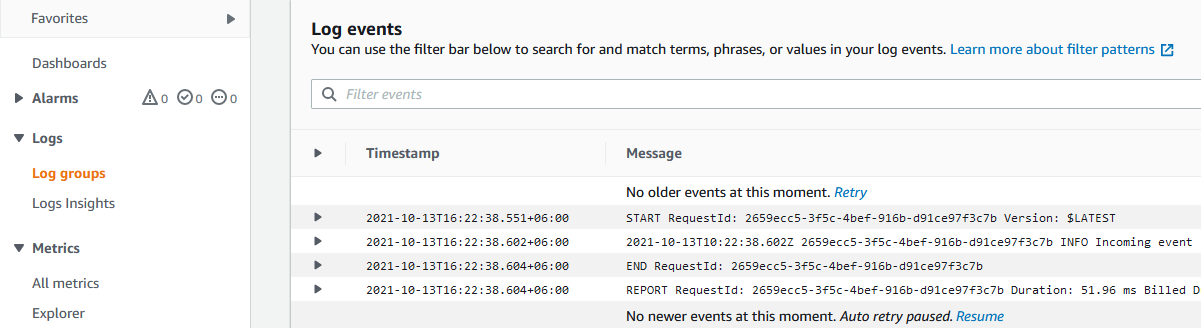
Первое, что можно заметить: в логах содержатся записи, начинающиеся со START, END, REPORT. Эти вспомогательные записи, создаваемые AWS, дают представление о том, когда лямбда начала выполнять запрос, когда закончила и результирующие метрики — время выполнения, оплачиваемое время, используемый объем памяти, выделенная память и т.д.
Второе, на что стоит обратить внимание: у каждого запроса есть свой уникальный RequestId. Благодаря ему я могу найти все логи для определенного запроса, посмотреть всю цепочку выполнения.
Пользоваться просмотром стримов в лог группе неудобно. За день может быть создано и убито несколько десятков экземпляров функций, искать ошибки в таком случае очень трудоемко. На помощь приходит другой инструмент в том же сервисе — Logs Insights. Он инструмент позволяет искать логи сразу по всем потокам разных лог групп с фильтрацией и сортировкой. Язык запросов, конечно, потребует некоторого привыкания, не один раз придется заглянуть в документацию, но ситуацию немного облегчает автодополнение.
Попробую отфильтровать все логи с уровнем INFO. Оказывается, в лог записи нет никакого поля, по которому я могу отфильтровать такие логи. Логи не структурированы и представляют собой просто текстовую строку. Строка INFO находится в поле @message:
fields @timestamp, @message
| filter @message like 'INFO'
| sort @timestamp desc
| limit 100Logs Insights гораздо удобнее в работе, чем возможность просматривать “сырые” лог записи. Да, по функционалу он проигрывает Kibana и ElasticSearch. Но минимального набора вполне хватит, чтобы исследовать проблемы и находить решения. Для тех случаев, где требуется более продвинутый язык запросов, можно поднять ELK в облаке и пересылать логи от функций туда.
Logs Insights или его аналог должен быть в арсенале любого serverless разработчика. Если требуются логи только определенной функции, то в этом также может помочь sam. Команда sam logs позволяет получить логи конкретной лямбда функции. Есть возможность фильтровать записи по дате и тексту:
D:\serverless-bugtracker> sam logs -n GetProjectByIdFunction --stack-name serverless-bugtracker-ch5 -s '10days ago'Можно настроить непрерывное получение логов:
D:\serverless-bugtracker> sam logs -n GetProjectByIdFunction --stack-name serverless-bugtracker-ch5 --tailНеструктурированные логи неудобны в работе, сложно делать фильтрацию. Например, я бы хотел иметь возможность искать все логи, относящиеся в определенному projectId. В текущей реализации сделать это будет затруднительно.
С Cloudwatch структурированные логи можно реализовать на уровне кода. Если в console.log() передать объект, то AWS автоматически разобьет этот объект на части и позволит осуществлять поиск по полям этого объекта. Если не хочется делать самостоятельно такие костыли (каждую строку оборачивать в объект с полем), то можно использовать специальные библиотеки для логов.
Например, есть winston-cloudwatch, но там используется Cloudwatch API для публикации логов с любых внешних ресурсов. Придется явно задавать имя лог группы, настраивать параметры AWS аккаунта. Вариант отпадает, не мой случай.
В идеале нужна просто обертка вокруг console.log (info,warn, error), которая поможет завернуть текст и теги в объекты. С этой ролью отлично, к примеру, справляется библиотека lambda-log, никаких настроек аккаунтов, просто удобная обертка для вывода логов в консоль, логи на выходе получаются структурированные. Также эта библиотека позволяет работать с контекстом лог записей:
const log = require('lambda-log');
exports.lambdaHandler = async (event, context) => {
const projectId = event.pathParameters.projectId;
log.options.tags.push(projectId);
log.info("Incoming event", event);
//code here...
};В логах будет следующий объект:
{
"_logLevel": "info",
"msg": "Incoming event",
"body": null,
"headers": {
...
},
"httpMethod": "GET",
"isBase64Encoded": false,
"multiValueHeaders": {
...
},
"multiValueQueryStringParameters": null,
"path": "/projects/1",
"pathParameters": {
"projectId": "1"
},
"queryStringParameters": null,
"requestContext": {
...
},
"resource": "/projects/{projectId}",
"stageVariables": null,
"version": "1.0",
"_tags": ["1"]
}Мой идентификатор проекта попал в секцию tags, теперь я смогу искать по этому полю в Cloudwatch. В будущем, если в тегах будет храниться множество данных, то можно каждое значение оснастить префиксом.
Иногда бывают ситуации, когда запросы не доходят до функций. В такой ситуации помогут логи, настроенные в ApiGateway.
В ApiGateway есть 2 типа логов:
execution логи;
access логи.
В первом типе логов можно найти информацию о запросе/ответе, о том, какие способы аутентификации используются. Эти логи получаются очень объемными, на один запрос я могу получить 10 строк ответа. Но это может быть полезным для глубоких исследований каких-то проблем, потому что дает информацию о том, как запрос обрабатывается в самом сервисе.
Включить execution логи можно следующим образом:
# template.yaml
BugTrackerApi:
Type: AWS::Serverless::Api
Properties:
MethodSettings:
- LoggingLevel: INFO
ResourcePath: '/*' # allows for logging on any resource
DataTraceEnabled: false #true if request/response needs
HttpMethod: '*' # allows for logging on any methodAWS для каждого ApiGateway автоматически создает отдельную лог группу для execution логов. Пример логов для одного запроса:

Мне хватит просто одной строки, которая содержит информацию о запросе, статусе ответа и другие дополнительные параметры. Настрою access логи, AWS дает возможность настраивать формат этих логов. Помимо формата (Common Log Format, CSV,XML,JSON) можно настраивать список полей для отображения. В контексте лог события содержится большое количество данных, существует несколько десятков разных полей, которые можно выводить в логах. Я остановлюсь на стандартных:
# template.yaml
BugTrackerApi:
Type: AWS::Serverless::Api
Properties:
...
AccessLogSetting:
DestinationArn: !GetAtt AccessLogGroup.Arn
Format: '{"requestTime":"$context.requestTime","requestId":"$context.requestId","httpMethod":"$context.httpMethod","path":"$context.path","resourcePath":"$context.resourcePath","status":$context.status,"responseLatency":$context.responseLatency}'
AccessLogGroup:
Type: AWS::Logs::LogGroup
Properties:
RetentionInDays: 14
Теперь я могу обновить и остальные лямбда функции: добавить логи, интегрировать с новым форматом событий.
Готовое serverless приложение, как правило, состоит из множества функций. Эти функции вызывают другие сервисы, другие функции. Результирующая цепочка вызовов от получения запроса до возвращения результата может быть довольно сложной. В такой распределенной среде, помимо логов, нужны инструменты,помогающие оценить производительность приложения, обнаружить узлы, которые приводят к ошибкам. Конечно, всю эту информацию можно достать из логов, но удобство пользования этими данными оставляет желать лучшего, потому что строить цепочку вызовов придется каждый раз самостоятельно в голове. На помощь приходит сервис для трассировки в лице AWS X-Ray.
Он позволяет строить карты сервисов, отслеживать логику выполнения для входящих запросов, показывает ошибки и отказы в приложении. Этот сервис отмечает часть запросов специальным идентификатором TraceId. Если в процессе обработки запроса происходят вызовы других сервисов, то порожденные запроса тоже отмечаются этим идентификатором. Таким образом это позволяет построить цепочку вызовов, отслеживать выполнение конкретного запроса, профилировать приложение.
Для того, чтобы начать пользоваться этим сервисом, необходимо включить xray трассировку в ApiGateway и лямбда функциях:
Resources:
BugTrackerApi:
Type: AWS::Serverless::Api
Properties:
TracingEnabled: true
...
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
Tracing: Active
...Теперь сделаю пару вызовов моего API и зайду в AWS Console в раздел X-Ray. AWS построил вот такую карту:

Помимо карты, X-Ray предоставляет информацию о длительности шагов. Моя карта очень простая, можно только увидеть время инициализации и работы лямбда функции:

Тут нет ни БД, ни гитхаба, для более детальной профилировки они необходимы. Исправлю эту неточность. Для добавления этих сервисов придется использовать aws-xray-sdk в коде функций. Для профилирования работы с БД:
// src/handlers/get-project-by-id/app.js
const captureMySQL = require('aws-xray-sdk-mysql');
const mysql = captureMySQL(require('mysql2/promise'));После этих изменений в X-Ray автоматически будет попадать информация о запросах в MySQL. При желании можно добавить в контекст сам SQL запрос.
Github API не является стандартным сервисом для sdk, так что эти запросы не будут отображаться ни на карте, ни в цепочках трассировки. Чтобы улучшить трассировку для GitHub API, я воспользуюсь тем, что X-Ray может отслеживать http/https запросы.
// src/handlers/get-project-by-id/app.js
const AWSXRay = require('aws-xray-sdk-core');
AWSXRay.captureHTTPsGlobal(require('https'));Теперь запросы в GitHub API появятся на карте.
Еще одна полезная функциональность в X-Ray sdk - это создание своих сегментов. Они не отображаются на карте сервисов, зато для них считается длительность и с помощью этого можно делать профилирование важных частей кода. Я сделаю сегмент, который включает запрос в GitHub API и его обработку:
// src/handlers/get-project-by-id/app.js
const xraySegment = AWSXRay.getSegment();
var subsegment = xraySegment.addNewSubsegment(get-pull-requests');
const { data: prInfo } = await listPullRequests(owner, project['github_repo']);
subsegment.close();SSM интегрировать с sdk можно, но не нужно в моем случае. Все потому, что запрос в SSM происходит один раз за все время жизни экземпляра в момент инициализации. Трассировка же работает, только когда происходит фаза обработки события.
После всех изменений карта вызовов получается такой:

А вот и обновленный список сегментов:

Как видно, инструмент полезный и нужный в распределенных системах. Но есть своя ложка дегтя. Теперь мой код не работает локально. Все-таки локально запускается не настоящая лямбда функция и X-Ray контекст не создается, как следует. Из-за этого происходит ошибка и лямбда функция не запускается: 'Missing AWS Lambda trace data for X-Ray. Ensure Active Tracing is enabled and no subsegments are created outside the function handler'.
Для локального запуска можно скрыть эти ошибки. Для определения локального запуска Amazon предоставляет специальную переменную AWS_SAM_LOCAL. Чтобы игнорировать эти ошибки, я воспользуюсь специальным режимом в X-Ray клиенте:
if (process.env.AWS_SAM_LOCAL) {
AWSXRay.setContextMissingStrategy("IGNORE_ERROR");
}Развернутое приложение будет работать с трассировкой, а в локальном режиме трассировка будет игнорироваться.
Сервисы трассировки играют важную в роль в мониторинге и отладке распределенных систем. И эта роль увеличивается с увеличением числа компонентов приложения. Такой инструмент обязательно должен быть в чемоданчике serverless разработчика.
Как уже было сказано ранее, на каждое событие от ApiGateway AWS будет искать готовый к обработке экземпляр функции. Если готового экземпляра нет, то AWS начнет его создавать. Таким образом, если нет готовых экземпляров и прилетит 10 событий разом, то будет создаваться 10 экземпляров лямбда функций. Это очень удобно, провайдер сможет обрабатывать пиковые нагрузки и масштабироваться автоматически. Но что будет с моей БД?
Очевидно что такое бесконтрольное “размножение” в конце концов приведет к отказу БД или очень большим задержкам. Аналогичная проблема может быть с любым ресурсом, доступ к которому ограничен какими-то квотами. Что тут можно сделать?
Для каждой функции можно задать максимальное количество экземпляров, которые могут одновременно работать. Я задам этот параметр через глобальные настройки для всех функций:
# template.yaml
Globals:
Function:
ReservedConcurrentExecutions: 5Введя это ограничение, я заблокирую создание новых экземпляров сверх этого лимита. События, которым не будет хватать обработчика останутся необработанными. В случае с API Gateway пользователь получит ошибку. Этот механизм позволяет контролировать скорость обработки событий для приложений. Правильно ли так обрабатывать такие нагрузки - это другой вопрос, и решается он по-разному в каждом отдельном случае.
Если установить ReservedConcurrentExecutions в значение 0, то моя лямбда совсем перестанет обрабатывать события, поскольку провайдер не сможет создавать новые экземпляры. Это может быть полезно в ситуациях, когда необходимо отключить часть функционала без обновления всего приложения. Например баг в функции или проблемы с БД, я могу отключить лямбду, которая может вызывать эти проблемы.
В первой части я коснулся немного проблемы cold start. Для уменьшения времени холодного запуска я выбрал nodejs, поскольку у интерпретируемых языках программирования время инициализации меньше. Но тем не менее, даже с использованием определенного языка, эта проблема может не исчезнуть. Чем больше логики в блоке инициализации, тем больше время ожидания первого ответа. Как же быть? Что еще можно предпринять для сокращения этого времени, или для того, чтобы влияние этого было минимальным?
В фазе инициализации происходит скачивание кода, подготовка окружения. После того как окружение готово, происходит собственно инициализация кода.
Как разработчик, я могу повлиять на то, как мой код инициализируется. Очевидно, что использование “тяжелых” библиотек и фреймворков увеличит это время. Поэтому если в приложении можно обойтись без каких-либо фреймворков, то лучше их не добавлять. Например, можно прекрасно обойтись без Express.js при написании лямбда функций. Нет необходимости добавлять в зависимости aws-sdk целиком, если из этой библиотеки нужен только клиент работы с SSM.
Как разработчик, я также могу повлиять на размер моей кодовой базы. Здесь рекомендация очень похожа на предыдущие. Фреймворки и библиотеки помимо времени загрузки влияют еще и на размер артефакта. AWS-SDK занимает 70 МБ, тогда как aws-ssm client всего около 5 МБ (по данным npm).
Другим способом уменьшения кодовой базы является использование специальных инструментов для сжатия исходников, например webpack. Этот вариант наиболее прост и эффективен в случае, если не применяются слои с зависимостями, а все библиотеки находятся внутри лямбда функции.
Организация сжатия внутри слоев потребует больше усилий. Зависимости из слоев могут использоваться во многих функциях. Придется зафиксировать используемые методы библиотек через прокси модули. Такое решение очень неудобное и громоздкое.
Все эти способы помогут уменьшить время cold start. Но окончательно побороть это явление сложно. Да, я могу оптимизировать свои зависимости, но они все равно будут вносить какой-то вклад в общее время инициализации. Что делать?
В AWS существует возможность держать в облаке определенное число “живых” экземпляров функций. Таким образом, при появлении нового события для обработки функция сразу готова к работе, ей не нужно время на инициализацию. Этот функционал в AWS для лямбда функций называется Provisioned Concurrency. Я плачу деньги за то, чтобы облачный провайдер держал некоторое число функций “прогретыми”.
Для этих “прогретых” функций проблема cold start становится неактуальной. Если количество событий превышает количество существующих прогретых функций, то включаются обычные правила AWS. Создаются новые экземпляры по обычным правилам (c cold start)
Настройка ProvisionedConcurrency для лямбда функции выполняется в SAM шаблоне:
# template.yaml
Globals:
Function:
ProvisionedConcurrencyConfig:
ProvisionedConcurrentExecutions: 5
В каком-то смысле можно рассматривать возможность поднимать уже “прогретые” экземпляры как серебряную пулю для борьбы с cold start. Это решение особенно выигрышно в случае небольших нагрузок. Для приложений с плавающей нагрузкой, такое решение может таить в себе дополнительные расходы.
Приложение готово и пришло время подвести итоги всего приключения. Разработка serverless приложения была увлекательной и интересной. Я затронул базовый набор: api gateway, лямбда функции, RDS, sam. В процессе разработки я старался затронуть те же моменты, с которыми часто сталкиваюсь при разработке классических серверных приложений: тестирование, отладка, развертывание и так далее.
Чемоданчик наполнился следующими инструментами:
SAM framework для построения и управления приложением;
AWS X-Ray как решение для трассировк;
Logs Insights, sam logs для работы с логами;
lambda-log для создание структурированных логов.
В предисловии я писал о плюсах, которые обычно приписывают serverless разработке. В процессе работы над приложением я точно могу подтвердить два из четырех:
быстрота разработки;
быстрые релизы.
Часто при старте проектов первые недели идет усиленная работа по созданию окружений, написанию скриптов развертывания, проработка CI/CD. Достаточно много работы в это время ложится на DevOps инженеров. С serverless приложениями этот первый шаг можно пройти быстрее.
Безусловно, скорее всего потребуется помощь DevOps для настройки VPC, VPN, и их интеграции с AWS сервисами. Что касается самого приложения, то тут разработчик вполне в состоянии создать скрипты развертывания, настроить SSM, задать параметры сборки, организовать dev/qa/stg/feature environments. SAM оказался очень удобным инструментом для развертывания.
Сами релизы происходят быстро, нет необходимости обновлять все приложение целиком, можно обновить только часть.
“Гибкое масштабирование” и “уменьшение времени или затрат на администрирование приложений” в полной мере прочувствовать не удалось. Настоящей опытной эксплуатации у моего проекта не было, несмотря на это удалось немного протестировать работу приложения в условиях плавающей нагрузки.
Тюнинг производительности существенно упрощается, есть 3 параметра, которыми можно управлять для повышения/понижения производительности приложения: объем памяти в самой функции, значения ReservedConcurrency и ProvisionedConcurrency.
Но не может быть все идеальным и таким безоблачным. Есть моменты, которые требуют большого внимания.

Если с serverless компонентами проблем практически не было, то на стыке SAM и CF возникали затруднения. В CF число ресурсов и компонентов гораздо больше, эти ресурсы сложнее в настройке. Поэтому по ощущениям больше времени тратилось именно на CF ресурсы и настройки.
Иногда не хватало подсказок в документации AWS о том, как делать те или иные вещи.
Признаться, в процессе работы над приложением я несколько раз переделывал структуру проекта. Все потому, что не было каких-то четких указаний или рекомендаций от AWS, как лучше располагать файлы в проекте. Изначально все мои js файлы были в одной папке и все казалось простым и понятным, пока я не заглянул в папку со сборкой. Пришлось даже потратить время на то, чтобы научиться применять webpack для сжатия моих исходников. Но потом пришло понимание, что такая структура проекта не совсем подходит для serverless приложения.
Это приключение подошло к концу. Я однозначно в будущих своих проектах буду рассматривать возможность переезда на serverless рельсы.
Я надеюсь, что получится сделать какое-то продолжение. В “стране serverless” есть еще множество интересных вещей:
работа с длительными вычислениями (ведь время работы лямбда функции ограничено 15 минутами);
построение цепочек из лямбда функций при помощи step functions;
использование других фреймворков для развертывания (serverless, aws cdk);
другие облачные провайдеры.
Оставляйте в комментариях набор инструментов, который входит в ваш личный чемоданчик serverless разработчика.
P.S. Спасибо oN0 за помощь в написании статей.
P.P.S Код можно найти в репе