https://habr.com/ru/company/plesk/blog/508420/- Блог компании Plesk
- PHP
- JavaScript
- Lua
- Хакатоны
Карантин и переход на удаленку наводят на ностальгические воспоминания о полном жизни офисе, когда вместо звонков и трансляций мы работали и собирались на хакатонах в одной комнате с коллегами. Сегодня вспомним хакатон, где мы писали веб-сервер на Lua, а заодно кратко пробежимся по истории развития real-time web. Под этим термином мы будем понимать технологии, которые позволяют делать в браузере вещи, сравнимые по UX с десктопными приложениями — когда отклик на действия или события приходит сразу. Вспомним, как это делалось раньше, как делается сейчас, сравним существующие решения и расскажем, что и как используем сами. Видео-версию оригинального доклада можно посмотреть
на нашем канале.
История
iframe
Начнем с начала нулевых — многие, наверное, помнят чаты на iframe. Сейчас уже сложно назвать это real-time технологией, но тем не менее. Принцип работы — в HTML-документ с помощью тега
iframe встраивается содержимое другой веб-страницы — например, блок с чатом в игре. При обновлении этой встроенной части вся остальная страница не обновляется.
Технология очень старая, и хотя кое-где используется до сих пор, отказ от нее начался еще с момента появления AJAX.
Polling
На скриншоте — Network-лог в Chrome, куда мы ходили и проверяли, появились ли у нас новые данные о прогрессе задач в Plesk.
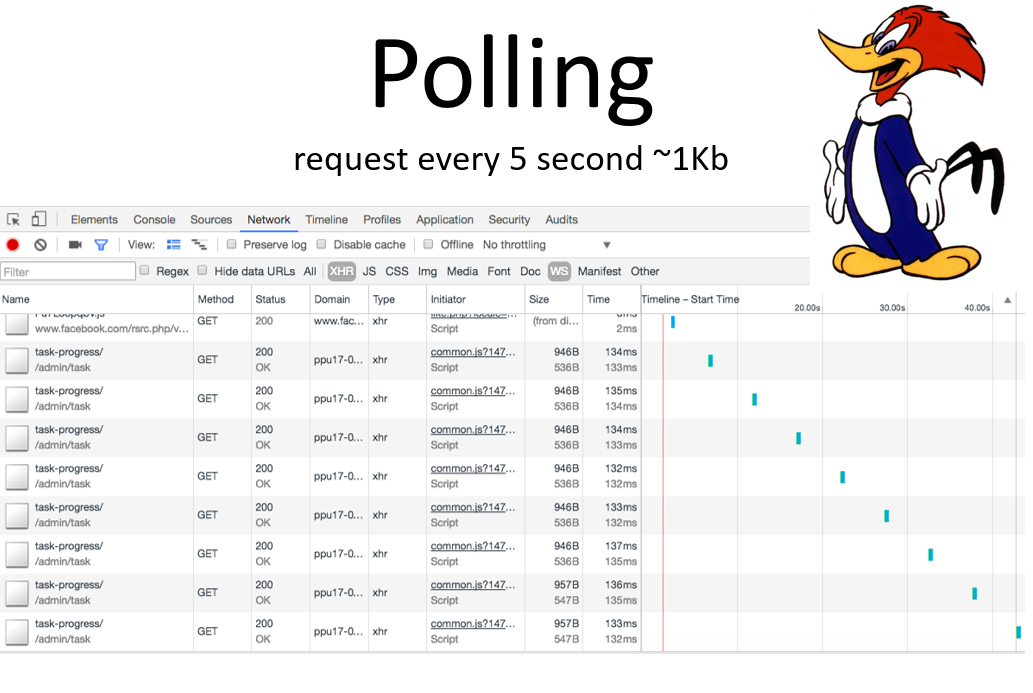
Предположим, что запрос отправляется каждые 5 секунд и суммарно включает примерно 1 Кб данных. За час накопится уже 1 Мб, и это лишь одна из проблем. Другая — это то, что в течение этих 5 секунд мы не получаем никаких обновлений — то есть минимальная задержка между событием и реакцией становится равна 5 секундам.
Такая технология называется polling (от слова poll — опрос). Она очень простая в реализации — есть веб-сервер, который отдает ответы, есть клиент, который может посылать запросы с какой-то периодичностью. Всё просто, но существенными минусами являются задержки (мы не получаем события) и высокий объем трафика.
Поэтому на этой же основе был разработан long polling.
Long polling
Его отличие состоит в том, что сервер не дает ответа до тех пор, пока не появятся данные, запрошенные клиентом. Опять-таки реальный скриншот из Plesk — это лог-браузер. Мы ждем, когда в логе появятся какие-то данные, посылаем запрос и сервер в бесконечном цикле ждет, когда же эти данные появятся.
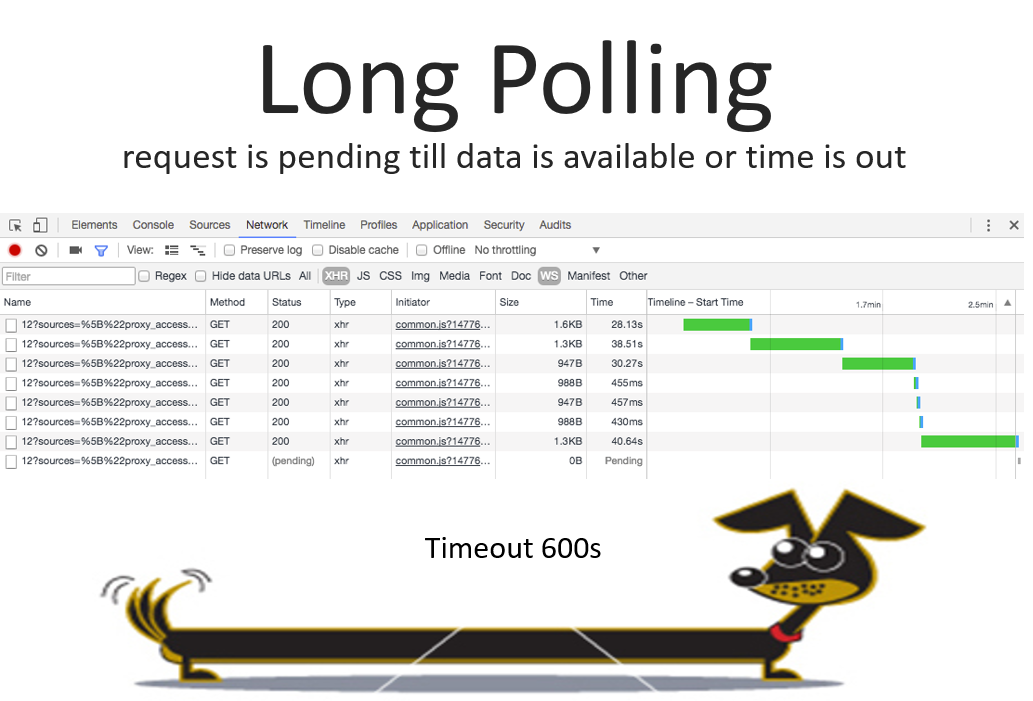
Когда данные появляются, он формирует нужную структуру и отдает ее в запросе. На этом запрос заканчивается, клиент получает необходимые данные и шлет новый запрос.
Есть и ограничения: сервер не может держать открытый запрос больше 10 минут, поэтому при приближении к этому времени он принудительно закрывает запрос с пустыми данными. Ошибок в результате не происходит, клиент просто получает пустой сет данных и шлет новый запрос. Всё вроде бы неплохо, но остается проблема в случае, если данные появляются очень часто. На скриншоте мы видим кусочек, где запрос пошел очень часто — при этом, даже если в запросе данных совсем мало, HTTP-хэдеры и другие накладные расходы всё равно приводят к тому, что трафик будет большой.
Итак, плюсы:
- не пришлось изобретать какие-то новые технологии, используется привычный нам PHP, Apache, nginx
- минимальные задержки для получения данных, то есть на событие получается реагировать практически мгновенно.
Минусы:
- трафик не уменьшился.
- самое главная проблема: угроза упасть в случае DDoS.
Количество PHP-процессов ограничено настройками FPM — для Plesk у нас установлено 26 child-процессов. И если число клиентов, которые запрашивают long polling запросы, превышает 26, то 27-й и все последующие просто висят и ждут, когда освободится хотя бы один PHP-процесс. Для клиентов это выглядит как неответ сервера — то есть, для них не то что конкретно long polling, а вообще ничего не работает, просто PHP не доступно.
Это плохо, но в Plesk мы с этим пока поделать ничего не можем, потому что другого бэкенда, кроме PHP, у нас нет. Однако в мире существуют различные технологии, которые позволяют делать не блокирующие сервера: например, Facebook использует Python Tornado, Node.js вообще не может быть блокирующим, еще есть Go, в общем, очень много всего придумано. Чуть дальше мы еще вернемся к задаче построения бэкенда.
WebSocket
Следующая технология — WebSocket. Больше 10 лет назад появился такой стандарт, позиционирующийся как новый протокол взаимодействия клиента и сервера.
Принцип его работы — постоянное соединение, через которое мы можем в обе стороны передавать данные — от сервера к клиенту, от клиента к серверу. Клиент от сервера с точки зрения этой технологии вообще мало чем отличается.
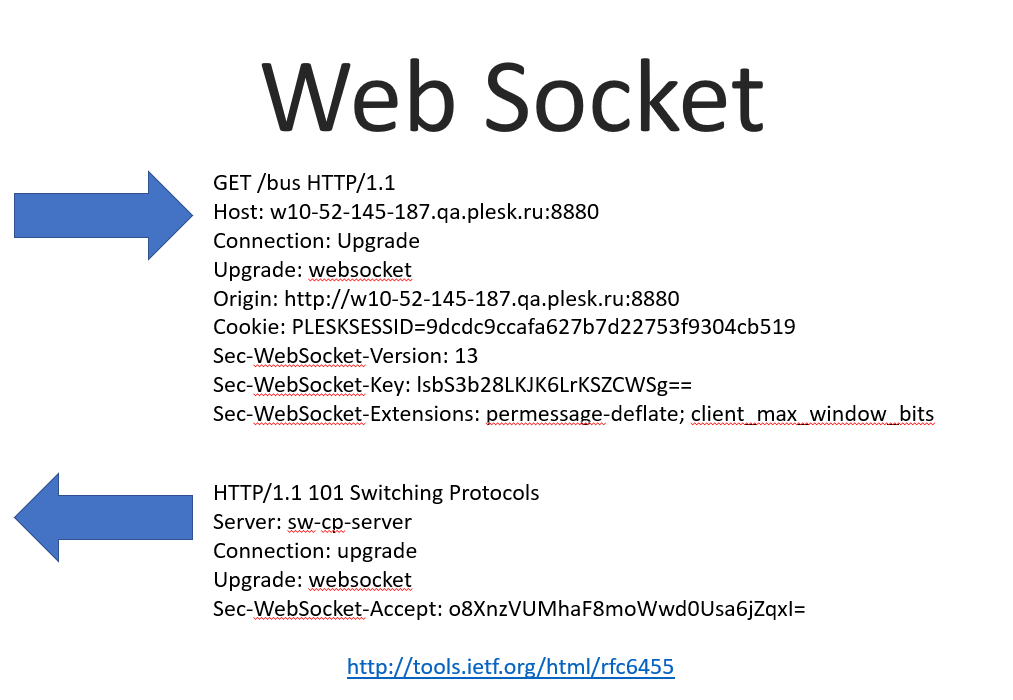
Как это всё работает: WebSocket построен над HTTP, то есть клиент (браузер) устанавливает handshake с сервером с помощью HTTP-пакетов, к которым добавлено несколько дополнительных хэдеров. Он говорит “будем апгрейдить это соединение до веб-сокета”, передает версию протокола, специальные ключи для безопасности — чтобы удостовериться что мы действительно WebSocket соединение устанавливаем, — различные сжатия и т.п. Сервер отвечает согласием с определенным хэшом, подтверждающим что это WebSocket-соединение, и больше у нас HTTP-запросы не передаются — всё дальнейшее взаимодействие будет на бинарном протоколе передавать фреймы (в сущности — plain text, просто XOR-ом замаскированный). То есть дальнейший трафик у нас не передает никаких хэдеров и практически отсутствует, если не передаются данные.
Кроме самого протокола, появился еще браузерный API для WebSocket — в Javascript мы создаем объект WebSocket и можем подключаться к удаленному серверу. Полноценная поддержка протокола предоставляется всеми современными браузерами, и согласно caniuse.com, доступна 97% пользователей Интернета.
var address = (window.location.protocol === 'https:'?'wss://':'ws://') +
window.location.host + '/websocket';
var ws = new WebSocket(address);
ws.onopen = function() {};
ws.onclose = function(event) {};
ws.onmessage = function(event) {};
ws.onerror = function(error) {};
ws.send(“Hello”);
Еще одна задача данного API — это уменьшить сложность всего того, что мы писали ради поллинга и лонг-поллинга: какие-то свои методы по периодичности, таймауты и т.д. — здесь ничего этого нет, и всё очень прозрачно.
Как же можно сделать WebSocket сервер? А вот как:
SocketIO
Многие, говоря про WebSocket и клиент-серверное взаимодействие, подразумевают библиотеку Socket.IO, но те плюсы, которые она дает, конкретно нам не очень нужны. Это: кросс-браузерная поддержка (начиная с IE 6) c различными фолбеками, комнаты, channels и так далее, что, наверное, актуально для чатов, но не актуально для наших приложений. Еще там есть авто-переподключение при разрыве связи, которое не составляет труда сделать самостоятельно.
Единственное, когда можно было бы использовать Socket.IO — это когда вы пишете приложение на Node.js, чтобы писать его на абсолютно одинаковом коде на сервере и на клиенте. Наверное, это удобно, но мы не пишем.
WS
Давайте посмотрим, как же писать приложения на Node.js, правда, используя не Socket.IO, а библиотеку WS (WebSocket), которая по непроверенным данным со stackoverflow считается одной из самых быстрых, и вообще очень похожа на браузерное API.
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: process.env.PORT || 8080 });
wss.on('connection', function connection(ws) {
ws.on('message', function incoming(message) {
console.log('received: %s', message);
ws.send(message);
});
console.log('connection established');
});
console.log('App is running...');
Тут всё очень просто — в этом примере мы в каких-то несколько строчек научились принимать сообщения с браузера и отправлять обратно.
Как запускать такие сервера? Для клиентских приложений на Node.js мы в Plesk предлагаем использовать Passenger. И свои тесты мы также проводили с Passenger.
PHP Ratchet
Теперь вернемся к PHP. Есть такая популярная библиотека PHP Ratchet, которая реализует WebSocket протокол на PHP.
<?php
use Ratchet\MessageComponentInterface;
use Ratchet\ConnectionInterface;
class MyChat implements MessageComponentInterface {
public function onOpen(ConnectionInterface $conn) {}
public function onMessage(ConnectionInterface $from, $msg) {}
public function onClose(ConnectionInterface $conn) {}
public function onError(ConnectionInterface $conn, \Exception $e) {}
}
$app = new Ratchet\App('localhost', 8080);
$app->route('/chat', new MyChat);
$app->route('/echo', new Ratchet\Server\EchoServer, array('*'));
$app->run();
Запускается она как command-line скрипт, на сервере слушает какой-то порт и отвечает по нему. То есть, не как привычный нам PHP FPM, который получает реквесты через веб-сервер, а самостоятельно слушает, как привычно нам в Node.js. Это накладывает свои какие-то ограничения на то, что у тебя этот daemon может прилечь, прибит по памяти и т.д., и по идее к нему требуется супервайзер, но это осталось за рамками данного исследования.
OpenResty (Lua)
Следующий пример — OpenResty библиотека для Lua. Здесь мы переходим к тому, чем мы занимались на хакатоне – к задаче написания такого же WebSocket сервера на Lua.

WebSocket сервер на Lua
Реализация
OpenResty это набор библиотек, которые позволяют добавить в nginx немного функциональности — как например подключение к MySQL, или к Redis, или еще к чему-то. В том числе есть реализация WebSocket протокола, которая позволяет сделать аппликейшн, запускаемый на nginx и отвечающий на запросы клиентов по WebSocket протоколу. Набор этих библиотек большой, у них есть своя сборка nginx, но даже она не обязательна, пока мы не используем много библиотек. Мы взяли конкретную библиотеку и просто подключили ее к nginx, положили в папочку и сказали, что этот контент мы будем обрабатывать с помощью Lua.
lua_package_path "/etc/sw-cp-server/lib/?.lua;;";
server {
...
location /bus {
lua_socket_log_errors off;
lua_check_client_abort on;
content_by_lua_file "/etc/sw-cp-server/lib/plesk/bus.lua";
}
}
Вообще Lua очень приятный язык, который теоретически мог бы заменить javascript, и все браузеры обрабатывали бы Lua и мы бы не писали на JS. Но наверное маркетологи не доработали что-то в начале 90х и имеем что имеем. Тем не менее, Lua во многие области внедрился, он очень простой, очень легко, как говорят, написать его реализацию – например, в nginx какая-то своя реализация используется.
Вот ею мы и воспользуемся.
local server = "resty.websocket.server"
local wb, err = server:new{ timeout = 5000, max_payload_len = 65535 }
while true do
local data, typ, err = wb:recv_frame()
if not data then wb:send_ping()
elseif typ == "close" then break
elseif typ == "ping" then wb:send_pong()
elseif typ == "pong" then ngx.log(ngx.INFO, "client ponged")
elseif typ == "text" then wb:send_text(data)
end
end
wb:send_close()
В действительности код был побольше, потому что каждая функция, так же как в Golang, возвращает error, который нужно обрабатывать — здесь мы опустили всю обработку ошибок, и функционально это весь код, который требуется для работы с клиентом.
Итак, чем мы занимались на хакатоне — мы сделали своеобразную шину событий, которая делает публикацию всех событий в Redis. Redis предоставляет реализацию publish-subscribe парадигмы, когда все «подписчики» получают моментальное уведомление о произошедших в очереди событиях.
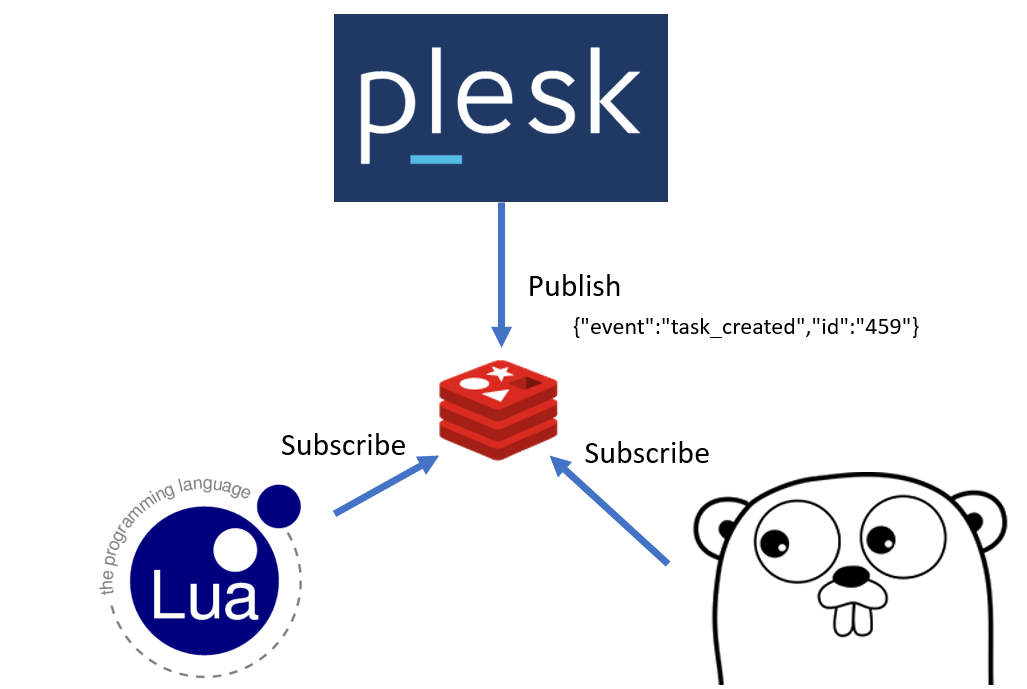
Мы подписали воркер, который выполняет реальные задачи, на эту очередь, также подписали веб-сервер и тем самым мы получаем события из Plesk моментально, обрабатываем их и отдаем ответы клиенту. На скриншоте видно, что теперь мы получаем информацию о том, что статусы обновились, новые задачи появились, создались новые домены — в общем, любые события из Plesk приходят клиенту.
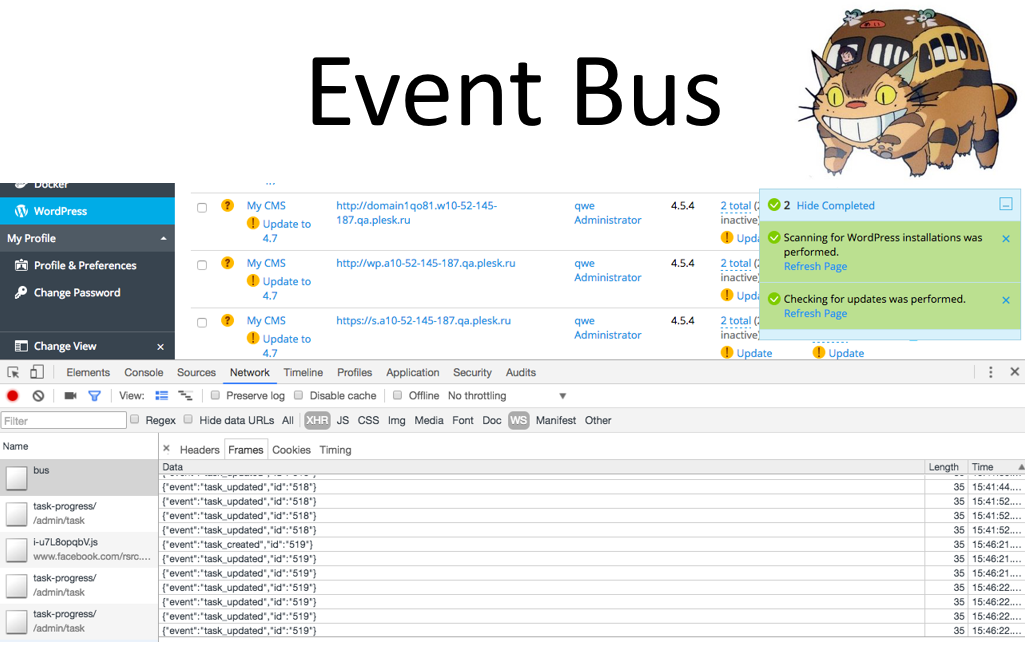
Задержки минимальные, трафик минимальный, всё очень шустро.
Проблемы
Теперь мы дошли до проблем, с которыми столкнулись. В Plesk очень много бизнес логики и вот какая проблема у нас возникла: у нас есть клиент с определенным sessionId и вот генерируется событие. Возникает вопрос — может ли клиент видеть это событие или не может? За это отвечает бизнес-логика. Чтобы мы пересылали (или не пересылали) через WebSocket это событие, он должен как-то эту логику позвать. Например, она должна быть реализована на том же языке, что и WebSocket сервер. Если мы будем отвечать всё подряд, то мы можем, например, передать имя созданного домена, что, наверное, считается приватной информацией, которую не должны получать все клиенты.

Варианты решений
Отдавать только безопасные данные
Соответственно, простейшее решение — отдаем только безопасные данные. У нас нет имен доменов, есть только ID (цифра). На хакатоне мы пошли этим путем и отдаем только безопасные данные. Да, их получается много, но свою задачу мы решили, для прототипа этого достаточно и мы не допустили уязвимостей.
API
Следующее предложение, как это можно реализовать: мы делаем API, которое отвечает на вопрос — можно или нельзя передавать это событие этому клиенту. Как это может работать: API принимает session ID, принимает событие и отвечает “да” или “нет”. В принципе несложно, но, наверное, получится многовато взаимодействий туда-сюда.
Промежуточное состояние
Предложение, которое кажется самым удачным — промежуточное состояние, когда событие до отправки клиенту обрабатывает обработчик, написанный на PHP. Как это может работать: мы получаем события в очереди, достаем ID всех открытых сессий, и проверяем для каждой сессии, можем ли мы этому клиенту отправить это событие. Если да, то генерируем новое событие “отправить такое-то событие для такой-то session ID”, после этого для WebSocket сервера (в данном случае у нас Lua) уже всё готово и понятно, кому нужно отправить такие данные.
Кажется, что это решает проблему. Но это дополнительная прослойка, которая должна быть каким-то образом запущена.
Измерения и сравнения
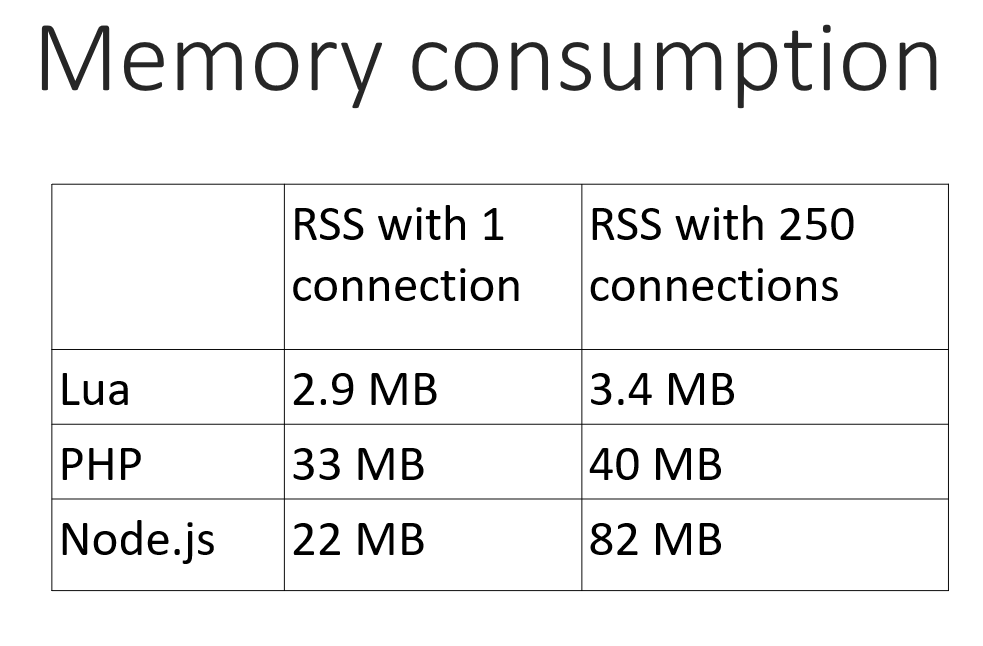
Рассмотрим такой тест — откроем в браузере 250 соединений с сервером.
Почему 250 — если пойти чуть дальше, то Chrome отказывается это делать. Наверное у них были для этого какие-то основания и в реальной жизни вряд ли кому-то понадобится с одного окна открывать столько соединений. Но для начала давайте сравним 250.
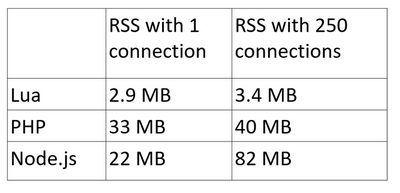
На Lua цифры весьма смешные. Стоит сразу сказать, что если мы бы не подключали Lua, то воркер nginx занимал бы примерно 2 Мб, с Lua стало 2.9, разницы практически нет.
PHP заметно хуже: сам запущенный процесс занимает довольно весомый объем памяти. Поскольку у нас PHP как daemon, он будет запущен всегда и съедать довольно много памяти, впрочем, с ростом соединений эта цифра растет не слишком сильно.
Node.js совсем не порадовал — он тоже используется как интерпретатор, то есть запущен всегда, и съедает 20 Mб, но с ростом соединений объем памяти доходит до сотни. На наш взгляд, неприемлемо в наших условиях.
Ну и, конечно же, всегда интересно устроить краш-тест и попробовать всё уронить – здесь мы говорим скорее о Lua, ведь в том, что развалится всё остальное, сомнений нет :)
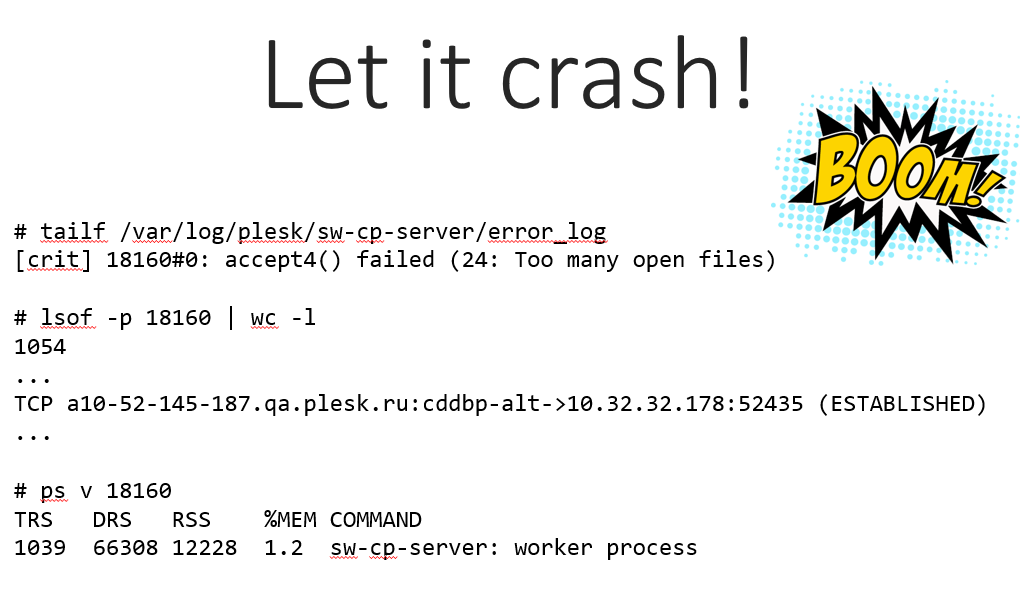
Мы увеличивали число соединений с разных браузеров до тех пор, пока nginx не уперся в лимит и не отказался больше принимать. Получилось порядка 750 открытых соединений, они показывались открытыми напрямую к какому-то порту клиента и при этом съели всего ничего — 12 Mб памяти.
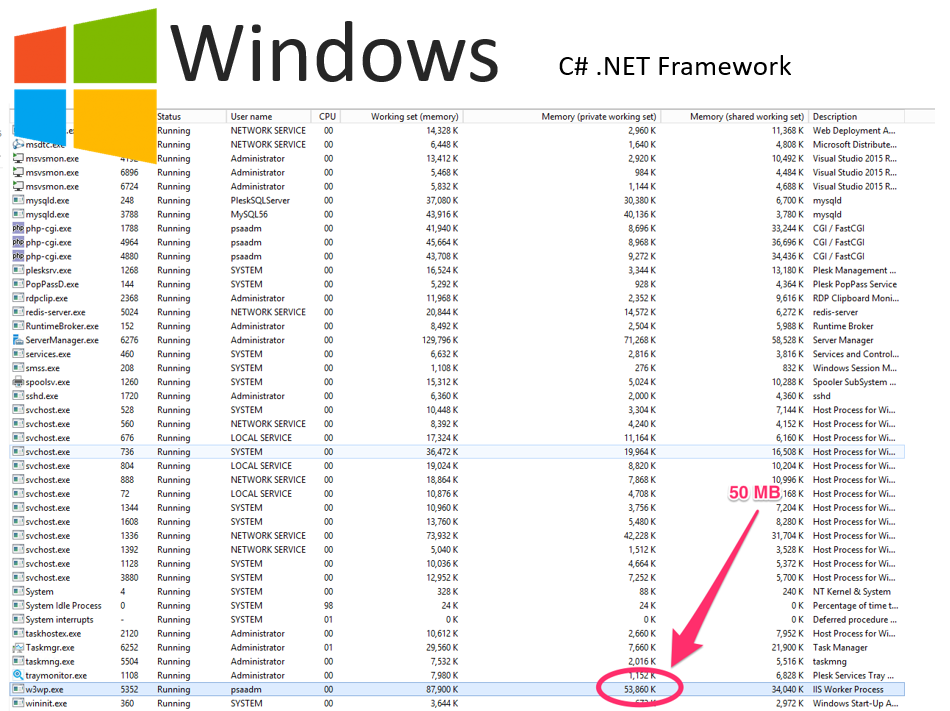
Windows версия
В завершение коротко упомянем о про-Windows имплементации, которой мы тоже занимались на хакатоне. Она была реализована на C#, при этом пришлось использовать .NET фреймворк и, как видно в списке процессов, вот тут воркер занимает уже порядка 50 Мб, хотя без .NET он занимал 5 Мб.
Конечно, это всего лишь прототип и Proof-of-Concept, но выводы мы сделали: такая реализация нас не устроит и нужно писать нативные хэндлеры на С++. Попытались сделать Proof-of-Concept, но до конечной реализации не дошли – будет задел на будущее, когда мы снова вернемся в офис хакатонить бок-о-бок с коллегами.