Делаем домашнюю библиотеку с Notion и Python
- четверг, 19 сентября 2019 г. в 00:30:48
Мне всегда было интересно, как бы получше распределить книги у себя в электронной библиотеке. В итоге пришел к такому варианту с автоматическим подсчетом количества страниц и прочими плюшками. Всех заинтересованных прошу под кат.
Все книжки у меня лежат на дропбоксе. Существуют 4 категории, на которые я все поделил: Учебник, Справочник, Художественное, Нехудожественное. Но справочники я в табличку не добавляю.
Большая часть из книг — .epub, остальные — .pdf. То есть конечное решение должно как-то покрывать оба варианта.
Пути до книг у меня примерно такие:
/Книги/Нехудожественное/Новое/Дизайн/Юрий Гордон/Книга про буквы от А до Я.epub Если книга художественная, то категория (то есть "Дизайн" в случае выше) убирается.
Я решил не заморачиваться с API дропбокса, благо у меня стоит их приложение, которое синхронизирует папку. То есть план такой: берем книги из папки, каждую книгу прогоняем через счетчик слов, добавляем в Notion.
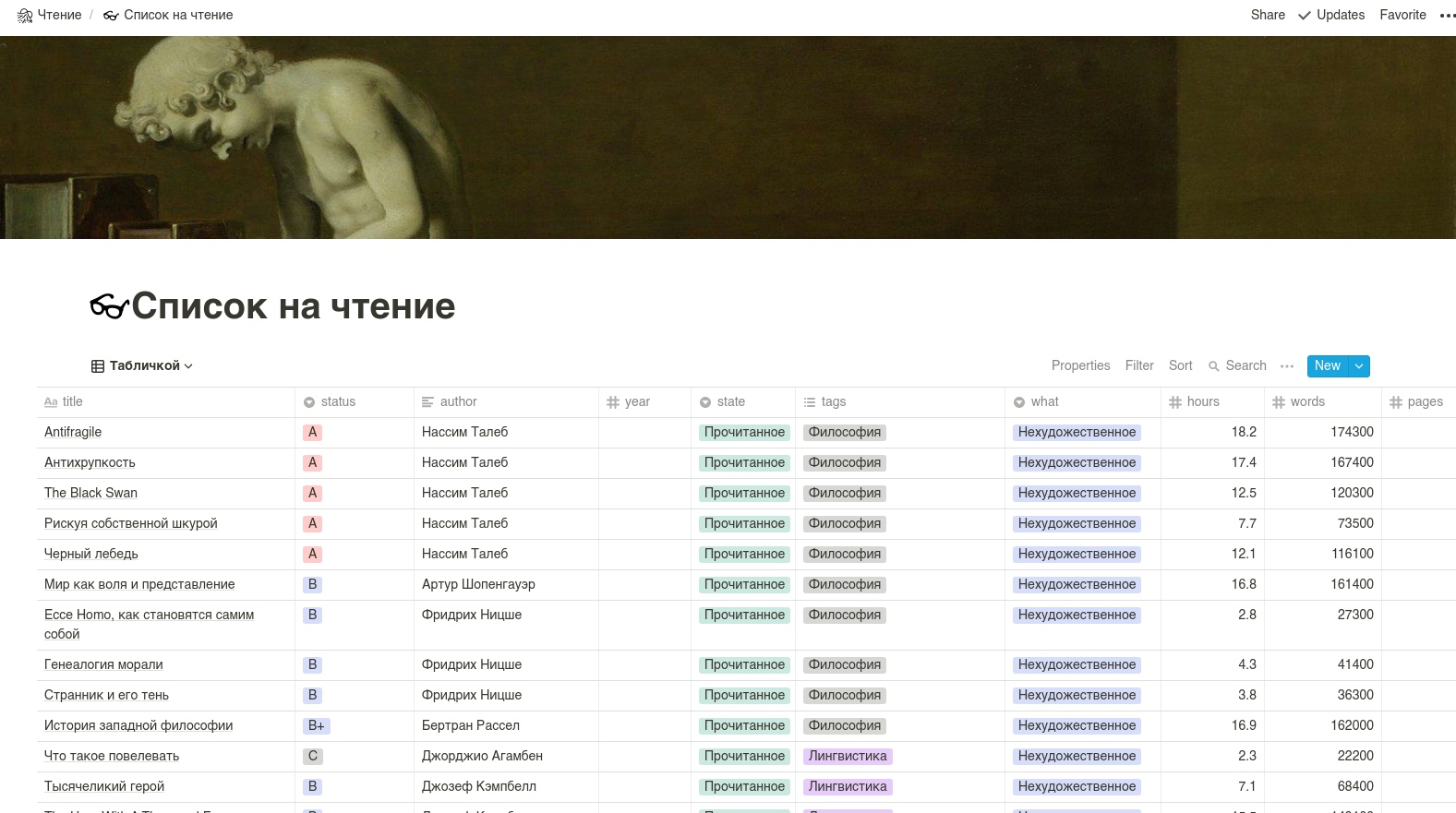
Сама таблица должна выглядеть приблизительно следующим образом. ВНИМАНИЕ: названия столбцов лучше делать латиницей.
Использовать будем неофициальное API Notion'а, потому что официальное еще не завезли.

Идем в Notion, жмякаем Ctrl + Shift + J, идем в Application -> Cookies, копируем token_v2 и называем его TOKEN. Потом идем на нужную нам страницу с табличкой библиотеки и копируем ссылку. Называем NOTION.
Потом пишем код на подключение к Notion'у.
database = client.get_collection_view(NOTION)
current_rows = database.default_query().execute()Далее напишем-ка функцию на добавление строки в табличку.
def add_row(path, file, words_count, pages_count, hours):
row = database.collection.add_row()
row.title = file
tags = path.split("/")
if len(tags) >= 1:
row.what = tags[0]
if len(tags) >= 2:
row.state = tags[1]
if len(tags) >= 3:
if tags[0] == "Художественное":
row.author = tags[2]
elif tags[0] == "Нехудожественное":
row.tags = tags[2]
elif tags[0] == "Учебники":
row.tags = tags[2]
if len(tags) >= 4:
row.author = tags[3]
row.hours = hours
row.pages = pages_count
row.words = words_countЧто тут происходит. Мы берем и добавляем новую строку к таблице в первой строке. Далее сплитим наш путь по "/" и получаем теги. Теги — в плане "Художественное", "Дизайн", кто автор и так далее. Потом задаем все необходимые поля таблички.
Это уже задачка посложнее. Как мы помним, у нас есть два формата: епаб и пдф. Если с епабом все понятно — слова там, вероятно, точно есть, то вот насчет пдф все не так однозначно: оно может состоять просто из склеенных изображений.
Так что функция для подсчета слов в пдф у нас будет выглядеть следующим образом: мы берем количество страниц и домножаем на определенную константу (среднее число слов на странице).
Вот она:
def get_words_count(pages_number):
return pages_number * WORDS_PER_PAGEЭто самое WORDS_PER_PAGE для страницы A4 примерно равно 300.
Теперь давайте напишем функцию для подсчета страничек. Будем юзать PyPDF2.
def get_pdf_pages_number(path, filename):
pdf = PdfFileReader(open(os.path.join(path, filename), 'rb'))
return pdf.getNumPages()Далее напишем штучку для подсчета страниц в епабе. Используем epub_converter. Тут мы берем книжку, конвертируем в строки, и для каждой строки считаем слова.
def get_epub_pages_number(path, filename):
book = open_book(os.path.join(path, filename))
lines = convert_epub_to_lines(book)
words_count = 0
for line in lines:
words_count += len(line.split(" "))
return round(words_count / WORDS_PER_PAGE)Теперь сделаем подсчет времени. Берем наше любимое количество слов и делим на вашу скорость чтения.
def get_reading_time(words_count):
return round(((words_count / WORDS_PER_MINUTE) / 60) * 10) / 10Нам нужно обойти все возможные пути в нашей папке с книгами. Проверить, есть ли уже книга в Notion: если есть — строку создавать нам уже не надо.
Потом нам нужно определить тип файла, в зависимости от этого подсчитать количество слов. В конце добавить книгу.
Вот такой код у нас получается:
for root, subdirs, files in os.walk(BOOKS_DIR):
if len(files) > 0 and check_for_excusion(root):
for file in files:
array = file.split(".")
filetype = file.split(".")[len(array) - 1]
filename = file.replace("." + filetype, "")
local_root = root.replace(BOOKS_DIR, "")
print("Dir: {}, file: {}".format(local_root, file))
if not check_for_existence(filename):
print("Dir: {}, file: {}".format(local_root, file))
if filetype == "pdf":
count = get_pdf_pages_number(root, file)
else:
count = get_epub_pages_number(root, file)
words_count = get_words_count(count)
hours = get_reading_time(words_count)
print("Pages: {}, Words: {}, Hours: {}".format(count, words_count, hours))
add_row(local_root, filename, words_count, count, hours)А функция для проверки, добавлена ли книга, выглядит так:
def check_for_existence(filename):
for row in current_rows:
if row.title in filename:
return True
elif filename in row.title:
return True
return FalseСпасибо всем, кто прочитал эту статью. Надеюсь, она вам поможет читать больше :)