http://habrahabr.ru/company/mailru/blog/271513/

В одной из своих статей я рассказывал об
асинхронной работе с Tarantool на Python. В данной статье продолжу эту тему, но внимание хочу уделить обработке информации через очереди на
Tarantool. Мои коллеги опубликовали несколько статей о пользе очередей (
Инфраструктура обработки очередей в социальной сети Мой Мир и
Push-уведомления в REST API на примере системы Таргет Mail.Ru). Хочу дополнить информацию об очередях на примере решений наших задач, а также рассказать о работе с
Tarantool Queue на Python и asyncio. Почему мы выбираем именно Tarantool, а не Redis или RabbitMQ?
Задача о рассылке сообщений «по всей базе пользователей»
На Mail.Ru существует множество медийных сайтов:
Новости,
Авто,
Леди,
Здоровье,
Hi-Tech и т.д., и каждый день их посещают миллионы пользователей. Сайты адаптированы для мобильных устройств, для большинства из них существует touch-версия. Для удобства пользователей мы создали
мобильное приложение Новости, которое пользуется популярностью на Android- и iOS-устройствах. После публикации «горячей» новости каждому пользователю нашего приложения поступает пуш-уведомление. Выглядит это обычно так: главный редактор выбирает новость, нажимает в админке кнопку «Огонь», и все — поехали! А что же дальше? Дальше нужно как можно быстрее разослать эту новость по всей базе подписчиков. Если кто-то получит пуш-уведомление через полчаса, то, возможно, новость будет уже не такой «горячей», и пользователь узнает о ней из другого источника. Это не наш случай.
Итак, есть база данных, которая хранится в нашем любимом Tarantool. Нужно как можно быстрее обойти всю базу и отправить пуш-уведомление всем подписчикам. Для каждого из них в базе данных хранится пуш-токен и немного информации об устройстве в json-формате: версия приложения, разрешение экрана, часовой пояс, интервал времени, в котором пользователь хочет получать уведомления. Указание часового пояса очень важно, ведь рассылать пуш-уведомления по ночам, когда все спят, не очень хорошая идея.
С требованиями все ясно, идем дальше.
Решаем задачу
Обычно решать задачу мы начинаем в лоб, по-простому. Простой код выглядит всегда очень красиво и понятно:
while «Есть пользователи»:
Выбрать «пачку» пользователей
Отправить пуш-уведомление каждому пользователю из «пачки»
Основной цикл
while будет выполняться до тех пор, пока он не обойдет всех пользователей. Если база пользователей небольшая, то дальше можно ничего не делать, задача решена. Что здесь можно улучшить? Как ускорить такой цикл? Как рассылать за фиксированное время вне зависимости от размера базы данных? Для этого нужно уточнить детали процесса отправки уведомлений.
Для простоты остановлюсь на двух платформах Android и iOS. Что же такое «отправить пуш»? Как это сделать? Есть описание протоколов
Google Cloud Messaging и
Apple Push Notification Service. Есть готовые библиотеки для отправки пуш-уведомлений в
Android и
iOS на Python, предназначенные для работы в привычном «синхронном» режиме. Если копнуть глубже, то каждая платформа обладает своей спецификой. Пуш в Android — это отправка json-данных по https, в iOS — отправка бинарных данных в ssl-сокет. Apple скоро обещает поддержку протокола HTTP/2. Под Android возможна отправка нескольким адресатам. В iOS имеется возможность группировки нескольких пользователей и отправки уведомлений группе. То есть группировка для каждой платформы также имеет свои особенности.
Явно напрашивается решение с очередями. Хочется разделить процесс выборки пользователей из базы данных и процесс рассылки уведомлений по платформам. Но есть много важных деталей. Для независимости процесса отправки одной платформы от другой мы можем разделить пользователей из выбранной «пачки» на iOS и Android, сгруппировать пользователей и добавить сообщение на отправку в нужную нам очередь. Далее сообщения можно обработать, то есть выполнить непосредственно саму работу по отправке пуш-уведомлений. Схематично все эти процессы можно представить так:
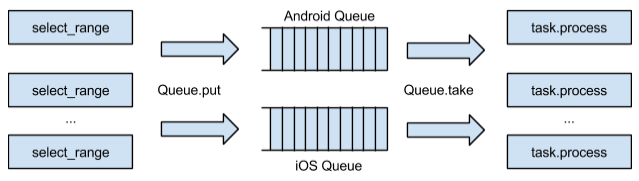
Схема обхода базы пользователей и обработки сообщений через очередь
Что даст такой подход? Мы отделим процесс обхода базы пользователей от рассылки пуш-уведомлений. Таким образом, начнем быстрее перебирать (выполнять
select_range) «пачки» в нашем исходном цикле. Если при обработке сообщений по одной из платформ мы столкнемся с потенциальными проблемами (а такие бывают достаточно часто), то это никак не повлияет на рассылку по другой платформе. Таким образом, сможем легко распараллелить обработку сообщений по ядрам сервера, ведь у нас теперь есть логические очереди. Если понадобится немного расширить нашу систему, то мы просто добавим новые логические очереди.
Решаем проблемы с нагрузкой и масштабированием
С увеличением нагрузки на одном сервере быстро закончится CPU. Добавляем еще один сервер? Да, в точности такой же. Но лучше это сделать еще на этапе проектирования сервиса. Если заставить работать систему на двух серверах, то добавить еще пару десятков не составит труда. Мы придерживаемся этого принципа: минимум два сервера, даже когда нет настоящей нагрузки. Несколько серверов также повысят надежность сервиса. Архитектура сервиса принимает следующий вид:
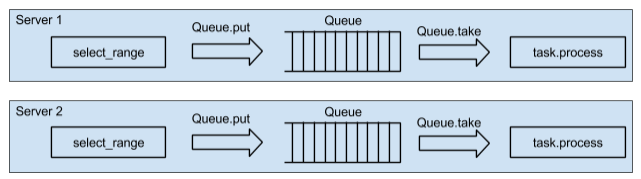
Схема обхода базы пользователей на двух серверах
Итак, мы имеем два сервера, на каждом из которых свои очереди (еще, конечно же, есть база пользователей, считаем, что она просто есть где-то рядом, доступна для выполнения
select_range, не будем уделять этому много внимания). Очень важно запустить цикл обхода параллельно на двух серверах. Можно итерироваться по нашему циклу на одном из серверов, выбирать «пачки», каждую «пачку» помещать в разные очереди, равномерно распределять «пачки» по всем серверам. При таком подходе мы будем вынуждены «гонять» данные по сети. Выбрать «пачку» и положить ее в очередь на другой сервер — слабая сторона такого подхода. Нужно распараллелить
select_range по серверам.
Для этого на одном из серверов необходимо выбрать «пачку», в очередь на «соседнем» сервере добавить маленькое сообщение с информацией о последнем id-пользователя из текущей «пачки». При обработке маленького сообщения на втором сервере мы должны получить «новую пачку» начиная с указанного id, сформировать аналогичное сообщение «серверу-соседу», и т.д., пока не переберем всю базу. Текущую «пачку» нужно всегда обрабатывать локально в своей очереди. Таким образом, мы «как бы» переместим код к нашим данным, распараллелим генерацию «пачек» по серверам и не будем гонять данные по сети.
Диаграмма последовательности будет выглядеть так:

Цикл «по всем пользователям» делается неявно через
queue.put(last_id). Процесс рассылки завершится после того, как в
select_range закончатся пользователи. Очень важно, что в схеме рассылки отсутствуют какие-либо блокировки в БД. Эта схема очень похожа на процесс MapReduce в Hadoop, тот же принцип «Разделяй и властвуй».
Точно такая же архитектура применяется и в нашем продакшен. Для каждого типа мобильного приложения и платформы используются отдельные логические очереди, что позволяет добиваться независимого параллельного выполнения процессов. Рассылка пуш-уведомлений для новости по нашей боевой 2-миллионной базе пользователей занимает около 2 минут. Одновременно с такими рассылками кластер из восьми серверов отправляет около 10 тыс. пуш-уведомлений в секунду.
Особенности написания кода для Tarantool Queue
Как работать с большим количеством логических очередей? Как одновременно разгребать и генерировать данные для всех очередей в одном Python-процессе? На помощь приходят асинхронные приемы в программировании. В примерах я буду использовать Centos 6.4, Python 3, asyncio,
aiotarantool_queue, Tarantool 1.6 и Tarantool Queue.
Очередь Tarantool Queue выдерживает достаточно большие нагрузки. Есть
описание на GitHub. В одном инстансе с Tarantool Queue можно создать несколько логических очередей при помощи вызова
queue.create_tube. Логические очереди называются tube (тьюбы). Поддерживается несколько типов логических очередей. В Tarantool Queue имеется механизм
take/ack. Вызов
take помечает таск как «в работе». Вызов
ack удаляет таск из очереди, подтверждая таким образом его успешное выполнение. Если дело не дойдет до вызова
ack, то другой процесс «подхватит» таск и выполнит
take. Можно на какое-то время отложить выполнение таска при помощи параметра
delay. Таким функционалом и производительностью обладает не каждая очередь.
Использование Tarantool как для хранилища пользователей, так и для системы очередей делает наш сервис простым в плане используемых технологий. Использовать Tarantool Queue вовсе не обязательно. Tarantool и Lua предоставляют возможность для реализации собственной очереди.
Устанавливаем Tarantool, размещаем
github.com/tarantool/queue в каталоге /usr/local/lua. В конфиге Tarantool /etc/tarantool/instances.enabled/q1.lua указываем:
#!/usr/bin/env tarantool
package.path = package.path .. ';/usr/local/lua/tarantool-queue/?.lua'
box.cfg{listen = 3301, slab_alloc_arena = 2}
queue = require 'queue'
queue.start()
box.queue = queue
Стартуем наш инстанс с очередью:
tarantoolctl start q1
Заходим в консоль:
# tarantoolctl enter q1
/usr/bin/tarantoolctl: Connecting to /var/run/tarantool/q1.control
/usr/bin/tarantoolctl: connected to unix/:/var/run/tarantool/q1.control
unix/:/var/run/tarantool/q1.control
Разрешаем гостевой доступ и создаем логическую очередь
q1:
q1.control> box.schema.user.grant('guest','read,write,execute','universe')
q1.control> queue.create_tube('q1', 'fifo')
^D
Разгребать одну очередь можно так:
queue = Tarantool.Queue(host="localhost", port=3301)
while True:
task = queue.take(tube="q1")
process(task)
task.ack()
Для того чтобы разгребать N очередей, можно создать N процессов. В каждом процессе необходимо выполнить connect к нужной очереди и запустить точно такой же цикл. Вполне рабочий подход, но если очередей много, то будет много коннектов к Tarantool Queue. Также будет запущено множество процессов, потребляющих физическую память сервера. Ну и «много коннектов» не делает работу с Tarantool настолько эффективной, насколько она может быть. Также в процессах придется держать коннекты к серверам Google и Apple. И опять же, чем меньше коннектов к серверам Google или Apple мы держим, тем меньше мы их нагружаем, тем больше ресурсов нашего сервера нам доступно.
В статье «Асинхронная работа с Tarantool на Python» я подробно рассказывал, почему обращение в один коннект к Tarantool может дать заметный прирост производительности (это очень важно для наших нагрузок). Данный подход можно применить и здесь. Немного модифицируем наш исходный псевдо-код для разгребания очереди. Адаптируем его под asyncio.
import asyncio
import aiotarantool_queue
@asyncio.coroutine
def worker(tube):
while True:
task = yield from tube.take(.5)
if not task:
break
# process(task.data)
yield from task.ack()
loop = asyncio.get_event_loop()
queue = aiotarantool_queue.Queue("127.0.0.1", 3301, loop=loop)
workers = [asyncio.async(worker(tube), loop=loop)
for tube in (queue.tube('q1'), queue.tube('q2'), queue.tube('q3'))]
loop.run_until_complete(asyncio.wait(workers))
loop.run_until_complete(queue.close())
loop.close()
В одном процессе создаем коннект к очереди. Создаем корутины с циклом take/ack для всех логических очередей. Запускаем event loop и разгребаем все наши очереди. Так выглядит наш паттерн работы с очередями.
Хочется отметить, что код остался линейным, нет никаких callbacks. Также «под капотом» этого кода скрыто то, что таски из очереди будут вычитываться «пачками» — все это дает из коробки
aiotarantool_queue. И никаких ожиданий, пуллинга очередей и таймаутов! Круто? Для загрузки всех ядер сервера по CPU, конечно, придется сделать несколько таких процессов, но это уже дело техники. Обработка очередей на Python-процессах выглядела бы примерно так же. Вместо корутин были бы процессы. А при синхронном подходе код мог бы получиться еще более запутанным, и самое главное — не таким производительным.
Но есть и минусы использования asyncio. Нужно заставить работать сторонние библиотеки, что не так сложно сделать, но придется внимательно просмотреть код этих библиотек и адаптировать их работу при помощи вызовов asyncio. Если нам нужен производительный сервис, то все старания по поддержке работы сторонних библиотек под asyncio будут оправданы.
А как же Redis и RabbitMQ?
Почему мы используем Tarantool Queue, а не Redis или RabbitMQ? Выбор в пользу того или иного продукта сделать не так просто — мы рассматривали и Redis, и RabbitMQ. Даже был прототип на Redis. Все эти решения обладают достаточно хорошей производительностью. Но тут дело не только в том «кто быстрее»…
Прежде всего, хочется, чтобы очередь была надежной, и находилась не в памяти. Tarantool с его WAL выглядит надежнее, чем Redis и RabbitMQ.
Каждая из систем очередей обладает своими особенностями. В Redis есть механизм pub/sub, а он не подходит для решения наших задач — нам нужна именно очередь. В Redis есть списки и операции rpush/blpop с блокировкой и ожиданием появления данных, однако нет механизма take/ack. В нашем продакшен надежность обеспечивается именно этим механизмом — он не раз проявлял себя с лучшей стороны.
RabbitMQ богат различными паттернами для очередей. Для решения наших задач требуется лишь часть функционала RabbitMQ. Его производительность действительно очень высокая, однако если включить сохранение данных на диск, то производительность при нагрузке сильно падает. Для эксплуатации RabbitMQ нужны опытные системные администраторы, которые смогут диагностировать проблемы в продакшен, а не просто порестартить инстанс RabbitMQ.
Отдельного внимания у RabbitMQ заслуживает его Python API и коннектор для asyncio. API для очередей реализовано на callback-ах. Код от callback-ов становится сложным и тяжело поддерживаемым. Чтобы сделать message.ack в asyncio, нужно создать
Future и дождаться ее. Такой код выглядит очень сложно. Также у нас не получилось отправить несколько put/take в один коннект.
У Redis с asyncio все гораздо лучше: есть прекрасный коннектор от автора самого asyncio. Работает действительно быстро.
В Redis и в RabbitMQ отсутствует такая интеграция данных в БД и lua, как у Tarantool. Как правило, задачи на продакшен требуют от очереди чуть больше «логики» из коробки. А в Tarantool этого легко добиться благодаря lua. Например, можно начать хранить счетчики или кеш с данными, или статистику прямо на инстансах с очередями. Все это делает Tarantool удобным для решения различных задач.
Подводим итоги
Мы рассмотрели архитектуру того, как максимально быстро и эффективно распараллелить обход всей базы пользователей с помощью системы очередей на нескольких серверах. Мы рассмотрели паттерны использования Tarantool Queue и asyncio. Уделили внимание проблемам разработки кода с использованием систем очередей. Рассмотрели проблемы RabbitMQ и Redis, а также преимущества Tarantool Queue.
Надеюсь, информация окажется полезной для читателей Хабра. Буду рад, если кто-то поделится своими кейсами применения очередей и расскажет о причинах выбора того или иного решения.
Ссылки, используемые при написании статьи: