Блины с ICOй на питоне или как померять людей и проекты ICO
- четверг, 27 сентября 2018 г. в 00:18:45
Друзья, добрый день.
Есть четкое понимание, что большая часть ICO проектов это по сути своей совсем нематериальный актив. ICO проект это не автомобиль мерседес-бенц – который ездит вне зависимости от того что его кто любит или нет. И основное влияние на ICO оказывает настроение народа – как настрой на основателя\founder ICO, так и самого проекта.
Было бы хорошо как-то измерить настрой народа по отношению к основателю ICO и\или к ICO проекту. Что и было проделано. Отчет ниже.
Результатом стал инструмент сбора позитивного\негативного настроения из Интернетов, в частности из твиттера.
Моё окружение это Windows 10 x64, использовал язык Python 3 в редакторе Spyder в Anaconda 5.1.0, проводное подключение к сети.
Настрой буду получать из постов твиттера. Сначала выясню, чем сейчас занимается основатель ICO и насколько положительно об этом отзываются на примере пары известных личностей.
Буду использовать python библиотеку tweepy. Для работы с твиттером необходимо в нем зарегистрироваться как разработчику, см. twitter/. Получить критерии доступа к твиттеру.
Код получается такой:
import tweepy
API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr"
API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr"
ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr"
ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr"
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)Теперь мы сможем обратиться к API твиттера и что-то от него получить или наоборот запостить. Дело делалось в первых числах августа. Нужно получить сколько-то твиттов для поиска актуального проекта основателя. Искал так:
import pandas as pd
searchstring = searchinfo+' -filter:retweets'
results = pd.DataFrame()
coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500)
for tweet in coursor.items():
my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted'])
result = pd.DataFrame(my_series).transpose()
results = results.append(result, ignore_index = True)
results.to_excel('results.xlsx')В searchinfo подставляем нужное имя и вперёд. Результат сохранял в эксельку results.xlsx.
Дальше решил сделать креатив. Нам необходимо найти проекты основателя. Имена проектов – это имена собственные и пишутся с заглавной буквы. Предположим и это похоже на правду, что с заглавной буквы в каждом твитте будут написаны: 1) имя основателя, 2) имя его проекта, 3) первое слово твитта и 4) посторонние слова. Слова 1 и 2 будут в твиттах встречаться часто, а 3 и 4 редко, по частотности мы 3 и 4 и отсеем. Да, ещё выяснилось, что в твиттах часто попадаются ссылки, 5) их тоже уберём.
Получилось так:
import re
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
corpus = []
for i in range(0, len(results.index)):
review1 = []
mystr = results['text'][i]
#убрать 1)имя кого ищем и 2)его имя в тэге
mystr = re.sub(searchinfo, ' ', mystr)
searchinfo1 = searchinfo.replace(" ","_")
mystr = re.sub(searchinfo1, ' ', mystr)
#убрать 3)ссылки
splitted_text = mystr.split()
mystr=""
for word in splitted_text: #первые 7 символов
if len(word)>6:
if word.find('https:/')==-1 and word.find('http://')==-1:
mystr = mystr+' '+word
else:
mystr = mystr+' '+word
review = re.sub('[^a-zA-Z]', ' ', mystr)
review = review.split()
for word in review:
if word[0].isupper():
review1.append(word.lower())
ps = PorterStemmer()
review1 = [ps.stem(word) for word in review1 if not word in set(stopwords.words('english'))]
review1 = ' '.join(review1)
corpus.append(review1)
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X = cv.fit_transform(corpus).toarray()
names = cv.get_feature_names()В переменной names у нас лежат слова, а в переменной X – места их упоминания. «Сворачиваем» таблицу Х – получаем количество упоминаний. Удаляем слова, которые упоминаются редко. Сохраняем в Эксель. И в Экселе делаем красивую столбчатую диаграмму с информацией как часто какие слова в каком запросе упоминаются.
Наши супер ICO звёзды это «Le Minh Tam» и «Mike Novogratz». Графики:
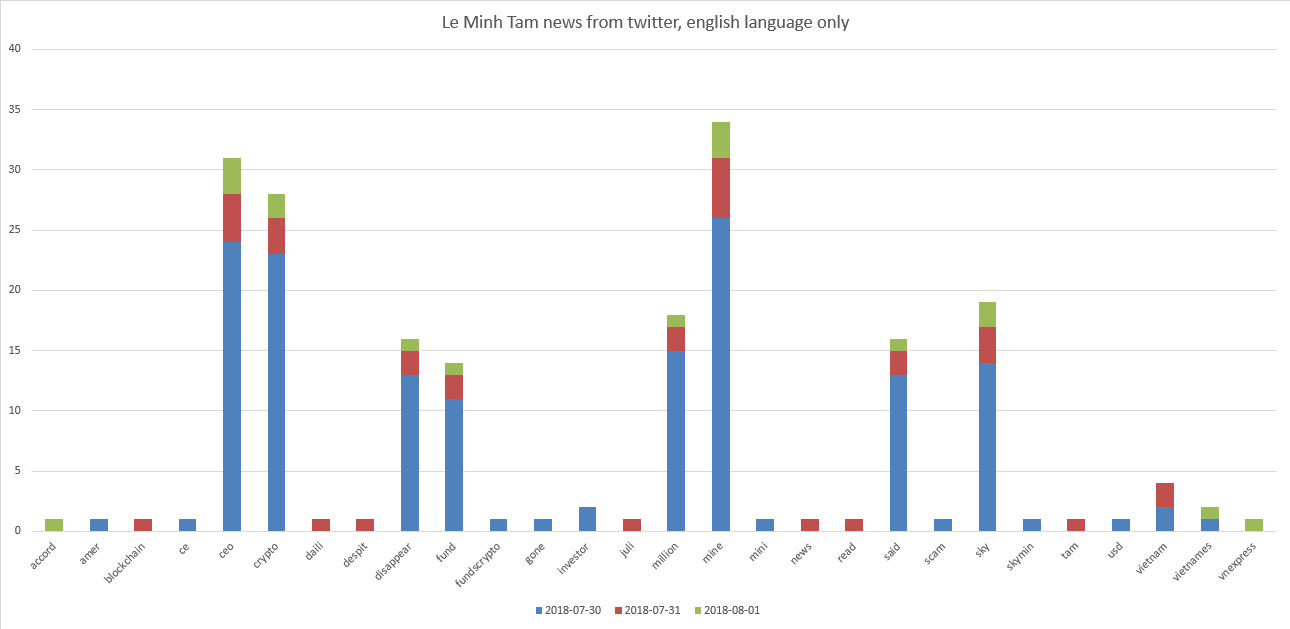
Видно, что Le Minh Tam имеет отношение к "ceo, crypto, mine, sky". И немного к "disappear, fund, million".
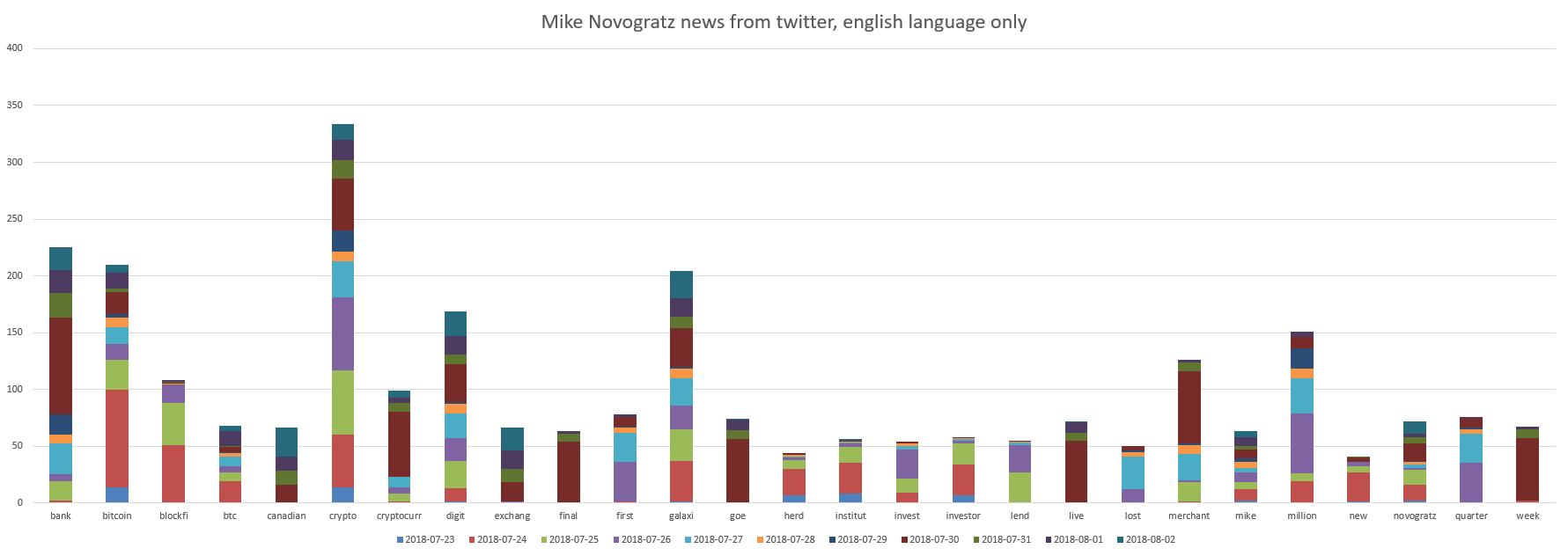
Видно, что Mike Novogratz имеет отношение к "bank, bitcoin, crypto, digit, galaxy".
Данные из Х можно залить в нейронную сеть и она научиться определять всякое, а можно:
И тут мы перестаём маяться дурью креативить и начинаем использовать python библиотеку TextBlob. Библиотека чудо как хороша.
Умные люди говорят, что она умеет:
Библиотека позволяет добавить новые модели или языки через расширения и имеет интеграция WordNet. Одним словом, NLP вундервафля.
Мы выше сохраняли результаты поиска в файл results.xlsx. Загружаем его и проходимся по нему библиотекой TextBlob для целей оценки настроения:
from textblob import TextBlob
results = pd.read_excel('results.xlsx')
polarity = 0
for i in range(0, len(results.index)):
polarity += TextBlob(results['text'][i]).sentiment.polarity
print(polarity/i)Классно! Пара строк кода и бах результат.
Получается, что на момент начала августа 2018 года найденные по запросу «Le Minh Tam» твитты показывают что-то такое, что негативно отразилось в твиттах со средней оценкой по всем твиттам минус 0.13. Если мы посмотрим сами твитты – то увидим например «Crypto Mining CEO Said to Disappear With $35 Million In Funds Crypto mining firm Sky Mining's CEO Le Minh Tam has r…».
А товарищ «Mike Novogratz» сделал что-то такое, что положительно отразилось в твиттах со средней оценкой по всем твиттам плюс 0.03. Можно интерпретировать это так, что всё спокойно движется вперёд.
Для целей оценки ICO стоит мониторить информацию по основателям ICO и по самому ICO из нескольких источников. Например:
План для мониторинга одного ICO:
Ну вот как-то так.
P.S. Ну или покупаем эту информацию, например здесь thomsonreuters