Битва за производительность: SparseMap vs GenerationsMap
- воскресенье, 24 сентября 2023 г. в 00:00:18
Есть такая занимательная структура данных, описанная в статье Russ Cox — sparse map.
Она используется, например, в недрах компилятора Go. А ещё в некоторых пакетах его стандартной библиотеки.
У неё есть много интересных свойств и, чем больше я о ней думаю, тем больше применений нахожу в своих задачах. Казалось бы, всё так хорошо, что лучше быть просто не может. Однако сегодня я расскажу вам о секретной штуке, которая будет экономить ещё больше бесценных наносекунд!
Надеюсь, у меня получилось заинтриговать вас частью до ката.
Чтобы снизить уровень ожиданий, мне сразу хочется дать вам знать — я не эксперт по структурам данных. Тем не менее, я неплохо знаю Go и некоторые хитрости, связанные с оптимизацией кода на нём.
Во время создания "самой быстрой библиотеки поиска пути на Go"™ я без лишних раздумий воспользовался своей любимой sparse-dense map. А затем я увидел её в CPU-профиле и расстроился. Более детальное изучение показало, что несмотря на эффективный Reset, операции доступа (вставка и извлечение) имеют ощутимое замедление по сравнению с обычным слайсом. Настолько ощутимое, что почти весь выигрыш от быстрого зануления может перекрываться.
Перейдём к постановке задачи, так станет понятнее.
Во время реализации A* по двухмерной матрице (сетке) мне понадобились контейнеры для хранения посещённых клеток с их весами. Ключами являются координаты {x,y}. Зная область поиска, можно свести это к простому числовому значению:
func packCoord(c coord, numCols int) uint {
return uint((c.Y * numCols) + c.X)
}Мне нужны были операции Set, Get и Reset:
При этом область поиска пути ограничена некоторым окном, поэтому будем считать, что packCoord возвращает значения в диапазоне [0-65535].
Самый простой вариант — это map[uint16]T. Правда для "самой быстрой библиотеки поиска пути на Go"™ такое не подходит — работает недостаточно эффективно, а контролировать переиспользование памяти почти нереально.
Так как ключи у нас числовые и их пространство весьма ограничено, то следующим вариантом может быть использование обычного слайса. Ключ — это индекс в этому слайсе. Нам придётся аллоцировать слайс размера, равному максимальному возможному ключу (n=65535+1). Перерасход памяти при низкой заполненности высокий, зато операции Get и Set очень быстрые, а ещё память гарантированно можно переиспользовать.
Есть только одно но: для очистки такого слайса перед повторным использованием придётся занулить его содержимое.
Здесь на сцену выходит sparseMap, который даёт нам все те же преимущества, что и слайс, добавляя при этом O(1) очистку без необходимости настоящего зануления.
| Структура данных | Set | Get | Reset |
|---|---|---|---|
| slice | 2665 |
1289 |
6450 |
| genMap | 3068 (x1.1) |
1349 (x1.04) |
26 |
| sparseMap | 17859 (x6.7) |
2435 (x1.89) |
16 |
| map | 47802 (x17.9) |
36922 (x28.6) |
1801 |
Некоторые наблюдения:
Тут стоит отметить, что Reset в обеих структурах такой быстрый не без нюансов. Честного очищения не происходит, поэтому хранить в этих контейнерах указатели не рекомендуется.
Код, использованный в бенчмарках, может быть найден тут.
Некоторые пояснения к бенчмаркам и результатам:
К бенчмаркам в интернете надо относиться с подозрением и перепроверять результаты. Однако, как вы дальше увидите, у genMap есть причины работать быстрее, чем sparseMap. О них мы и поговорим.
Так почему же Set в sparseMap такой медленный?
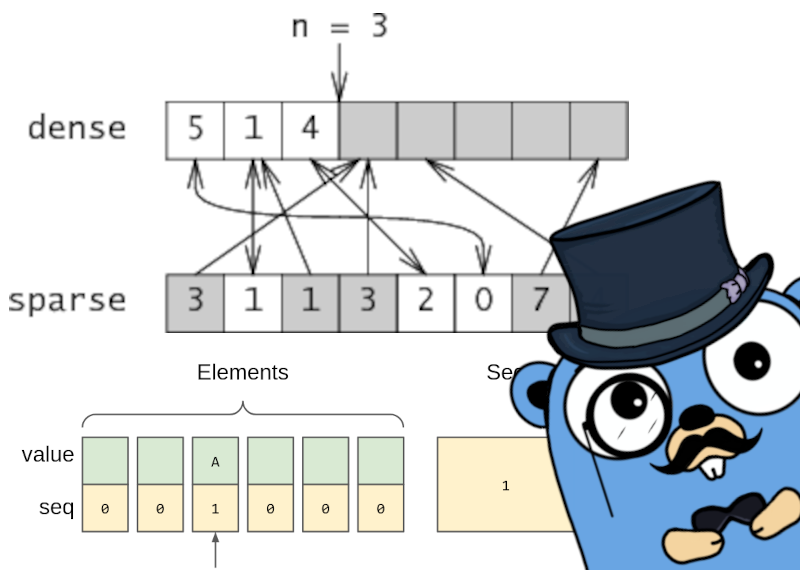
Для начала я напомню, как определяется sparseMap:
type sparseEntry[T any] struct {
key int32
val T
}
type sparseMap[T any] struct {
dense []sparseEntry[T]
sparse []int32
}
func newSparseMap[T any](n int) *sparseMap[T] {
return &sparseMap[T]{
sparse: make([]int32, n),
}
}Вставка нового значения в sparseMap требует двух записей в память. Первая — в sparse слайс, вторая — в dense слайс. Если ключ уже присутствует в контейнере, то писать мы будем только в dense.
func (s *sparseMap[T]) Set(k int32, v T) {
i := s.sparse[k]
if i < int32(len(s.dense)) && s.dense[i].key == k {
s.dense[i].val = v
return
}
s.dense = append(s.dense, sparseEntry[T]{k, v})
s.sparse[k] = int32(len(s.dense)) - 1
}Вторая проблема — это проверки границ массива при доступе (boundchecks). Два слайса (sparse и dense) означают, что у нас вдвое больше потенциальных проверок.
Get отстаёт от слайса не так сильно, но всё ещё страдает от двойного чтения памяти:
func (s *sparseMap[T]) Get(k int32) T {
i := s.sparse[k]
if i < int32(len(s.dense)) && s.dense[i].key == k {
return s.dense[i].val
}
var zero T
return zero
}Для полноты картины покажу и Reset:
func (s *sparseMap[T]) Reset() {
// O(1), как и было обещано.
s.dense = s.dense[:0]
}Начнём с определения самого контейнера:
type genMapElem[T any] struct {
seq uint32 // Счётчик поколения элемента
val T
}
type genMap[T any] struct {
elems []genMapElem[T]
seq uint32 // Счётчик поколения контейнера
}
func newGenMap[T any](n int) *genMap[T] {
// У контейнера изначально счётчик равен 1,
// а у его элементов - 0.
return &genMap[T]{
elems: make([]genMapElem[T], n),
seq: 1,
}
}Только что созданный genMap схематически описывается следующим образом:

Вставка в этот контейнер почти идентична вставке в обычный слайс, но кроме самого значения мы ещё устанавливаем счётчик поколения целевого элемента.
func (m *genMap[T]) Set(k uint, v T) {
// Проверка на длину тут нужна чтобы избежать вставляемого
// компилятором boundcheck при доступе к elems.
// Явная проверка, обычно, более предпочтительна в таких
// крохотных функциях.
// То, что out-of-bounds установка ключа по сути no-op, должно
// быть частью документации нашего genMap.
if k < uint(len(m.elems)) {
m.elems[k] = genMapElem[T]{val: v, seq: m.seq}
}
}
Извлечение элемента будет сравнивать счётчик поколений элемента и контейнера. Если они не совпадают, то мы считаем, что элемент по ключу не установлен.
func (m *genMap[T]) Get(k uint) (T, bool) {
// Здесь проверка на длину не только помогает обращаться
// к m.elems[k] без boundcheck, но и позволяет
// реализовать возврат "not found" для out-of-bounds.
if k < uint(len(m.elems)) {
el := m.elems[k] // Единственное чтение из слайса
if el.seq == m.seq {
return el.val, true
}
}
var zero T
return zero, false
} несуществующего элемента") |
 существующего элемента") |
Самая простая реализация Reset выглядит так:
func (m *genMap[T]) Reset() {
m.seq++
}Эта реализация лучше всего работает при использовании uint64 в качестве счётчика поколений. Вероятность переполнения такого счётчика будет крайне мала. В свою очередь, uint64 будет означать, что мы платим лишние 8 байтов за каждый элемент.
Выше я использовал тип uint32, поэтому давайте запишем более надёжную версию:
func (m *genMap[T]) Reset() {
// Эту проверку можно немного переписать, чтобы она
// работала для переполнения любого из uintX типов.
// Этот пример работает только для uint32.
if m.seq == math.MaxUint32 {
m.seq = 1
clear(m.elems)
} else {
m.seq++
}
}Один раз из MaxUint32 мы будем производить честное очищение памяти. Счётчик можно уменьшать до uint16 или даже uint8, подгоняя его так, чтобы перерасход памяти был минимален (учитывая padding и выравнивание). При этом очевидный побочный эффект будет в том, что более компактный счётчик означает более частые зануления памяти.
Вот несколько примеров подбора счётчика:
| Тип элемента-значения | Счётчик | Перерасход памяти на элемент |
|---|---|---|
| uint8 | uint8 | 1+0 |
| uint16 | uint8 | 1+1 |
| uint32 | uint8 | 1+3 |
| [2]uint32 | uint8 | 1+3 |
| uint8 | uint16 | 2+1 |
| uint16 | uint16 | 2+0 |
| uint32 | uint16 | 2+2 |
| [2]uint32 | uint16 | 2+2 |
| uint8 | uint32 | 4+3 |
| uint16 | uint32 | 4+2 |
| uint32 | uint32 | 4+0 |
| [2]uint32 | uint32 | 4+0 |
Свойства genMap:
Внеся минимальные изменения, из genMap можно сделать genSet. Операция Get становится Contains, а вместо данных со счётчиками мы будем хранить только счётчики.
func (m *genSet) Contains(k uint) bool {
if k < uint(len(m.counters)) {
return m.counters[k] == m.seq
}
return false
}У этой структуры есть и свои минусы по сравнению со sparseMap.
Например, для sparseMap можно реализовать очень эффективную итерацию по элементам. genMap такого не может — придётся обходить все элементы. Так что если нужна операция обхода присутствующих в мапе элементов, то genMap вам не подходит (по крайней мере, без модификаций).
genMap так же не имеет тривиального способа для возвращения своей длины. Вставка элемента такая быстрая, потому что мы не делаем никаких лишних действий. Если добавить счётчик count в сам контейнер и выполнять проверки внутри Set, мы конечно добавим поддержку операции Len, но раза в 2 замедлим вставку.
Среднее потребление памяти будет выше, чем у sparseMap. И хотя в худшем случае sparseMap занимает те же ~2n памяти, чаще всего dense стартует пустым и наполняется через append по мере надобности. Это означает, что при усреднённом заполнении в 50% sparseMap будет использовать 1.5n памяти, а genMap — все 2n.
Отдельно стоит отметить, что sparseMap не требует настоящего зануления памяти на старте, поэтому инициализация этой структуры в языках типа C/C++ будет быстрее. Но так как в Go без всяких трюков выделить грязную память нельзя, sparseMap и genMap играют тут на равных. Тем более что не всегда инициализация контейнера является важным местом — в моём случае контейнер выделяется один раз и затем многократно переиспользуется.
Эту структуру данных я использовал в своей библиотеке pathing, о которой я расскажу подробнее в следующий раз. Переход со sparseMap на genMap дал мне ускорение в 5-8%, что довольно впечатляюще.
В свою очередь, эту библиотеку я использовал в игре, которая уже вышла в стиме: Roboden.
Так что будем считать, что эта структура данных — production-ready.
Не хотите пропустить статью о поиске пути на Go? Присоединяйтесь к нашему сообществу разработки игр на Go.